作者简介:crystonesc,研究PaaS运维开发方向,博客地址:https://blog.csdn.net/crystonesc
本文主要分为两部分,第一部分介绍容器内日志收集主要的解决方案,并对各解决方案的优劣进行比较。第二部分首先介绍镜像内集成日志采集组件部署方案,再介绍Sidecar(边车)模式日志采集部署方案。文章中若有不正之处,请指出。

第一部分:容器内日志收集主要的解决方案
方案1.在宿主机上实现日志采集(Logging at the node Level)
方案1的实现方式如下图1所示,通过在容器所在的宿主机部署日志采集插件(Log-collector)来对容器中的日志进行采集,采集预处理后输出到外部的消息队列当中(入Kafka等),再通过类似于ELK的框架进行处理,最终日志持久化到ElasticSearch当中。接下来将详述该实现方式。
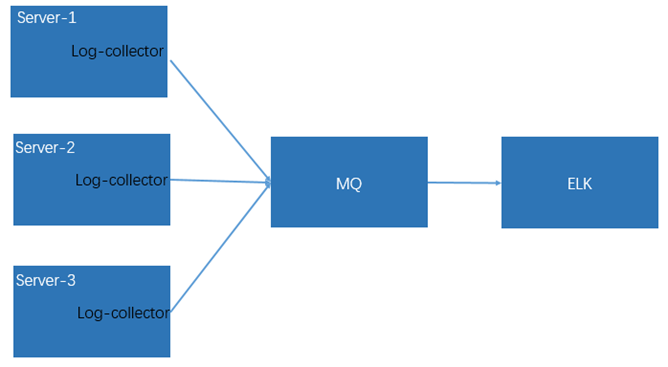
图1
我们知道,容器内应用输出到标准输出(stdout)和(标准错误输出)stderr的日志会被容器引擎所处理,例如docker就可以配置其日志引擎(logging driver),默认的logging driver是json-file,那么通过在宿主机中查看对应容器的logs文件,就可以查看到应用容器输出到标准输出的日志内容。同样在Kubernetes环境下也是一样的,pod内应用容器打印到控制台的日志也会被按照json格式存储在宿主机当中。基于这样的原理,如果我们在宿主机上部署日志采集工具(Log-collector),我们就能够实现容器内应用日志的采集。这样方式的部署,优点在于部署简单,日志采集资源开销小,但是会带来以下几个问题:
问题1.应用容器的日志输出到stdout和stderr,同时被容器引擎处理后存储到宿主机本地,随着日志的增多(如果应用容器不停止),会大量占用宿主机磁盘空间。
解决办法:引入滚动日志工具,将日志进行切割,并滚动生成,这样落盘的日志就不会一直消耗本地存储空间。
问题2.我们在宿主机上进行日志采集,会统一部署一套日志采集工具,那么如何来标记日志是属于哪个应用以及日志属于哪个容器?
解决办法:对日志采集工具进行开发或者引入开源的日志采集工具,例如:阿里的log-pilot ( https://github.com/AliyunContainerService/log-pilot )。核心思路是日志采集工具能够通过容器引擎提供的API(如:docker api)监听到容器的启动和停止,从而能建立容器与日志的对应关系,从而在采集日志的时候标识出日志属于哪个容器。那么如何标识日志属于哪个应用呢?实现方式较多,既可以通过应用层在输出日志时进行标识,也可以在启动容器的时候通过环境变量来标识容器所属应用。
问题3.json-file格式的日志,对于某些开发语言(例如JAVA)异常堆栈信息是被分行处理,日志采集后还需要进行二次加工。
解决办法:目前来看只能通过对日志采集工具进行二次开发或者对日志进行二次处理来解决。
可以看出,为了解决上述问题,我们不得不进行一些二次开发和处理工作,这增加了工作量和难度,所以除非有充足资源的情况下,可以采取该方案。
方案2.将镜像内集成日志采集组件部署方案(Logging at the App Level)
如图2所示,日志采集插件(Log-collector)与应用(App)部署在一起,日志采插件作为后台成运行,应用将日志写入容器环境的操作系统目录当中,日志采集插件读取日志并进行预处理,完成后送到MQ当中,最后与方案1一样,将日志持久化到ElasticSearch当中,相面详细介绍该方案。
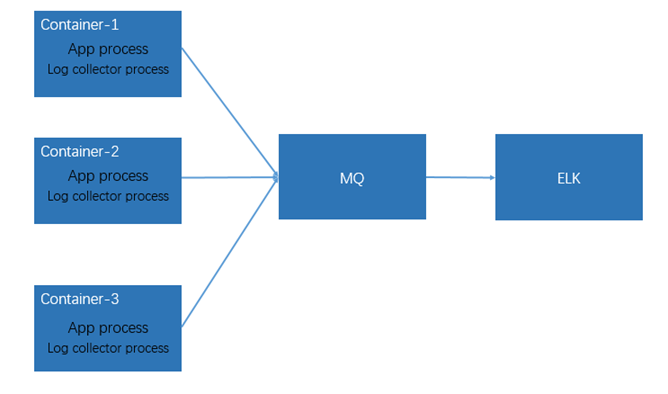
图2
为了解决宿主机日志收集存在的问题,同时不增加工作量和难度,我们可以考虑将日志采集工具集成到应用的基础镜像之中,应用基于基础镜像来生成应用镜像,在镜像启动的时候会把日志采集工具以后台进程的方式拉起来,搜集到日志后,日志采集工具可以将日志送到消息中间件,如Kafka,再由Logstash解析入ElasticSearch,最终用户可以通过Kibana进行日志检索。基于上述方式的部署,我们将采集工具和应用部署到一起,这样我们就能轻松的在日志采集工程中标识出日志所属的应用,同时因为日志是按照文件格式落到容器内部,一般的日志采集工具都能够通过multiline的方式来处理异常堆栈信息。对于日志增多的问题,还是需要应用引入滚动日志工具来解决。
该方案优点在于实现难度小,不增加工作量,同时能够准确的标识出日志所述的应用和所属的文件,使得应用方能够更加精确的管理日志。缺点在于每个应用镜像中都会引入额外的日志采集工具,增加了应用容器额外的资源开销,同时日志采集工具和应用基础镜像紧耦合。
方案3.基于Sidecar日志采集方式(Logging base on Sidecar)
如图3所示,该方案仅针对于Kubernetes环境,将日志通过Sidecar(边车)方式部署到应用Pod中,实现日志采集,下面将详细介绍该方案。
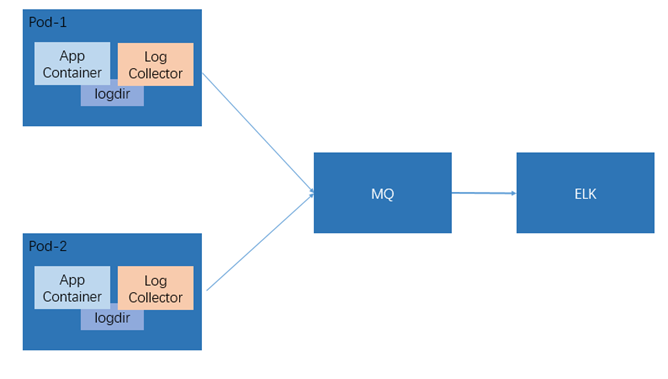
图3
在Kubernetes中,Pod中可以存在多个容器,这些容器之间可以通过emptyDir的方式共享文件系统,基于上述的原理,我们能够将日志采集工具从应用基础镜像中剥离出来,单独部署于一个容器中,这个日志容器与应用容器存在于一个Pod之中,他们之间共享应用容器的日志文件,从而实现应用容器将日志写入本地容器内部文件,日志采集容器读取文件内容并进行解析和传输。
该方案是第二个方案的优化版本,其减小了日志采集工具与应用基础镜像的耦合,缺点在于每个应用Pod内都需要启动一个Sidecar日志采集容器,不过通过实际观察来看,该Sidecar日志采集容器只需要很小的资源,即可完成日志采集。
三种方案选择思路
三种方案各有优劣点,方案一是比较理想的实施方式,其部署方式资源开销小,同时对应用侵入小,如果能够解决日志标识等问题,该方案应该是首选。方案二和方案三实施技术难度低,但对应用侵入较大,系统资源开销也稍多一些。当在这三种方案中进行抉择的时候,需要根据实际情况进行决定。
第二部分:详细方案介绍
1.方案2部署实践(Logging at the App Level)
1.1 部署环境
- 应用镜像: Tomcat
- 日志采集工具: filebeat6.2.4
- 容器引擎:Docker
- 消息组件:Kafka
1.2 应用镜像介绍
首先看一下基础镜像的Dockerfile,可以看到在应用的镜像中添加了filebeat-6.2.4-x86_64.rpm,并进行了安装,最后通过start.sh将Tomcat进行启动,我们继续看看start.sh做了什么。
FROM 192.168.1.2:5000/centos:7.3.1611
WORKDIR /home/tomcat
RUN mkdir -p /usr/java
ADD openjdk-8u40.tar /usr/java
ENV JAVA_HOME /usr/java/java-se-8u40-ri
ENV CATALINA_HOME /home/tomcat
ENV PATH=$JAVA_HOME/bin:$CATALINA_HOME/bin:$PATH
ENV LANG en_US.UTF-8
ENV FILEBEAT_OUTPUT kafka
ADD start.sh /home/tomcat/
ADD config_filebeat.sh /home/tomcat/
ADD filebeat-6.2.4-x86_64.rpm /home/
RUN rpm -ivh /home/filebeat-6.2.4-x86_64.rpm
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime;\
/bin/echo -e "ZONE="Asia/Shanghai"/nUTC=false/nRTC=false" > /etc/sysconfig/clock;\
rm bin/*.bat;\
groupadd -g 8000 xkx;\
useradd --create-home --no-log-init --password mypasswd1 -g xkx -u 8000 --shell /home/tomcat xkx;\
chown -Rf xkx.xkx /home/tomcat;
user xkx
EXPOSE 8080
CMD ["sh","/home/tomcat/start.sh"]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
FROM192.168.1.2:5000/centos:7.3.1611
WORKDIR/home/tomcat
RUN mkdir-p/usr/java
ADD openjdk-8u40.tar/usr/java
ENV JAVA_HOME/usr/java/java-se-8u40-ri
ENV CATALINA_HOME/home/tomcat
ENV PATH=$JAVA_HOME/bin:$CATALINA_HOME/bin:$PATH
ENV LANG en_US.UTF-8
ENV FILEBEAT_OUTPUT kafka
ADD start.sh/home/tomcat/
ADD config_filebeat.sh/home/tomcat/
ADD filebeat-6.2.4-x86_64.rpm/home/
RUN rpm-ivh/home/filebeat-6.2.4-x86_64.rpm
RUN/bin/cp/usr/share/zoneinfo/Asia/Shanghai/etc/localtime;\
/bin/echo-e"ZONE="Asia/Shanghai"/nUTC=false/nRTC=false">/etc/sysconfig/clock;\
rm bin/*.bat;\
groupadd-g8000xkx;\
useradd--create-home--no-log-init--password mypasswd1-gxkx-u8000--shell/home/tomcat xkx;\
chown-Rf xkx.xkx/home/tomcat;
user xkx
EXPOSE8080
CMD["sh","/home/tomcat/start.sh"]
在start.sh中我们首先通过环境变量来生成Filebeat的配置文件(filebeat.yml),环境变量主要包含日志的位置、应用标识、Kafka brokers的地址和Kafka Topic名称,接下来通过后台方式启动Filebeat,完成启动后首先检查Filebeat是否启动成功,如果启动成功,则以前台方式启动Tomcat。(注意:一定要以前台方式启动Tomcat,不然可能出现应用已经退出,而容器还存在)
#获取容器中的环境变量并执行脚本配置filebeat,生成配置文件
sh /home/tomcat/config_filebeat.sh
# 启动filebeat
nohup /usr/bin/filebeat -c /etc/filebeat/filebeat.yml >/dev/null 2>&1 &
#检查filebeat启动是否成功
ps -ef | grep filebeat |grep -v grep
PROCESS_1_STATUS=$?
echo $PROCESS_1_STATUS
if [ $PROCESS_1_STATUS -ne 0 ]; then
echo "Failed to start filebeat: $PROCESS_1_STATUS"
exit $PROCESS_1_STATUS
fi
sleep 5
#最后通过前台方式启动Tomcat
sh /home/tomcat/bin/catalina.sh run
#获取容器中的环境变量并执行脚本配置filebeat,生成配置文件
sh/home/tomcat/config_filebeat.sh
#启动filebeat
nohup/usr/bin/filebeat-c/etc/filebeat/filebeat.yml>/dev/null2>&1&
#检查filebeat启动是否成功
ps-ef | grep filebeat|grep-vgrep
PROCESS_1_STATUS=$?
echo$PROCESS_1_STATUS
if[$PROCESS_1_STATUS-ne0];then
echo"Failed to start filebeat: $PROCESS_1_STATUS"
exit$PROCESS_1_STATUS
fi
sleep5
#最后通过前台方式启动Tomcat
sh/home/tomcat/bin/catalina.sh run
接下来我们看下config_filebeat.sh脚本的片段,可以看到,我们主要通过环境变量来配置filebeat.yml文件
cat > $FILEBEAT_CONFIG << EOF
logging.level: error
logging.to_syslog: false
logging.to_files: false
logging.metrics.enabled: false
filebeat.prospectors:
- type: log
enabled: true
paths:
- ${TOMCATLOG}*
fields:
type: tomcat_catalina_log
PORT0: ${PORT0}
host: ${HOST}
app: ${_APP}
fields_under_root: true
multiline.pattern: ^[0-9]
multiline.negate: true
multiline.match: after
EOF
}
kafka() {
assert_not_empty "$KAFKA_BROKERS" "KAFKA_BROKERS required"
KAFKA_BROKERS=$(/usr/bin/echo $KAFKA_BROKERS|awk -F, '{for(i=1;i<=NF;i++){printf "\"%s\",", $i}}')
KAFKA_BROKERS=${KAFKA_BROKERS%,}
cat >> $FILEBEAT_CONFIG << EOF
$(base)
output.kafka:
hosts: [$KAFKA_BROKERS]
topic: '%{[type]}'
EOF
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
cat>$FILEBEAT_CONFIG<<EOF
logging.level:error
logging.to_syslog:false
logging.to_files:false
logging.metrics.enabled:false
filebeat.prospectors:
-type:log
enabled:true
paths:
-${TOMCATLOG}*
fields:
type:tomcat_catalina_log
PORT0:${PORT0}
host:${HOST}
app:${_APP}
fields_under_root:true
multiline.pattern:^[0-9]
multiline.negate:true
multiline.match:after
EOF
}
kafka(){
assert_not_empty"$KAFKA_BROKERS""KAFKA_BROKERS required"
KAFKA_BROKERS=$(/usr/bin/echo$KAFKA_BROKERS|awk-F,'{for(i=1;i<=NF;i++){printf "\"%s\",", $i}}')
KAFKA_BROKERS=${KAFKA_BROKERS%,}
cat>>$FILEBEAT_CONFIG<<EOF
$(base)
output.kafka:
hosts:[$KAFKA_BROKERS]
topic:'%{[type]}'
EOF
}
最终生成的filebeat.yml效果如图4所示:

图4
完成上述工作后,我们的镜像就制作好了,这时候应用只需要将日志输出到指定的位置,Filebeat就采集日志并输出到Kafka当中,最后通过ELK框架完成持久化和展示分析。如图5所示,是Kibana中查询到的日志信息。
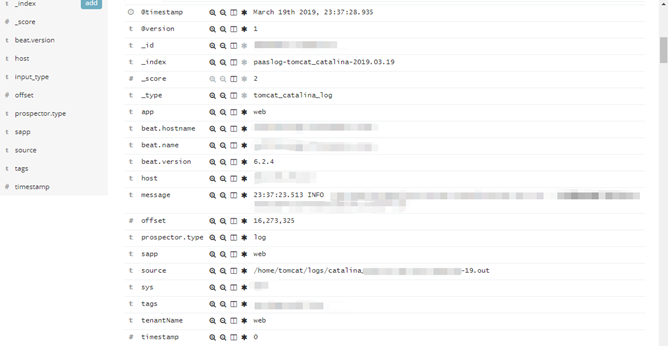
图5
2.方案3详细部署实践
2.1 部署环境
- 容器编排平台:Kubernetes
- 应用镜像:Tomcat
- 日志采集工具: Fluentd
- 消息组件:Kafka
2.2 日志采集镜像介绍
日志采集镜像是基于Fluentd +Kafka plugin来的制作的,下面是Dockerfile内容.
FROM alpine:3.8
ARG VERSION=1.1
LABEL maintainer "crystonesc"
LABEL Description="Fluentd docker image" Vendor="Fluent Organization" Version=${VERSION}
ENV DUMB_INIT_VERSION=1.2.1
ENV SU_EXEC_VERSION=0.2
ARG DEBIAN_FRONTEND=noninteractive
RUN echo "#aliyun" > /etc/apk/repositories
RUN echo "https://mirrors.aliyun.com/alpine/v3.8/main/" >> /etc/apk/repositories
RUN echo "https://mirrors.aliyun.com/alpine/v3.8/community/" >> /etc/apk/repositories
# Do not split this into multiple RUN!
# Docker creates a layer for every RUN-Statement
# therefore an 'apk delete' has no effect
RUN apk update \
&& apk upgrade \
&& apk add --no-cache \
ca-certificates \
ruby ruby-irb ruby-etc ruby-webrick \
su-exec==${SU_EXEC_VERSION}-r0 \
dumb-init==${DUMB_INIT_VERSION}-r0 \
&& apk add --no-cache --virtual .build-deps \
build-base \
ruby-dev wget gnupg \
&& update-ca-certificates \
&& echo 'gem: --no-document' >> /etc/gemrc \
&& gem install oj -v 3.3.10 \
&& gem install json -v 2.1.0 \
&& gem install fluentd -v 1.3.1 \
&& gem install ruby-kafka -v 0.6.8 \
&& gem install fluent-plugin-kafka -v 0.7.9 \
&& gem install bigdecimal -v 1.3.5 \
&& apk del .build-deps \
&& rm -rf /var/cache/apk/* \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
# for log storage (maybe shared with host)
RUN mkdir -p /fluentd/log
# configuration/plugins path (default: copied from .)
RUN mkdir -p /fluentd/etc /fluentd/plugins
RUN mkdir -p /usr/local/tomcat/logs
COPY fluent.conf /fluentd/etc/
COPY entrypoint.sh /bin/
#RUN mkdir -p /home/fluent/hello/
RUN chmod +x /bin/entrypoint.sh
ENV FLUENTD_OPT=""
ENV FLUENTD_CONF="fluent.conf"
ENV LD_PRELOAD=""
ENV DUMB_INIT_SETSID 0
EXPOSE 24224 5140
ENTRYPOINT ["/bin/entrypoint.sh"]
CMD exec fluentd -c /fluentd/etc/${FLUENTD_CONF} -p /fluentd/plugins $FLUENTD_OPT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
FROM alpine:3.8
ARG VERSION=1.1
LABEL maintainer"crystonesc"
LABEL Description="Fluentd docker image"Vendor="Fluent Organization"Version=${VERSION}
ENV DUMB_INIT_VERSION=1.2.1
ENV SU_EXEC_VERSION=0.2
ARG DEBIAN_FRONTEND=noninteractive
RUN echo"#aliyun">/etc/apk/repositories
RUN echo"https://mirrors.aliyun.com/alpine/v3.8/main/">>/etc/apk/repositories
RUN echo"https://mirrors.aliyun.com/alpine/v3.8/community/">>/etc/apk/repositories
#Donotsplit thisinto multiple RUN!
#Docker createsalayer forevery RUN-Statement
#therefore an'apk delete'has no effect
RUN apk update\
&&apk upgrade\
&&apk add--no-cache\
ca-certificates\
ruby ruby-irb ruby-etc ruby-webrick\
su-exec==${SU_EXEC_VERSION}-r0\
dumb-init==${DUMB_INIT_VERSION}-r0\
&&apk add--no-cache--virtual.build-deps\
build-base\
ruby-dev wget gnupg\
&&update-ca-certificates\
&&echo'gem: --no-document'>>/etc/gemrc\
&&gem install oj-v3.3.10\
&&gem install json-v2.1.0\
&&gem install fluentd-v1.3.1\
&&gem install ruby-kafka-v0.6.8\
&&gem install fluent-plugin-kafka-v0.7.9\
&&gem install bigdecimal-v1.3.5\
&&apk del.build-deps\
&&rm-rf/var/cache/apk/* \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
#forlog storage(maybe shared with host)
RUN mkdir-p/fluentd/log
#configuration/plugins path(default:copied from.)
RUN mkdir-p/fluentd/etc/fluentd/plugins
RUN mkdir-p/usr/local/tomcat/logs
COPY fluent.conf/fluentd/etc/
COPY entrypoint.sh/bin/
#RUN mkdir-p/home/fluent/hello/
RUN chmod+x/bin/entrypoint.sh
ENV FLUENTD_OPT=""
ENV FLUENTD_CONF="fluent.conf"
ENV LD_PRELOAD=""
ENV DUMB_INIT_SETSID0
EXPOSE242245140
ENTRYPOINT["/bin/entrypoint.sh"]
CMDexecfluentd-c/fluentd/etc/${FLUENTD_CONF}-p/fluentd/plugins$FLUENTD_OPT
在entrypoint.sh当中,我们完成Fluentd配置文件的生成,entrypoint.sh内容如下:
#!/usr/bin/dumb-init /bin/sh
uid=${FLUENT_UID:-1000}
# check if a old fluent user exists and delete it
cat /etc/passwd | grep fluent
if [ $? -eq 0 ]; then
deluser fluent
fi
# (re)add the fluent user with $FLUENT_UID
adduser -D -g '' -u ${uid} -h /home/fluent fluent
#source vars if file exists
DEFAULT=/etc/default/fluentd
if [ -r $DEFAULT ]; then
set -o allexport
source $DEFAULT
set +o allexport
fi
#chown home and data folder
chown -R fluent:fluent /home/fluent
chown -R fluent:fluent /fluentd
chown -R fluent:fluent /usr/local/tomcat
if [ -z "$LOGPATH" ]
then
echo "LOGPATH is not configure"
exit 1
fi
if [ -z "$BROKERS" ]
then
echo "BROKERS is not configure"
exit 1
fi
if [ -z "$KAFKA_TOPIC" ]
then
echo "KAFKA_TOPIC is not configure"
exit 1
fi
export REAL_LOGPATH="$(echo $LOGPATH | sed 's/\//\\\//g')"
sed -i "s/{LOGPATH}/${REAL_LOGPATH}/g" /fluentd/etc/fluent.conf
sed -i "s/{BROKERS}/${BROKERS}/g" /fluentd/etc/fluent.conf
sed -i "s/{KAFKA_TOPIC}/${KAFKA_TOPIC}/g" /fluentd/etc/fluent.conf
sed -i "s/{TENANTID}/${TENANTID}/g" /fluentd/etc/fluent.conf
sed -i "s/{_SYS}/${_SYS}/g" /fluentd/etc/fluent.conf
sed -i "s/{_SAPP}/${_SAPP}/g" /fluentd/etc/fluent.conf
sed -i "s/{_SGRP}/${_SGRP}/g" /fluentd/etc/fluent.conf
sed -i "s/{_ITG}/${_ITG}/g" /fluentd/etc/fluent.conf
sed -i "s/{HOST}/${HOST}/g" /fluentd/etc/fluent.conf
exec su-exec fluent "$@"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
#!/usr/bin/dumb-init/bin/sh
uid=${FLUENT_UID:-1000}
#check ifaold fluent user exists anddelete it
cat/etc/passwd | grep fluent
if[$?-eq0];then
deluser fluent
fi
#(re)add the fluent user with$FLUENT_UID
adduser-D-g''-u${uid}-h/home/fluent fluent
#source vars iffile exists
DEFAULT=/etc/default/fluentd
if[-r$DEFAULT];then
set-oallexport
source$DEFAULT
set+oallexport
fi
#chown home anddata folder
chown-Rfluent:fluent/home/fluent
chown-Rfluent:fluent/fluentd
chown-Rfluent:fluent/usr/local/tomcat
if[-z"$LOGPATH"]
then
echo"LOGPATH is not configure"
exit1
fi
if[-z"$BROKERS"]
then
echo"BROKERS is not configure"
exit1
fi
if[-z"$KAFKA_TOPIC"]
then
echo"KAFKA_TOPIC is not configure"
exit1
fi
export REAL_LOGPATH="$(echo $LOGPATH | sed 's/\//\\\//g')"
sed-i"s/{LOGPATH}/${REAL_LOGPATH}/g"/fluentd/etc/fluent.conf
sed-i"s/{BROKERS}/${BROKERS}/g"/fluentd/etc/fluent.conf
sed-i"s/{KAFKA_TOPIC}/${KAFKA_TOPIC}/g"/fluentd/etc/fluent.conf
sed-i"s/{TENANTID}/${TENANTID}/g"/fluentd/etc/fluent.conf
sed-i"s/{_SYS}/${_SYS}/g"/fluentd/etc/fluent.conf
sed-i"s/{_SAPP}/${_SAPP}/g"/fluentd/etc/fluent.conf
sed-i"s/{_SGRP}/${_SGRP}/g"/fluentd/etc/fluent.conf
sed-i"s/{_ITG}/${_ITG}/g"/fluentd/etc/fluent.conf
sed-i"s/{HOST}/${HOST}/g"/fluentd/etc/fluent.conf
exec su-exec fluent"$@"
生成的Fluentd配置文件如下所示,通过在日志中添加{SYS}.{HOST} 来标识日志所属的系统和POD IP地址,这里要说明的是,虽然Kubernetes中Pod IP地址发生变化,但是在运行态中,其能够唯一标识出日志对应的容器位置,这样方便开发者定位到输出日志的容器。
<source>
@type tail
path {LOGPATH}
pos_file /fluentd/catalina.fluent.pos
path_key filepath
tag {SYS}.{HOST}.log
format multiline
format_firstline /\d{4}-\d{1,2}-\d{1,2}/
format1 /(?<message>.*)/
</source>
<filter {SYS}.{HOST}.log>
@type record_transformer
<record>
topic {KAFKA_TOPIC}
</record>
</filter>
<match {SYS}.{HOST}.log>
@type kafka_buffered
# list of seed brokers
brokers {BROKERS}
# buffer settings
buffer_type file
buffer_path /home/fluent/td-agent/buffer/td
flush_interval 3s
# topic settings
default_topic {KAFKA_TOPIC}
#get_kafka_client_log true
# data type settings
output_data_type json
compression_codec gzip
# producer settings
max_send_retries 1
required_acks -1
</match>
<system>
# equal to -qq option
log_level info
</system>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
<source>
@typetail
path{LOGPATH}
pos_file/fluentd/catalina.fluent.pos
path_keyfilepath
tag{SYS}.{HOST}.log
formatmultiline
format_firstline/\d{4}-\d{1,2}-\d{1,2}/
format1/(?<message>.*)/
</source>
<filter{SYS}.{HOST}.log>
@typerecord_transformer
<record>
topic{KAFKA_TOPIC}
</record>
</filter>
<match{SYS}.{HOST}.log>
@typekafka_buffered
#listofseedbrokers
brokers{BROKERS}
#buffersettings
buffer_typefile
buffer_path/home/fluent/td-agent/buffer/td
flush_interval3s
#topicsettings
default_topic{KAFKA_TOPIC}
#get_kafka_client_log true
#data type settings
output_data_type json
compression_codec gzip
#producer settings
max_send_retries1
required_acks-1
</match>
<system>
#equal to-qq option
log_level info
</system>
2.3 Kubernetes 应用Yaml文件介绍
完成日志采集组件镜像制作后,我们就可以进行部署,下面是Deployment Yaml文件内容,可以看到在Pod中我们启动了两个容器,一个为应用容器,另一个为日志采集容器,应用容器共享/usr/local/tomcat/logs目录给日志采集容器,日志采集容器采集该目录下的所有日志。
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: logtest-app
namespace: xkx
labels:
app:xkx
version: v1
spec:
# replicas: 2
template:
metadata:
labels:
app: logtest-app
spec:
nodeSelector:
node-mode: app1
containers:
- name: logtest-app
image: logtest:3.0
volumeMounts:
- name: logdir
mountPath: /usr/local/tomcat/logs/
ports:
- containerPort: 8080
resources:
limits:
cpu: 800m
memory: 2Gi
requests:
cpu: 400m
memory: 1Gi
imagePullPolicy: IfNotPresent
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
- name: fluentd-log-collector
image: fluentd-plugin-kafka:v1.6
volumeMounts:
- name: logdir
mountPath: /usr/local/tomcat/logs/
resources:
limits:
cpu: 300m
memory: 256M
requests:
cpu: 150m
memory: 128M
env:
- name: LOGPATH
value: "/usr/local/tomcat/logs/*"
- name: _SYS
value: "xkx"
- name: _SAPP
value: "logtest"
- name: BROKERS
value: "192.168.100.2:6667,192.168.100.3:6667,192.168.100.4:6667,192.168.100.5:6667,192.168.100.6:6667"
- name: _APP
value: "logtest"
- name: KAFKA_TOPIC
value: "testt"
- name: HOST
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
imagePullSecrets:
- name: xkx-rep
volumes:
- name: logdir
emptyDir: {}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
kind:Deployment
apiVersion:extensions/v1beta1
metadata:
name:logtest-app
namespace:xkx
labels:
app:xkx
version:v1
spec:
#replicas:2
template:
metadata:
labels:
app:logtest-app
spec:
nodeSelector:
node-mode:app1
containers:
-name:logtest-app
image:logtest:3.0
volumeMounts:
-name:logdir
mountPath:/usr/local/tomcat/logs/
ports:
-containerPort:8080
resources:
limits:
cpu:800m
memory:2Gi
requests:
cpu:400m
memory:1Gi
imagePullPolicy:IfNotPresent
readinessProbe:
tcpSocket:
port:8080
initialDelaySeconds:30
periodSeconds:10
livenessProbe:
tcpSocket:
port:8080
initialDelaySeconds:15
periodSeconds:20
-name:fluentd-log-collector
image:fluentd-plugin-kafka:v1.6
volumeMounts:
-name:logdir
mountPath:/usr/local/tomcat/logs/
resources:
limits:
cpu:300m
memory:256M
requests:
cpu:150m
memory:128M
env:
-name:LOGPATH
value:"/usr/local/tomcat/logs/*"
-name:_SYS
value:"xkx"
-name:_SAPP
value:"logtest"
-name:BROKERS
value:"192.168.100.2:6667,192.168.100.3:6667,192.168.100.4:6667,192.168.100.5:6667,192.168.100.6:6667"
-name:_APP
value:"logtest"
-name:KAFKA_TOPIC
value:"testt"
-name:HOST
valueFrom:
fieldRef:
apiVersion:v1
fieldPath:status.podIP
imagePullSecrets:
-name:xkx-rep
volumes:
-name:logdir
emptyDir:{}


