

Linux SRv6实战(第四篇)-“以应用为中心”的Overlay & Underlay整合方案
source link: https://www.sdnlab.com/23420.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:苏远超 思科首席工程师、李嘉明 思科系统工程师
摘要:本文阐述并实现了以应用为中心的集中式/分布式Overlay & Underlay整合方案,将重点介绍分布式方案,最后对集中式方案和分布式方案的性能做简单的对比。

一、“以应用为中心”的Overlay & Underlay整合理念
随着多云应用成为新常态,多云环境下Underlay和Overlay整合需求越来越多,而业界目前两种常见的解决方案都是“以网络为中心”的(VXLAN或者基于流交接给SR-TE),均存在一定的不足,具体见本系列文章的第三篇,这里不再赘述。
SRv6天生具备整合Underlay、Overlay能力。而且通过使用uSID(详见作者关于uSID的文章),可以轻而易举地基于现有设备编码超长的SR-TE路径(21个航路点只需要80B的协议开销),这对于实现从应用到应用的端到端SLA而言至关重要。
我们的理念是,与其努力弥合两个节奏不同的世界,不如让节奏快的发展的更快。为此,我们提出了“以应用为中心”的Overlay & Underlay整合方案,并在本系列文章的第三篇中做了相应的展示:Underlay设备作为航路点,把Underlay能力提供给应用;应用根据Underlay设备提供的能力,生成SRH并对Overlay网关/VPP进行编程,从而实现Overlay与Underlay的整合。
“以应用为中心”的优势是:
- 对于Overlay:更灵活、更多的控制权、更大的扩展性
- 对于Underlay:更简单、更高效、更容易利用现有网络
然而,不同客户对应用和网络的掌控力度有着很大的不同,这不完全是技术问题,还涉及到管理边界、运维习惯等因素。因此,在“以应用为中心”这个大框架下,我们设计了两种方案:集中式方案和分布式方案。集中式方案可能更容易被网络中已经规模部署了Underlay SDN控制器的客户接受,而分布式方案可能更容易被以云为中心的客户接受。需要说明的是,集中式方案和分布式方案并非是对立的,事实上集中式方案可以迁移至分布式方案,也可以在网络中结合使用集中式方案和分布式方案。对于Overlay网关而言,只是生成SRv6 Policy的来源不同罢了。
下面将详细介绍“以应用为中心”的Overlay & Underlay整合方案的架构与实现。
二、集中式/分布式方案架构
2.1 集中式方案架构
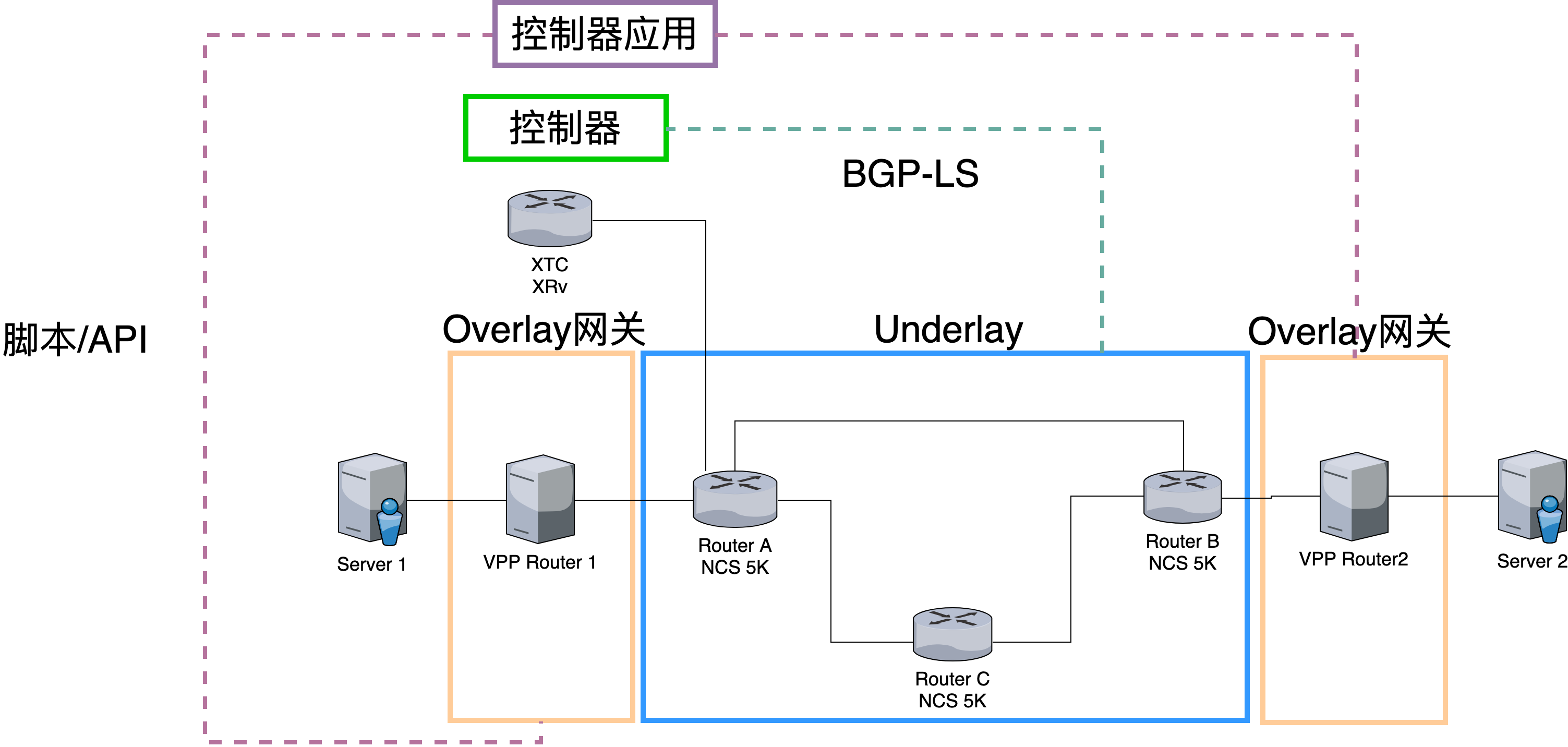
在本系列文章的第三篇中,我们已经详细介绍了集中式方案的架构与实现,这里我们只是简单回顾一下。
上图显示了集中式方案的典型架构。Underlay部分由支持SRv6 End功能的设备组成,只充当航路点,不作为SRv6 Policy的头端(在测试时,采用了三台Cisco NCS5500,组成一个环状拓扑结构)。Overlay网关基于开源VPP开发,Overlay网关同时作为SRv6 Policy的头端,负责将应用发出的IPv4流量封装入SRv6 Policy发往对端,同时对收到的流量执行End.DX4操作以去掉IPv6报头并执行IPv4转发。
控制器采用Cisco XTC,XTC通过BGP-LS得到全网拓扑结构,根据SLA要求计算出最优路径。上层控制器应用通过Rest API从控制器取到拓扑和最优路径信息,构造出相应的SRv6 Policy,并通过VPP API 下发给Overlay网关,从而实现动态的路径创建和控制。
可以看到在集中式方案中,所有的操作均依赖于集中的上层控制器应用对Underlay控制器(XTC)的调用,包括Overlay SLA需求的传递、Underlay设备SRv6信息的采集、Underlay网络发生状态触发的重算。
当海量的应用均需获得端到端SLA路径时,对Underlay控制器的高频调用可能会遇到性能瓶颈(第5.2节的性能测试证明了这一点)。因此,我们设计了分布式方案。
2.2 分布式方案架构
分布式方案引入了etcd,作为存储和维护Underlay网络SRv6 Policy信息的分布式数据库,并作为Overlay和Underlay整合的桥梁。
分布式方案的核心思想如下图:

在分布式方案中,有三个关键的变化:
1.控制器应用变为分布式了,并且控制器应用不直接编程Overlay网关上的SRv6 Policy,而是把计算所得的SRv6 Policy信息写入etcd
2.运行在Overlay网关上的控制代理通过etcd获取和监控Underlay的SRv6 Policy信息,并根据此信息编程Overlay网关上的SRv6 Policy
3.Overlay网关上的控制代理基于etcd的watch机制获知Underlay的变化,Overlay网关可自行决定如何处理,例如重算还是回退到常规转发等
一个关键的事实是,在正常的Underlay网络中,发生路径重算的情况是很少的,可以重用的路径又是很多的。所以,分布式方案的本质是基于etcd建立了一个全网范围内的、超大容量、超高扩展性的“少写多读”的分布式数据库,这样Overlay网关上的控制代理或者其他应用就可以用应用开发人员非常熟悉的etcd API获得Underlay SRv6 Policy信息,以及通过etcd watch机制监控Underlay SRv6 Policy,并独立地做出决策。这赋予了应用开发者高度的灵活性和快速的迭代能力,因为Underlay能力已经被抽象成一个个etcd数据库对象,而不再是难以把控的“黑盒子”。
在本文的后续章节中,将详细介绍我们的分布式方案实现示例。下图显示了此分布式方案实现示例的拓扑。在这里特地采用了与集中式方案一致的物理拓扑来解析分布式方案的实现,以说明分布式方案其实可以由集中式方案演变而来。
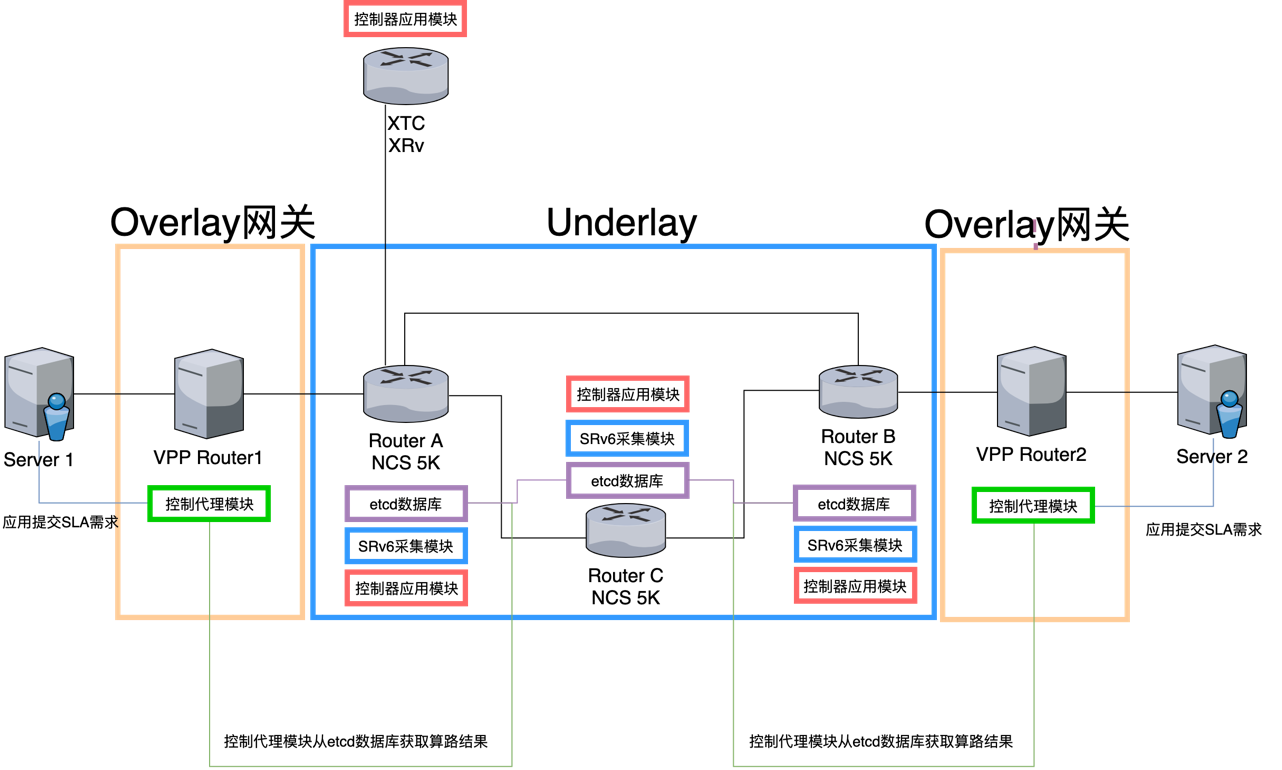
在我们的实现中,利用了Cisco IOS XR对第三方容器的支持能力,即分布式方案的各个组件容器都运行在Cisco NCS5500之上。
- 控制器应用模块容器负责接收算路请求,通过Cisco XTC的API获得IPv4/Prefix-SID形式的算路结果;模块读取etcd数据库中的全网SRv6 Segment,将算路结果转换为SRv6 Segment列表并存储到数据库中,以供控制代理模块读取。
- SRv6信息采集模块容器通过gRPC采集Underlay设备的SRv6 Segment等信息,并存储在etcd数据库中。
- etcd数据库容器运行etcd。
- 控制代理模块需要部署在Overlay网关(VPP)上。此模块通过读取配置文件得到应用的SLA需求,查询etcd数据库获取此SLA需求相应的最优路径,并部署SRv6 Policy到Overlay网关。
需要指出的是,图中的控制器应用模块可以部署在网络中的任意位置,既可以像本文介绍的实现示例一样作为容器部署在多台Underlay设备上,也可以部署在外置的主机上,控制器应用模块本身可以做到是无状态的,因此支持在多个控制器应用模块实例间实现负载均衡。etcd数据库集群同样可以运行在Cisco IOS XR设备或者外置的主机上。
可以看到,在分布式架构设计中,整个系统可以不依赖于其中一台设备或者模块,每个模块均可水平扩展,因此扩展性非常好;使用了业界成熟的etcd数据库作为信息存储/推送模块,大大简化了程序设计。但分布式架构涉及到多个组件间的协同交互,因此实现比集中式方案复杂。
三、实现流程
3.1 集中式方案实现流程解析
详见本系列文章第三篇。
3.2 分布式方案实现流程解析
下面首先对运行在每台Cisco NCS5500上的容器进行简单的解析:
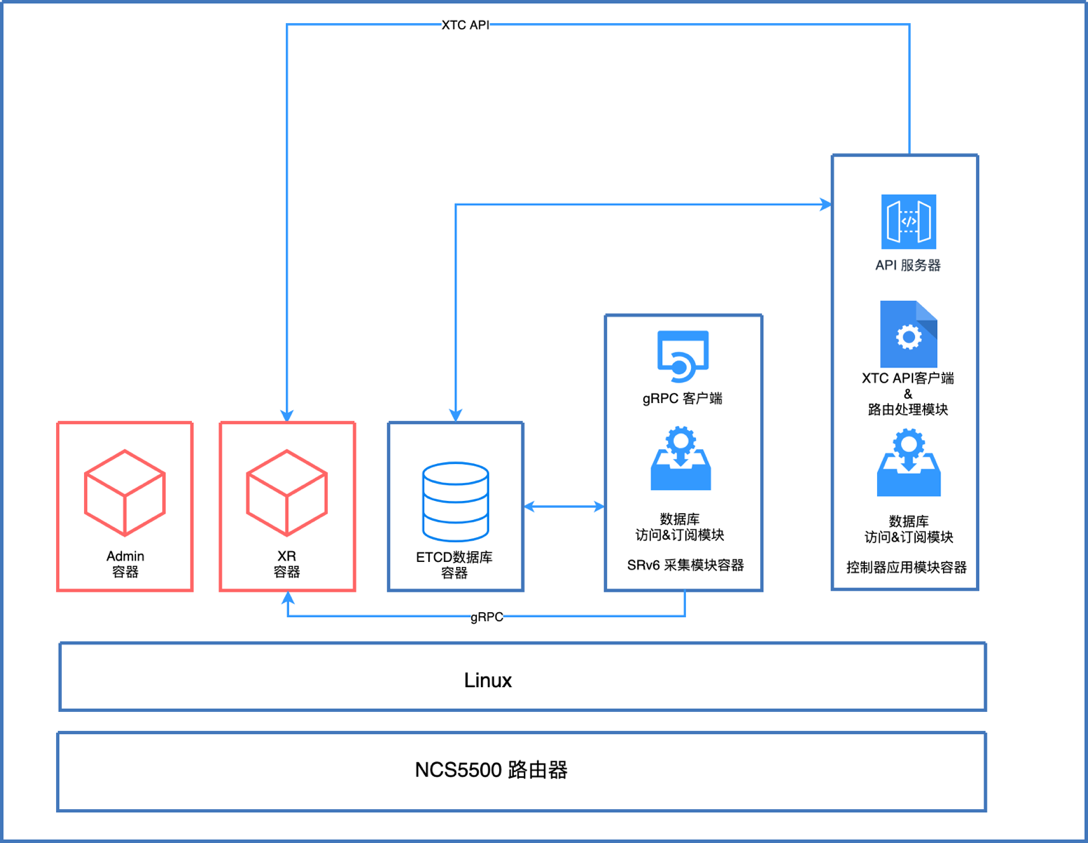
如上图所示,Cisco NCS5500路由器操作系统基于Linux,自带两个容器(LXC),即Admin容器以及XR容器。在自带的容器之外,我们部署了三个应用容器:
- etcd数据库容器:作为整个分布式方案的中间件数据库。
- SRv6数据采集模块容器:该容器内主要包括两个模块,一个是gRPC模块,主要负责通过gRPC访问XR容器,获取SRv6相关的信息;另一个是数据库访问/订阅模块,负责把定时抓取到的数据和etcd里存储的信息进行比较,如果不同则进行更新。
- SRv6控制器模块容器:该容器包括一个API服务器用于提供北向API接口;以及一个XTC API客户端用于调用XTC进行算路;还包括一个数据库访问/订阅模块用于从etcd读取全网SRv6信息,并存储算路结果。
下图显示了分布式方案实现示例的总体运行逻辑:
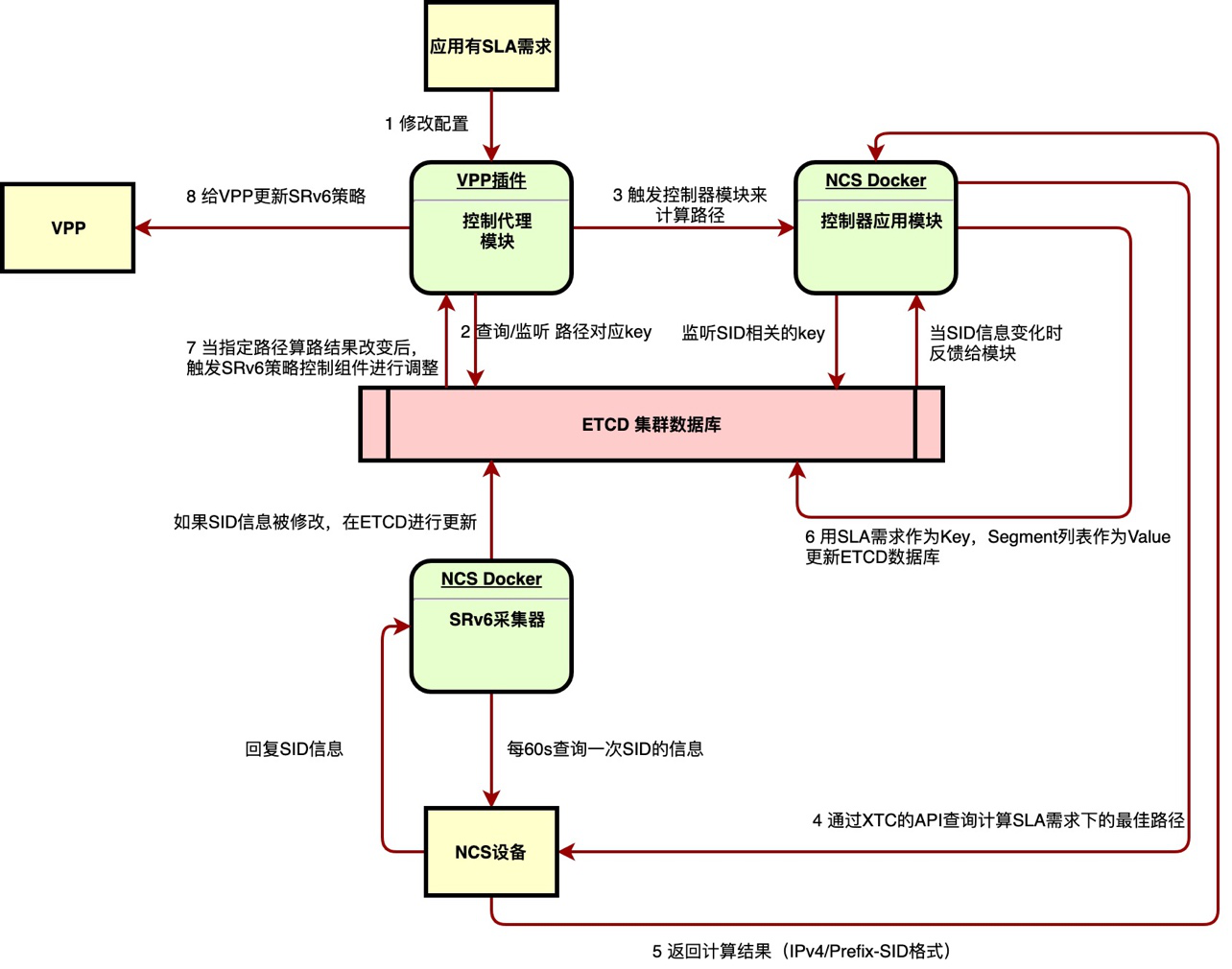
如上图,当应用有SLA需求时,会首先修改控制代理模块的配置(❶)。控制代理模块会尝试获取并监听etcd数据库中关于该SLA需求的算路结果(❷)。。
如果没有已有的算路结果的话,控制代理模块就会通过API触发控制器模块算路(❸)。控制器应用模块会通过XTC API访问XTC网络控制器(❹)。控制器应用模块获得XTC返回Prefix-SID格式的算路结果(❺)。控制器应用模块根据自己从etcd数据库读取到的全网SRv6 信息,将Prefix-SID信息转换为Segment列表,存储回数据库(❻)。
当算路结果更新后,控制代理模块即会收到推送(❼)。最后通过代码下发/更新相应的SRv6 Policy给VPP(❽)。
在这个流程中,各个模块之间使用了etcd数据库的watch机制,因此当网络状态发生变化时,可以立刻更新相关SRv6 Policy。
下面我们详细解析各模块的运行流程。
3.2.1 SRv6 采集模块
SRv6采集模块的具体代码在:https://github.com/ljm625/xr-srv6-etcd
SRv6采集模块主要通过gRPC,访问Cisco NCS5500设备,获取SRv6对应的YANG信息,需要注意的是当前的YANG实现中只包含设备本地的信息,因此需要在每台Cisco NCS5500设备上部署此容器。
具体的模块运行流程如下图:
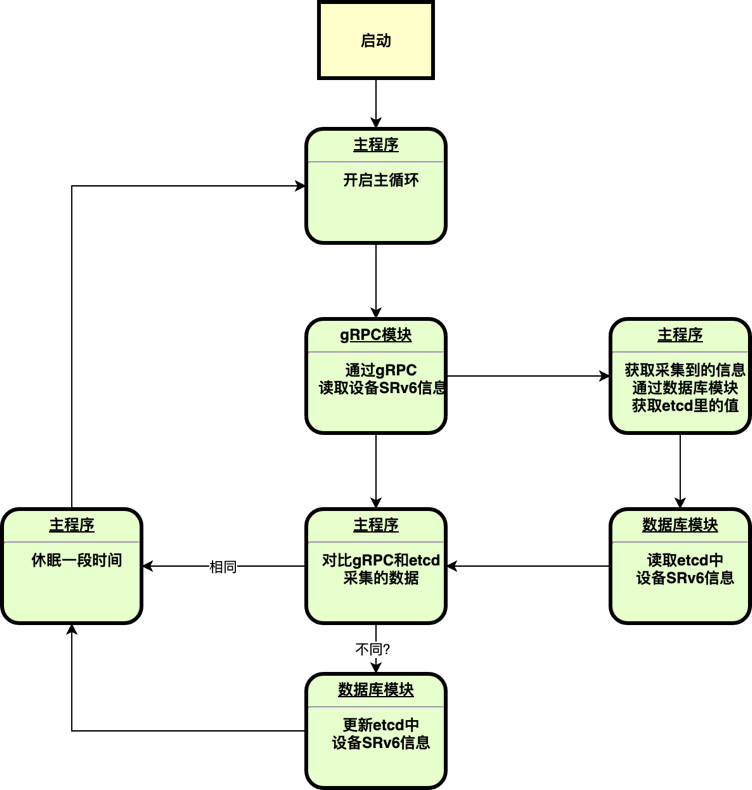
SRv6模块每隔一段时间通过gRPC采集设备本地的SRv6相关信息,并存储到etcd集群数据库中。
3.2.2 控制器应用模块
控制器应用模块的具体代码见:https://github.com/ljm625/xr-srv6-controller
控制器应用模块是整个程序中最复杂的模块,包含四个部分:
- API 服务器
- 提供算路API及查询全网Underlay端点设备的API。
- etcd数据库模块
- 主要负责读取/写入etcd数据库的信息。
- 还负责订阅全网设备的SRv6信息,如果发生变化,etcd会推送给本模块。
- XTC客户端
- 主要负责通过XTC API获取算路结果。
- 算路模块
- 执行主要的算路逻辑,根据XTC算路结果,把表示为IPv4地址的Segment转换为SRv6 Segment(XTC尚不支持SRv6 Policy计算)。
具体的算路流程如下图所示:

如上图,根据是否有算路的历史结果,算路模块会执行不同的策略,并且在网络状态发生变化时,会自动触发控制器模块重新计算影响到的路径。
3.2.3 控制代理模块
控制代理模块具体代码在:https://github.com/ljm625/srv6-vpp-controller
该模块主要负责读取Overlay应用的SLA请求信息,以及VPP的本地SID表配置,需要对本地VPP的SID进行配置,并将相关信息上传到etcd。他还从etcd处获得算路结果以及对端VPP指定VRF的End.DX4/DX6 SID信息,并通过VPP API下发相应的SRv6 Policy。
具体的逻辑流程如下图:
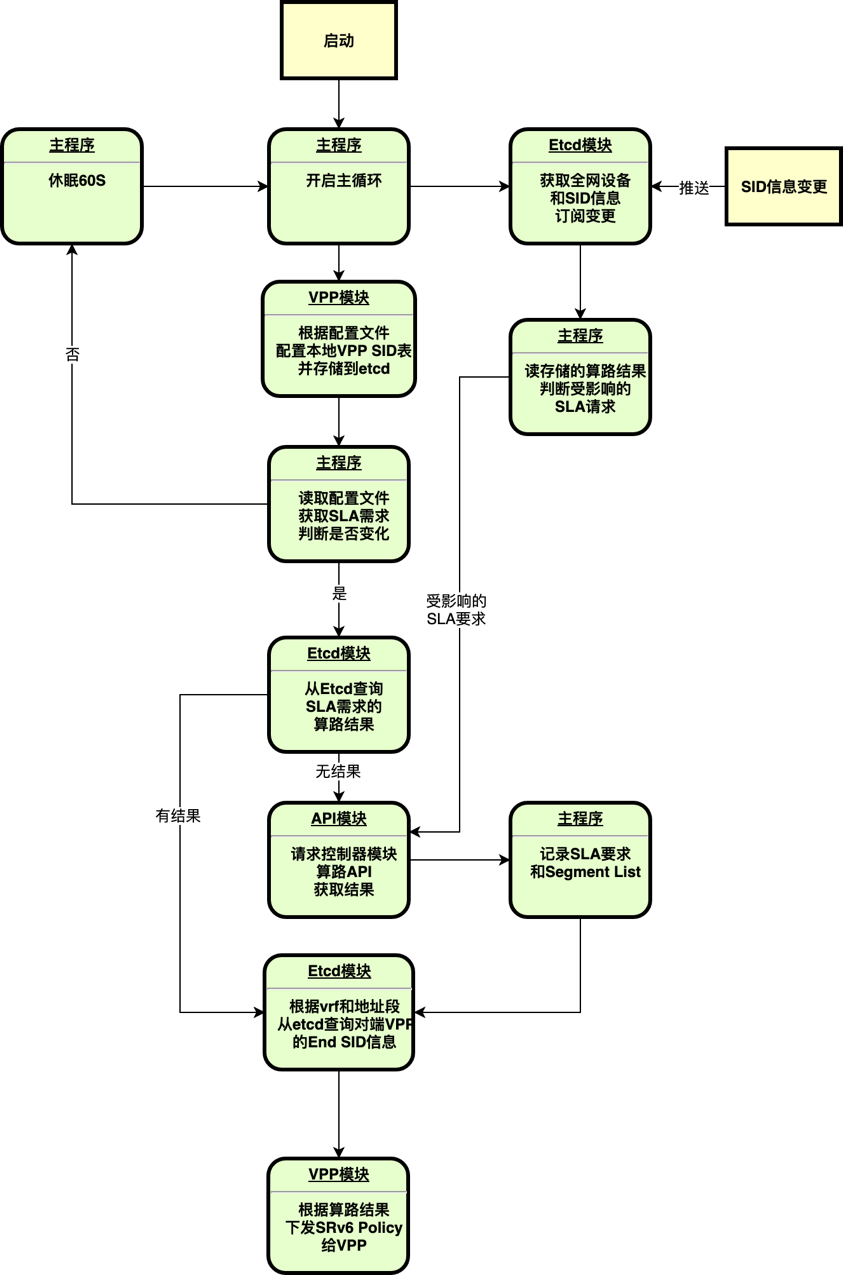
程序主要监听配置文件的变化(SLA需求的变更)以及算路结果的变化。
当配置文件发生变化时,模块会自动判断出需要增/删的路径,算路结果发生变化之后,则说明网络出现变动,也会触发该模块自动修改Overlay网关的SRv6 Policy,动态作出相应调整。
四、实现示例的部署
4.1 集中式方案实现示例的部署
详见本系列文章第三篇。
4.2 分布式方案实现示例的部署
主要采用Docker进行部署,相关容器均已上传到Docker Hub。
4.2.1 etcd数据库部署
etcd数据库部署在多台Cisco NCS5500中,容器的相关代码见:https://github.com/ljm625/ios-xr-etcd
安装很简单,分为单点部署和多点部署两种情况。
单点部署:
bash
mkdir /misc/app_host/etcd export DATA_DIR=/misc/app_host/etcd export IP=Cisco NCS5500的TPA IP地址,如172.20.100.150
docker run -itd \ --cap-add=SYS_ADMIN \ --cap-add=NET_ADMIN \ -v /var/run/netns:/var/run/netns \ --volume=${DATA_DIR}:/etcd-data \ --name etcd ljm625/etcd-ios-xr:latest \ /usr/local/bin/etcd \ --data-dir=/etcd-data --name node1 \ --initial-advertise-peer-urls http://${IP}:2380 \ --listen-peer-urls http://${IP}:2380 \ --advertise-client-urls http://${IP}:2379 \ --listen-client-urls http://${IP}:2379 \ --initial-cluster node1=http://${IP}:2380
执行后即可完成部署。

查看容器日志,可以看到etcd数据库容器正常运行。
集群部署:
在集群部署中,我们把etcd容器部署到三台Cisco NCS5500上,使用的镜像相同。
第一台Cisco NCS5500:
mkdir /misc/app_host/etcd export DATA_DIR=/misc/app_host/etcd export IP=你的NCS的TPA IP地址,如172.20.100.150 export NAME=本机的节点名称,要和下面的相同,如etcd-node-0 (即节点1) NAME_1=etcd-node-0 //集群节点1名称 NAME_2=etcd-node-1 //集群节点2名称 NAME_3=etcd-node-2 //集群节点3名称 HOST_1=172.20.100.150 //集群节点1 IP HOST_2=172.20.100.151 //集群节点2 IP) HOST_3=172.20.100.152 //集群节点3 IP
CLUSTER_STATE=new //集群状态,默认即可 TOKEN=my-etcd-token //集群的通信密钥,任意内容,需要保持一致
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
docker run -itd \ --cap-add=SYS_ADMIN \ --cap-add=NET_ADMIN \ -v /var/run/netns:/var/run/netns \ --volume=${DATA_DIR}:/etcd-data \ --name etcd ljm625/etcd-ios-xr:latest \ /usr/local/bin/etcd \ --data-dir=/etcd-data --name ${NAME} \ --initial-advertise-peer-urls http://${IP}:2380 \ --listen-peer-urls http://${IP}:2380 \ --advertise-client-urls http://${IP}:2379 \ --listen-client-urls http://${IP}:2379 \ --initial-cluster ${CLUSTER} \ --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
第二台Cisco NCS5500:
mkdir /misc/app_host/etcd export DATA_DIR=/misc/app_host/etcd export IP=你的NCS的TPA IP地址,这里为172.20.100.151 export NAME=本机的节点名称,要和下面的相同,如etcd-node-1 (即节点2) NAME_1=etcd-node-0 //集群节点1名称 NAME_2=etcd-node-1 //集群节点2名称 NAME_3=etcd-node-2 //集群节点3名称 HOST_1=172.20.100.150 //集群节点1 IP HOST_2=172.20.100.151 //集群节点2 IP HOST_3=172.20.100.152 //集群节点3 IP
CLUSTER_STATE=new //集群状态,默认即可 TOKEN=my-etcd-token //集群的通信密钥,任意内容,需要保持一致
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
docker run -itd \ --cap-add=SYS_ADMIN \ --cap-add=NET_ADMIN \ -v /var/run/netns:/var/run/netns \ --volume=${DATA_DIR}:/etcd-data \ --name etcd ljm625/etcd-ios-xr:latest \ /usr/local/bin/etcd \ --data-dir=/etcd-data --name ${NAME} \ --initial-advertise-peer-urls http://${IP}:2380 \ --listen-peer-urls http://${IP}:2380 \ --advertise-client-urls http://${IP}:2379 \ --listen-client-urls http://${IP}:2379 \ --initial-cluster ${CLUSTER} \ --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
第三台Cisco NCS5500:
mkdir /misc/app_host/etcd export DATA_DIR=/misc/app_host/etcd export IP=你的NCS的TPA IP地址,这里为172.20.100.152 export NAME=本机的节点名称,要和下面的相同,如etcd-node-0 (即节点3) NAME_1=etcd-node-0 //集群节点1名称 NAME_2=etcd-node-1 //集群节点2名称 NAME_3=etcd-node-2 //集群节点3名称 HOST_1=172.20.100.150 //集群节点1 IP HOST_2=172.20.100.151 //集群节点2 IP HOST_3=172.20.100.152 //集群节点3 IP
CLUSTER_STATE=new //集群状态,默认即可 TOKEN=my-etcd-token //集群的通信密钥,任意内容,需要保持一致
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
docker run -itd \ --cap-add=SYS_ADMIN \ --cap-add=NET_ADMIN \ -v /var/run/netns:/var/run/netns \ --volume=${DATA_DIR}:/etcd-data \ --name etcd ljm625/etcd-ios-xr:latest \ /usr/local/bin/etcd \ --data-dir=/etcd-data --name ${NAME} \ --initial-advertise-peer-urls http://${IP}:2380 \ --listen-peer-urls http://${IP}:2380 \ --advertise-client-urls http://${IP}:2379 \ --listen-client-urls http://${IP}:2379 \ --initial-cluster ${CLUSTER} \ --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
执行后即完成了部署。
访问etcd的数据库,使用默认的端口2379即可。
4.2.2 SRv6 采集模块部署
SRv6的YANG采集模块通过gRPC抓取YANG模型对应的SRv6部分的内容,获取设备本地的SRv6 Segment等信息。由于当前的YANG实现里只有设备本地的SRv6信息,因此需要在全网每台Cisco NCS5500上通过docker部署该模块。
首先需要打开Cisco NCS5500的gRPC功能:
注意的是,这里的端口57777需要和之后的配置对应上,并关闭TLS功能。
然后进入Cisco NCS5500的Linux Bash,启动docker容器,容器相关的代码见:https://github.com/ljm625/xr-srv6-etcd
需要注意的是,在启动该容器时需要正确配置以下参数:
- gRPC port: -g,需要和之前配置的一致,这里是57777
- gRPC IP:-z,一般为127.0.0.1,即本机 127.0.0.1
- gRPC username: -u,和ssh登陆的账户名一致,这里为admin
- gRPC password: -p,和ssh登陆的密码一致,这里为admin
- etcd IP: -i,指定etcd数据库的IP地址,这里为172.20.100.150
- etcd Port: -e, 指定etcd数据库的端口,这里为默认端口2379
执行的命令如下:
docker pull ljm625/xr-srv6-etcd:yang
docker run -itd --cap-add=SYS_ADMIN --cap-add=NET_ADMIN \ -v /var/run/netns:/var/run/netns ljm625/xr-srv6-etcd:yang \ -g 57777 -u admin -p admin -i 172.20.100.150 -e 2379 -z 127.0.0.1
第一行为下载docker镜像,第二行根据给定的参数启动容器。
启动成功后可以查看日志:

如上图输出所示,即表示启动成功,请注意需要在每台Cisco NCS5500上启动这个容器。
除此之外,还有另外一种选择是使用SRv6 CLI抓取模块进行部署。
SRv6的CLI抓取模块通过gRPC执行CLI命令,通过查询ISIS数据库,获取全网设备的SRv6 Segment等信息。由于该部分数据暂时不存在于YANG中,因此目前只能通过CLI访问到。全网的设备均需要开启ISIS,并分发自身的SRv6 Segment信息。该模块只需要在全网任意一台或多台Cisco NCS5500上通过docker部署即可。
部署步骤和运行方式,与前文完全一致,这里不再赘述,只需要将ljm625/xr-srv6-etcd:yang 镜像替换为 ljm625/xr-srv6-etcd:cli 即可。
4.2.3控制器应用模块部署
第三个需要部署在Cisco NCS5500的模块为控制器应用模块,该模块可以部署在一台或者多台Cisco NCS5500上。
容器的相关代码见:https://github.com/ljm625/xr-srv6-controller
首先需要配置Cisco NCS5500作为PCE(XTC)。
接着进入Cisco NCS5500的bash,启动对应的容器,其中有一些参数需要进行配置:
- XTC IP : XTC的IP,如果是本机的话为TPA地址,这里为172.20.100.150
- XTC Username : XTC的登陆用户名,这里为cisco
- XTC Password : XTC的登陆密码,这里为cisco
- etcd IP : etcd的IP地址,这里为172.20.100.150
- etcd Port :etcd的端口信息,这里为2379
- docker pull ljm625/xr-srv6-controller
docker pull ljm625/xr-srv6-controller
docker run -itd --cap-add=SYS_ADMIN --cap-add=NET_ADMIN -v /var/run/netns:/var/run/netns ljm625/xr-srv6-controller -u cisco -p cisco -i 172.20.100.150 -e 2379 -x 172.20.100.150
启动控制器应用模块容器之后可以查看日志:

4.2.4 控制代理模块部署
最后一个模块安装在Overlay网关/VPP上,读取应用要求的SLA信息,算路并动态下发SRv6 Policy给VPP。
该模块无法通过docker进行部署,并且必须和Overlay网关/VPP部署在同一Linux上。
4.2.4.1 安装Python3 运行环境
该模块要求Python3.6以上的环境运行,这里以Ubuntu 16.04 LTS版本作为示例:
添加python3.6的源:
安装python3.6:
调整python3优先级,使得python3.6优先级较高:
4.2.4.2 安装配置VPP Python Script
首先执行:
安装一些必备的模组,其中包括vpp的api json文件,这个是api所必须的。
接着安装vpp在python下的api包,vpp_papi,其实在上一步,我们已经自动通过deb安装了2.7版本的vpp-papi,但适用于python 3.x版本的依赖需要自己手动安装。
执行:
完成vpp_papi依赖的安装。
4.2.4.3 安装配置控制代理模块
接下来配置config.json文件:
{ "config": { "etcd_host": "172.20.100.150", "etcd_port": 2379, "controller_host": "172.20.100.150", "controller_port": "9888", "bsid_prefix": "fc00:1:999::" }, "sla": [ { "dest_ip":"10.1.1.0/24", "source":"RouterA", "dest": "RouterB", "method": "latency", "extra": {}, "vrf_name": "c1"
} ], "sid": [ { "interface": "GigabitEthernet0/4/0", "action": "end.dx4", "gateway": "10.0.1.1", "ip_range": "10.0.1.0/24", "vrf_name": "c1"
} ]
}
里面有几个参数:
- etcd_host/etcd_port: etcd数据库的IP和端口信息
- controller_host/controller_port: 控制器应用模块的IP地址和端口,需要注意的是这个模块默认端口即为9888
- bsid_prefix: 本机VPP SRv6 Policy的BSID前缀范围,新创建的SRv6 Policy都会从这个前缀范围内分配BSID。
- sla:sla部分为应用的SLA需求,为一个数组,可以包含多个SLA需求
- source:起始设备
- dest:目的设备
- method:算路依据,有三种,分别是latency/te/igp
- extra:额外信息,例如避免使用特定资源(节点、链路、SRLG)等,目前暂未实现,为预留的扩展字段
- dest_ip:需要访问的对端Overlay的网段信息,可以为IPv4或者IPv6地址段
- vrf_name:该规则对应的VRF名称,用于隔离多个VPN。需要和对端一致。
- sid:sid部分为VPP节点的本地SID信息,主要是VPP/Overlay网关定义的End.DX4或者End.DX6信息,可以包含多个需要定义的SID信息
- action:SID对应的action,可以为End.DX4或者End.DX6
- interface:End.DX4和End.DX6解封装之后包将通过该网卡转发
- gateway:End.DX4和End.DX6解封装之后将包转发给该网关设备
- ip_range:该网关下设备的IP段。
- vrf_name:该Segment ID对应的VRF名称,用于隔离多个VPN。需要和对端VPP的SLA部分配置一致。
在该模块运行过程中,应用可以根据需求修改配置文件的sla部分,从而动态调整SLA规则。
修改好配置文件之后即可执行代码:

看到类似上图的输出即表示模块正常运行。
4.2.5 运行
在上述部署完成之后,实际上分布式方案实现示例的各个模块已经在运行。
首先可以通过检查各个模块的日志来查看运行状态。
- SRv6 采集模块:

如上图,SRv6采集模块容器的日志输出显示,此模块不断获取到设备本地的SRv6相关信息,并存储到etcd数据库,说明运行正常。
- 控制器应用模块
对于控制器应用模块,可以使用日志确认工作状态,并使用API来测试运行状态。

如上图,表示运行正常,并且已经订阅了网内设备SRv6信息对应的键值(Key)。
可以用Postman 测试控制器的功能以及API:
获取设备API:
GET http://:9888/api/v1/devices
返回:
[“RouterA”, “SR-PCE”, “RouterB”] //网内的Underlay设备列表
计算路径:
POST http://:9888/api/v1/calculate
JSON Payload:
返回:
当这两个API可以正常访问,则表示控制器应用模块运行正常。
- 控制代理模块
对于控制代理模块,首先可以检查其运行日志:
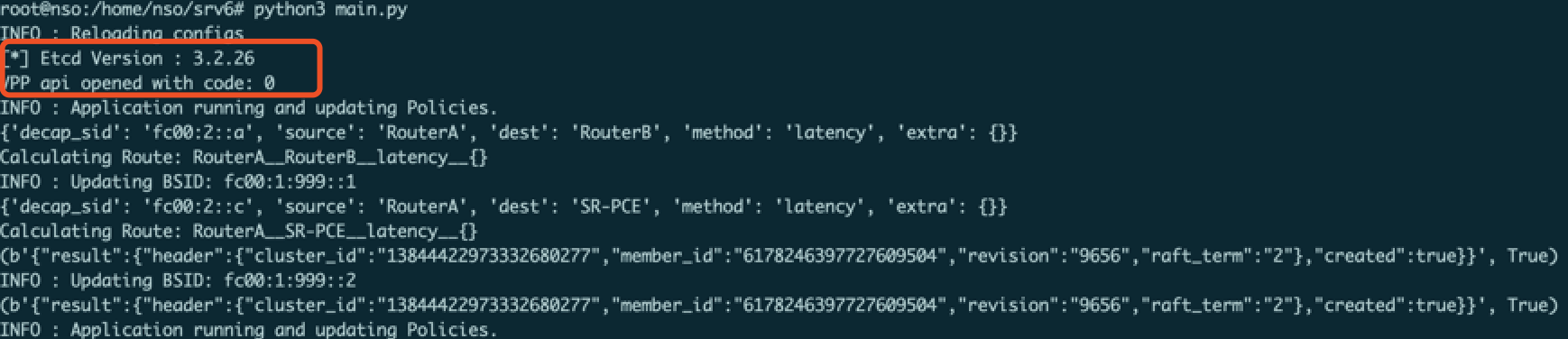
如上图,可以看到控制代理成功连接到etcd以及Overlay网关/VPP,并开始根据配置文件的SLA部分开始算路。
下面添加一个新的SLA需求到控制代理模块的配置文件中,此时保持控制代理模块在后台运行。
{ "config": { // 控制器相关信息 "etcd_host": "172.20.100.150", "etcd_port": 2379, "controller_host": "172.20.100.150", "controller_port": "9888", "bsid_prefix": "fc00:1:999::" }, "sla": [ // SLA 需求部分 { "dest_ip":"10.1.1.0/24 ", "source":"RouterA", "dest": "RouterB", "method": "latency", "extra": {}, "vrf_name": "c1" }, { "dest_ip":"10.2.1.0/24 ", "source":"RouterA", "dest": "SR-PCE", "method": "latency", "extra": {}, "vrf_name": "c1" }, // 新添加的SLA需求 { "dest_ip":"10.2.2.0/24 ", "source":"RouterB", "dest": "SR-PCE", "method": "latency", "extra": {}, "vrf_name": "c1" }, // 新添加的SLA需求 "sid": [ { "interface": "GigabitEthernet0/4/0", "action": "end.dx4", "gateway": "10.0.1.1", "ip_range": "10.0.1.0/24", "vrf_name": "c1" } ]
] }

如上图,当修改了配置文件之后,模块自动读取到更改,计算新添加的从RouterB去往SR-PCE的低延迟路径。
在VPP上可以看到新下发的SRv6 Policy:
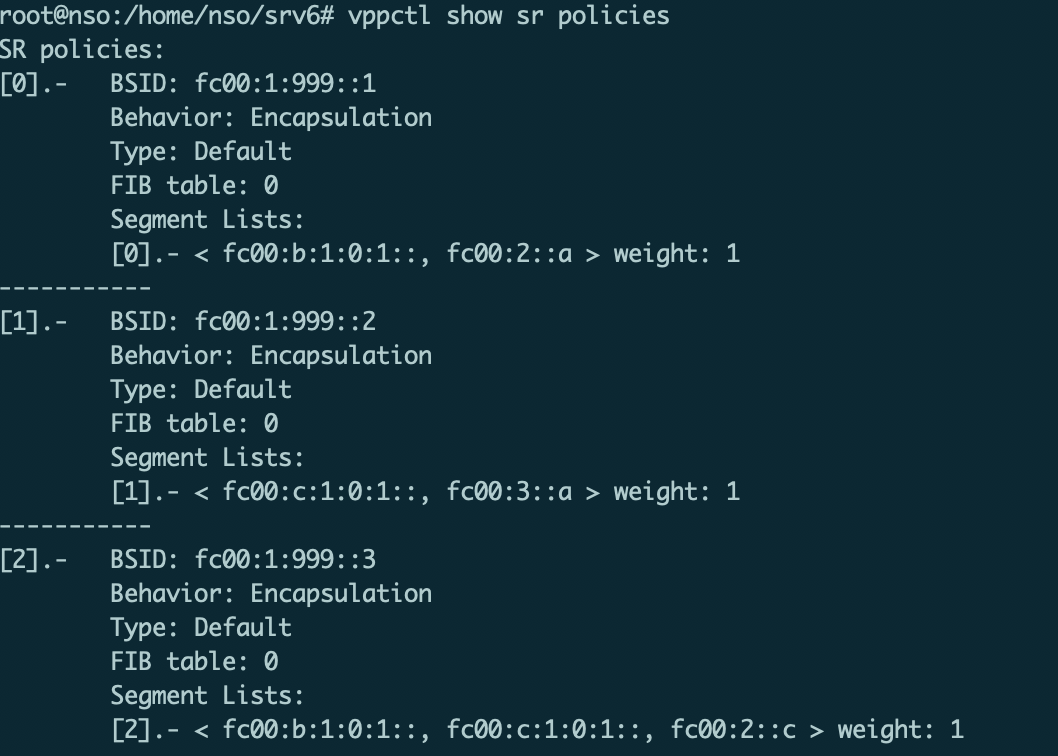
如上图所示,控制代理模块成功下发了满足应用SLA需求的SRv6 Policy。
接下来测试当网络发生变化时控制器应用模块能自动更新SRv6 Policy。
我们继续之前的测试,首先查看SRv6采集模块采集的信息:

接着关闭路由器A上与路由器C直连的端口:
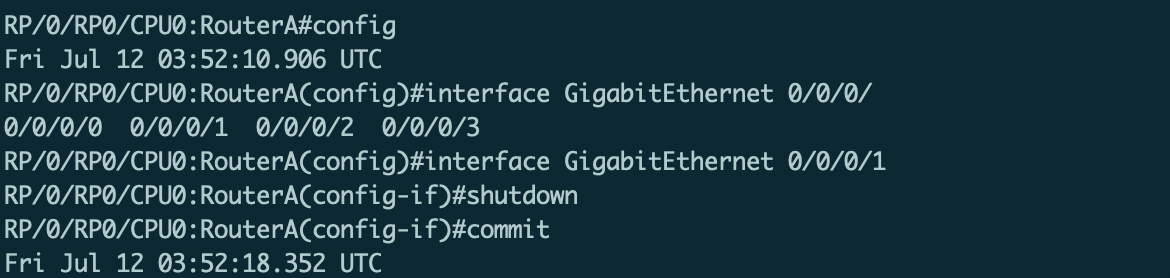
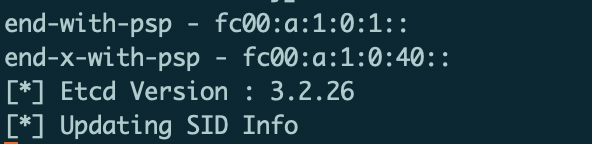
如图21所示,可以看到SRv6采集模块采集到的信息发生了变化,接着SRv6采集模块将自动更新etcd里存储的SRv6信息。由于控制代理模块订阅了相应的键值,因此在算路结果发生变化后将收到etcd推送信息。
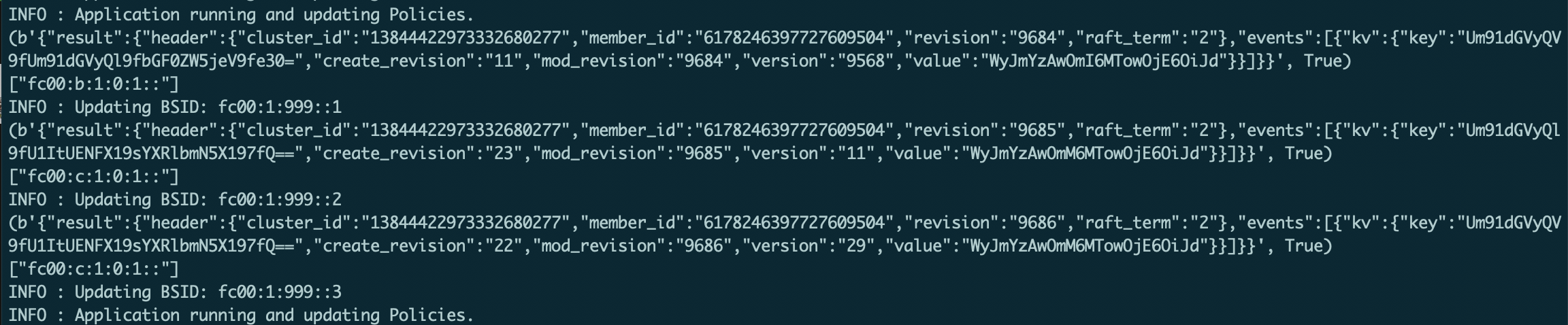
然后,控制代理模块更新相应的SRv6 Policy。此时在Overlay网关/VPP上使用show sr policies,可以看到Segment列表已经自动完成了更新。

五、性能测试
下面将对分布式方案和集中式方案做一个简单的性能测试和对比。
测试软件使用的是开源软件K6(https://k6.io)。
测试例为模拟300个虚拟用户,在100秒的固定时间内,不停访问API请求算路,相当于对API做压力测试。
对于集中式方案实现示例,由于每次请求都是直接从XTC取数据,因此这里简化为直接访问XTC API。XTC使用XRv 9000虚拟机,配置为4vCPU,8G RAM。
对于分布式方案实现示例,我们对控制器应用模块API进行压力测试。
测试结果如下:
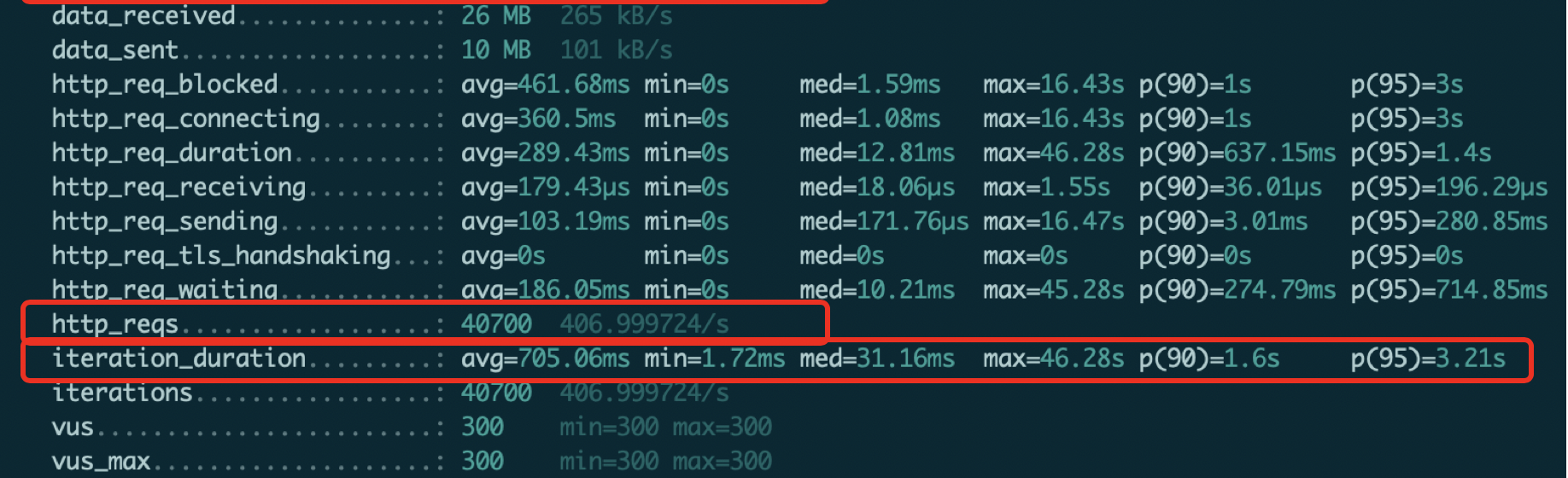
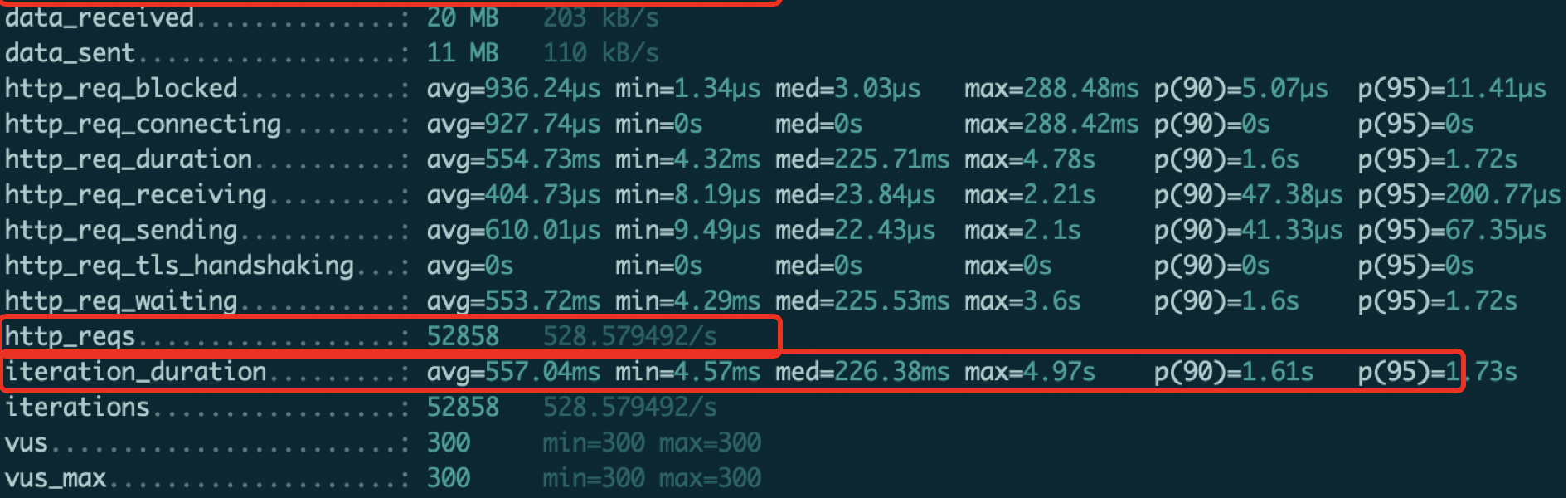

我们对比了三种场景,如图24-26所示,第一种为直接访问XTC的算路API(集中式),第二种为访问三个负载均衡的控制器应用模块实例(分布式),第三种为访问单个控制器应用模块实例(分布式)的测试结果。
http_reqs代表在100秒内总共处理的请求数,数字越大代表能力越强,可以看到XTC的处理能力相当不错,但与负载均衡的多个控制器应用模块相比,性能还是有着明显差距。
iteration_duration代表每个API请求的平均返回时间,可以看到多个控制器应用模块实例<XTC<单个控制器应用模块实例。

具体的对比情况见表1,可以看到即使是单实例的分布式方案,也能很好地在高负载环境下运行,虽然单个实例的请求处理能力受限,但当我们通过增加实例数量水平扩展后,分布式方案的性能可以获得成比率的提升。
本次测试拓扑只有三台设备,SRTE数据库条目很少。而在真实生产环境中,SRTE数据库条目数以万计,此时XTC在对大容量SRTE数据库进行大量计算时性能不可避免会下降。相反地,分布式方案由于可快速水平扩展,并使用etcd作为缓存,因此理论上可以提供更好的性能。
六、总结与展望
传统的Underlay与Overlay整合解决方案是“以网络为中心”。
本文提出的方案则是“以应用为中心”,即Underlay设备只需要将SLA能力提供给etcd,由应用负责根据Underlay SLA能力采用SRv6编码路径。
相较于“以网络为中心”的解决方案,“以应用为中心”的解决方案可以让Overlay和Underlay独立进行演进,Underlay不再成为Overlay的瓶颈,Overlay也不会把复杂性引入Underlay。“以应用为中心”的解决方案允许应用快速地迭代,自主控制SLA策略,非常有利于提供细颗粒度的差异化服务,这无疑对于提升云业务的竞争力大有裨益。
SRv6支持“以网络为中心”和“以应用为中心”两种解决方案,用户可以灵活选择。我们认为,“以应用为中心”的解决方案未来将占据更为重要的位置,这是由于应用和网络具有不同的迭代速度所决定的。
Between overlay & underlay, there is a BRIDGE!
注:本文相关的代码均已上传至Github,链接具体见第4.2节。
【参考文献】
1.uSID draft:https://tools.ietf.org/html/draft-filsfils-spring-net-pgm-extension-srv6-usid-00
2.SRH draft:https://tools.ietf.org/html/draft-ietf-6man-segment-routing-header-21
3.SRv6 draft:https://tools.ietf.org/html/draft-ietf-spring-srv6-network-programming-01
4.Linux SRv6实战(第三篇):多云环境下Overlay(VPP) 和Underlay整合测试:https://www.sdnlab.com/23218.html
5.uSID:SRv6新范式:https://www.sdnlab.com/23390.html
6.VPP的相关资料:https://docs.fd.io/vpp/18.07/
7.VPP SRv6相关资料/教程:https://wiki.fd.io/view/VPP/Segment_Routing_for_IPv6
8.etcd 资料/教程:https://etcd.io/
6. etcd架构与实现解析:http://jolestar.com/etcd-architecture/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK