

Structuring Legal Documents with Deep Learning
source link: https://www.tuicool.com/articles/hit/rEZJzyQ
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
:dart:Introduction
Nearly 4 million decisions are delivered each year by French courts. The case law they drive is critical to lawyers who use it in court to defend their clients. Legal research is tedious andDoctrine’s mission is to help them get straight to the point.
Court decisions are traditionally long and complex documents. To make things worse, for example, a lawyer may be interested in the operative part of the judgement only, that is, the trial's outcome. In fact, in general, it is pretty common to be looking for a specific legal aspect in such a lengthy text and it can quickly feel like looking for a needle in a haystack. Our goal here is to detect the structure of decisions on Doctrine (i.e. the table of contents) to help users navigate through them more easily.
:page_facing_up: How are French decisions structured?
A decision is generally structured as follows:
- Metadata (« En-tête » in French): court, number, date, etc., of the trial.
- Parties (« Parties » in French): information about the claimants and defendants
- Composition of the court (« Composition de la cour » in French): name of the President of the court, the Clerk, etc.
- Facts (« Faits » in French): what happened?
- Pleas in law and main arguments (« Moyens » in French): arguments presented by the claimant and defendant.
- Grounds (« Motifs » in French): reasons and arguments used by the court for its final judgment.
- Operative part of the judgment (« Dispositif » in French): final decision of the court.
These are the usual sections, however, there isn't a systematic structure in decisions. Courts may use different styles , both in terms of writing and organising the documents. For instance, some have titles that highlight a specific part, some have not. And some have all the sections described above, some only have a few.
 Example of a table of contents of a decision on Doctrine. This decision does not include metadata, nor pleas in law.
Example of a table of contents of a decision on Doctrine. This decision does not include metadata, nor pleas in law.
The French Court of Appeal usually has a very unified way of writing. Around 55% of their decisions (among those hosted onDoctrine) have explicit titles for each category:
 Extract of a French Court of Appeal decision with an explicit title for the Facts section. Extracted from https://www.doctrine.fr/d/CA/Orleans/2007/SKDD824CCFE8D8D9D93128 . See an English translation .
Extract of a French Court of Appeal decision with an explicit title for the Facts section. Extracted from https://www.doctrine.fr/d/CA/Orleans/2007/SKDD824CCFE8D8D9D93128 . See an English translation .
For the remaining 45% , we don't have an explicit title for all sections.
 Example of a non structured text provided by the French Court of Appeal. Extracted from https://www.doctrine.fr/d/CA/Metz/2015/RAC1261A1563690C06B77 . See an English translation .
Example of a non structured text provided by the French Court of Appeal. Extracted from https://www.doctrine.fr/d/CA/Metz/2015/RAC1261A1563690C06B77 . See an English translation .
The decisions can be seen as small stories and while humans can understand them because they understand the context and have some expectations, how would an algorithm do?
So, how can we automatically generate tables of contents for court decisions?
:bulb: Technical approach
For every input paragraph from a decision, we want to predict which section it should be labelled with (the one it belongs to).
Let's think a little bit about how a human being can understand the transition between the two sections in the figure above (from « Facts » to « Grounds »).
- The order of the paragraphs is a big clue: the court will always remind us of the facts before giving its grounds.
- Then, the vocabulary used looks also different within these sections. In the non-structured example above, the first paragraph is summarising events , whereas the second paragraph is quoting some precise legislation points and seems to be an authority argument . But it's not that easy to see the difference by only looking at the words used. Indeed, in this case both paragraphs quote a legislation aspect, and so both paragraphs contain semantics on health care and health environments.
Our first approach was to use a bag-of-words (BoW) approach to encode the vocabulary information of a paragraph, along with conditional random fields (CRF) over paragraphs to encode the sequential information. Unfortunately, this attempt quickly proved insufficient, certainly because of its simplicity given the tough problem. As highlighted before, the vocabularies among paragraphs are not different enough to allow BoW to perform well.
In order to address this challenging issue, we trained a more complex model: a neural network (bi-LSTM with attention) using PyTorch to help us predict a table of contents given a free text decision.
Modelling
In this section, we first detail the data we used and how we pre-processed it. Then, we explain which models we tried, and the reasons why. Finally, we provide a look back with results and interpretations :eyes:.
:bomb: Spoiler: our models work well!
:open_file_folder: Our dataset & pre-processing
As detailed in the introduction, our task is to classify every paragraph (let's call it X) of a decision into one of the 7 most common categories (let's call it y ).
These categories are the following: Metadata, Parties, Composition, Facts, Pleas in law, Grounds and Operative part.
Defining X
Below, a paragraph (noted ¶) is a distinct section of text, indicated by a new line \n character. See below how we retrieve them in our decisions.
 Splitting into paragraphs ¶1, ¶2 and ¶3.
Splitting into paragraphs ¶1, ¶2 and ¶3.
Setting and finding y
We want to have a supervised classification setting (with a true, or expected y ), we thus need labelled data for our paragraphs.
In fact, it's pretty straightforward. For many decisions of the French Court of Appeal there's an explicit, clear table of contents. These decisions use titles to structure the documents, so we can look for these titles to annotate our dataset ( y ), and remove them afterwards. Our data set is now labelled.
Pre-processing
In order to avoid having a too large vocabulary, we:
- Lowercase text
- Stem words
- Replace all numbers by zero
- Replace singletons with word
<UNK>with a probabilityp=0.5. In our case, it is quite important to keep rare words, even under one single representation, because it will often correspond to last names. And we hypothesised we can learn things from last names (which eventually proved to be true).
✏ Model design
In this section, we briefly describe what models we chose and the intuition behind these choices.
Wait... is this Named Entity Recognition?
One thing we quickly noticed is the similarity of our task (paragraph classification) with Named Entity Recognition (NER). NER is a traditional task in Natural Language Processing where an algorithm is trained to detect entities in a sentence.
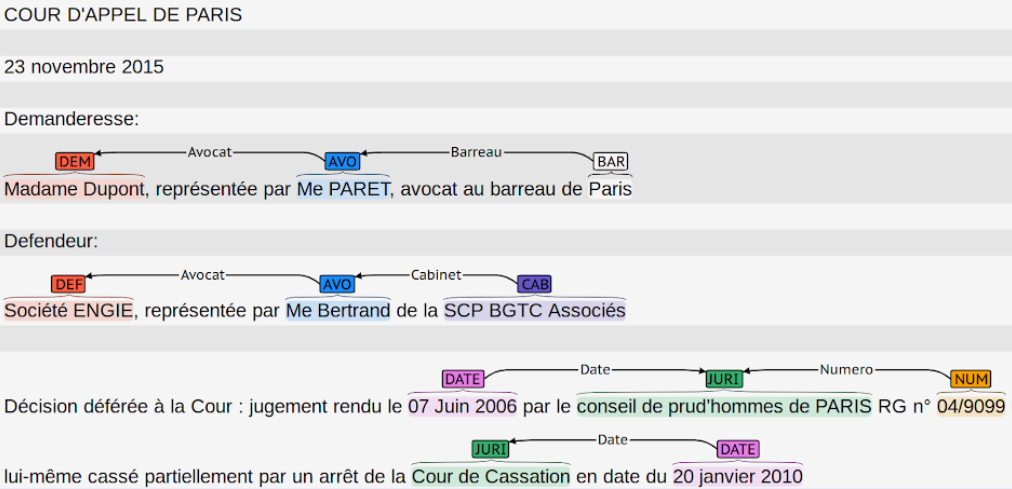 Named Entity Recognition: finding lawyers, dates & other entities in a decision.
Named Entity Recognition: finding lawyers, dates & other entities in a decision.
In our case, we are not working at the word scale but at the paragraph scale . Still, the idea remains the same, we can infer the label of a word / paragraph with:
- its inherent properties
- its context (the neighborhood gives insights on the label).
So, studying the literature in NER provided us with some great model architecture ideas (namely bi-LSTM neural networks with attention — we'll see that soon). Our chosen architecture is strongly inspired from this paper .
Paragraph embeddings
Just like NER, models use word embeddings as an initial representation for their inputs, we need to represent our paragraphs with paragraph embeddings .
Aggregating word embeddings
At Doctrine, we trained our own word embeddings on 2 million legal documents using wang2vec . We can use these word embeddings to compute paragraph embeddings, for example by aggregating the paragraph's words embeddings. We tried two aggregations:
- Average of the word embeddings of the paragraph, initialised by our pre-trained vectors.
- Sum of the word embeddings of the paragraph, initialised by our pre-trained vectors.
Training with bi-LSTMs
One problem of the previous method (average & sum) is that it doesn't capture sequential information from word order in the paragraph embeddings and we may hurt the training. One solution is to use bi-LSTM that keep information from left to right and from right to left. We trained these using our pre-trained word embeddings.
- bi-LSTM over the paragraph and reading the words, keeping the last hidden state from left to right and from right to left.
- bi-LSTM with self-attention mechanism, strongly inspired by this paper from Bengio et al, 2017. Will prove very useful for the interpretation of which words impact the final classification.
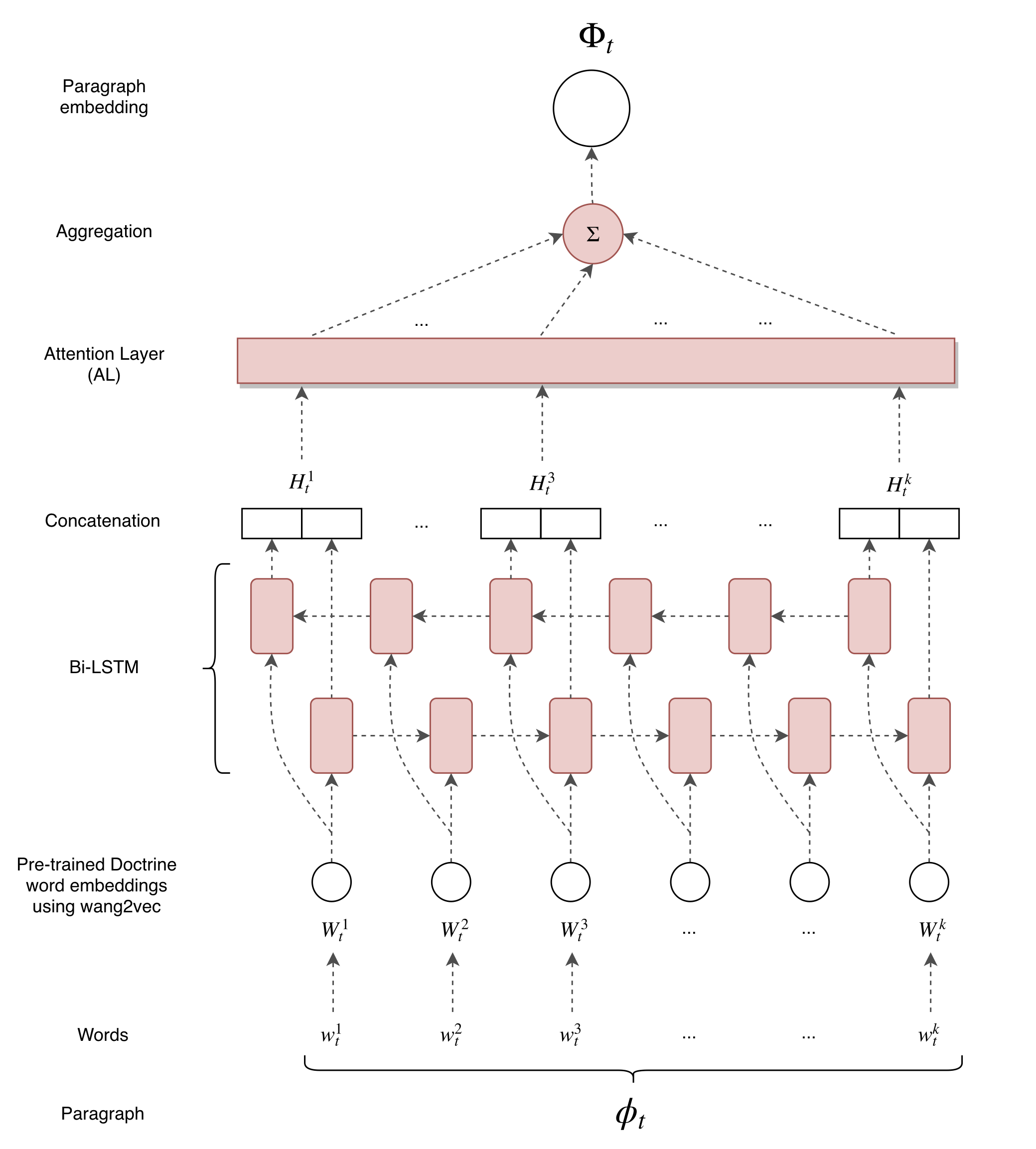 Architecture of our paragraph-embedding (PE) model.
Architecture of our paragraph-embedding (PE) model.
Classifier
Now that we have a good design for paragraph embeddings, we can define the operations on those embeddings to predict which class they belong to.
- Encoder choice
We want to classify one paragraph based on surrounding paragraphs information too, so as to capture the sequence of paragraphs. Here again, we chose an bi-LSTM.
- Decoder choice
We chose CRF because they enable to model transition probabilities between classes . And in our case, our classes have sequential information (i.e. class « Motifs » should come after class « Facts » and before class « Dispositif »), so looking at the transition matrix helps to check whether / where the model learns well or not.
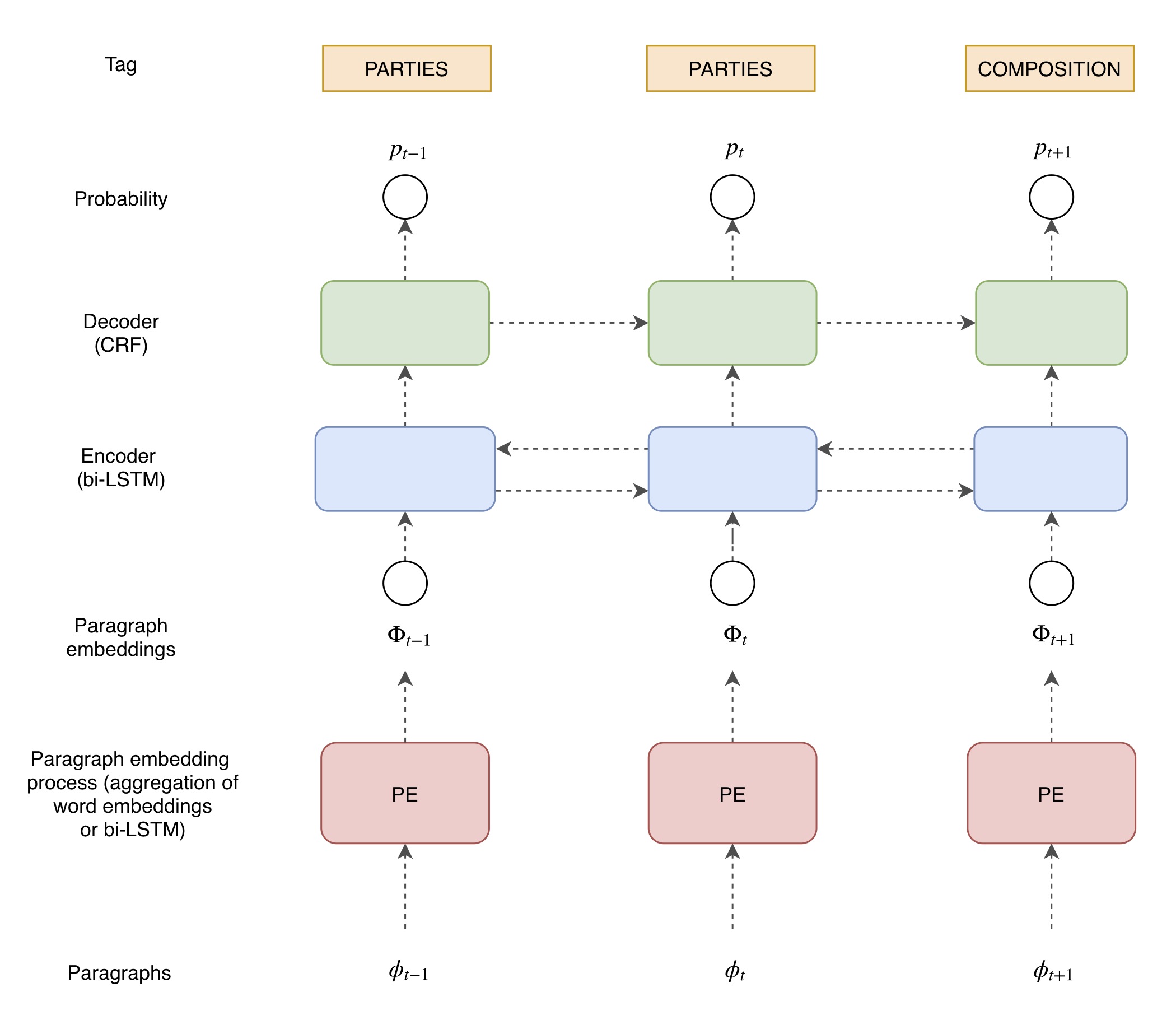 Architecture of the paragraph classification network.
Architecture of the paragraph classification network.
Note that we also tried a simple softmax for the decoder part, and compared results (we'll see it later).
:eyeglasses: Learning
We split into train & test sets and learnt using Adam optimiser with learning rate = 0.0025 and beta = 0.85. Our loss is the negative log-likelihood .
:bar_chart: Results
Find below the performance of our best models:
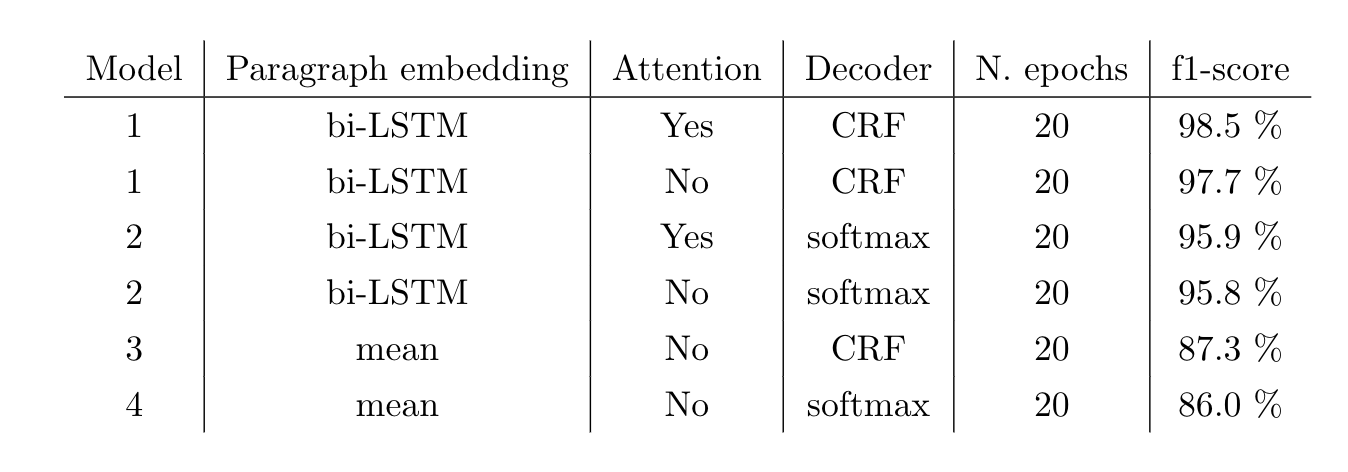 Results of our best models on paragraph classification.
Results of our best models on paragraph classification.
Note that the training of models with mean aggregation for paragraph embeddings takes about 30% less time than with bi-RNNs!
Note also that the f1-score is for all tags. However, we went deeper in the results and noticed that the model had more difficulties to predict the specific tag « Moyens ». They are indeed not always present in the decisions, and sometimes mixed with the « Facts » part.
Performance of the best model
Our best model reaches 0.98 f1-score!
Thanks to the CRF, we can have a look at normalised transition scores between classes, and see where the model performs well or not.
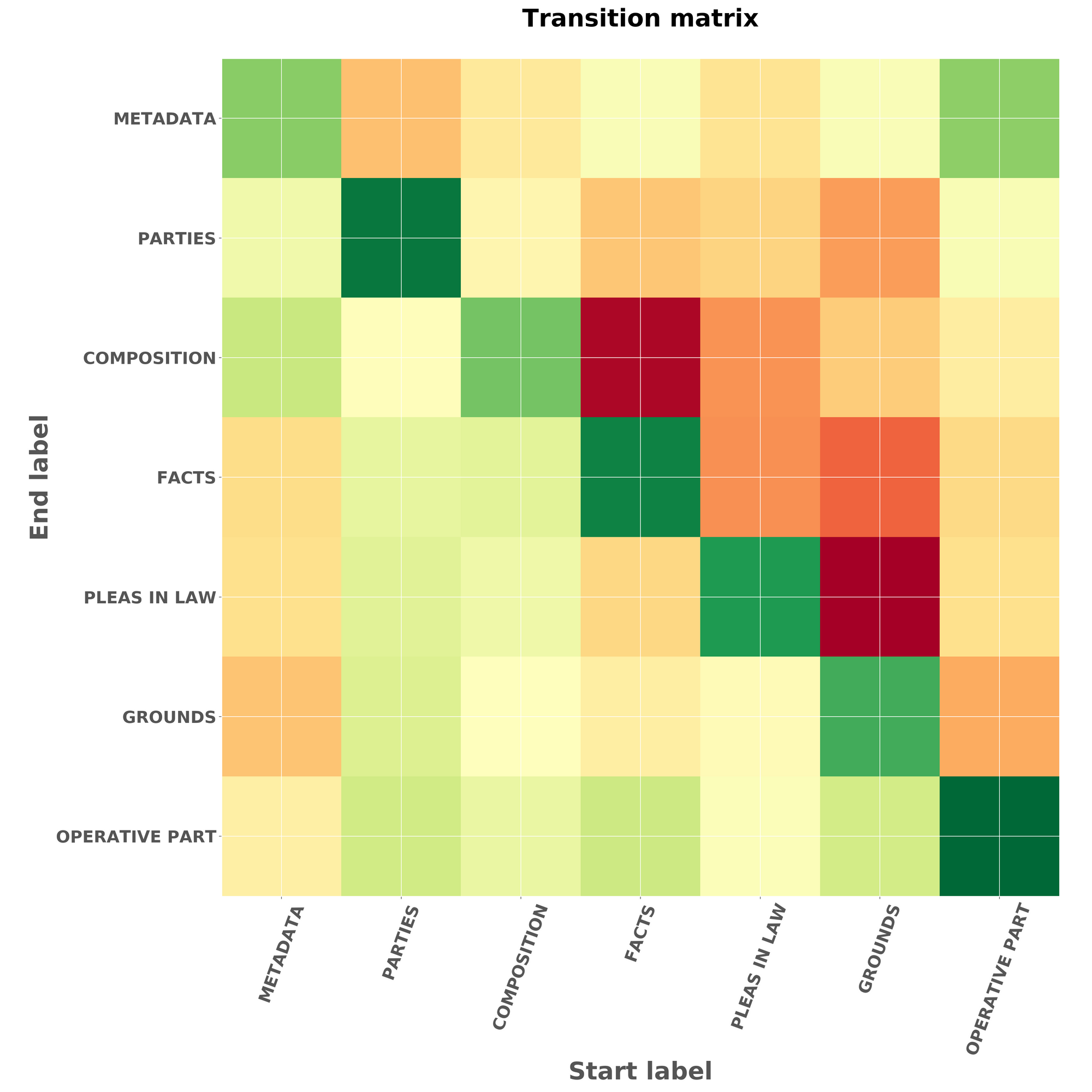 Transition matrix representing the transition scores between different sections. Red means a low transition score, green means a high transition score.
Transition matrix representing the transition scores between different sections. Red means a low transition score, green means a high transition score.
Some interpretations:
- Each class is likely to be followed by itself (because each class nearly always has multiple paragraphs).
- Section « Metadata » is likely to be followed by « Parties » or « Composition ».
- Generally, the lower triangle is green and the higher triangle is red , which is a good sanity check ensuring that the sections generally avoid going from a label to the previous one!
- There is indeed a poor transition probability between classes « Grounds » & « Parties » because they are far apart in a decision.
Visualisations with attention
We used the attention weights to analyse which words help the model in predicting the correct classes. In the following examples, it is very interesting to note that the words with high attention make total sense.
 Words very specific to the parties section are highlighted: avocat (lawyer) and barreau (bar).
Words very specific to the parties section are highlighted: avocat (lawyer) and barreau (bar).
 Words very specific to the composition of the court section are highlighted: président (president), conseiller (counsellor), délibéré (deliberated) and Greffier (clerk).
Words very specific to the composition of the court section are highlighted: président (president), conseiller (counsellor), délibéré (deliberated) and Greffier (clerk).
 Words very specific to the operative part are highlighted: Confirme (confirm), déféré (referred), surplus (remainder).
Words very specific to the operative part are highlighted: Confirme (confirm), déféré (referred), surplus (remainder).
 Words very specific to the operative part are highlighted: DÉCLARE (declare), RENVOIE (refer), RAPPELLE (remind) and CONDAMNE (condamne).
Words very specific to the operative part are highlighted: DÉCLARE (declare), RENVOIE (refer), RAPPELLE (remind) and CONDAMNE (condamne).
:rocket:Conclusion
This project was a great opportunity to test paragraph embeddings and attention mechanisms atDoctrine. We obtained fantastic results and our model is deployed for our users today. It enables us to complete the table of contents as a fallback when regular expressions fail to catch an explicit section title. Over the 45% incomplete table of contents of Court of Appeal decisions, we now manage to get 90% complete ones thanks to the model! :clap::clap:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK