

uSID:SRv6新范式
source link: https://www.sdnlab.com/23390.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:苏远超,思科首席工程师;蔡德忠,阿里巴巴基础设施首席架构师;蒋治春,腾讯资深架构师
摘要:本文介绍最新的SRv6创新uSID(Micro Segment)。uSID兼容既有的SRv6框架,将极大地改变SRv6的设计、实现和部署方式,成为SRv6的新范式。

一、SRv6 101
Segment Routing(以下简称SR)指由思科院士Clarence Filsfils发明,并主要由IETF SPRING(Source Packet Routing In Networking)工作组进行标准化的新一代网络传送技术。SR基于源路由并且只在网络边缘维持状态,这使得SR非常适合于超大规模SDN部署,现已成为支持5G、物联网、多云、微服务发展的标准网络传送技术。
Clarence在发明SR的第一天,就为SR数据平面设计了两种实现方式(详见RFC 8402):一种是SR-MPLS,其重用了MPLS数据平面,可以在现有IP/MPLS网络上增量部署;另一种是SRv6,使用IPv6数据平面,基于IPv6路由扩展头进行扩展(SRv6报头格式详见IETF草案draft-ietf-6man-segment-routing-header-21),可以在现有IPv6网络上增量部署。
如果说SR-MPLS可以简单地认为是“下一代MPLS”的话,那么SRv6则是代表了全新的思考、设计、运营网络的方式¬——网络即计算机(详见IETF草案draft-ietf-spring-srv6-network-programming-01)。下图是笔者经常使用的一张类比示意图:

- 图中左侧是大家熟悉的X86体系,程序最终是通过X86的CPU指令来操控服务器;右侧是SRv6体系,SDN通过SRv6 Segment来操控网络。
与X86 CPU指令是固定的不同,SRv6 Segment指令是可以任意扩充的(我们建议把新的Segment指令提交IETF进行标准化,但私有的Segment指令也是允许的),这赋予了SRv6极高的灵活性和极强的可扩展性。
目前多个IETF草案定义了多种SRv6 Segment指令,包括Underlay的Segment(转发、TE),也包括Overlay的Segment(L2/L3 VPN),还包括服务编程的Segment(服务链)以及用于5G移动核心网用户面的Segment等。可以看出,SRv6早已超出了Underlay的范畴,朝着全功能、网络级指令集演进。
还需要强调的是,SRv6实现了网络极简:控制平面是支持IPv6的IGP/BGP,转发平面则是纯IPv6。“简单即力量”,SRv6无疑在降低OPEX/CAPEX方面有着非常好的前景。
SRv6极简和可编程两大特性得到了业界的广泛认可。事实上,SRv6的生态系统发展的很快,如下图所示:
但SRv6在实际网络中的部署却很少,部署的业务也只是尽力而为的L3VPN over SRv6,没有SRv6流量工程,更没有服务链这类高级功能。与之相对的是,随着Linux/VPP/智能网卡对SRv6的支持,SRv6在主机侧的应用和创新则是蓬勃发展(详见本文作者发表的Linux SRv6系列文章)。
SRv6在网络侧和主机侧呈现完全不同的情况,原因是什么?如何加速网络侧的SRv6部署?网络侧SRv6与主机侧SRv6如何整合/联动从而实现“网络即计算机”的愿景?
二、SRv6的阿喀琉斯之踵
前面谈到了SRv6在网络侧和主机侧呈现出完全不同的发展速度,根本原因是两者在查找和转发机制上存在根本的差异。
网络侧:ASIC/NPU收到数据包后,把数据包存在外置的内存中。ASIC/NPU读取固定长度的报头内容(一般是96~128字节),然后查找芯片本地/外部内存中的转发表,进行转发。如果报文头太长,无法在一个处理周期完成读取,则需要使用两个处理周期进行读取(Recycle),这将导致吞吐量下降一半。
主机侧:CPU读取完整的(一组)数据包,查找路由表/缓存,进行转发。因此报文头的长度对主机的吞吐不会有太大的影响,当然代价就是吞吐量远低于ASIC/NPU。
在SR-MPLS下,协议引入的开销较小,因此现有的大多数网络设备硬件均可以在一个处理周期内读取完SR报头信息,完成转发,意味着现有的硬件无须替换,只需升级软件即可支持SR-MPLS。这是SR-MPLS能迅速得到大量部署的技术基础之一。
但SRv6引入的协议开销远大于SR-MPLS[1] ,Segment所对应的操作也比SR-MPLS复杂,因此SRv6对网络设备提出了非常高的要求。如果按照目前的SRv6协议实现,要么需要替换掉绝大多数的网络设备,要么网络吞吐降低一半(Recycle),这对于很多用户而言是难以接受的。毕竟SRv6虽好,但如果其前期门槛是如此高的话,网络业界都会踌躇不前;缺乏网络侧SRv6(Underlay)的支持,主机侧(APP/Overlay)的SRv6创新也难以大规模部署,因为无法确保端到端的用户体验——这成为了SRv6的阿喀琉斯之踵。
下面我们通过一个例子来具体分析SR-MPLS和SRv6在协议开销、承载效率、MTU和对硬件芯片要求等方面的异同。假设净荷是IPv4报文,净荷长度是IMIX 440B,需要经过具有5个Segment的路径转发数据包。
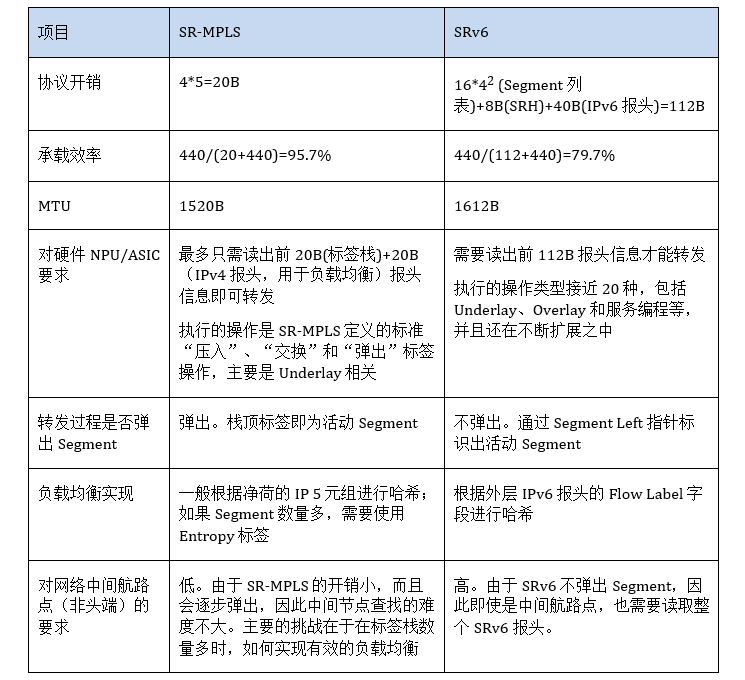
从上表可以看出,SRv6在网络可编程性和负载均衡方面有着巨大的优势,但要发挥其优势,需要迫切解决SRv6在协议开销、承载效率、MTU和对硬件要求方面的问题。这几个问题,其实本质上都是同一个问题:如何提高SRv6 Segment效率?
三、uSID原理
思科(Clarence)联合业界众多领先的运营商、OTT、设备厂商和芯片厂商,在2019年7月8日提交了IETF草案draft-filsfils-spring-srv6-net-pgm-extension-usid-00。这个草案对现有SRv6框架做了扩展,定义了新的Segment类型uSID(Micro Segment)。
uSID可以彻底解决上述的协议开销、承载效率、MTU和对硬件要求高方面的问题。uSID将极大加速SRv6在网络侧的部署,并成为SRv6新范式。一个典型的uSID如下图所示。可见一个128bit的IPv6地址被分为8份,第1份(16bit)用于表示uSID块信息,另外7份每份用于表示一个Segment信息(uSID),这意味着SRv6 Segment效率提高了7倍!

3.1 uSID概念
uSID相关概念如下:
- uSID承载器(uSID Carrier):128bit的SRv6 Segment,其格式为<活动uSID><下一个uSID>…<最后一个uSID><承载器结束标志><承载器结束标志>
- uSID:16bit的Segment ID。也可采用其他长度。
- uSID块(uSID Block):uSID地址块
- 活动uSID(Active uSID):在uSID地址块后的第一个uSID。
- 下一个uSID(Next uSID):在活动uSID之后的uSID。
- 最后一个uSID(Last uSID):在第一个承载器结束标志前的uSID。
- 承载器结束标志(End-of-Carrier ):16进制值“0000”作为承载器结束标志。承载器内所有空闲的位置都需要用承载器结束标志来填充,因此承载器结束标志可以在一个承载器内出现多次。
uSID的设计在一定程度上借鉴了MPLS封装,但保持了对IP路由最长匹配机制的支持。如果将uSID承载器中每个16bits的uSID类比于一个32 bits的MPLS标签,则可以将整个uSID承载器中除了uSID块(前16个bits)以外的部分看做最多7个MPLS标签。uSID相对于MPLS标签的一个优化是每个uSID只包含Segment信息(即MPLS 标签中的20bits的部分),而去除了3 bits的TC(Traffic Class,之前叫EXP)、1bit的栈底标志和8 bits的TTL——TC和TTL信息在IPv6报头字段体现,栈底标志由承载器结束标志表示。

3.2 uSID相关操作
目前草案里只定义了一个操作uN,功能类似于SRv6标准的End操作。
假设uSID块=FC00::/16(ULA地址,详见RFC 4193),节点N对应的uSID=0N00, 则在节点N上uN操作会与以下两条FIB条目相关联:
- FC00:0N00/32绑定至“Shift & Forward(位移 & 转发)”伪代码
- FC00:0N00:0000/48绑定至End操作(弹出uSID承载器,处理下一SRv6 Segment)
其中“Shift & Forward”伪代码如下:
- 把 uSID承载器中第32至127位的内容拷贝至第16-111位(即二进制左移16位,注意从0开始编号)。
- 把第112至127位的内容置为 16进制的“0000”(承载器结束标志)
- 在FIB中查找更新后的目的地址(即uSID块和活动uSID组合起来的前缀)
- 按照匹配的条目转发数据包
uN操作中设备转发表项设计的巧妙构思,可以将IP路由最长匹配的优势发挥得淋漓尽致。
设备利用一长一短两条FIB条目进行最长匹配查找,若匹配到长条目(uSID块+活动uSID+承载器结束标志),说明被处理的uSID是uSID承载器中的最后一个Segment,从而执行uSID承载器的弹出;若匹配到短条目(uSID块+活动uSID,下一个uSID不是承载器结束标志),说明被处理的uSID不是整个uSID承载器的最后一个Segment,则执行“Shift & Forward”操作。uSID对栈底标志的处理,更接近于MPLS,而不是常规的SRv6使用的Segment Left指针。
uSID在转发时则完全继承了SRv6的特点。不同uSID之间完全是标准的IPv6路由,遵循IP路由最长匹配原则。因此,用户完全可以只通告uSID块的汇总路由(甚至只通告默认路由)给末端接入网络,而无须像MPLS一样一定要建立端到端LSP才能转发。这无疑将极大简化了全网的路由设计和减少 了FIB条目。需要注意的是,uSID操作形成的Segment是固定可预知的(uSID块+活动uSID),无须建立和维护复杂的映射表,这使得硬件设备实现起来非常简单。
由此可见,uSID操作是非常简单的,现有的硬件芯片完全可以完成;并且由于uSID将SRv6 Segment效率提高了7倍,因此硬件芯片只需要读取有限的包长就可以完成转发(详见第3.4.2节)。
3.3 uSID转发流程示例
以下基于IETF草案draft-filsfils-spring-srv6-net-pgm-extension-usid-00中的示例,介绍uSID转发流程。
本示例将介绍如何基于uSID实现低延迟IPv4 L3VPN业务,示例拓扑如下图所示:
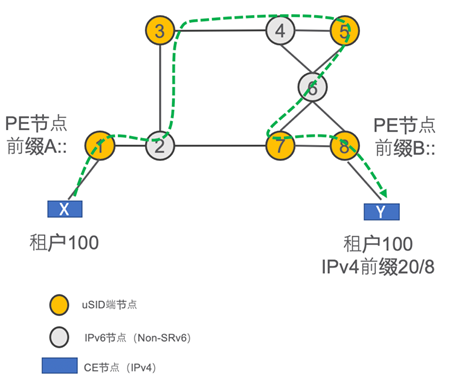
假设uSID块=FC00::/16,节点N对应的uSID=0N00。
图中节点1-节点8位于同一IGP域中,节点1和节点8是SRv6 PE节点。此IGP域中所有链路的IGP度量相等,链路3->4->5->6->7具有更低的延迟。节点1/节点3/节点5/节点6/节点7/节点8均支持uSID,且都在IGP中通告FC00:0N00::/32路由。
图中节点X和节点Y是IPv4 CE节点,不属于SRv6域。
现在要基于uSID为IPv4 数据包(X,Y)[3]提供低延迟的L3VPN业务。转发流程如下:
PE节点1把IPv4数据包(X,Y)封装入IPv6报头内,并转发给节点3。此IPv6报头的目的地址=FC00:0300:0500:0700::,SRH= (B:8:D0::; SL=1; NH=4)。其中FC00:0300:0500:0700::是承载器,用于编码3->4->5->6->7的低延迟路径(注意不需要把路径中的每一跳进行编码,而只需要对航路点进行编码,以充分发挥IP路由ECMP能力);B:8:D0::是表示End.DT4操作(Per-VRF IPv4 VPN)的常规SRv6 Segment。
此时完整的数据包格式是:(A1::, FC00:0300:0500:0700::)(B:8:D0::; SL=1; NH=4)(X, Y)。
由于节点3通告了FC00:0300::/32路由,因此数据包将根据IGP路由转发给节点3。
节点2在从节点1去往节点3的IGP最短路径上,因此节点2会收到PE节点1发出的上述数据包。由于目的地址FC00:0300:0500:0700::不是节点2上的地址,因此根据RFC 8200的规定,节点2不处理扩展头,而只是简单地查自身路由表把数据包发给节点3。 节点3收到数据包(A1::, FC00:0300:0500:0700::)(B:8:D0::; SL=1; NH=4)(X, Y),FC00:0300::/32在本地SID表中的uN操作匹配,节点3执行“Shift & Forward”操作:把目的地址更新为FC00:0500:0700::;查找路由表,匹配到最长条目FC00:0500::/32,于是把数据包转发给节点5。此时完整的数据包格式是:(A1::, FC00:0500:0700::)(B:8:D0::; SL=1; NH=4)(X, Y)
节点4在从节点3去往节点5的IGP最短路径上。节点4的处理与节点2类似,只是简单地按照IGP路由把数据包转发至节点5。 节点5收到数据包(A1::, FC00:0500:0700::)(B:8:D0::; SL=1; NH=4)(X, Y),FC00:0500::/32在本地SID表中的uN操作匹配,节点5执行“Shift & Forward”操作:把目的地址更新为FC00:0700::;查找路由表,匹配到最长条目FC00:0700::/32,于是把数据包转发给节点7。
此时完整的数据包格式是:(A1::, FC00:0700::)(B:8:D0::; SL=1; NH=4)(X, Y)
节点6在从节点5去往节点7的IGP最短路径上。节点6的处理与节点2类似,只是简单地按照IGP路由把数据包转发至节点7。 节点7收到数据包(A1::, FC00:0700::)(B:8:D0::; SL=1; NH=4)(X, Y),FC00:0700:0000::/48与本地SID表中的uN操作匹配(注意由于IP路由最长匹配的特性,此时不是匹配FC00:0700::/32这个条目),因此节点7执行支持PSP[4]和USD[5]的End操作 :将SL递减1,SL=0,把IPv6报头的目的地址更新为Segment列表[0],即B:8:D0::;由于此时SL=0,节点7执行PSP操作,把SRH弹出;根据新的目的地址B:8:D0::查找路由表,把数据包沿最短路径转发至节点8。此时完整的数据包格式是:(A1::, B:8:D0::)(X, Y)。
节点8收到数据包(A1::, B:8:D0::)(X, Y),执行End.DT4操作:去掉外层的IPv6报头,在相应的VRF表中查找VPN前缀路由并转发。
3.4 uSID优势
3.4.1 互操作性
uSID完全遵循srv6-network-programming框架,并非是重新发明一套体系。事实上,uSID只是一系列符合srv6-network-programming框架的新指令。
正是由于uSID本质上只是一个新的SRv6 Segment,因此uSID可以与常规的SRv6 Segment互操作,也可以与纯IPv6节点(Non-SR)互操作。例如在第3.3节中,PE节点1生成数据包(A1::, FC00:0300:0500:0700::)(B:8:D0::; SL=1; NH=4)(X, Y),此数据包使用uSID编码路径,沿途经过纯IPv6节点(节点2/节点4/节点6),最后在节点8基于常规SRv6 Segment完成标准的End.DT4操作。
uSID与常规SRv6 Segment、纯IPv6转发的互操作能力使用户可以在现网增量部署uSID,无需对现有的硬件做全面的替换;利用IPv6提供的可达性,轻松实现uSID的跨域部署。典型的互操作场景如下图所示:

由于现网部署SRv6的案例很少,因此如果业界能迅速地接纳并部署uSID,那么未来很可能是第三种互操作场景成为主流。
3.4.2 协议开销 & MTU
节省协议开销能提高转发效率、节省投资。带宽能更有效地用于转发净荷,而不是用于承载报头开销。
节省协议开销的另外一个重要意义是解决MTU问题。如果使用uSID,即便是需要采用7个uSID编码路径(对于很多应用场景已经足够),其协议开销也只有40B,与IPv4 VxLAN的开销相近。这对于现网部署至关重要,因为很多时候无法配置沿途所有设备的MTU,而MTU不匹配容易导致吞吐下降甚至是流量中断。
下面将针对uSID vs 常规SRv6 Segment以及uSID vs VxLAN over SR-MPLS分别进行分析。
3.4.2.1 uSID vs常规SRv6 Segment
1.Segment列表全部使用uSID
每个uSID承载器可以携带7个uSID,因此如果用于编码路径的uSID数量不超过7,则只需要把各个uSID依次填入uSID承载器对应的位置,并把uSID承载器拷贝到IPv6报头字段即可,不需要使用SRH。此时的协议开销是40B,同样数量的Segment,采用常规SRv6 Segment的协议开销是16*6+8+40=144B,协议开销节省率=(144-40)/144=72.2%。
如果需要使用超过7个uSID,则需要引入SRH。例如对于21个uSID的情况,uSID协议开销是162+8+40=80B,同样数量的Segment,采用常规SRv6 Segment的协议开销是1620+8+40=368B(如此大的协议开销实际上无法使用),协议开销节省率=(368-80)/368=78.3%。
一般地,uSID的协议开销可以用以下公式来计算:

其中T是uSID的总数,[T]表示T的整数部分。
因此,uSID方案相比于常规SRv6 Segment的协议开销节省率可用以下公式计算:

2.混合使用uSID和常规SRv6 Segment
在第3.3节所述示例中,使用uSID实现低时延IPv4 L3VPN业务的协议开销=161+8B+40B=64B[6];如果使用常规的SRv6 Segment,则协议开销为163[7]+8B+40B=96B。两者对比,uSID方案的协议开销节省1/3。
更一般地,假设Segment列表的长度为L(Reduce操作之前),其中K个Segment是uSID,另外L-K个Segment是常规SRv6 Segment,则uSID方案相比于uSID和常规SRv6 Segment混用的协议开销节省率按以下公式计算:
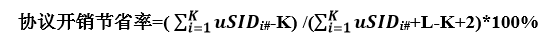
其中uSIDi#表示第i个uSID承载器里包含的uSID数量,uSIDi#<=7。
显然uSID承载器越多、uSID承载器里包含的uSID越多,协议开销节省得越多。
如果每个uSID承载器里只含有一个uSID,则退化为常规SRv6 Segment的情况。
需要说明的是,以上关于协议开销的计算只是理论上的。事实上当常规SRv6 Segment数量超过一定数量后,硬件芯片已经无法在一个处理周期内处理。这时已经不是效率问题了,而是性能问题。
3.4.2.2 uSID vs VxLAN over SR-MPLS
目前,很多用户在数据中心内采用VxLAN实现Overlay,在骨干网采用SR-MPLS实现Underlay,因此当需要跨数据中心提供SLA业务时,需要把VxLAN封装入SR-TE。
SRv6则是天生整合了Overlay和Underlay,无须 在Overlay和Underlay间进行复杂的交接,这极大地降低了网络复杂性和业务复杂性(详见本文作者发表的Linux SRv6系列文章)。而uSID则是将SRv6这一优势发挥到极致:通过一个uSID实现Overlay,其余uSID实现SR-TE,在多数情况下(用于编码路径的uSID数量<=6),甚至不需要SRH,而只需外层加一个IPv6报头!
下图显示了uSID vs IPv4 VxLAN over SR-MPLS vs IPv6 VxLAN over SR-MPLS协议开销对比情况:
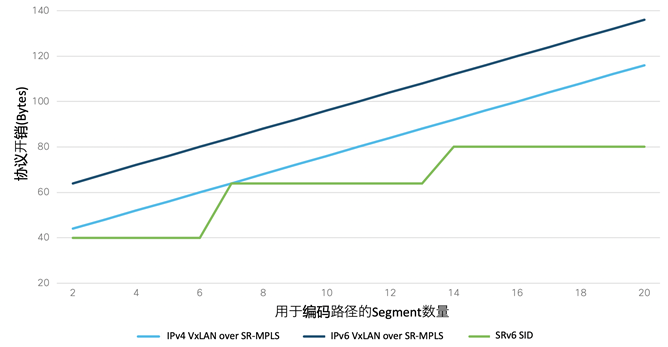
由上图可见,SRv6 uSID在任何情况下的协议开销都要低于VxLAN over SR-MPLS。尤其是当基础设施迁移至IPv6,VxLAN承载在IPv6之上时,uSID的优势更加明显,这个优势随着Segment数量的增多不断放大,最大可以达到50B左右。请不要小看这50B的差异,对于IMIX长度的数据包,这意味着10%的吞吐差异;这也意味着在硬件芯片处理上的巨大差异(是否需要Recycle),进而影响网络性能;同时也意味着可能在MTU处理上的截然不同。
3.4.3 可扩展性
1.uSID数量的可扩展性
uSID长度为16bit,则每个域(uSID块)支持uSID数量=216=65K。如果觉得65K个uSID不够,则可以通过分配额外的uSID块来获得更多的uSID。例如FC00::/16这个uSID块支持65K个uSID,而在FC/8里含有256个类似的uSID块,因此FC/8总共可以支持的uSID数量=256*65K=14M。
如果还是不足够(例如对于物联网的场景),可以设置uSID长度为32bit,此时每个域(uSID块)支持的uSID数量=232=4.3B。
可见uSID数量具备足够的可扩展性。
2.流量工程路径的可扩展性
uSID继承了SR与生俱来的对海量流量工程路径的支持能力,同时还具备对超长流量工程路径的支持能力。这是因为uSID只需要很少的开销就可以支持数十个航路点,而这用常规的SRv6 Segment是无法做到的。
当SRv6流量工程的头端推向主机,流量工程路径是从一端主机发起至另一端主机时,往往需要许多的航路点来编码路径以穿越数据中心、城域网、骨干网、对等互联网络等,此时uSID对超长流量工程路径的支持将发挥关键作用。
3.功能的可扩展性
当前的uSID草案中只定义了uN操作,在后续草案中会定义更多的uSID操作,扩展uSID的功能。
另外,uSID与常规的SRv6 Segment可以无缝结合,可以像乐高积木一样,把uSID的各种操作和SRv6 Segment的各种操作任意组合起来,从而完成各种复杂的功能。
3.4.4 简化控制平面和转发平面
1.控制平面简化
uSID节点只需通告uN操作对应的前缀,网络中其他节点就可通过在路由表中查找uSID块+活动uSID构成的前缀把数据包路由至uSID节点,路由设计非常简单。
无需复杂的映射关系用于把uSID对应到可路由的前缀,也无需任何的路由扩展,现有的IGP/BGP就可胜任,非常简单。
2.转发平面简化
基于IP路由最长匹配进行查找和转发,成熟可靠。
在大多数情况下,IPinIP就足够,不需要使用SRH;即使是使用SRH,uSID的协议开销也比VxLAN over SR-MPLS小,这使得绝大多数硬件可以在一个处理周期完成转发,不用Recycle,这极大地简化了转发平面的设计和实现。
“Shift & Forward”对硬件要求低,容易实现。事实上思科在1年前就可以基于商业芯片Broadcom Jericho演示uSID的线速转发。
无需查找额外的映射表,简化设计,提高效率。
五、总结与展望
对于尚未部署SRv6的网络,我们建议直接部署uSID;对于少量已经部署SRv6的网络,我们建议迁移至uSID,由于uSID支持与IPv6/SRv6网络的无缝互操作,因此往uSID的迁移可以逐步进行。我们相信未来绝大多数的SRv6部署应该是基于uSID的,uSID将是SRv6新范式。产业链的聚合有利于加速SRv6发展。
我们相信,当uSID解锁了Underlay的SRv6能力后,更多的应用场景将被激活,例如基于SRv6/uSID打造Underlay和Overlay一体的智能网络平台。未来uSID发展空间巨大,大有可为。
诚然,uSID还刚起步,目前业界厂商也只有演示代码实现,尚未正式支持。还需要业界各方一起努力,不断完善uSID相关操作,打造强健的生态系统,积极推动现网部署。
未来已来!
【标注】
[1]在整个传送路径上直到倒数第二跳,SRv6数据包中的SRH报头始终存在且长度不会缩短(不像SR-MPLS每经过一个航路点会弹出相应的Segment标签),这就使得承载效率的问题更加严重。
[2]总共需要5个Segment,这里假设采用了Reduce操作,因此Segment列表里只包含了后4个Segment,第1个Segment已经被拷贝至IPv6报头的目的地址字段。
[3](X,Y)表示源地址=X,目的地址=Y
[4]PSP=Penultimate Segment Pop,倒数第二个Segment弹出
[5]USD=Ultimate Segment Decapsulation,最终Segment解封装
[6]后续uSID草案会进一步降低协议开销
[7]总共需要4个Segment(3个航路点+1个End.DT4),这里假设采用了Reduce操作,因此Segment列表里只包含了后3个Segment(2个航路点+1个End.DT4),第1个Segment已经被拷贝至IPv6报头的目的地址字段。
【参考文献】
1.uSID draft:https://tools.ietf.org/html/draft-filsfils-spring-net-pgm-extension-srv6-usid-00
2.SRH draft:https://tools.ietf.org/html/draft-ietf-6man-segment-routing-header-21
3.SRv6 draft:https://tools.ietf.org/html/draft-ietf-spring-srv6-network-programming-01
4.Linux SRv6实战:VPN、流量工程和服务链(第一篇): https://www.sdnlab.com/22842.html
5.Linux SRv6实战(第三篇):多云环境下Overlay(VPP) 和Underlay整合测试:https://www.sdnlab.com/23218.html
6.Think in SRv6:极简的编程化网络:https://www.cisco.com/c/dam/assets/global/CN/solutions/industry/segment_sol/enterprise/programs/2018/cin_fy19q1_sp_workshop_ppt.pdf
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK