

docker实现原理以及简单体验(一)-Arvin
source link: https://blog.51cto.com/14163901/2417017
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
docker实现原理以及简单体验(一)
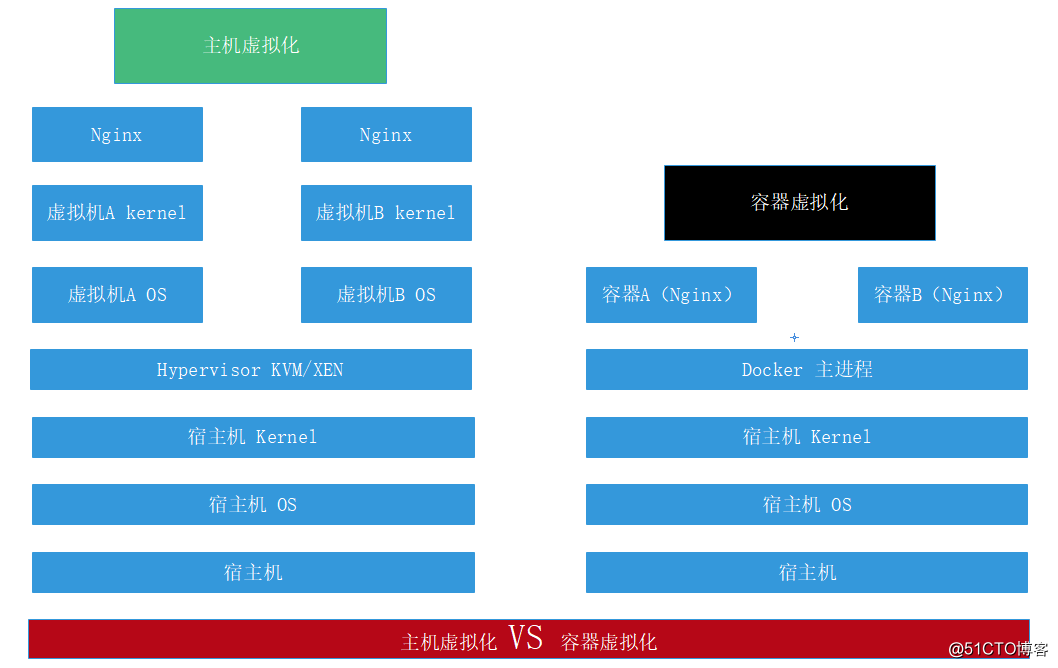
由于科技技术的高度发展,在物理机服务器性能越来越高的今天,很多生产环境中使用的服务器,由于没有很多的用户访问,而导致性能过剩。而生产中又需要在多台服务器上部署业务。如果总是购买物理服务器,显然会造成经济成本大大增加,这时候就需要虚拟化技术来完成物理机性能的合理分配。
虚拟化技术在上世纪已经诞生,但是上世纪的物理机性能显然无法提供大规模的虚拟化环境,所以没有流行开来。最现如今虚拟化技术已经以势不可挡之势步入各个公司的生产环境中,不经能够大幅节约成本,还可以提高 IT 敏捷性、灵活性和可扩展性。
虚拟机技术中最先诞生的是主机级虚拟化,主机级虚拟化典型的代表便是KVM/XEN,它可以在物理机之上部署多台虚拟机同时运行,而各个虚拟机之间互不影响,即使某一台服务器由于各种原因“寿终正寝”之后,也不会影响到其它虚拟机和宿主机的正常运行。但是这种技术的缺点也很明显,每个虚拟机都有单独的内核空间,对系统的资源消耗相当大。
而容器虚拟化技术则解决了这一难题,它不需要在运行是安装一个庞大的内核,而只是将运行某个服务的环境集成在一个容器中,大大减少了对系统资源的消耗,并且有“秒级”的自愈功能,一个容器宕机之后可立即弃之,随后头也不回的重启一个容器接替它的位置,当然此功能需要运维人员对容器进行很好的优化才能实现。
linux namespace的组成
虽然容器虚拟化技术有种种好处,但是在宿主机之上运行N个容器,如何让这些容器之间的运行稳定,且各个容器之间环境互不影响,就成为了迫在眉睫的问题。每个容器占用系统资源较少,可麻雀虽少,也得五脏俱全。它也得具备主机名,网卡,用户等资源。为了解决此各个容器之间不冲突,就得使用到Linux Namespace
namespace 是 Linux 系统的底层概念,在内核层实现,即有一些不同类型的命名空间被部署在内核之中,各个docker容器运行时共享一个宿主机的内核。与此同时,每个宿主机之间要相互隔离的运行,并意识不到别的容器的存在,以为自己就是这个“世界”的主宰,那么一个容器必须有如下几类namespace
IPC Namespace:保证容器内的进程间能够相互通信,但是不能跨容器访问其他容器的数据
MNT Namespace:独立的根文件系统,以实现在容器里面启动服务并且构建出容器的运行环境
[root@node1 ~]#docker exec -it k1 bash
[root@3864270aea99 /]# ls /
#独立根文件系统
anaconda-post.log dev home lib64 mnt proc run srv tmp var
bin etc lib media opt root sbin sys usrUTS Namespace:用于系统标识,包含主机名和域名,用来唯一标识独立于宿主机系统和运行在其上的其他容器
[root@node1 ~]#docker exec -it k1 bash
[root@3864270aea99 /]# hostname
#主机名
3864270aea99
[root@3864270aea99 /]# uname -a
#内核版本,注意此处也是宿主机的内核版本
Linux 3864270aea99 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/LinuxPID Namespace:每个容器出有一个PID为1的进程,用来管理进程的创建和回收
[root@node1 ~]#docker exec -it k1 bash
[root@3864270aea99 /]# top
top - 03:13:35 up 2:17, 0 users, load average: 0.00, 0.03, 0.06
Tasks: 3 total, 1 running, 2 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995896 total, 146980 free, 216372 used, 632544 buff/cache
KiB Swap: 2097148 total, 2096884 free, 264 used. 558252 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
#容器的PID
1 root 20 0 11820 1680 1408 S 0.0 0.2 0:00.02 bash
44 root 20 0 11820 1888 1508 S 0.0 0.2 0:00.02 bash
57 root 20 0 56192 2008 1468 R 0.0 0.2 0:00.02 topNet Namespace:网络是容器中非常重要的一环每个容器都类似于虚拟机一样有自己的网卡、监听端口、TCP/IP 协议栈等,在运行容器时会自动生成一些防火墙规则用于和外界通讯。
容器内网卡逻辑架构图
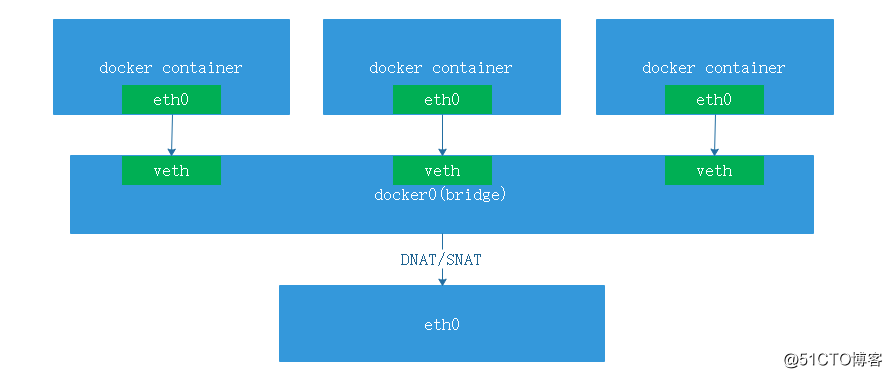
查看容器内网卡
[root@3864270aea99 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 4190 bytes 39525574 (37.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3233 bytes 179563 (175.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0查看宿主机的上容器网卡的映射
[root@node1 ~]#ifconfig
veth4ce4103: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::c061:9aff:fe02:ce89 prefixlen 64 scopeid 0x20<link>
ether c2:61:9a:02:ce:89 txqueuelen 0 (Ethernet)
RX packets 3234 bytes 179605 (175.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4191 bytes 39525616 (37.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0查看自动生成的防火墙规则
[root@node1 ~]#iptables -vnL
Chain INPUT (policy ACCEPT 7764 packets, 77M bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
7409 40M DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0
7409 40M DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0
4179 39M ACCEPT all -- * docker0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
0 0 DOCKER all -- * docker0 0.0.0.0/0 0.0.0.0/0
3230 134K ACCEPT all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 docker0 0.0.0.0/0 0.0.0.0/0 User Namespace: 每个容器中都要单独的用户和组,和宿主机并不冲突,只是会把用户的作用范围限制在每个容器内
root@node1 ~]#docker exec -it k1 bash
[root@3864270aea99 /]# cat /etc/passwd
#每个容器中都有相应的用户
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin容器资源限制
在使用VMware创建虚拟机时,每个虚拟在安装和启动之前都会有这么一个界面来设置这个虚拟机之前,可以设置此虚拟机占用宿主机的内存,CPU,网卡等硬件设备的大小。
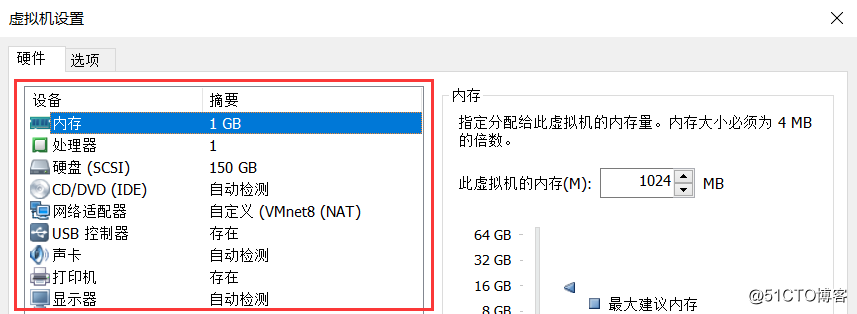
容器亦是如此,虽然一个容器内的程序可以在其“领地”内行使对所有资源使用权利,但还是要对其做资源限制,容器亦是如此,如果不对容器使用的资源做任何限制,当容器内的资源不够时,容器便会侵蚀宿主机的资源,直至把宿主机的资源占完,成为这台物理机新的“主人”。
对容器的资源限制还可以提高对于宿主机的安全性,假设一个容器出现漏洞被别人拿到控制权后,资源限制可使其只能够使用这个容器中的资源,而无法对宿主机的资源形成危害。
那么为了避免物理机的“主人”被其它容器取而代之,就需要一些手段来限制,主要使用的技术便是Linux control groups,简称Linux Cgroups。它的主要作用是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。此外,还能够对进程进行优先级设置,以及将进程挂起和恢复等操作。
在容器使用的过程中,一旦内存超过期初给它分配了空间,那么内核将主动杀死这个容器所使用的进程。
此功能在内核层默认已经开启。
[root@node1 ~]#cat /boot/config-3.10.0-957.el7.x86_64 | grep CGROUP
#验证系统的Cgroups是否开启
CONFIG_CGROUPS=y
#CONFIG_CGROUP_DEBUG is not set
CONFIG_CGROUP_FREEZER=y
CONFIG_CGROUP_PIDS=y
CONFIG_CGROUP_DEVICE=y
CONFIG_CGROUP_CPUACCT=y
CONFIG_CGROUP_HUGETLB=y
CONFIG_CGROUP_PERF=y
CONFIG_CGROUP_SCHED=y
CONFIG_BLK_CGROUP=y
#CONFIG_DEBUG_BLK_CGROUP is not set
CONFIG_NETFILTER_XT_MATCH_CGROUP=m
CONFIG_NET_CLS_CGROUP=y
CONFIG_NETPRIO_CGROUP=yCgroup的具体实现
[root@node1 ~]#ll /sys/fs/cgroup/
总用量 0
drwxr-xr-x 2 root root 0 7月 3 21:02 blkio
lrwxrwxrwx 1 root root 11 7月 3 21:02 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 7月 3 21:02 cpuacct -> cpu,cpuacct
drwxr-xr-x 2 root root 0 7月 3 21:02 cpu,cpuacct
drwxr-xr-x 2 root root 0 7月 3 21:02 cpuset
drwxr-xr-x 4 root root 0 7月 3 21:02 devices
drwxr-xr-x 2 root root 0 7月 3 21:02 freezer
drwxr-xr-x 2 root root 0 7月 3 21:02 hugetlb
drwxr-xr-x 2 root root 0 7月 3 21:02 memory
lrwxrwxrwx 1 root root 16 7月 3 21:02 net_cls -> net_cls,net_prio
drwxr-xr-x 2 root root 0 7月 3 21:02 net_cls,net_prio
lrwxrwxrwx 1 root root 16 7月 3 21:02 net_prio -> net_cls,net_prio
drwxr-xr-x 2 root root 0 7月 3 21:02 perf_event
drwxr-xr-x 2 root root 0 7月 3 21:02 pids
drwxr-xr-x 4 root root 0 7月 3 21:02 systemdblkio:块设备 IO 限制
cpu:使用调度程序为 cgroup 任务提供 cpu 的访问
cpuacct:产生 cgroup 任务的 cpu 资源报告
cpuset:如果是多核心的 cpu,这个子系统会为 cgroup 任务分配单独的 cpu 和内存
devices:允许或拒绝 cgroup 任务对设备的访问
freezer:暂停和恢复 cgroup 任务。
memory:设置每个 cgroup 的内存限制以及产生内存资源报告
ns:命名空间子系统
perf_event:增加了对每 group 的监测跟踪的能力,可以监测属于某个特定的 group 的所 有线程以及运行在特定 CPU 上的线程
有了这些就具备了容器的基础运行环境,但是还需要有相应的容器创建与删除的管理工具、以及怎么样把容器运行起来、容器数据怎么处理、怎么进行启动与关闭等问题需要解决,于是容器管理技术便应运而生。
容器管理工具
容器的管理技术早期诞生的有 Linux Container(LXC),它可以提供轻量级的虚拟化来隔离各个容器之间的通讯。但是LXC启动容器依赖于模板,而模板需要一步步创构建文件系统、准备基础目录及可执行程序等一堆步骤才可使容器运行,另外后期代码升级也需要重新从头构建模板。
这就与容器的理念背道而驰,容器本身是为了简化操作而诞生的,如此大费周折的启动一个容器,显然不是生产环境中所期望的。后来docker的横空出世,便以势不可挡之势侵占了大部分LXC的市场。
然而并不是说docker启动容器时不需要模板,docker也是需要的。只是它把这些模板包装成为一个个的镜像。而docker的镜像即可以保存在一个公共的地方供所有人共享使用,也可以保存在本地的私有仓库中使用。
当我们在使用镜像时,只要把别人制作的镜像下载下来就可以使用。如果我们觉得别人的配置不符合生产环境中的需求,我们还可以在别人制作的镜像基础之上做自定义配置,配置完成后保存为自己的一个镜像。如此形成了前人栽树后人乘凉的良性循环,这也是容器技术越来越火爆的原因之一
docker官方镜像仓库地址:https://hub.docker.com/
docker 的组成
docker 主机(Host):一个物理机或虚拟机,用于运行 docker 服务进程和容器。
docker 服务端(Server):docker 守护进程,运行 docker 容器。
docker 客户端(Client):客户端使用 docker 命令或其他工具调用 docker API。
docker 仓库(Registry): 保存镜像的仓库,类似于 git 或 svn 这样的版本控制系
docker 镜像(Images):镜像可以理解为创建实例使用的模板。
docker 容器(Container): 容器是从镜像生成对外提供服务的一个或一组服务。
了解了上述这些原理后,基本上对docker有了一个初步的认识,下面说一下如果安装docker,以及如何在docker中运行并管理一个容器。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK