

Linux SRv6实战 (第三篇) 多云环境下Overlay(VPP) 和Underlay整合测试
source link: https://www.sdnlab.com/23218.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
李嘉明 思科系统工程师、苏远超 思科首席工程师、赵勇 思科顾问工程师
摘要:本文基于Linux上开源的 VPP软件以及Cisco NCS5500路由器,验证了通过SRv6实现多云环境下Overlay和Underlay整合、一体化调度以及快速收敛功能。

一、VPP简介
关于SRv6原理及Linux SRv6常见功能(VPN、流量工程、服务链)的实现,请参见本系列文章的第一篇和第二篇,这里不再赘述。
VPP全称Vector Packet Processing(矢量数据包处理),最早是Cisco 于 2002年开发的商用代码。之后在2016年Linux基金会创建FD.io开源项目,Cisco将VPP代码的开源版本加入该项目,目前已成为该项目的核心。现在一般来讲的VPP特指 FD.io VPP,即Linux基金会发起的开源项目。
这个项目在通用硬件平台上提供了具有灵活性、可扩展强、组件化等特点的高性能IO服务框架。该框架支持高吞吐量、低延迟、高资源利用率的IO服务,并可适用于多种硬件架构(x86/ARM/PowerPC)以及各种部署环境(裸机/VM/容器)。
VPP底层使用了Intel数据平面开发工具包(DPDK:data plane development kit’s)的轮询模式驱动程序(PMD:poll mode drivers)和环形缓冲区库,旨在通过减少数据流/转发表缓存的未命中数来增加转发平面吞吐量。
VPP高度模块化,允许在不更改底层代码库的情况下轻松“插入”新的Graph Node(图节点)。这使开发人员可以通过不同的转发图轻松构建任意数量的数据包处理解决方案,它通过Graph Node(图节点)串联起来处理数据包,并可以通过插件的形式引入新的图节点或者重新排列数据包的图节点顺序,或者根据硬件情况通过某个节点直接连接硬件进行加速,因此可以用于构建任何类型的数据包处理应用。比如负载均衡、防火墙、IDS、主机栈等。目前业界已经有客户选用VPP来实现自己的数据包处理应用。
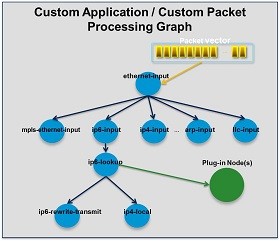
上图是VPP的自定义应用的处理图,除了VPP对一个包的默认处理流程外(图中蓝色的节点),可以在其中任意一个一个节点后,添加自定义的图节点,并在此实现自定义的操作或者扩展功能。

VPP目前已经支持了很多的功能,具体如图2所示,很多功能还可以通过第三方开源软件+插件的方式进行扩展,比如动态路由协议OSPF/BGP等的支持。
VPP对于SRv6有着非常好的支持,并且提供高性能。
二、多云环境下Overlay和Underlay的整合问题
一直以来,在多云环境下要实现overlay和underlay整合,都不太容易。一是如何将Overlay的SLA信息映射到Underlay;二是Underlay能否以足够细的颗粒来满足Overlay基于流的SLA诉求;三是如何快速实现两者的协同和交接,因为这通常涉及两个不同的部门。
常见的方案有以下两种:

方案一:多云之间之间通过VXLAN打通,Underlay就是纯粹的透传,对设备要求低。这种方案简单易行,不涉及到两个部门管理边界的问题;但缺点也很明显,对于需要Underlay提供SLA或多云间流量工程的情况(例如要求流量从Overlay网关C1->C2->C3),实现起来很困难。
方案二:每个云本地通过IP+DSCP的方式交接给Underlay的SRTE PE,PE设备需要支持基于流的自动引流功能。这种方案通过SR-TE基于流的自动引流实现了精细的映射,同时SR-TE自身的特性也保证了方案的可扩展性;需要指出的是,这种方案管理边界虽然清晰,但需要Overlay侧把IP+DSCP对应的SLA信息实时同步给Underlay侧;另外对Underlay设备要求较高,可能面临着软硬件升级的问题。
本文将讨论并验证第三种方案:基于SRv6,在Overlay网关上利用VPP及Underlay的SLA信息生成SRH(即发起SR-TE),这样可以充分利用前面谈到的方案1和方案2的优点:由于Underlay只需要执行简单的END操作,不需要作为基于流的SR-TE头端,因此无须对Underlay做大的改造,容易在现有网络中部署;Overlay和Underlay交互的是SLA路径信息(这里可以利用Flex-Algo功能做进一步简化),边界清晰。同时最重要的是,本方案是把Overlay的SLA交给应用来负责(通过编程Overlay网关上的SRH),因此可以提供高度的灵活性。
本方案用到的关键组件是VPP。如图2所示,VPP原生已经支持了SRv6,包括常见的SRv6操作,下面我们简单的对比一下目前Linux上几种SRv6实现方式:
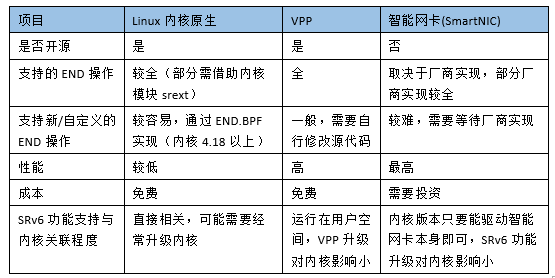
如上表所示,VPP是目前对SRv6支持最完备的开源项目。在性能方面,VPP同样出色,比Linux 内核原生支持的SRv6吞吐能力要超出很多;成本方面相比智能网卡则有着巨大优势。目前很多开源项目以及商业项目也选用了VPP,其整体的稳定性和性能得到了广泛的验证。
因此本次实验中,我们选用VPP作为虚拟SRv6路由器,用于模拟需要支持IPv6、高性能和高灵活性的Host Overlay网关。VPP模拟的SRv6 Overlay网关结合Cisco NCS5500模拟的SRv6 Underlay,验证了通过SRv6实现Overlay和Underlay的无缝/高性能整合以及一体化调度的强大能力。
三、实验准备工作
3.1 拓扑说明
1.总体架构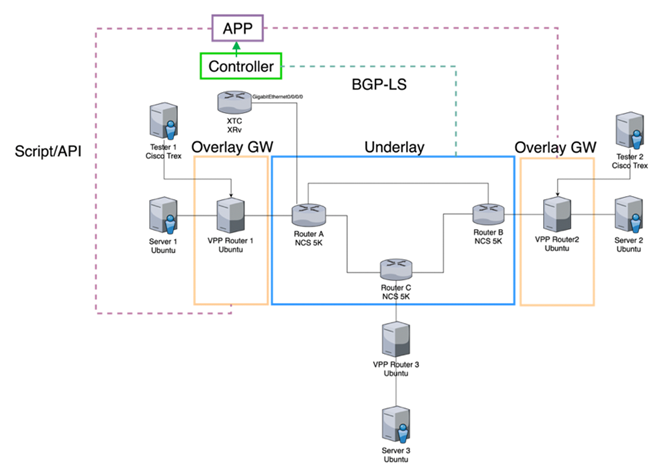
本次实验的总体架构如图所示,Underlay部分主要由三台Cisco NCS5500构成,组成一个环状拓扑结构,负责IPv6报文的转发以及执行简单的END操作。Overlay网关由VPP实现,VPP作为Overlay的网关,负责将测试仪(这里我们使用开源的Cisco Trex)以及服务器的IPv4流量进行封装,发往对端,以及执行End.DX4操作(去掉IPv6报头,转发所封装的IPv4数据包)。
控制器Cisco XTC通过BGP-LS得到全网拓扑信息,计算出最优路径,上层控制器应用(自己编写的示例程序)通过Rest API从控制器拿到最优路径信息,计算出新的SRv6 Policy,并通过VPP API 下发给Overlay网关设备,实现路径的实时更新。
2.主要软硬件列表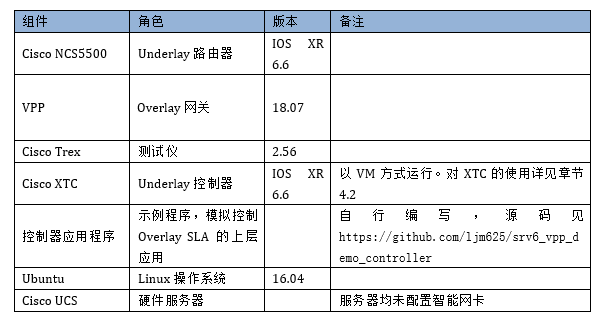
3.详细拓扑图
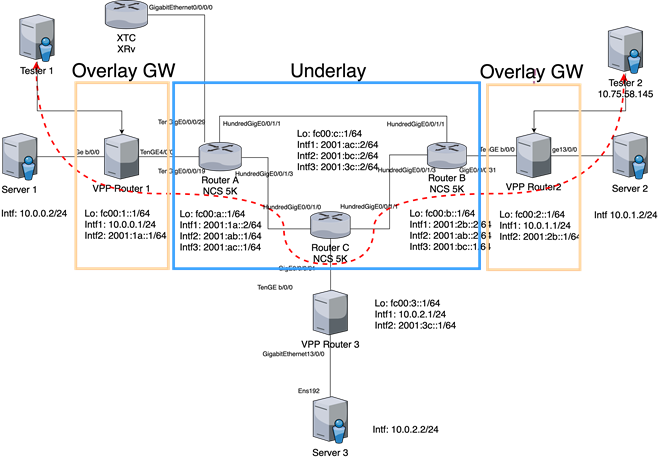
本次实验的详细拓扑如上图,中间为3台Cisco NCS5500路由器,构成了环形结构(Router A/B/C)。3台VPP 路由器(Overlay网关)均安装在ESXi环境下,通过PCI直通分别与每台NCS5500直连。图中所有的蓝色链路均为物理连接,红色链路为通过vSwitch虚拟连接的链路。
三台服务器Server1/Server2/Server3通过vSwitch和VPP路由器分别连接,测试仪1和2为思科开源的Trex软件,安装在Ubuntu虚拟机上,通过PCI直通和VPP路由器1与2直连。
XTC控制器为IOS XRv的虚拟机,通过PCI直通连接到Router A。
三台NCS5500之间运行纯IPv6。VPP路由器为IPv4+IPv6双栈,VPP和服务器/测试仪通过IPv4连接,和NCS5500通过IPv6连接。
测试仪1/2为基于Ubuntu 16.04安装的Cisco Trex开源测试仪软件。该测试软件有2种模式,Stateless(无状态)和Advanced Stateful Mode(高级带状态模式),在这里我们使用的是后者,在后文中我们会详细说明。
3.2 安装VPP
版本信息如图:

安装完成之后,执行:
如果能显示出vpp服务的详情,则代表安装完成。
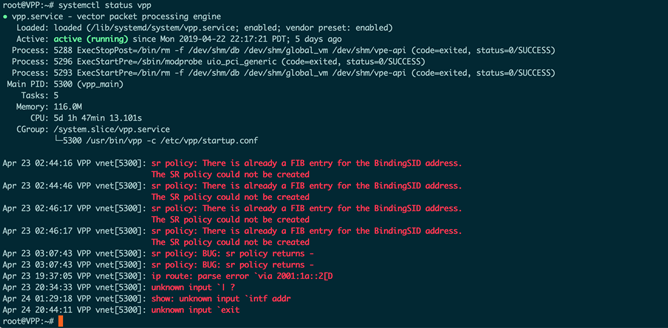
3.3 配置VPP
首先需要列出机器连接的PCI网络设备的ID:
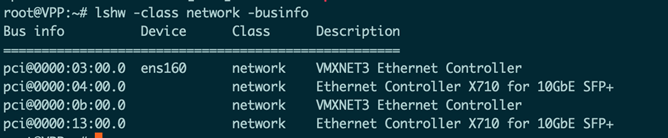
如上图,这个是在VPP1上列出的结果,其中包括4块网卡,可以看到2块网卡是VMXNET3的,即VMWare虚拟机的虚拟网卡,剩下2块网卡则是PCI直通到虚拟机的网卡,为X710网卡的2个端口。在这里我们把后3块网卡交给VPP管理(VPP管理的网卡,不能再被系统使用,因此请预留一个管理口,如图的ens160给系统使用,以及SSH访问等)。
在这里我们记录下来后3块网卡的PCI id,分别为0000:04:00.0,0000:0b:00.0以及0000:13:00.0。
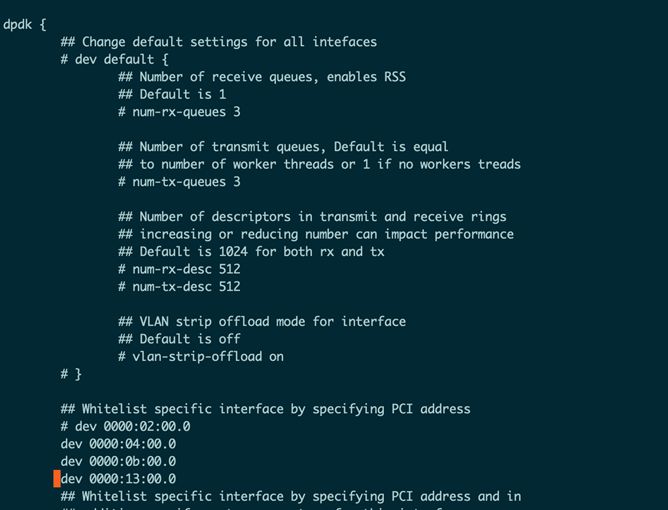
接着修改vpp的配置文件:
需要修改里面的dpdk部分:
保存文件,重启VPP:

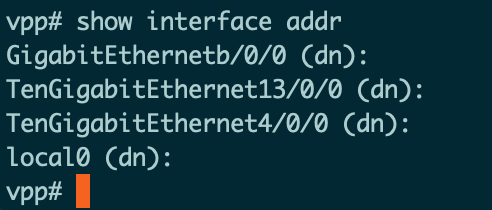
可以看到刚刚添加的几个Interface,说明配置成功:
0000:04:00.0 -> TenGigabitEthernet4/0/0(”04:00.0”所映射端口的编号”4/0/0”)
0000:0b:00.0 -> GigabitEthernetb/0/0(”0b:00.0”所映射端口的编号”b/0/0”)
0000:13:00.0 -> TenGigabitEthernet13/0/0(”13:00.0”所映射端口的编号”13/0/0”)
VPP在每次重启之后,之前的配置就会丢失,因为VPP在设计之初就是希望其他程序通过API与其进行交互。在本次实验中我们通过Day0配置文件来保存配置(读者也可以通过插件集成到VPP中实现类似功能,这里不再赘述)。
接着进行VPP的初始配置,VPP的初始配置由/etc/vpp/startup.conf 里面的配置决定:
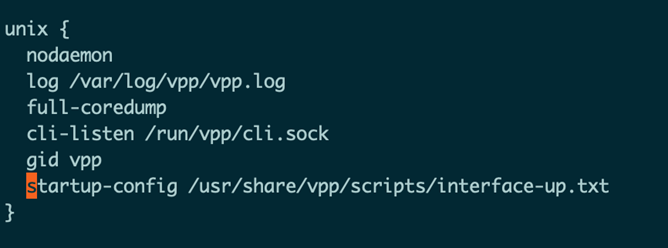
添加一行:
在这里我们定义的config文件为/usr/share/vpp/scripts/interface-up.txt。
接下来编辑interface-up.txt:
完成之后重启vpp:
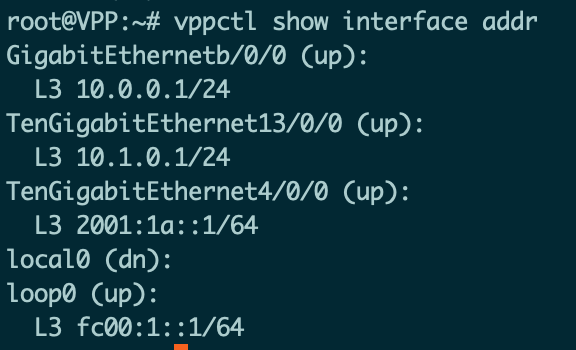
可以看到已经完成了day0的接口、 IP和路由配置。
3.4 配置Cisco NCS5500
Cisco NCS5500需要启用SRv6功能。在Cisco NCS5500启用SRv6功能并分配Locator之后,会自动获得End操作对应的Segment,这点和Linux不一样。
需要配置:
以上配置启用SRv6功能,并配置SRv6的locator。如果配置之后SRv6没有生效,则需要执行:
该命令会重启Cisco NCS5500,并启用新配置的hw-module。
配置之后,可以通过下面的命令查看locator以及Segment:

可以看到Locator已经是UP状态。

自动分配与End操作对应的Segment为fc00:c:1:0:1::
我们在三台Cisco NCS5500路由器上均进行该操作,对应的End操作Segment分别为:

3.5 配置控制器应用程序运行环境
控制器应用程序为Python实现的示例程序,可以安装在任意平台,这里以ubuntu为例。
至此安装环境完成。
接着获取控制器的代码:
需要修改配置文件config.json:
按需修改以上配置文件,预置值为本实验环境的配置。
四、实验流程
4.1 Overlay和Underlay整合下的性能测试
在这个测试里,我们将测试具有三个Segment的SRv6 Policy的端到端转发性能。
拓扑结构如图所示,本次试验使用2台Cisco开源测试仪软件Trex。Trex使用DPDK作为底层驱动,可以达到很高的性能。Trex分别部署在Tester1和Tester2,本次测试从Tester2打流到Tester1,并在VPP2上配置了一个包含三个Segment的SRv6 Policy,其中的2个Segment为NCS5500。Tester2发送594B的UDP小包流量。
首先重新配置VPP2:
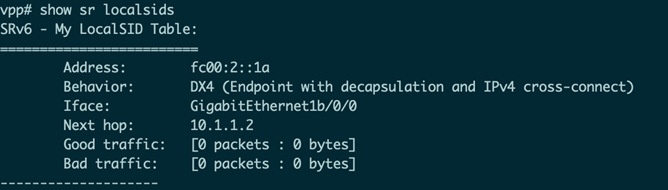
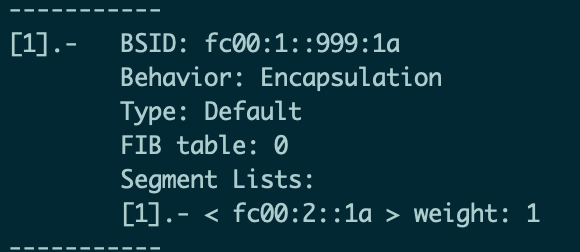
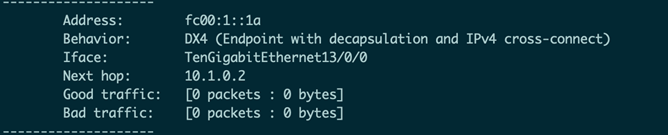
接着也需要在VPP1进行配置:
Tester2 配置: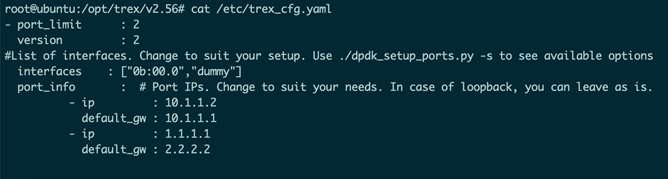
上图为Trex的配置文件,其中配置了Trex使用的网卡端口(通过PCI ID指定,如图中interfaces变量)以及网卡所配置的IP,网关等(如图port_info下的信息)。在配置文件中,interfaces变量对应的网卡端口数组中,第1、3、5个端口只能作为发送端(如上图的”0b:00:0”),数组第2、4、6个位置的端口只能作为接收端(如上图的dummy,dummy相当于一个假的接口),可以看到Tester2网卡被配置为发端。
Tester1 配置: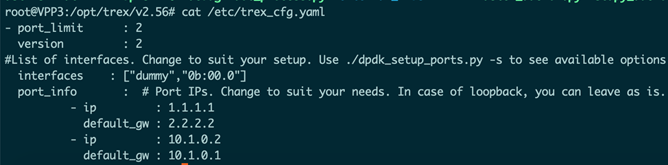
上图为Tester1的配置文件,可以看到和Tester2的区别为,Tester1的数组第一位为dummy(即为空),第二位为0b:00:0,即Tester1的网卡端口被配置为接收端。
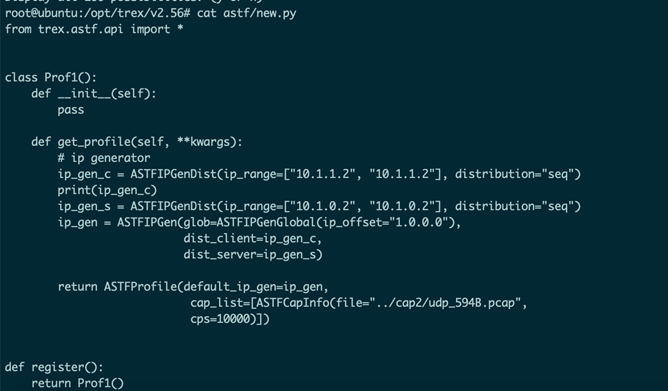
上图是测试仪发包的对应代码,主要核心部分在发送的包为594B的UDP包,并在每次执行时发送10000个所定义的UDP包。
首先使用测试仪ping对端:
可以Ping通后,开始正式打流:
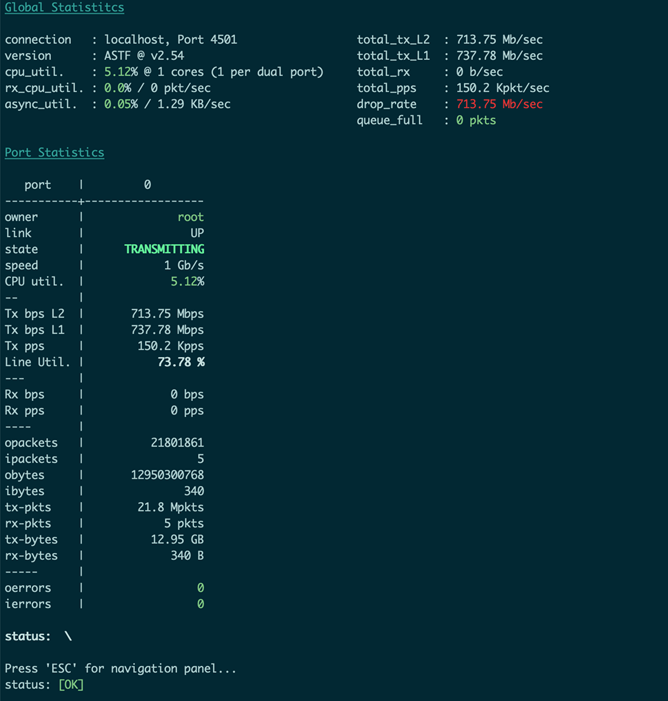
上图为发端的状态,可以看到不断在根据我们定义的UDP数据包打流,流量转发速率为710Mbps 左右,PPS为150.2K。
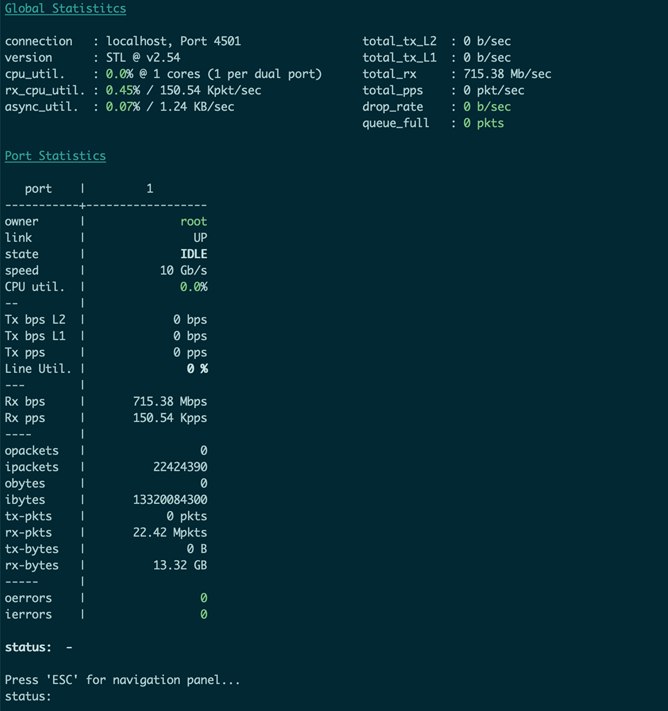
上图为收端的数据,可以看到接收端(Rx)的速率为715Mbps左右,PPS为150.5K左右,和发送端速率一致,证明该速率可以正常转发,无丢包。
4.2 控制器应用程序实现动态路径调整和策略下发
在上一个测试中,我们测试了VPP+NCS5500环境下具有三个Segment的SRv6 Policy转发性能,表现符合预期,在这一节中,我们通过Python实现了一个示例控制器应用程序,通过调用XTC控制器的Rest API来获取算路信息,并动态的调整SRv6 Policy,实现路径的调整。
控制器应用程序使用Python编写,具体的代码在:https://github.com/ljm625/srv6_vpp_demo_controller
免责声明:本控制器应用程序代码只是用于示例说明,并不代表Cisco公司正式的实现方式,也不代表实践中仅限于这种实现方式。
前面在安装部分,我们已经解析了配置文件,下面简单解析一下控制器应用程序:
上图为控制器应用程序流程图。
控制器应用程序主要分为三个部分:
1.主循环
主要进行循环,通过调用PathFinder,检测算路结果是否发生变化,如果发生变化,调用VPPController模块生成新的SRv6 Policy并下发给VPP设备。
2.PathFinder类
主要通过Rest API,调用XTC控制器,获取算路结果,并返回算路结果供使用。
重要说明:在写本文时,Cisco XTC尚不支持直接计算SRv6 Policy,只支持计算SR-MPLS Policy,因此我们实际上是使用了XTC的SR原生算法,计算出基于相同优化目标和约束条件下的SR-MPLS Policy的Segment列表,但不下发(dry-run),然后用下面谈到的VPPController类构造相应的SRv6 Policy并下发。
3.VPPController_CLI类
这个类其实还有其他实现方法,这里使用的是CLI方式。当路径被计算出来之后,它会根据给出的节点生成对应的SRv6 Policy,并通过CLI下发给VPP路由器。
接下来我们启动控制器应用程序,执行:

控制器应用启动之后,由于没有之前算路结果的记录,默认会自动进行算路和下发 SRv6 Policy给VPP1。
Underlay控制器XTC得出的从Router A去往Router B的最低延迟算路结果为Router A->Router C->Router B。
控制器应用程序下发给VPP1的SRv6 Policy为:
表示去往VPP2的SRv6 Policy,先去往Router C的Segment,再去往的Router B的Segment,最后去往VPP2,和Underlay算路结果一致。
控制器应用程序还计算了从Router A去往Router C的最低延迟路径。
上图为VPP1上去往VPP2/VPP3的SRv6 Policy,可以看到控制器应用程序已经动态下发了SRv6 Policy路径。
现在开始从10.0.0.2 ping 10.0.1.2。在某个时刻,我们在Router A上手工配置延迟(在performance-measurement子模式下)并通过ISIS进行泛洪(现网情况下可以通过SR 性能测量功能或者探针获得实延迟迟),使得最优路径发生变化。

如上图,在Router A上修改配置,将2条链路的延迟做了对调。

再次查看控制器应用程序,可以看到控制器应用程序检测到了路径的变化,重新进行了算路。
如上图,得出的从Router A去往Router B的最低延迟算路结果为Router A->Router B 。
对应的SRv6 Policy为:
此时再去VPP1上查看SRv6 Policy:
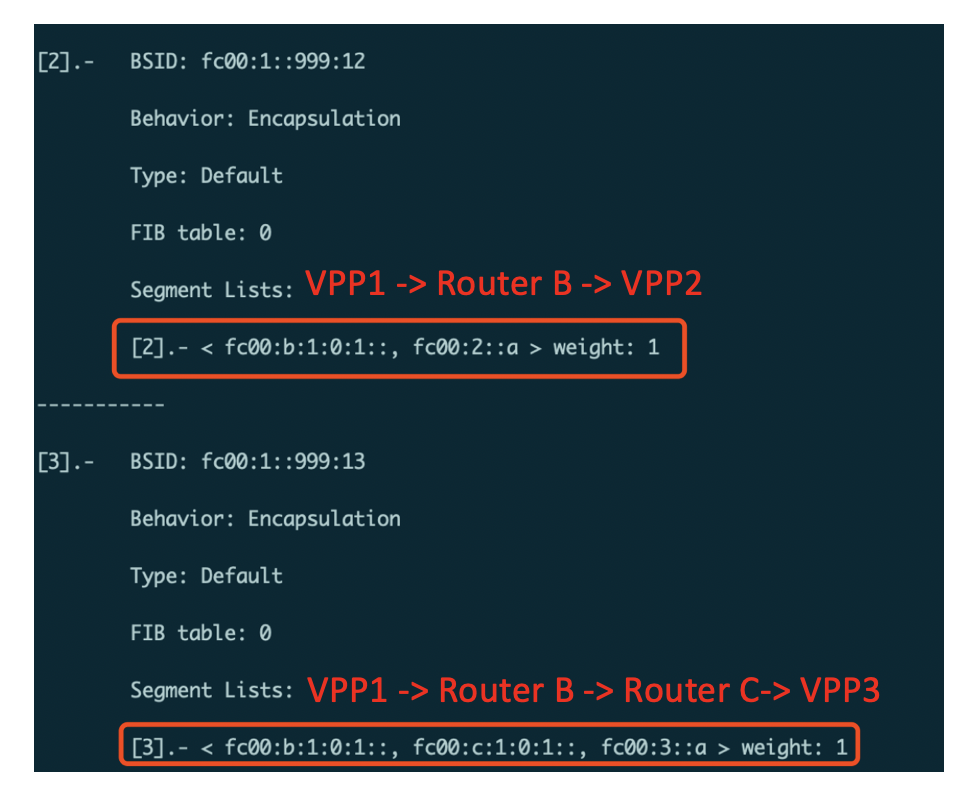
如上图红框部分,VPP1上去往VPP2/VPP3的SRv6 Policy已经由控制器应用程序自动进行了更新。

查看ping界面,在SRv6 Policy切换过程中没有出现丢包。
4.3 TI-LFA保护测试
在上一个测试中,我们使用控制器应用程序来实现了路径的动态计算,在这个实验中,我们将利用Cisco NCS5500的TI-LFA功能,测试TI-LFA链路保护效果。需要注意的是,之前的实验并没有开启TI-LFA。
在Router A/Router B/Router C上,在ISIS下对所有链路启用TI-LFA链路保护。相关配置如下所示(仅显示TI-LFA相关部分):
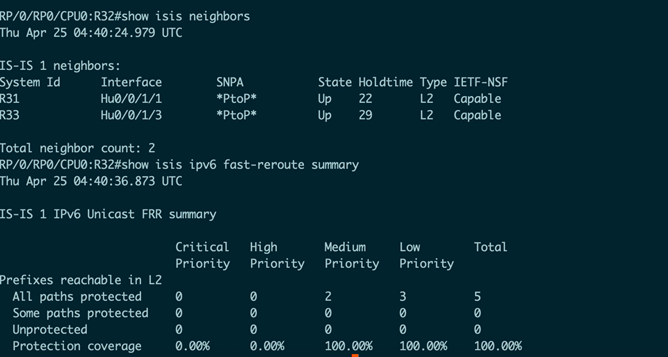
上图显示了Router B上的所有链路均已启用保护(具有备份链路)
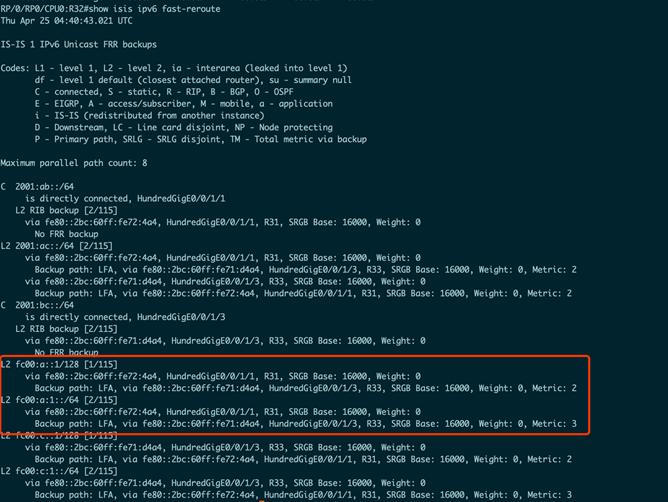
在图38所示的信息中,可以看到fc00: a:1::/64 (下一个Segment)的备份路径为HundredGigE0/0/1/3。
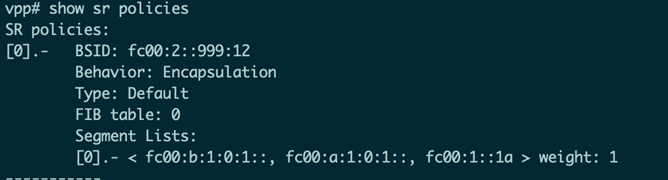
在开始测试之前,我们再次确认VPP2上去往VPP1的SRv6 Policy:

SRv6 Policy为先去往Router B,再去往Router A,最后到达VPP1执行End.DX4操作。
下面开始打流测试:

在Tester2运行UDP打流代码,开始打流: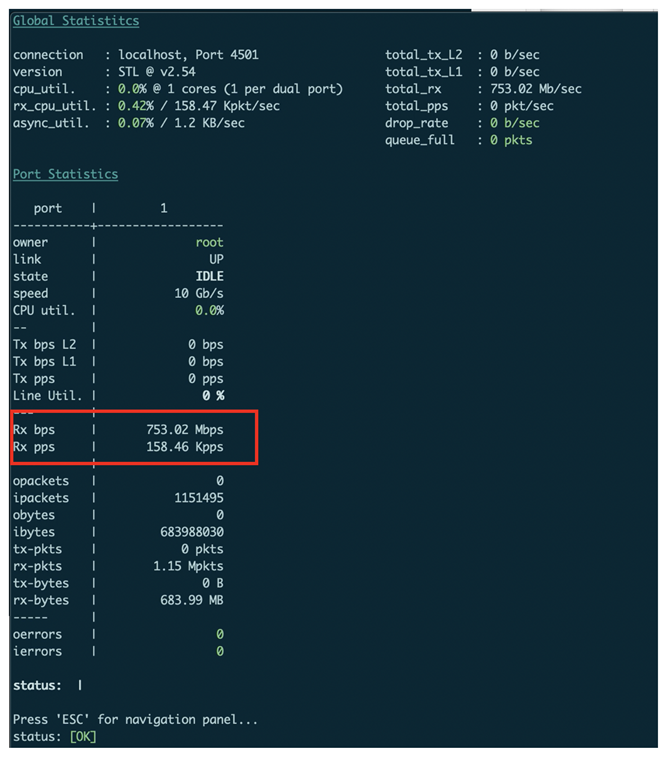
Tester1(接收端)可以收到发送端的流量。
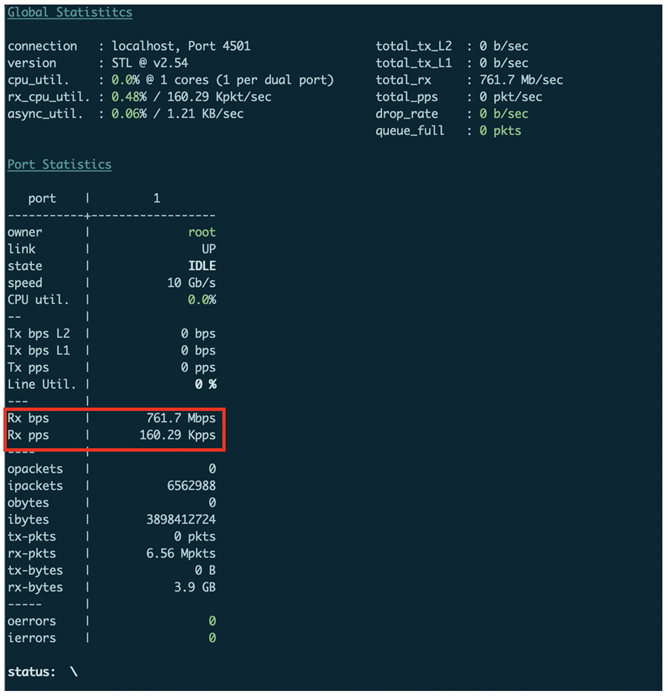
从上图可见目前流量经由HGE 0/0/1/1 转发。
接下来shutdown目前用于转发的HGE 0/0/1/1 接口。


从Tester1没有看到速率有所下降,说明自动切换路径成功。

端口信息确认HGE 0/0/1/1已经被shutdown,因此无法继续转发。
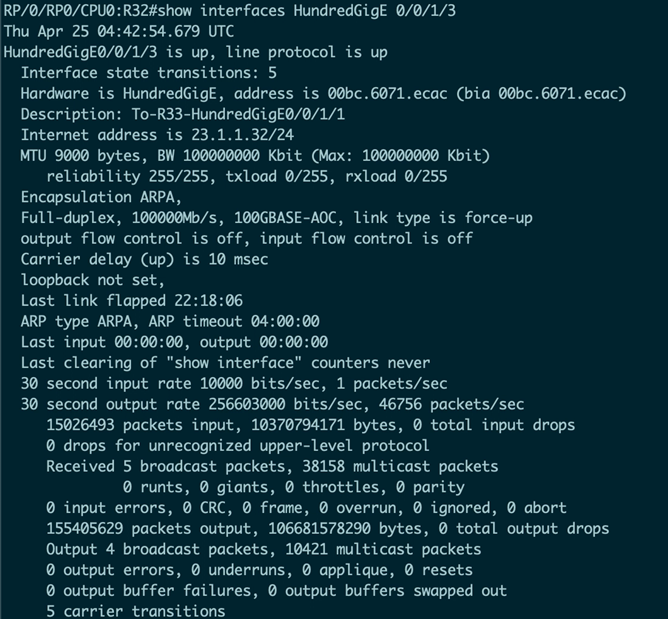
查看HundredGigE 0/0/1/3的端口信息,发现Router B开始使用该端口转发流量。

从fast-reroute的输出来看,切换后已经没有了备份链路,默认为HGE 0/0/1/3(FRR路径即收敛后路径), 证明切换成功。
接着等待实验发包结束。

从Tester1上来看接收到了15,984,004个数据包。
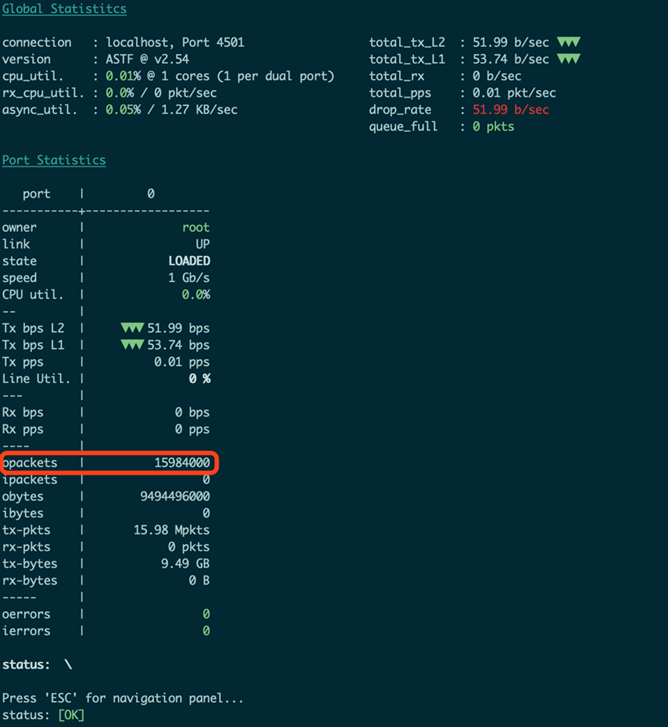
从Tester2上来看,发出了15,984,000个数据包,Tester1多收的一些数据包为ARP等数据包,从数据包数量来看,没有出现丢包。
该测试总计测试了5次,整理后的数据如下:
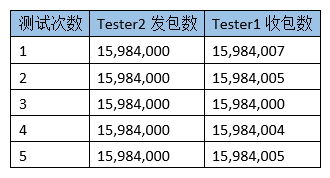
上表为多次测试下的测试结果。可以看到在目前的PPS速率下基本没有测出丢包,TI-LFA保护效果非常好。
五、总结与展望
本文基于Linux上开源的 VPP软件以及Cisco NCS5500路由器,验证了通过SRv6实现多云环境下Overlay和Underlay整合、一体化调度以及快速收敛功能。结果表明,这个方案在现有软硬件条件下就可以部署,不用进行大规模的升级,也能满足业务对性能、收敛方面的需求。
本系列的三篇文章,我们由浅入深地验证了Linux上SRv6的各项功能、不同的实现方式(内核/内核模块/VPP)、最后进行了性能测试和保护测试。希望能帮助各位读者深入了解SRv6的强大功能、快速上手Linux SRv6以及利用SRv6解决实际问题。
如笔者之前在公开演讲中所述,SRv6两个最重要的特点是极简和可编程,是全新的思考、设计、运营网络的方式,是一次彻底的变革。
大潮已来,势不可挡。Let‘s Embrace SRv6!
【参考文献】
1. SRH draft: https://tools.ietf.org/html/draft-ietf-6man-segment-routing-header-18
2. SRv6 draft:https://tools.ietf.org/html/draft-ietf-spring-srv6-network-programming-00
3. Flex-Algo(灵活算法):https://tools.ietf.org/html/draft-ietf-lsr-flex-algo-01
4. VPP简介:https://wiki.fd.io/view/VPP/What_is_VPP%3F
5. VPP 18.07版本相关资料:https://docs.fd.io/vpp/18.07/
6. VPP SRv6相关资料/教程:https://wiki.fd.io/view/VPP/Segment_Routing_for_IPv6
7. Cisco Trex的相关资料/教程:https://trex-tgn.cisco.com/
8. Cisco Trex ASTF(本实验用的模式)的相关资料/教程:https://trex-tgn.cisco.com/trex/doc/trex_astf.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK