

解耦 重构 Internet BGP SDN
source link: https://www.sdnlab.com/22498.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者简介:马绍文,邮箱[email protected]
1 介绍/Why
高清视频和云计算的蓬勃发展,带来互联网流量持续高速增长,主流云公司的Internet出口带宽都已经达到Tbps级别。 鉴于网络的拥堵大部分发生在出口互联,Edge Peering Fabric的架构设计直接影响到终端客户的用户体验, 2017年Google/Facebook对外发布了两种不同的Edge 设计理念,本文试着以Google Espresso为主详解下一代Cloud Edge的架构,并简单介绍一下Facebook Edge Fabric

Google工程师借助成功部署B4 SDN全球数据中心互联网DCI 经验,创造了个全新的Espresso Peering Fabric。总结来说,Espresso采用SDN动态调整BGP出口带宽,快速迭代最新特性,在全球TE控制器配合下,Espresso可以提供比传统BGP路由多传送13%的客户流量。同时可以显著提高每条链路利用率和端到端用户体验。有效减少了客户流量的rebuffers(减少35%-170%)。在2017年Espresso已经服务20%的Google用户,也就是说你看5次Youtube,就有一次机会Espresso控制器帮你调优转发路径。
首先简单介绍一下Google的网络,截止2018年1月,Google全球有33个数据中心,100+多个POP站点,同时在不同运营商网络中有很多Offnet Cache站点。信息从Google数据中心信息大致经过DC-POP-Cache三级网络发送到最终用户。
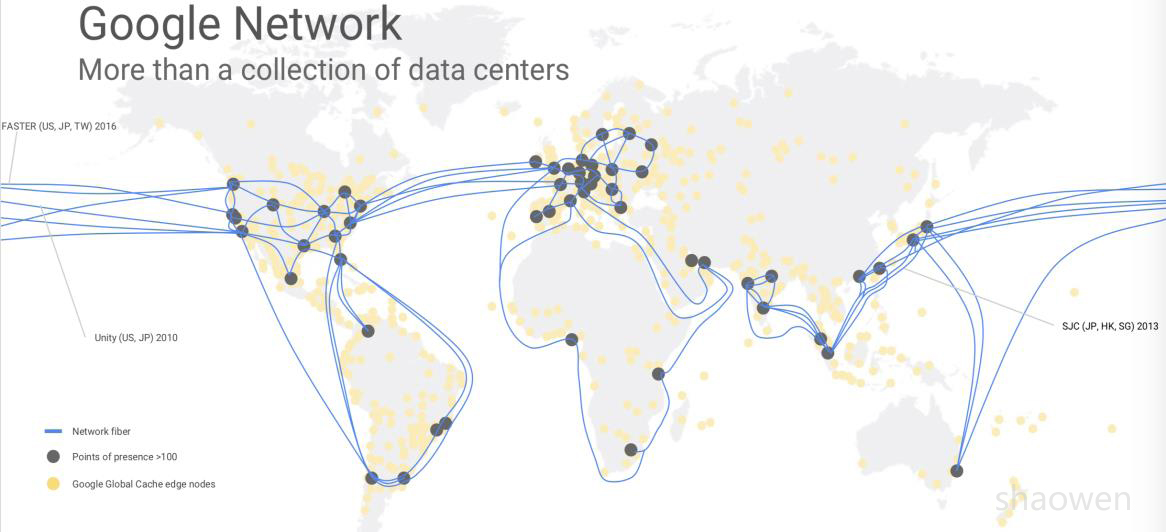
Google的广域网实际上分为B2全球骨干网和B4(DCI)数据中心互联网。如下图所示。B4作为Google全球数据中心互联采用自研交换机设备,运行纯IP网络。B2连接数据中心和POP点,采用厂家路由器设备,并且运行MPLS RSVP-TE进行流量工程调节,正在进行SDN/SR改造。简单的说,B4负责数据中心到数据中心的流量转发(Machine to Machine),B2负责数据中心到用户的流量转发(Machine to User)。关于B4详细信息,请参考Google B4广域网的前世今生
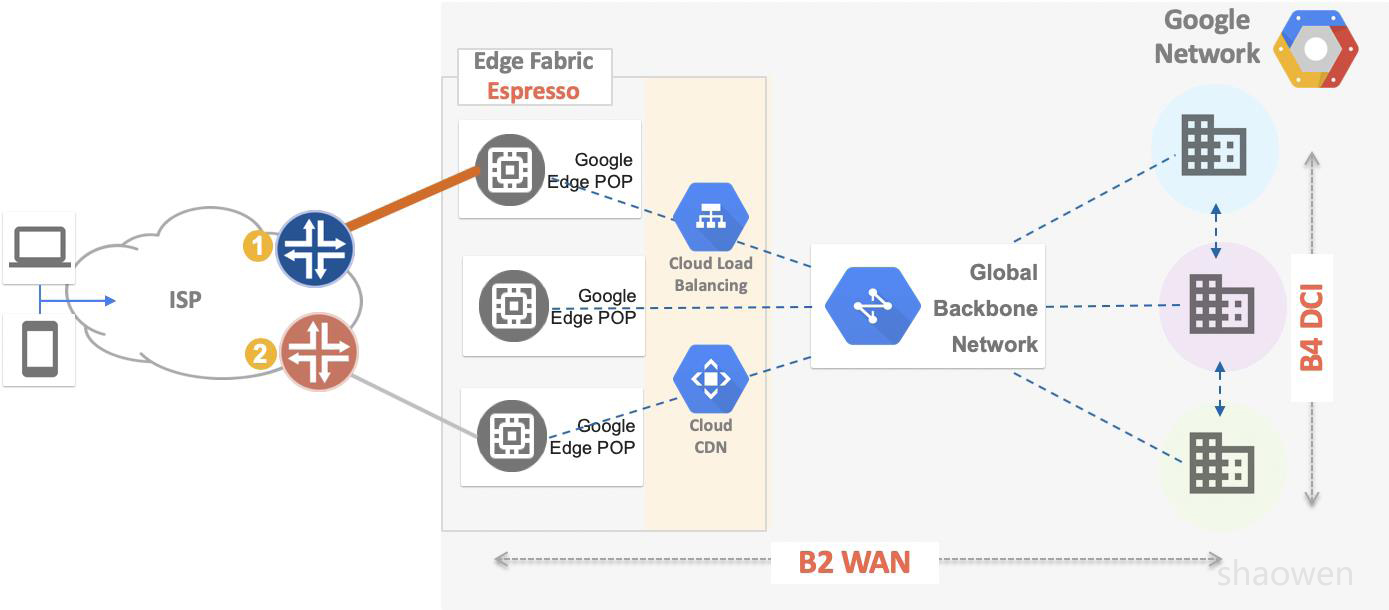
Google在ONS Summit 2017上推出了他的第四个SDN控制器Espresso(浓缩咖啡),在Metro网络中新引入SDN控制器来调整出方向(Egress)流量。在Google B4 DCI网络中,所有设备都是Google自己设计实现的。可以做到很好的端到端控制, Host/Switch/WAN全路径流量规划和可编程(Walled Garden)。如何开放的Internet BGP Peering上来提供Application Aware SDN?Google 尝试用全新的Espresso来解决这个问题。
Espresso最重要的需求是:动态调整每用户/每种应用流量,避免拥塞。现有的互联Peering网络是依赖于BGP设计的。BGP设计之初是为了提供稳定的联通性,完全没有考虑网络的动态变化,网络的需求,容量和性能都在每时每刻变化(BGP doesnt consider Demand, Capacity and Performance)。举个例子,对8.8.8.0/24的网段,可能有两个ISP或者ASBR都发送相同的路由。ASBR会根据BGP策略选择一个最优路径,比如上图中,选择ASBR1。过了10分钟,到ASBR1的链路拥塞了,只有当这个8.8.8.0/24 prefix从路径1不可达,BGP才会选择次优化路径。BGP号称是动态路由协议,实际上是非常静态的。但是BGP也不是无可救药,BGP有很多灵活的策略,比如根据Local Preference /Community/ Add Path 去调整选路。 不过需要网络管理员手动调节。 虽然BGP有这么多问题,但是大多数的传统的SP/ISP还在采用BGP互联,Google/Facebook还不能抛弃BGP,所以Google/Facebook引入SDN控制器来自动调节BGP出口流量。
Google Metro原有设计最重要的缺陷是没有全局观Metro View,没有办法很快引入新的特性。通常Google在Metro实时监测百万用户的流量带宽时延,不同应用不同优先级流量在链路分布。但是很难(受限)在路由器上进行细颗粒度的控制/改写override BGP转发行为。即便是可能去更改,也需要厂商路由器设备去配合。一般至少需要一年时间去通知厂商开发一个feature,才能成功部署在OTT网络中。无法满足Google的应用要求。
1.1 Egress/Ingress Peering Engineering
传统的流量工程仅仅 关注在IGP域部分,致力于避免网络内部拥塞。对于Cloud/Video/CDN等业务,网络的瓶颈还存在于BGP Peering部分。传统运营商能采用什么思路来解决BGP流量工程问题呢。如何找到没有拥塞的ASBR和BGP Peering链路进而提高网络传送能力?
C/J的路由专家和OTT专家讨论之后,提出了两种不同的思路来解决。核心思想都是给Peering Link分配标签,一种方式通过BGP-LU携带,另外一种通过BGP-LS携带。
- draft-gredler-idr-bgplu-epe-xx(RtBrick/Juniper)
- draft-ietf-idr-bgpls-segment-routing-epe-xx(Cisco/ Arrcus)
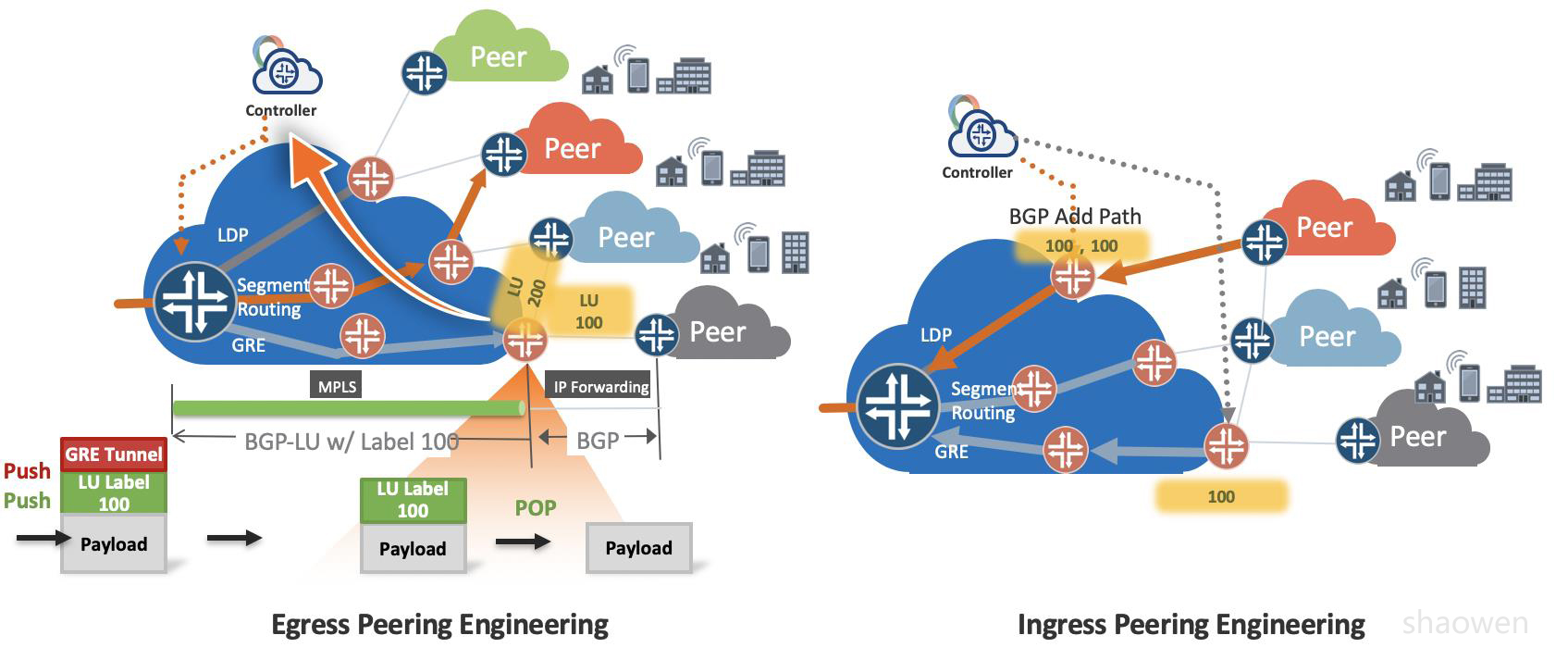
下面以BGP-LU方式为例解释一下流程:
- 引入SDN控制器搜集全网BGP prefix路径信息和Peering链路流量信息(Netflow/Telemetry)
- SDN控制器跟ASBR建立BGP-LU(3107)邻居,并且给每个Peer分配一个标签。
- SDN控制器根据实时链路状态,计算最优路径,例如每隔30秒来根据(latency/bandwidth/optical SRLG etc)来选择避免拥塞的ASBR或者某个链路。
- SDN控制器在Ingress头结点(可以是vRouter/TOR,也可以在GW router)进行策略控制:
- 外层隧道采用Segment Routing压上多个标签,外层SR标签找到ASBR,内层BGP-LU标签找到Peering
- 外层隧道也可以采用GRE/LDP等,建立Ingress/ASBR的直连MPLSoGRE隧道。在ASBR上解掉GRE封装,通过查找MPLS标签来指导Peering转发。
在BGP EPE转发路径上有个比较特殊的属性,从用户网络AS内部到Peer ASBR的转发,不需要查询Internet路由表,仅仅需要MPLS转发。
入方向(Ingress)流量根据Global LB(Google采用Meglev)或者BGP Addpath(运营商)来优化。这里不再详述。注意入方向进到ASBR流量可以是IP,ASBR只需要存储Google/Facebook内部网络的Prefix转发表(<<128K)。
利用给每个Peering分配标签特性,把完全Internet转发表的需求转移到Ingress Router(或者vRouter),可以采用新型态的LSR /Lean Core设备做Internet Peering,可以大幅减少网络投资。同时引入SDN控制器可以动态监控网络拥塞情况,动态调整BGP转发策略,极大的减少了网络的人工干预。
关于更多详细的BGP EPE解决方案,请参考我们在2016年初在New Zealand Apricot上的演讲。http://t.cn/RnXyHhR
2 Espresso详解
前面讲到Espresso来改造Google Metro,通常来讲Metro提供三个基本的功能
- 路由器:提供BGP路由与合作伙伴对等交换。
- 服务器池:负载分担和CDN静态缓存内容分发
- 服务器池:提供反向TCP代理
全新的Cloud Edge架构设计需要支持超低时延应用,提供重要的Anti-DDoS功能,并且能有效利用CDN减少经过云骨干网的流量。

从上图可以看到主流的OTT都部署了反向web代理。以Facebook为例,从首尔访问俄勒冈的数据中心,在跨越太平洋光缆一般要引入75ms的单程延迟。如果没有采用反向web代理(图左),从客户开始访问到收到网页,需要600ms。利用在东京的POP点里面的反向Web代理之后,延迟可以降低到240ms。用户体验得到极大提高。
2.1 Espresso系统架构
为了更好的规划Metro里的流量调度,Espresso引入了全球TE控制器(B4中也采用了)和本地控制器(Location Controller)来指导主机发出流量选择更好的外部Peering 路由器/链路,进行per flow Host到Peer的控制。
并且解耦了传统Peering路由器,演进为Peering Fabric和服务器集群(提供反向Web代理)。
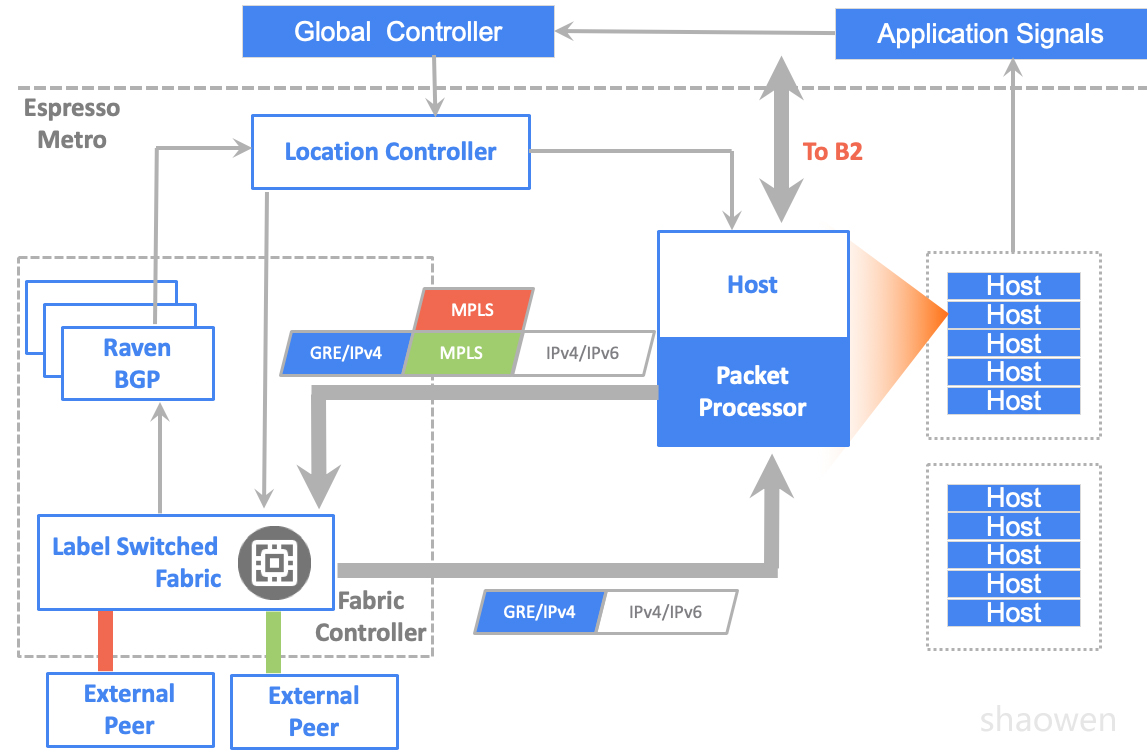
控制和转发流程:
- 外部系统请求进入Google Metro,在Peering Fabric上被封装成GRE,送到Meglev负载均衡和反向web代理主机处理。如果可以返回高速缓存上的内容以供用户访问,则该数据包将直接从此处发回。如果CDN没有缓存,就发送报文通过B2去访问远端数据中心。
- 主机把实时带宽需求发送给全局控制器(GC)
- GC根据搜集到的全球Internet Prefix情况,Service Class和带宽需求来计算调整不同应用采用不同的Peering路由器和端口进行转发,实现全局出向负载均衡。
- GC通知本地控制器(LC)来对host进行转发表更改。同时在PF交换机上也配置相应的MPLSoGRE 解封装。
- 数据报文从主机出发,根据GC指定的策略,首先找到GRE的目的地址(PF),PF收到报文之后,解除GRE报文头。根据预先分配给不同外部Peering的MPLS标签进行转发(注意,采用集中控制器,不需要引入BGP-LU来分配MPLS标签)。如上图所示,如果采用红色MPLS标签,就会转发给红色链路。
下面针对不同的子系统详细讲解。
2.2 全局和本地控制器
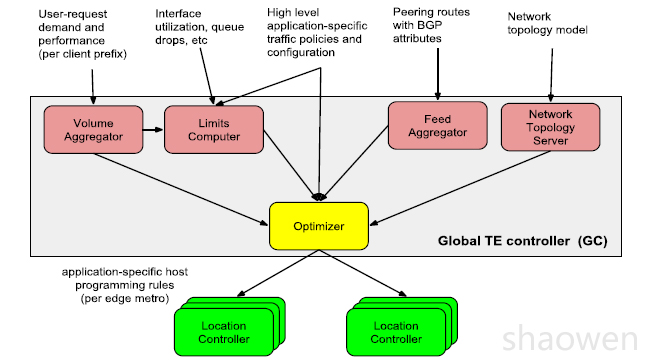
全局控制器是一个分布式系统,持续不断的搜集各类信息,并且定期产生针对应用优化过的转发规则。进行并且通过本地控制器(LC)在各个区域发布。本地控制器提供本地决策,来快速应对本地链路和Prefix的变化。
为了实现应用感知,全局控制器需要搜集:
- BGP Peering/Prefix信息,类似BMP全网路由和Peering关系。
- 用户带宽和性能需求,通过L7 Proxy搜集每用户带宽,延迟需求,并汇总。一般针对/24目的路由产生相近的延迟数据。
- PF出接口每队列链路利用率
全局控制器的输出是一个Egress Map规则,对特定{ POP | Prefix |Class },选择出口{ ASBR | Port }。
本地服务器收到GC的应用优化规则,结合从EBGP过来的实时peering路由信息,来产生主机转发表。为了Anti-DDoS攻击,还需要LC来下发大规模ACL转发表项到主机。一台本地控制器可以控制大概1000台服务器,持续不断的更新主机转发表项和ACL。

上图可以看到,LC 收到GC 转发规则之后,对每个主机,需要产生不同的{ Prefix | Application
Class } 采用不同的出口{ PF | Port | %},并且迭代找到相应的GRE/MPLS 封装。
2.3 解耦Peering Router 演进到Peering Fabric
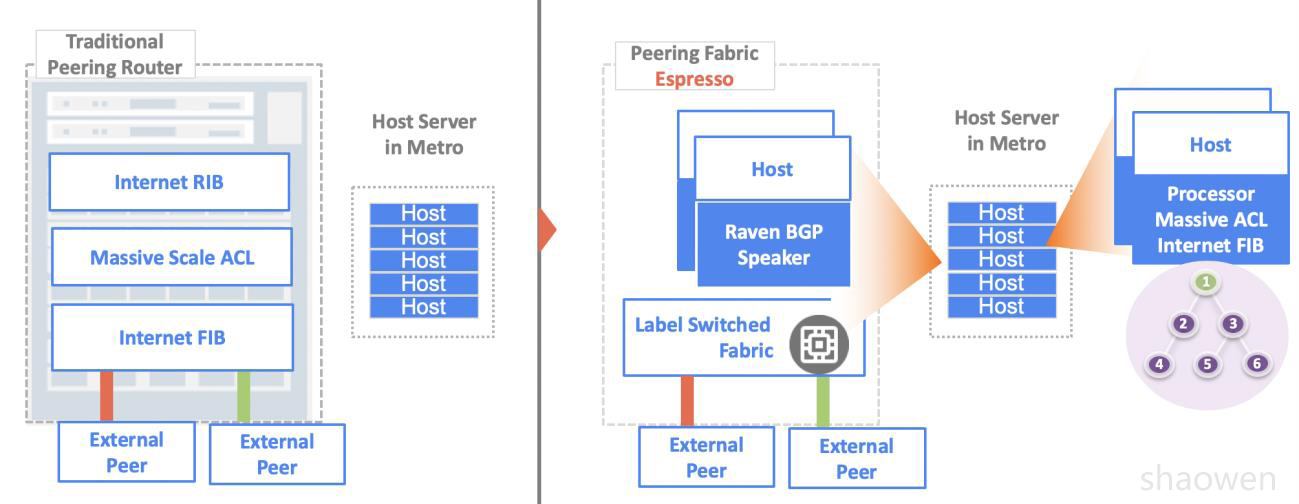
Espresso 另一个主要的设计原则是解耦路由器,演变成Peering Fabric。
传统的Peering 设备,由厂家统一提供软件和硬件。软件新特性开发周期过长。把非必要的功能从
Peering 路由器拿掉,仅保留最简单的MPLS(Label-Switch Fabric)数据转发平面。SDN 软件特性
开发工作由Google 工程师主导,可以极大提高网络可编程性(Programmability):
1. BGP Speaker 功能,从路由器移出来,采用Google 自研Raven BGP 协议栈,运行在专用服务器上,可以支持更多的Peering,运行更复杂的优化算法,更精细的路由器控制。仅仅实现必要的Feature。
- a. 支持多核和Scale Out 控制平面,支持BGP Graceful Restart
- b. 同一个Peering fabric可以运行多个Raven实例。多个session可以平均分配到Raven实例。当Raven出错时,仅仅影响少量的BGP session
- c. 之前采用Quagga,面临一些问题,Quagga只有单线程,C语言调试工具太少等。
2. Host集群:出方向(Egress)报文Internet路由查表/封装和ACL访问控制列表等放到在Edge里面的大规模服务器集群。
- a. 每个Host里面都存放完整Internet路由表。IPv4 FIB采用Compressed Multibyte Tire 算法,采用Binary Tire做IPv6 FIB查表。
- b. Espresso现网运行环境每个Host中,大概有190万Prefix/Service Class Tuple表项,占用 1.2GB内存。 峰值可以做到每Host传送37Gbps报文,大概3Mpps。查FIB表CPU占用率 2.1-2.3%左右。
- c. Host里存储大规模Internet Facing ACL(MPLS Switch硬件表项太小),配合支持Anti-DDoS等业务,一小部分常用ACL放到PF里面进行业务线速转发。
3. Peering Fabric(PF, MPLS Switch):进行MPLS转发,仅支持小规模FIB表和ACL表项。减少路由器成本
- a. 采用Openflow来编辑MPLS转发表,并且配置IP-GRE规则来匹配BGP协议报文发送去相应服务器,并生成MPLSoGRE转发表。
- b. Switch里面保留常用ACL(小规模)线速转发。5% ACL可以匹配99%的流量。在软件Host里面保存另外95%的ACL,从PF透过GRE tunnel把流量转到Host做进一步处理。
4. Peering Fabric 控制器
- a. 映射BGP Peering到不同的Raven实例。
- b. 管理PF转发表(后续详解)
2.4 配置管理红色按钮-Big Red Button
Espresso采用自动化Intent-Based配置管理工具。 收到人工可读的意向(Intention)配置管理工具会翻译详细的可以被设备理解的配置。
为了安全性和易用性考虑,Espresso提供了一个大红按钮(Big Red Button,BRB)配置管理功能。管理员可以很容易安全的关闭部分/全部系统功能:
- 可以告诉LC下发给所有主机采用本地最佳路由,不用接受全局控制器指令。
- 可以移除一个或多个BGP邻居。
- 点击BGP管理GUI可以移出流经这个Peer的流量。
3 Facebook Edge Fabric简介
2017年Sigcomm大会,Google和Facebook同时发布了两种不同的Edge架构。下面简单介绍一下Facebook Edge Fabric的架构。
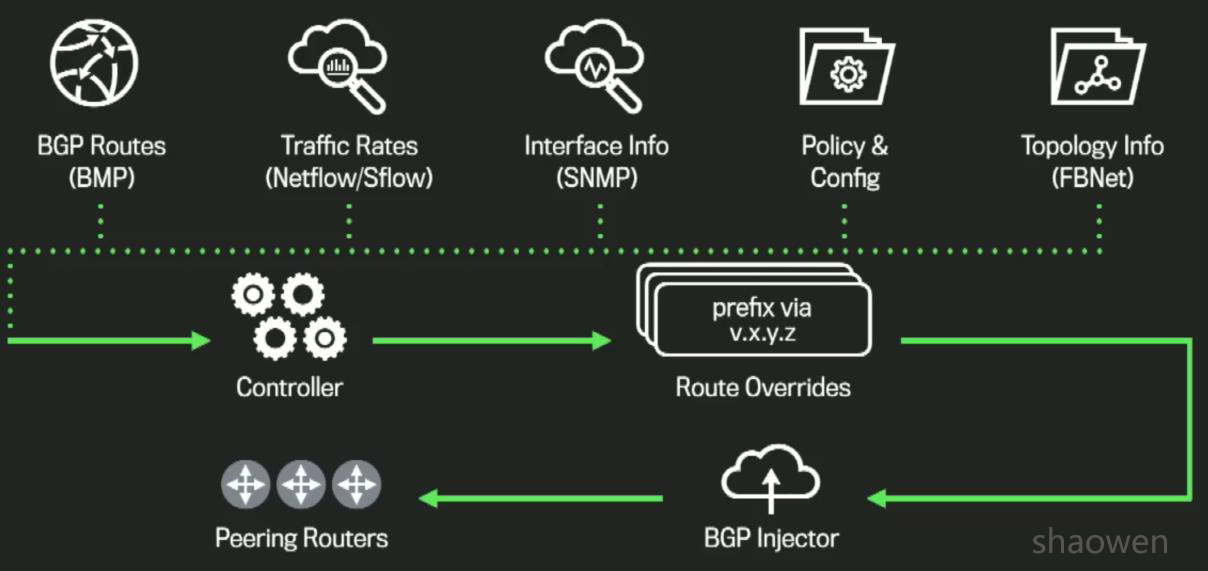
- 首先,Edge Fabric也引入一个SDN/BGP控制器。
- SDN控制器采用多重方式搜集网络信息
- 控制器和多个Peering Router之间建立BMP session,搜集Prefix/Peer信息。
- 控制器利用Netflow/SNMP搜集接口/Prefix流量。采用Sonar来监控用户的latency
- 控制器搜集现有的policy和网络拓扑信息。
- 控制器基于实时流量等相关信息,来产生针对某个Prefix的最优下一跳。指导不同Prefix在多个ASBR之间负载均衡。
- 控制器和每个Peering Router建立另一个BGP 控制session,每隔30秒钟用来改写Prefix,通过调整Local Preference来改变下一跳地址。
- 因为BGP不能感知网络质量,Edge Server对特定流量做eBPF标记DSCP,并动态随机选一小部分流量来测量主用和备用BGP路径的端到端性能。调度仍然发生在PR上,出向拥塞的PR上做SR Tunnel重定向到非拥塞的PR上.如下图所示:
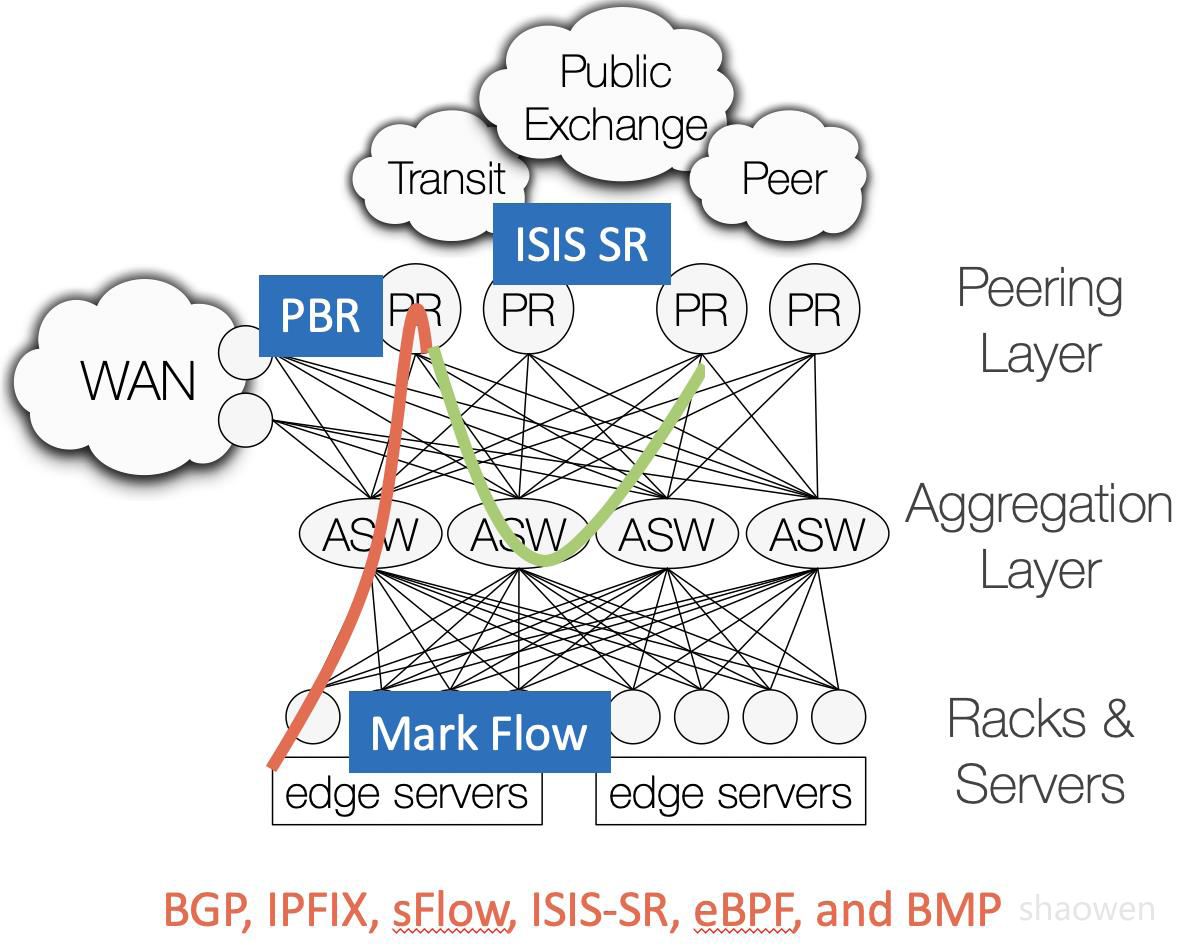
从上图可以看出Facebook采用的都是业界主流厂商支持的协议来实现Edge Fabric。同时有这样一些限制:
- SDN控制器单点控制PR设备。如果PR设备已经Overload,需要通过PBR和ISIS SR Tunnel转移到另一个没有拥塞的PR,流量路径不够全局优化。
- 控制器只能通过Prefix来控制流量,但是同一个prefix,可能承载视频和Voice流量,带宽和时延要求不同,Edge Fabric没有Espresso那么灵活。
Facebook介绍,最早他们的尝试过集中不同的方案,从Host选路到PR,都不太成功。
- 从Host建立LSP到PR
- 从Host 标识DCSP,PR根据DSCP转发到不同端口
- 从Host采用GRE tunnel到PR。
最后选择了BGP Inject@PR方案,他们认为是现阶段比较适合的方案。在最近的Network@Scale 2018大会上,Facebook工程师说,未来Edge Fabric架构可能考虑转向BGP EPE和Segment Routing。
下表我们总结了两种方案的比较,请参考。
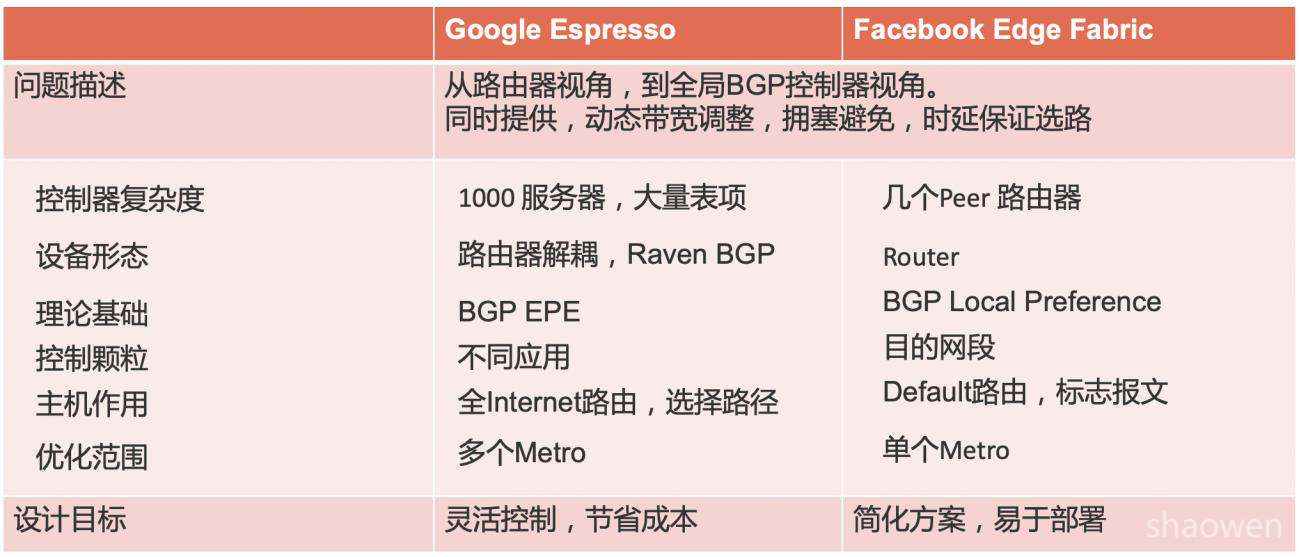
4 总结和展望
本文介绍了三种不同的思路来解决BGP出口流量调度问题。
- BGP EPE:采用标准协议为主,SDN控制器通过BGP LU/BGP-LS/Netflow方式选路。
- Facebook Edge Fabric:SDN控制器计算最佳路径,BGP Local Preference 方式来路由注入
- Google Espresso:主机存放完整Internet路由,SDN控制器找到相应ASBR/Port.

从端到端架构图中,可以看出在一个POP或DC WAN,Core/Aggregation设备大多已经采用Lean /BGP Free Core解决方案不用存储完整Internet路由。通过Espresso,Google改造/解耦了Peering/ASBR路由器,通过把大部分软件控制功能移到服务器。PF设备可以采用更简单的MPLS Switch(QoS能力强,大Buffer,小型FIB表,小型ACL表,类似B公司Jericho系列)。加上之前B4已经采用了CLOS架构的Stargate Switch设备。
Google已经成为业界第一个在WAN网络中没有采用传统Router的OTT公司。全网已经改造为Switch/Server的架构。对于在POP和DC中有大规模服务器的Google来讲,在POP中的每个Server处理内容的基础上加上1.2GB内存和2-3%的CPU来实现Internet路由查表和隧道封装基本上是可以接受的。
相比Facebook Edge Fabric,Google Espresso完美的解决了Application Aware TE问题,但是开发工作量也是巨大, Google为Espresso开发了很多全新组件:
{ 全新层次化SDN控制器GC/LC,全新BGP协议Raven实现,全新主机IPv4/IPv6 转发表, 全新路由器解耦PF MPLSoGRE隧道接口,实时L7 Proxy流量需求 }
Espresso 仅仅改造了Metro POP, 今后会不会在B2采用类似Espresso架构来打通Backbone和Peering Fabric进行跨越B2全网流量调度?期待Sigcomm 2019 Google能够揭晓更多B2改造成果!
国内OTT Metro改造展望
云计算进入下半场,企业上云(Cloud Onboarding),网络SDN动态调整的能力越发重要。从云到网需要端到端联动{ VPC/DCI | Metro | Cache | SDWAN },OTT SDN全网改造势在必行。
Google的网络改造方案是否过于复杂(Over Engineering)?Facebook Edge Fabric过于简化,能否找到一条更适合中国OTT的技术路线来改造POP点?本人认为:
1. 技术路线应该选择类似BGP EPE方案,跟Google保持一致。
- a. 不要采用BGP Inject方式,防止PR设备过载。并且可以做全局调度
2. 有条件情况下尽量采用Segment Routing + EPE 方式
- a. Google采用MPLSoGRE,是因为Metro/PoP一般比较小,内部也不会太拥塞。如果从超大数据中心跨越骨干网,最好是采用SR+EPE,避免鱼形TE问题。
- b. 对于BGP协议在服务器实现的方式,入方向BGP协议报文可以走GRE。
3. 跟云平台和OTT网络用户确定流量需求接口,支持Application Aware SDN
- a. 不光基于Prefix进行流量调度,最好分不同业务Class来指导转发。
4. 设备形态
- a. 大云公司可以尝试BGP跑在服务器,并且在Host支持IPv4/IPv6全internet转发表。但是需要工程师不断调优。
- b. 建议采用PTX/NCS/Jericho/Jericho2等类似设备,尤其是10T盒子/Chassis内置HBM2,一般1M FIB起跳,减少转发表没有太多设备成本节省。
随后我们会继续详解Google/Facebook/AWS 等OTT网络架构,下篇想谈谈Facebook DC, Fabric Aggregator, Express backbone,Edge Fabric和Open/R等,接下来也会详解AWS网络和云架构。敬请期待。
最后非常感谢Google 团队的开放/开源精神,在Youtube/SIGCOM公开了很多详细的技术细节,使得我们能够管中窥豹。如果希望跟作者讨论『Cloud/OTT SDN网络架构』,请扫码入群。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK