

软件开发|在 Fedora 上搭建 Jupyter 和数据科学环境
source link: https://linux.cn/article-11072-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在 Fedora 上搭建 Jupyter 和数据科学环境
在过去,神谕和魔法师被认为拥有发现奥秘的力量,国王和统治者们会借助他们预测未来,或者至少是听取一些建议。如今我们生活在一个痴迷于将一切事情量化的社会里,这份工作就交给数据科学家了。
数据科学家通过使用统计模型、数值分析,以及统计学之外的高级算法,结合数据库里已经存在的数据,去发掘、推断和预测尚不存在的数据(有时是关于未来的数据)。这就是为什么我们要做这么多的预测分析和规划分析。
下面是一些可以借助数据科学家回答的问题:
- 哪些学生有旷课倾向?每个人旷课的原因分别是什么?
- 哪栋房子的售价比合理价格要高或者低?一栋房子的合理价格是多少?
- 如何将我们的客户按照潜在的特质进行分组?
- 这个孩子的早熟可能会在未来引发什么问题?
- 我们的呼叫中心在明天早上 11 点 43 分会接收到多少次呼叫?
- 我们的银行是否应该向这位客户发放贷款?
请注意,这些问题的答案是在任何数据库里都查询不到的,因为它们尚不存在,需要被计算出来才行。这就是我们数据科学家从事的工作。
在这篇文章中你会学习如何将 Fedora 系统打造成数据科学家的开发环境和生产系统。其中大多数基本软件都有 RPM 软件包,但是最先进的组件目前只能通过 Python 的 pip 工具安装。
Jupyter IDE
大多数现代数据科学家使用 Python 工作。他们工作中很重要的一部分是 探索性数据分析Exploratory Data Analysis(EDA)。EDA 是一种手动进行的、交互性的过程,包括提取数据、探索数据特征、寻找相关性、通过绘制图形进行数据可视化并理解数据的分布特征,以及实现原型预测模型。
Jupyter 是能够完美胜任该工作的一个 web 应用。Jupyter 使用的 Notebook 文件支持富文本,包括渲染精美的数学公式(得益于 mathjax)、代码块和代码输出(包括图形输出)。
Notebook 文件的后缀是 .ipynb,意思是“交互式 Python Notebook”。
搭建并运行 Jupyter
首先,使用 sudo 安装 Jupyter 核心软件包:
$ sudo dnf install python3-notebook mathjax sscg
你或许需要安装数据科学家常用的一些附加可选模块:
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
设置一个用来登录 Notebook 的 web 界面的密码,从而避免使用冗长的令牌。你可以在终端里任何一个位置运行下面的命令:
$ mkdir -p $HOME/.jupyter$ jupyter notebook password
然后输入你的密码,这时会自动创建 $HOME/.jupyter/jupyter_notebook_config.json 这个文件,包含了你的密码的加密后版本。
接下来,通过使用 SSLby 为 Jupyter 的 web 服务器生成一个自签名的 HTTPS 证书:
$ cd $HOME/.jupyter; sscg
配置 Jupyter 的最后一步是编辑 $HOME/.jupyter/jupyter_notebook_config.json 这个文件。按照下面的模版编辑该文件:
{"NotebookApp": {"password": "sha1:abf58...87b","ip": "*","allow_origin": "*","allow_remote_access": true,"open_browser": false,"websocket_compression_options": {},"certfile": "/home/aviram/.jupyter/service.pem","keyfile": "/home/aviram/.jupyter/service-key.pem","notebook_dir": "/home/aviram/Notebooks"}}
/home/aviram/ 应该替换为你的文件夹。sha1:abf58...87b 这个部分在你创建完密码之后就已经自动生成了。service.pem 和 service-key.pem 是 sscg 生成的和加密相关的文件。
接下来创建一个用来存放 Notebook 文件的文件夹,应该和上面配置里 notebook_dir 一致:
$ mkdir $HOME/Notebooks
你已经完成了配置。现在可以在系统里的任何一个地方通过以下命令启动 Jupyter Notebook:
$ jupyter notebook
或者是将下面这行代码添加到 $HOME/.bashrc 文件,创建一个叫做 jn 的快捷命令:
alias jn='jupyter notebook'
运行 jn 命令之后,你可以通过网络内部的任何一个浏览器访问 <https://your-fedora-host.com:8888> (LCTT 译注:请将域名替换为服务器的域名),就可以看到 Jupyter 的用户界面了,需要使用前面设置的密码登录。你可以尝试键入一些 Python 代码和标记文本,看起来会像下面这样:
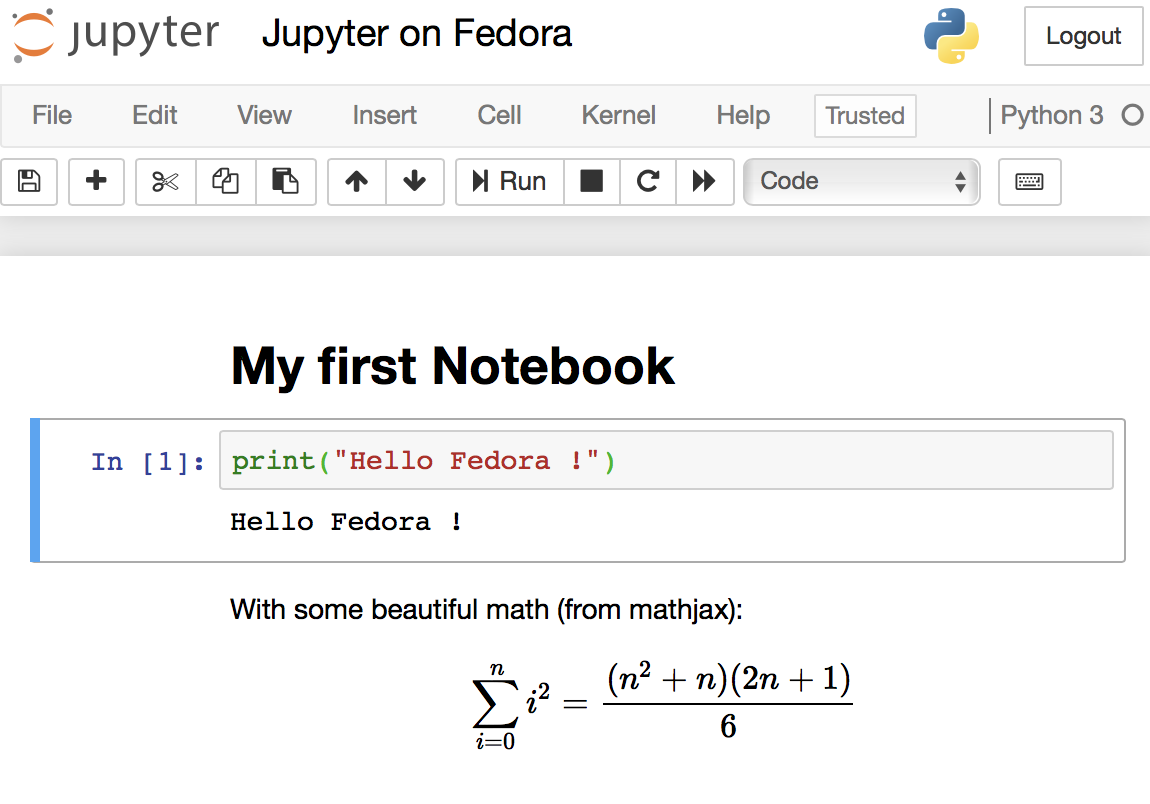
Jupyter with a simple notebook
除了 IPython 环境,安装过程还会生成一个由 terminado 提供的基于 web 的 Unix 终端。有人觉得这很实用,也有人觉得这样不是很安全。你可以在配置文件里禁用这个功能。
JupyterLab:下一代 Jupyter
JupyterLab 是下一代的 Jupyter,拥有更好的用户界面和对工作空间更强的操控性。在写这篇文章的时候 JupyterLab 还没有可用的 RPM 软件包,但是你可以使用 pip 轻松完成安装:
$ pip3 install jupyterlab --user$ jupyter serverextension enable --py jupyterlab
然后运行 jupiter notebook 命令或者 jn 快捷命令。访问 <http://your-linux-host.com:8888/lab> (LCTT 译注:将域名替换为服务器的域名)就可以使用 JupyterLab 了。
数据科学家使用的工具
在下面这一节里,你将会了解到数据科学家使用的一些工具及其安装方法。除非另作说明,这些工具应该已经有 Fedora 软件包版本,并且已经作为前面组件所需要的软件包而被安装了。
Numpy
Numpy 是一个针对 C 语言优化过的高级库,用来处理大型的内存数据集。它支持高级多维矩阵及其运算,并且包含了 log()、exp()、三角函数等数学函数。
Pandas
在我看来,正是 Pandas 成就了 Python 作为数据科学首选平台的地位。Pandas 构建在 Numpy 之上,可以让数据准备和数据呈现工作变得简单很多。你可以把它想象成一个没有用户界面的电子表格程序,但是能够处理的数据集要大得多。Pandas 支持从 SQL 数据库或者 CSV 等格式的文件中提取数据、按列或者按行进行操作、数据筛选,以及通过 Matplotlib 实现数据可视化的一部分功能。
Matplotlib
Matplotlib 是一个用来绘制 2D 和 3D 数据图像的库,在图象注解、标签和叠加层方面都提供了相当不错的支持。
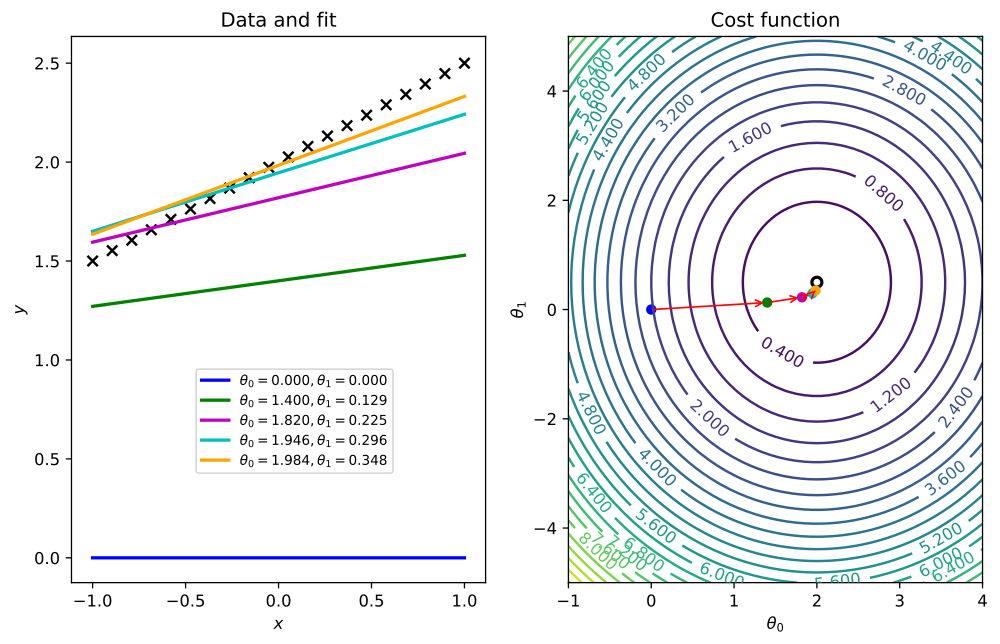
matplotlib pair of graphics showing a cost function searching its optimal value through a gradient descent algorithm
Seaborn
Seaborn 构建在 Matplotlib 之上,它的绘图功能经过了优化,更加适合数据的统计学研究,比如说可以自动显示所绘制数据的近似回归线或者正态分布曲线。
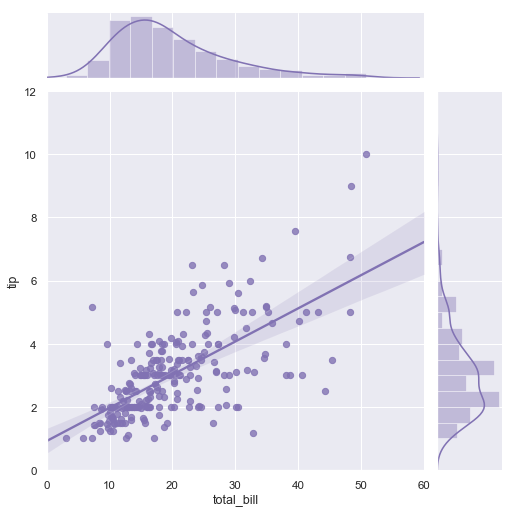
Linear regression visualised with SeaBorn
StatsModels
StatsModels 为统计学和经济计量学的数据分析问题(例如线形回归和逻辑回归)提供算法支持,同时提供经典的 时间序列算法 家族 ARIMA。
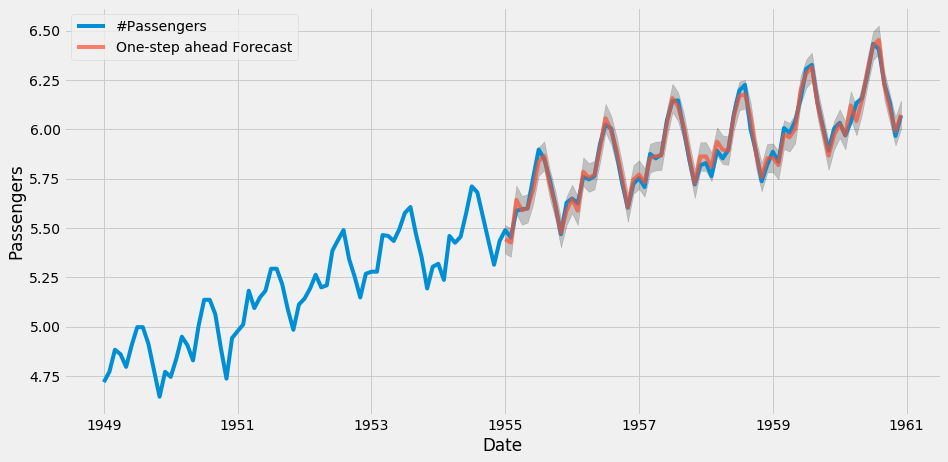
Normalized number of passengers across time \(blue\) and ARIMA-predicted number of passengers \(red\)
Scikit-learn
作为机器学习生态系统的核心部件,Scikit 为不同类型的问题提供预测算法,包括 回归问题(算法包括 Elasticnet、Gradient Boosting、随机森林等等)、分类问题 和聚类问题(算法包括 K-means 和 DBSCAN 等等),并且拥有设计精良的 API。Scikit 还定义了一些专门的 Python 类,用来支持数据操作的高级技巧,比如将数据集拆分为训练集和测试集、降维算法、数据准备管道流程等等。
XGBoost
XGBoost 是目前可以使用的最先进的回归器和分类器。它并不是 Scikit-learn 的一部分,但是却遵循了 Scikit 的 API。XGBoost 并没有针对 Fedora 的软件包,但可以使用 pip 安装。使用英伟达显卡可以提升 XGBoost 算法的性能,但是这并不能通过 pip 软件包来实现。如果你希望使用这个功能,可以针对 CUDA (LCTT 译注:英伟达开发的并行计算平台)自己进行编译。使用下面这个命令安装 XGBoost:
$ pip3 install xgboost --user
Imbalanced Learn
Imbalanced-learn 是一个解决数据欠采样和过采样问题的工具。比如在反欺诈问题中,欺诈数据相对于正常数据来说数量非常小,这个时候就需要对欺诈数据进行数据增强,从而让预测器能够更好地适应数据集。使用 pip 安装:
$ pip3 install imblearn --user
Natural Language toolkit(简称 NLTK)是一个处理人类语言数据的工具,举例来说,它可以被用来开发一个聊天机器人。
机器学习算法拥有强大的预测能力,但并不能够很好地解释为什么做出这样或那样的预测。SHAP 可以通过分析训练后的模型来解决这个问题。
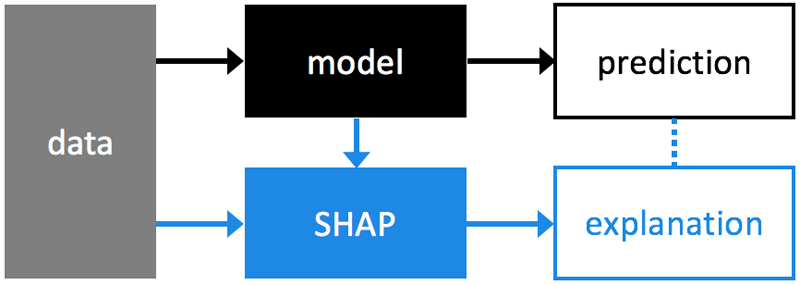
Where SHAP fits into the data analysis process
使用 pip 安装:
$ pip3 install shap --user
Keras
Keras 是一个深度学习和神经网络模型的库,使用 pip 安装:
$ sudo dnf install python3-h5py$ pip3 install keras --user
TensorFlow
TensorFlow 是一个非常流行的神经网络模型搭建工具,使用 pip 安装:
$ pip3 install tensorflow --user
Photo courtesy of FolsomNatural on Flickr (CC BY-SA 2.0).
via: https://fedoramagazine.org/jupyter-and-data-science-in-fedora/
作者:Avi Alkalay 选题:lujun9972 译者:chen-ni 校对:wxy

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK