

分表后需要注意的二三事 - crossoverJie - 博客园
source link: https://www.cnblogs.com/crossoverJie/p/11013769.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本篇是上一篇《一次分表踩坑实践的探讨》,所以还没看过的朋友建议先看上文。
还是先来简单回顾下上次提到了哪些内容:
- 分表策略:哈希、时间归档等。
- 分表字段的选择。
- 数据迁移方案。
而本篇文章的背景是在我们上线这段时间遇到的一些问题并尝试解决的方案。
之前提到在分表应用上线前我们需要将原有表的数据迁移到新表中,这样才能保证业务不受影响。
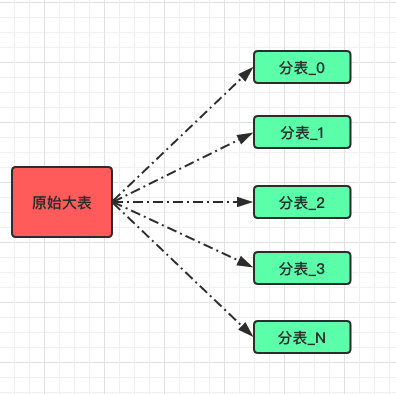
所以我们单独写了一个迁移应用,它负责将大表中的数据迁移到 64 张分表,而再迁移过程中产生的数据毕竟是少数,最后在上线当晚再次迁移过去即可。
一切想的很美好,当这个应用上线后却发现没这么简单。
数据库负载升高
首先第一个问题是数据库自己就顶不住了,在我们上这个迁移程序之前数据库的压力本身就比较大,这个应用一上去就成了最后一根稻草。
最后导致的结果是:所有连接了数据库的程序大部分的操作都出现超时,获取不到数据库连接等一系列的异常。
最后没办法我们只能把这个应用放到凌晨执行,但其实后面观察发现依然不行。
虽说凌晨的业务量下降,但依然有少部分的请求过来,也会出现各种数据库异常。
再一个是迁移程序的效率也非常低下,按照这样是速度,我们预估了一下迁移时间,大约需要 10 几天才能把三张最大的表(3、4亿的数据)迁移到分表中。
于是我们换了一个方案,将这个迁移程序在从库中运行,最后再用运维的方法将分表直接导入进主库。
因为从库的压力要比主库小很多,对业务的影响很小,同时迁移的效率也要快很多。
即便是这样也花了一晚上+一个白天的时间才将一张 1亿的数据迁移完成,但是业务上的压力越来越大,数据量再不断新增,这个效率依然不够。
最终没办法只有想一个不迁移数据的方案,但是新产生的数据还是往分表里写,至少保证大表的数据不再新增。
但这样对于以前的数据咋办呢?总不能不让看了吧。
其实对于数据的操作无非就分为增删改查,就这四种操作来看看如何兼容。
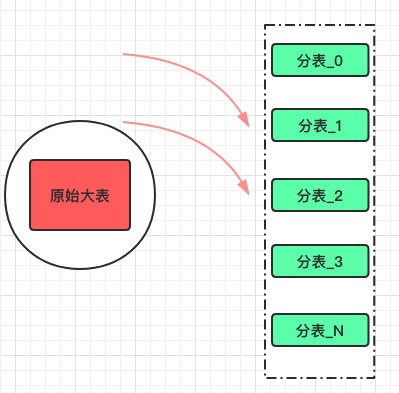
新增最简单,所有的数据根据分表规则直接写入新表,这样可以保证老表的数据不再新增。
删除就要比新增稍微复杂一些,比如用户想要删除他个人产生的一条信息(比如说是订单数据),有可能这个数据在新表也可能在老表。
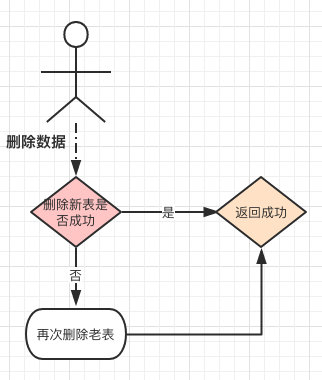
所以删除时优先删除新表(毕竟新产生的数据访问的频次越高),如果删除失败再从老表删除一次。
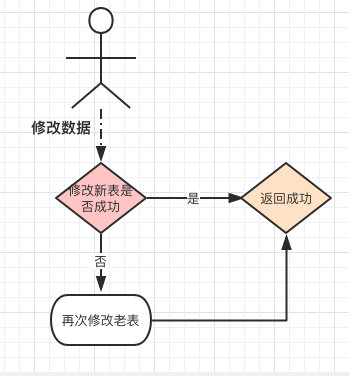
而修改同理,同样的会不确定数据存在于哪里,所以先要修改新表,失败后再次修改老表。
查询相对就要复杂一些了,因为这些大表的数据大部分都是存放一个用户产生的多条记录(比如一个用户的订单信息)。
这时在页面上通常都会有分页,并且按照时间进行排序。
麻烦的地方就出在这里:既然是要分页那就有可能出现要查询一部分分表数据和原来的大表数据做组合。
所以这里的查询其实分为三种情况。
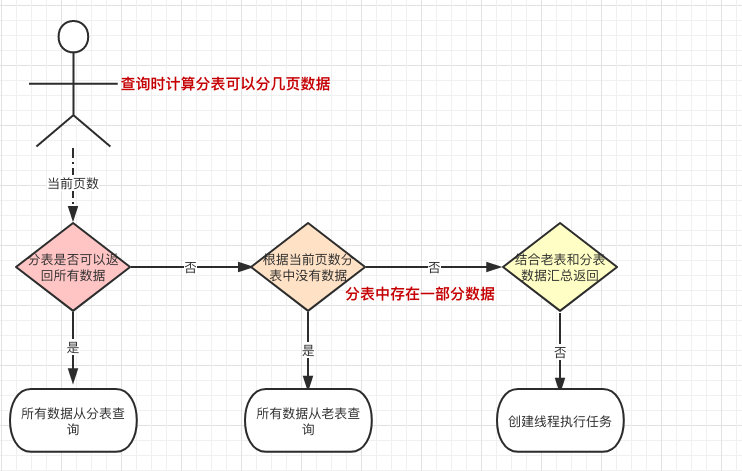
- 首先查询的时候要计算这个用户所在分表中的数据可以分为几页。
- 第一步首先判断当前页是否可以在分表中全部获取,如果可以则直接从分表中取出数据返回(假设分页中总共可以查询 2 页数据,当前为第 1 页,那就全部取分表数据)。
- 如果不可以就要判断当前页数在分表中是否取不到任何一条数据,如果是则直接取老表数据(比如现在要取第 5 页的数据,分表中一共才只有 2 页数据,所以第 5 页数据只能全部从老表中获取)。
- 但如果分表和老表都存在一部分数据时,则需要同时取两张表然后做一个汇总再返回。
这种逻辑只适用于根据分表字段进行查询分页的前提下
我想肯定会有朋友提出这样是否会有性能问题?
同时如果在计算分表分页数量时出现并发写入的情况,导致分页数量不准从而对后续的查询出现影响该怎么处理?
首先第一个性能问题:
其实这个要看怎么取舍,为了这样的兼容目的其实会比常规查询多出几个步骤:
- 判断当前页是否可以在分表中查询。
- 当新老表中都有数据时候需要额外多查询一张大表。
第一个判断逻辑其实是在内存中计算,这个损耗我觉得完全可以忽略不计。
至于第二步确实会有损耗,毕竟多查了一张表。
但在分表之前所有的数据都是从老表中获取的,当时的业务也没有出现问题;现在多的只是查询分表而已,但分表的数据量肯定要比大表小的多,而且有索引,所以这个效率也不会慢多少。
而且根据局部性原理及用户的使用习惯来看,老表中的数据很少会去查询,随着时间的推移所有的数据肯定都会从分表中获取,逐渐老表就会成为历史表。
而第二个并发带来的问题我觉得影响也不大,一定要这个分页准的前提肯定得是加锁了,但为了这样一个不痒的小问题却带来性能的下降,我觉得是不划算的。
而且后续我们也可以慢慢的将老表的数据迁移到新表,这样就可以完全去掉这个兼容逻辑了,所有的数据都从分表中获取。
还是之前那句话,这里的各种操作、方法不适合所有人,毕竟脱离场景都是耍牛氓。
比如分表搞的早,业务上允许一定的时间将数据迁移到分表那就不会有这次的兼容处理。
甚至一开始业务规划合理、团队架构师看的长远,一来就将关键数据分表存储那根本就不会有数据迁移这个流程(大厂有经验的团队可能,小公司小作坊都得靠自己摸索)。
这段期间也被数据库折腾惨了,数据库是最后一根稻草果然也不是瞎说的。
你的点赞与分享是对我最大的支持
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK