

Programming as interaction: A new perspective for programming language research
source link: https://www.tuicool.com/articles/hit/IjMjE3U
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Programming as interaction A new perspective for programming language research
In May, I joined the School of Computing at the University of Kent as a Lecturer (equivalent of Assistant Professor in some other countries). When applying for the job, I spent a lot of time thinking about how to best explain the kind of research that I would like to do. This blog post is a brief summary of my ideas. I'm interested in way too many things, including philosophy and design anddata journalism, but this post will be mainly about programming language research. After all, I'm a member of the Programming Languages and Systems group !

Unlike some of my other posts about programming languages , I won't try to convince you that we should be studying programming languages completely differently this time. Instead, I want to describe one simple trick that will make current programming language research much more interesting !
A lot of programming language papers today talk about programs and program properties. In statically typed programming languages, we can check that a program \(e\) has certain type \(\tau\) , which means that, when the program is run, it will only produce values of the type. This is very nice, but it misses a fundamental thing about programming. How was this program \(e\) actually constructed?
When programming, you spend most of your time working with programs that are unfinished . This means that they do not do what they are supposed to be (eventually) doing and, very often, they are not well-typed or even syntactically invalid. However, that does not mean that we can afford to ignore them. In many cases, programmers can even run those programs (using REPL or using a notebook environment). In other words, programming language research should not study programs , but should instead study programming !
I'm also writing this because I'll soon be looking for collaborators and PhD students, so if the ideas in this blog post sound interesting to you or if you've been working on something related, please let me know! You can get in touch at @tomaspetricek or [email protected].
We'll have funding for PhD students from September 2019 and I'm also working on getting money for a post-doc position. All of these are open ended, so if the blog post made you curious (and you wouldn't mind living in Canterbury or London), definitely reach out!
Why we should study programming as interaction
What do I mean when I say that we should study programming ? When you are programming, you are not writing code by starting on the first line, furiously typing and ending on the last line. (If a theoretician says, given a program \(e\) , this might well be how the program came to existence.) Instead, you start by writing some small piece of code, then test it, refine it, add some more code and so on. You also typically use various modern editor tools such as auto-complete. Let's look at a simple example using F#.

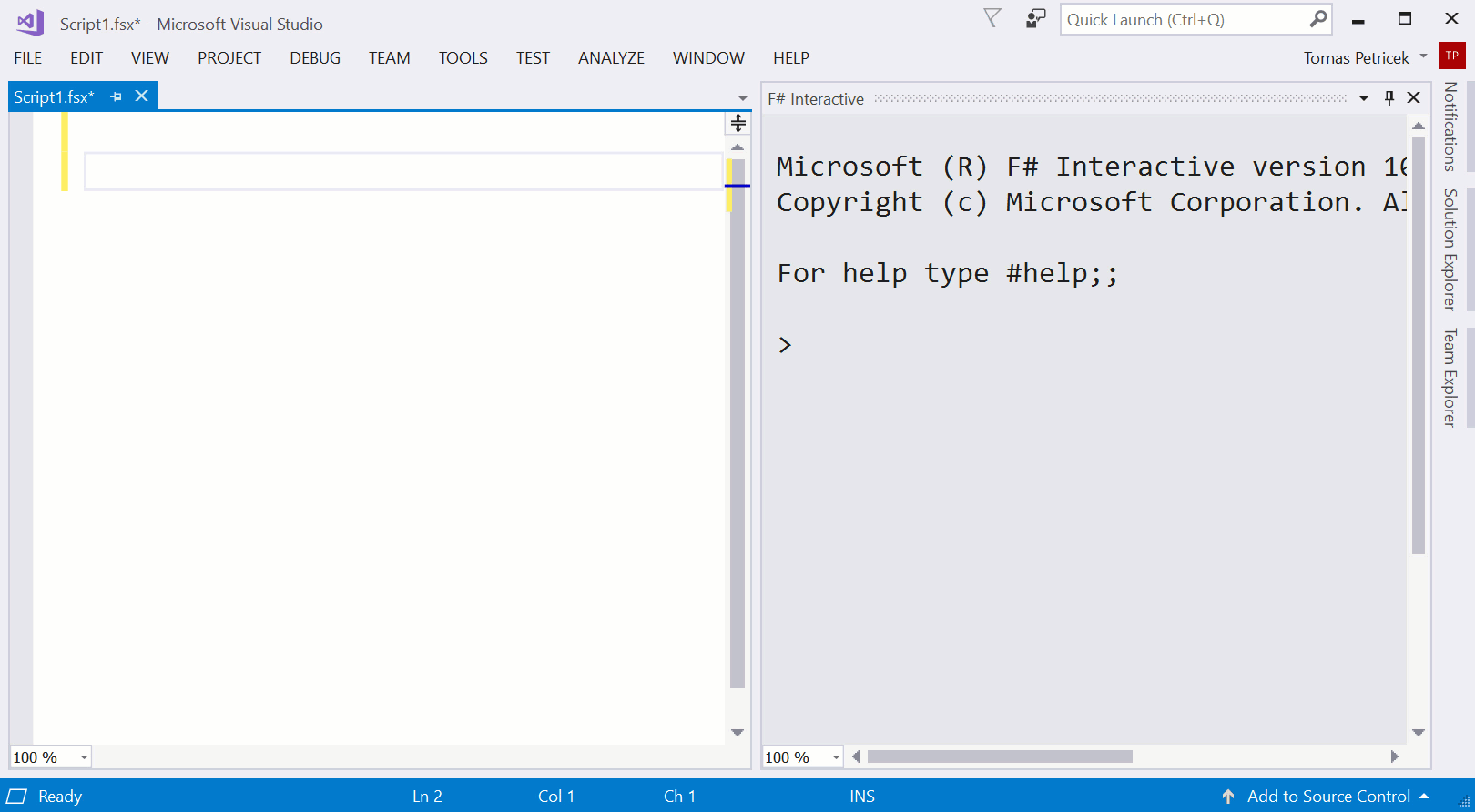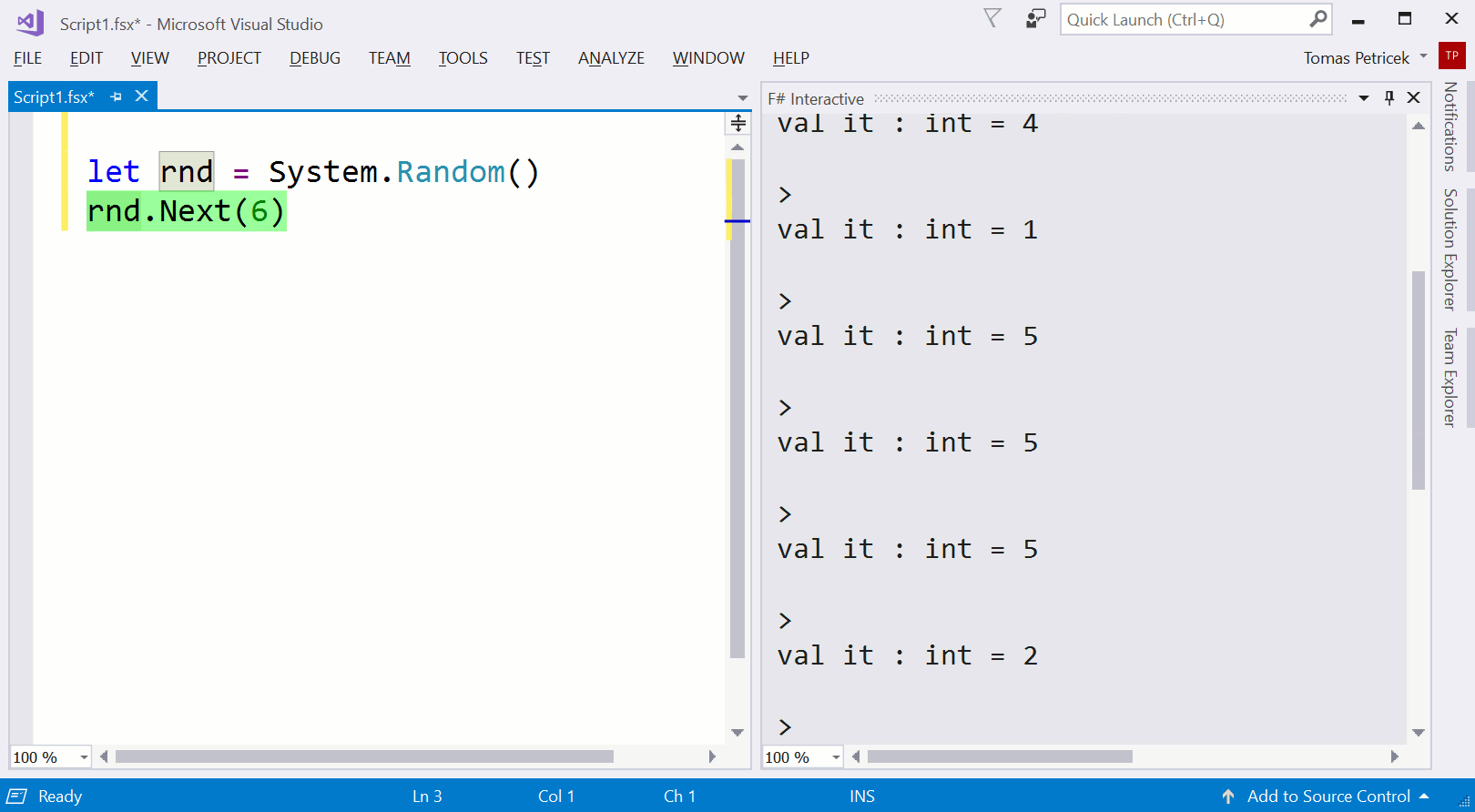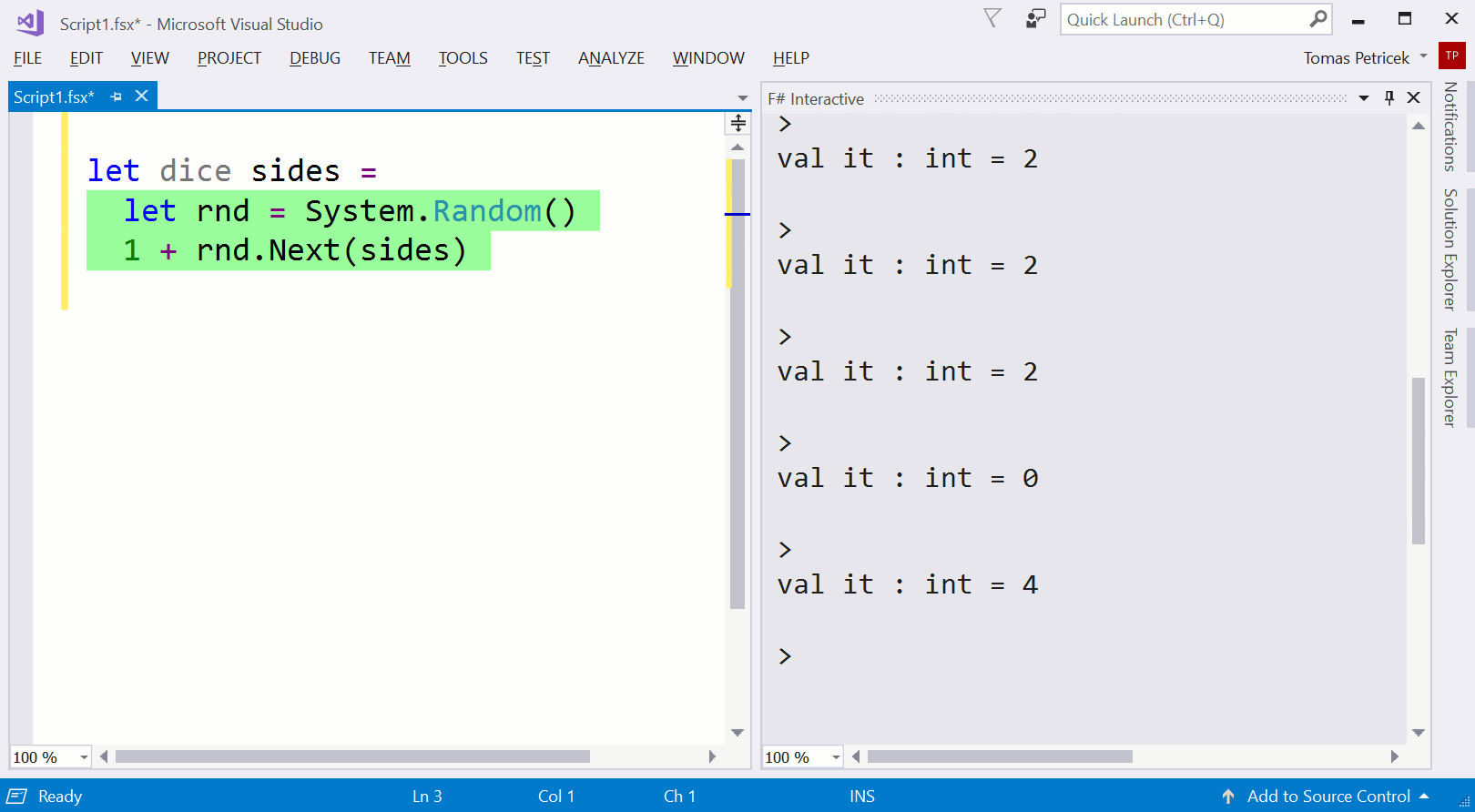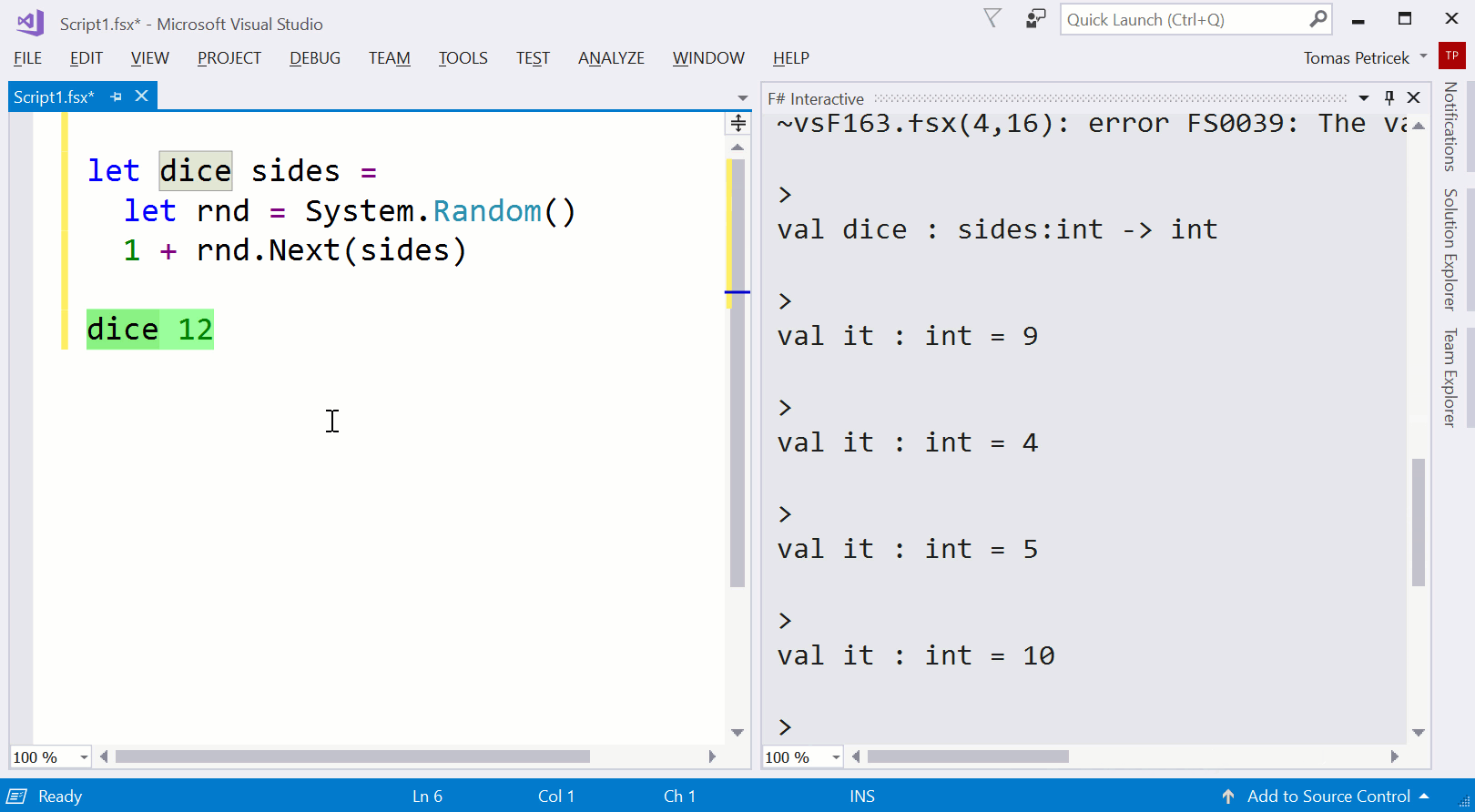
Example 1.Writing a function that models a dice using F# and F# interactive REPL to run parts of code interactively during the development.
(Click on the image to play it and then click again to stop it or open the image in a new window .)
{kind=link}
I intentionally picked a very basic example, but even this illustrates a number of interactions that happen during programming. Now, imagine that they were not just interactions with the editor, but actually something that the programming language understands!
-
Code completion.The demo uses auto-completion to enter some long names. All modern editors do this, but few language designers think about this. Selecting an item from a list is way easier than typing a name or a piece of code. How could we design a language that makes as much as possible available through selection ? (I did a bit of work on this in my dot-driven data exploration paper.)
-
Running code in REPL.In the demo, I use REPL to check that my code returns values in the correct range. In F#, you can do this by selecting block of code and evaluating it, but alternative model is to type directly into the REPL console. Again, this is just an editor feature and the language does not understand it. What if it helped me to make sure that the code I select will run?
-
Introducing a function.After testing the code, I wrap it in a function. Many editors have a refactoring for doing this, but again, the language does not know how the function was created. If it knew that, could it then suggest that the value 6 might be a good example input for the parameter
sidesand perhaps even use it automatically when I try to run the body in REPL? (I wrote about problems with functions on this blog before.)
My first example was writing extremely basic piece of code in a statically typed functional language. When creating a service or an application, you want to produce a program as the final result, even though you may use REPL, auto-complete and refactoring tools along the way. Things get even more interesting if we look at typical data science workflow. In data science, the end result is often not the program, but instead some insight, model, or a visualization.
This needs a more interactive environment that makes it easy to run snippets of code on the fly and see results immediately, which is why notebooks systems such as Jupyter became so popular. When writing code in notebooks, there is even more room for studying programming interactions. The following is a small example of loading CSV file into F# notebook hosted on Azure Notebooks .

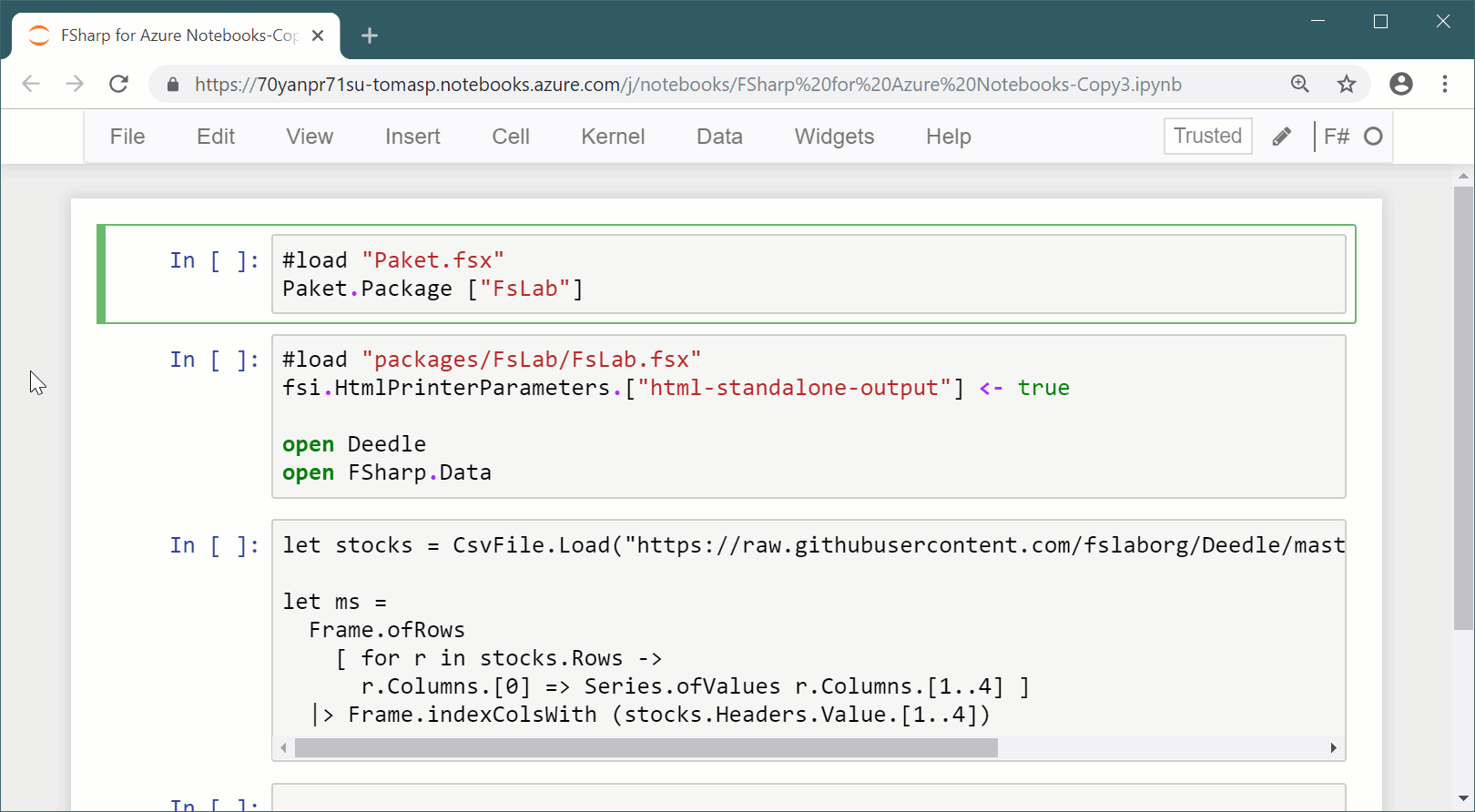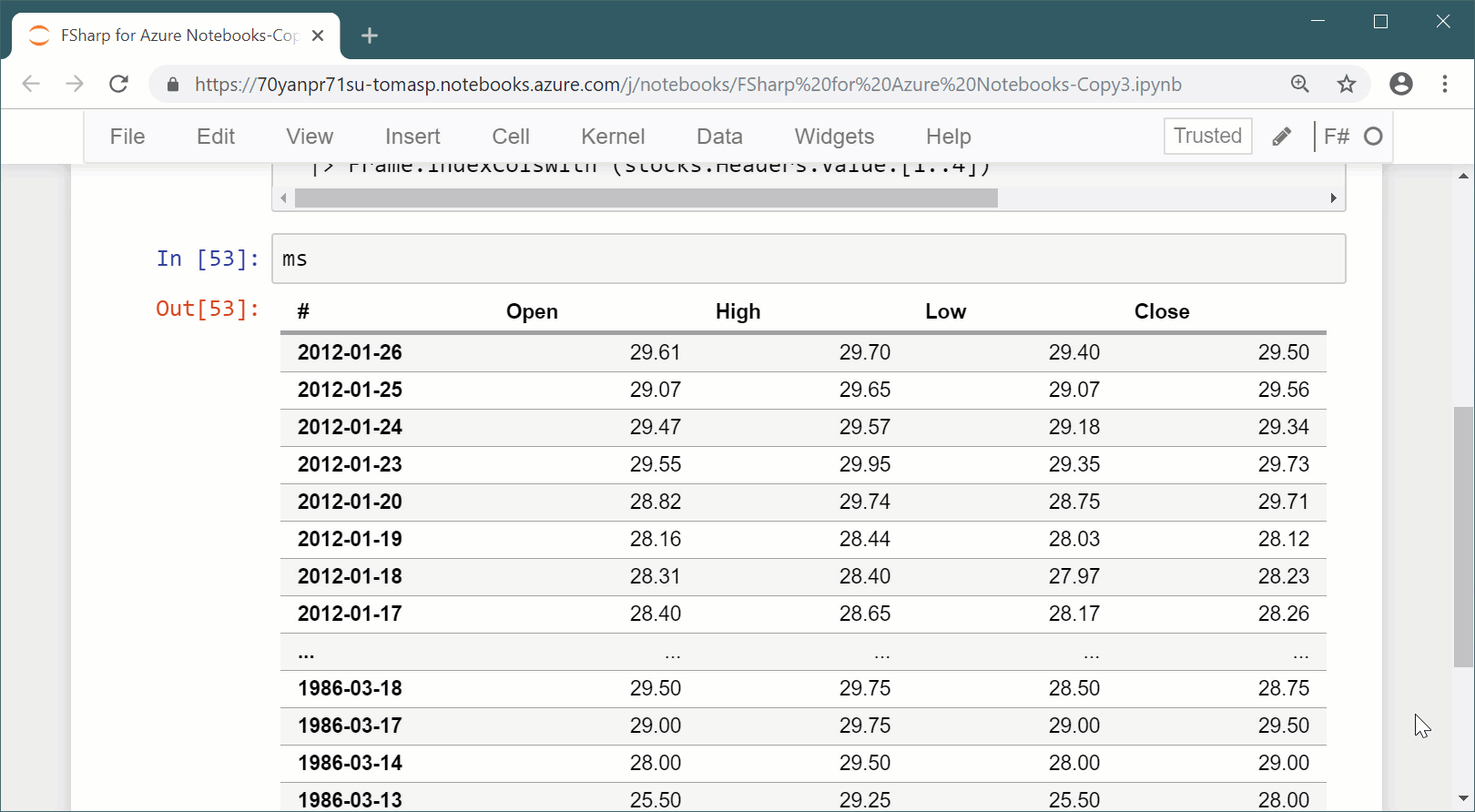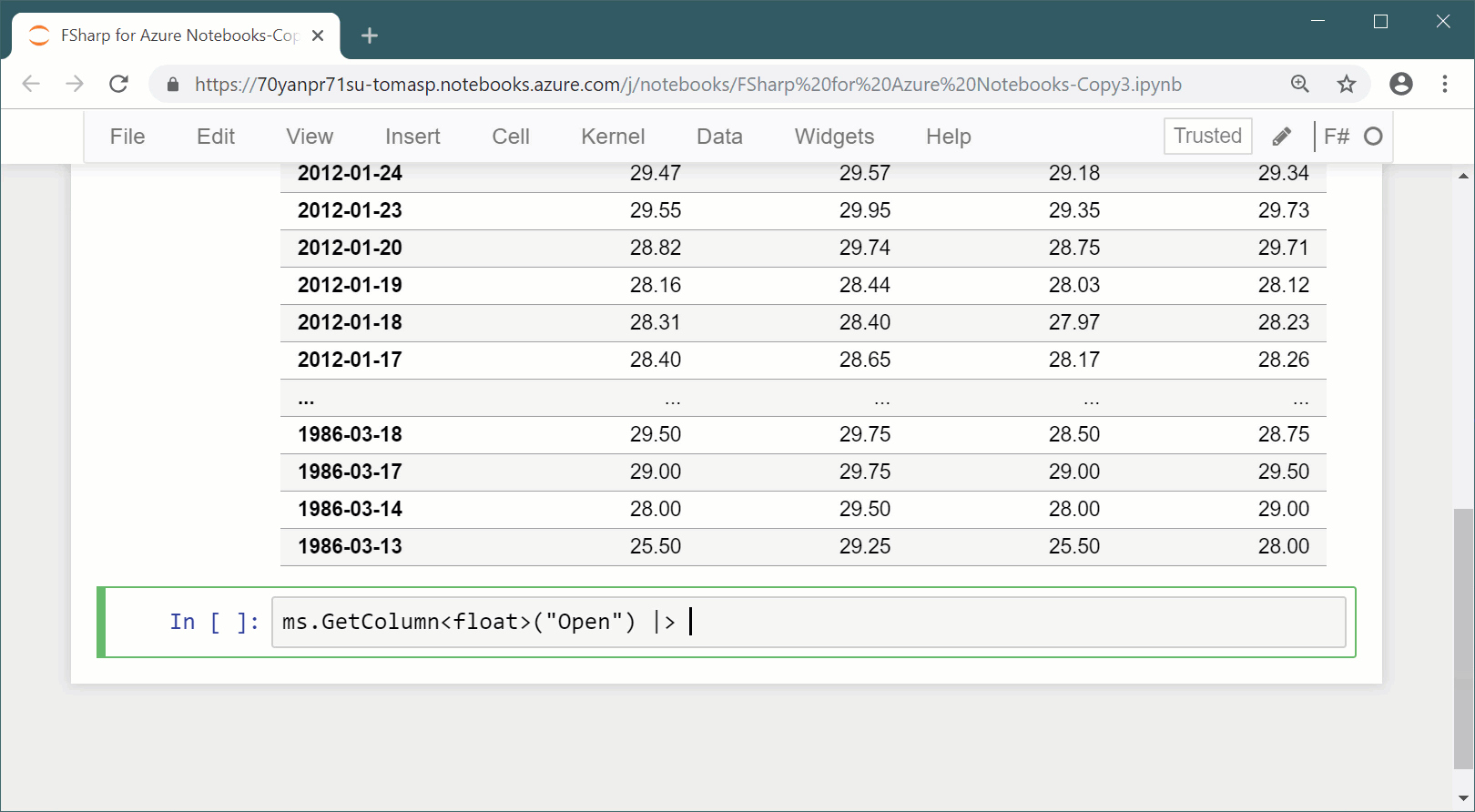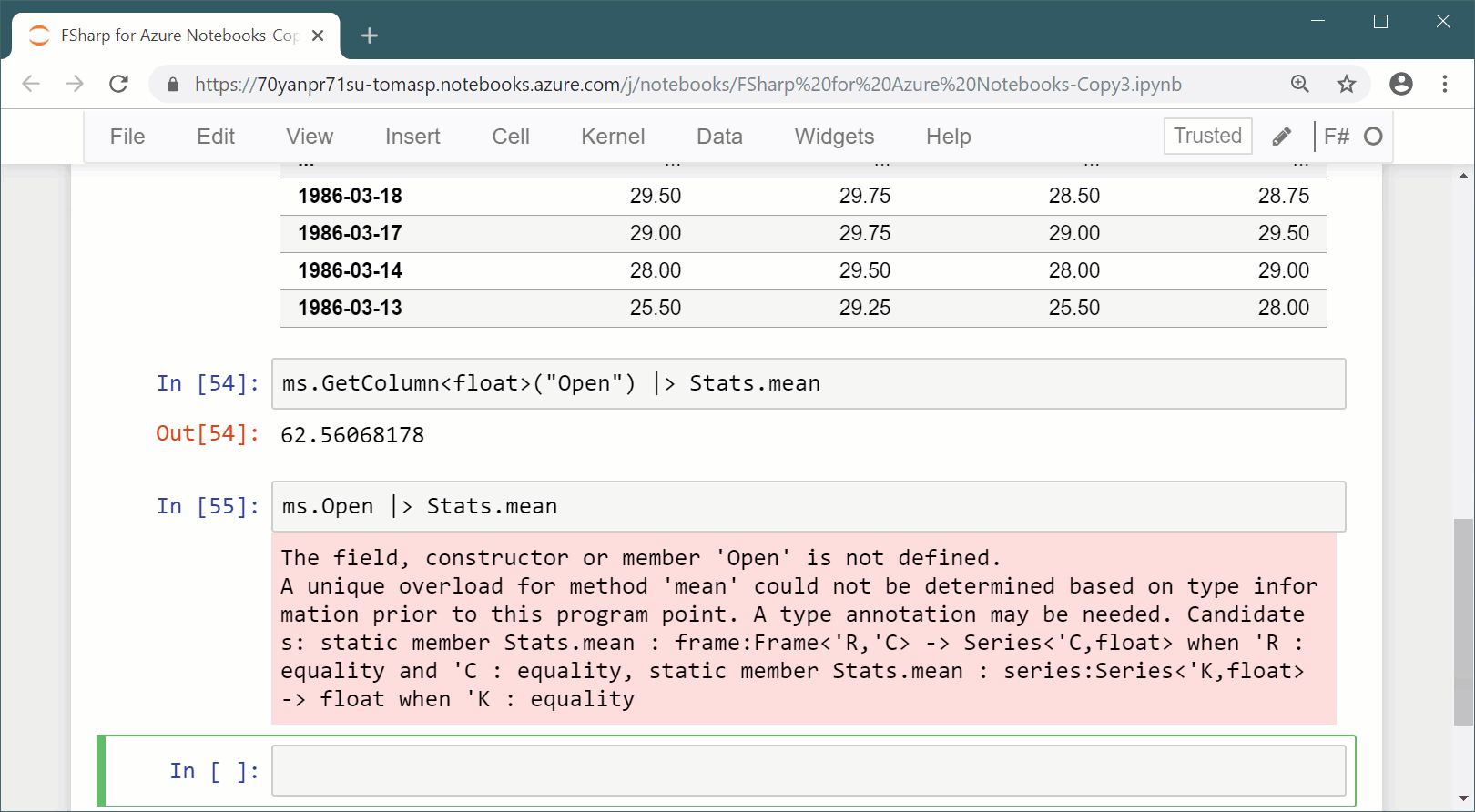
Example 2.Running code that loads stock data and calculates an average opening price using an F# data frame library in Jupyter notebook.
(Click on the image to play it and then click again to stop it or open the image in a new window .)
{kind=link}
The example uses the Deedle library together with a CSV parser to read data from the internet and do a simple calculation with it. I first run a bit of code I wrote before and then try to write some new code to perform a simple calculation. There is a couple of interesting things happening in notebook systems.
-
Understanding the dependencies.I run cells from top to bottom, but that's not always required. You can go back and rerun an earlier cell. What your program returns depends on how you interact with it! Could a better data science language understand the dependencies between cells and recommend what interactions are reasonable and which are not? And could the system also remember how we interact to make the results reproducible? (Our work onWrattler in the Alan Turing Institute is looking into this.)
-
Live previews and editors.An inherent part of any notebook system is that it displays previews of results such as the data frame in this demo. In Jupyter, this happens only when you explicitly run the program, but what if the previews were created on the fly as you write code? How do we design programming interactions so that code always has a valid preview? And how do we design libraries that allow us to gradually construct results, such as data visualizations? (Live previews in TheGamma do some of this.)
-
Typing for notebooks.In the example, the type of the
msdata frame isFrame<DateTime, string>. This says that rows are indexed byDateTimeand columns are indexed bystring, but the type does not know anything about the names and types of the columns in the data frame. This is hardly surprising, because the data come from a live URL! Consequently, we have to write rather uglyms.GetColumn<float>("Open")rather than justms.Open. However, what if running the cell that loads the data gave the type checker more information about the data frame and the type in a later cell was refined based on this information?
Theory of programming interactions
There are many kinds of programming interactions that happen during programming. Some of those have been studied in programming language research already. For example, my new colleagues are building verified refactorings . However, this is still treating programs just as lines of source code or parsed expressions and the refactoring happens on the side by transforming one program into another.
I believe that we can achieve more interesting things if we stop thinking about programs as code (or expressions), but instead think of them as results of series of interactions . This representation will make us think about programming differently, because the key entity will no longer be a program , but the programming process. However, having a record of how the program was constructed will also let us build new programming tools.
Different kinds of interactions
What kinds of interactions can be used to create a program? I do not have a complete list, but the following are some of the interactions I find important:
- Editing - There will always be some basic coding interactions that will just modify some part of the source code or edit some part of the expression tree.
- Selection - Selecting from an auto-complete should be treated as a separate kind of interaction.
- Evaluation - When you run some part of the code in REPL, we should remember this happened, because it gives us useful information that we can use later.
- Copy and paste - Copy and paste is frowned upon, but it's often the easier and more readable than using complex abstractions. Knowing how it was used lets us solve some of the problems attributed to it.
- Refactoring - All the different refactorings that exist should also be treated as recorded interactions that were used to construct the program.
This list is mostly based on what usual editors these days offer. The list does not even include different kind of interactions that might happen in more sophisticated notebook systems. Very likely, new programming languages and new editors will make it possible to have even more fine-grained information about different interactions. However, treating a program as a result of a series of the above interactions (as opposed to just the final text) already makes it possible to implement a number of interesting tools!
What new tools could offer
Let's say that our programming environment keeps a list of interactions (such as those above) that happened during programming. Similar pattern keeps appearing in many places in software. If you wish, you can think of this as a very fine-grained version control system (storing a diff, with a commit after each interaction). Alternatively, you can think of this as an editor based on the idea of event-sourcing or a system following the Elm-style architecture. What kind of new things would this enable?
-
Reliable copy and paste.If copy and paste was an interaction, the environment would know that a certain part of code is copied from somewhere else. If you changed it in one place, the editor could ask whether you want this change to happen just in this one place or in all other places where the code appears. (The Subtext programming language treats copy and paste in this way.)
-
Interaction-based typing.Type checking can also be done over the interaction list, rather than over the expression tree of a program at one point in time. This means that a type can be, in part, based on earlier interactions including running a part of code. It can, for example, be based on the structure of data loaded in earlier steps (as in notebooks) or even use sample values from REPL to give a probabilistic type (floating-point number with values that are typically in a certain range).
-
Direct program manipulation.This is a more fancy idea that could be very useful in the data science context. If we can give preview of a data frame as a table, could we also allow the user to edit data in the data frame? This could be tracked as another kind of interaction (making the program reproducible), but it should also play well with extract function refactoring, which would produce a function that applies the same edit operation to a given input.
-
Automatic selection correction.Let's say that you write a program and select a member
Substrbut then the library author renames the member toSubstringusing the rename refactoring. If the library is also a list of interactions, we can automatically suggest a fix for the user code using the library. If the library is opaque, we could at least go through all selection interactions that fail against the new version and ask the programmer to make their own choice. -
Semantic merging.Finally, we could also have a more clever merging algorithm than just diff3. Given two sequences of interactions that diverge at some point, we would need to find a way to append all the new interactions so that the resulting program makes sense. This could, for example, mean that refactoring done in one branch (and recorded as an interaction) will not conflict with manual edit of the refactored code in another branch.
All of these ideas are based on the simple list of interactions above, but I suspect that once someone actually implements a programming language based on these ideas, it will become much easier to imagine other kinds of interactions and other kinds of new tools and operations this would enable.
Related work and historical notes
As I mentioned throughout the blog post, there is a number of related ideas. The Elm architecture (also known as the Model-Update-View pattern) follows a similar idea by having a list of events and computing the current state from the history of events. In an enterprise architecture, similar idea appeared as Event sourcing . Here, you all actions done in a system are recorded as events and the system state can be obtained by replaying the events. Treating programs as list of interactions is very similar to these. We store the list (history) of interactions that were used to construct the program.
Focusing on interactions is not a new idea either. The Smalltalk system is a great example of a programming environment that focused on the human interaction. Different kinds of interactions have also been developed and studied in the past, including REPLs (Read-Eval-Print loops) and refactorings. However, these are typically treated as external tools that work on programs, rather than an inherent part of the programming language itself. Perhaps the closest work to the idea described in the blog post is the Subtext language by Jonathan Edwards. Among other things, it has a first-class support for copy and paste .
A curious reference that is well worth reading is the 1983 paper First Steps Towards Inferential Programming by William Scherlis and Dana Scott. As far as I can tell, nobody ever took the next steps. The paper shares the motivation with this blog post. To quote "Our basic premise is that the ability to construct and modify programs will not improve without a new and comprehensive look at the entire programming process." The authors note that existing work often looks at individual programs but that "little has been done (...) to develop a sound understanding of the process of programming - the process by which programs evolve in concept and in practice." The authors have a slightly different take on the subject and focus how you could co-develop a specification of a program with the program itself (by refining both via a series of interactions), but it is very interesting to see that the idea appeared already in 1980s!
Conclusions
Modern programming language research has certainly produced some useful programming tools, but I believe that we are a bit stuck in thinking about programming languages in one particular way . There are many alternatives worth exploring. Most fundamentally, mathematical approach to computer science is just one approach and I think we are using it in ways that might, in the future, appear unreasonable . Many good ideas could be learned fromdesign, urban planning, sociology and other disciplines.
That said, this blog post advocates a much less revolutionary research idea. To borrow a much hated online advertising phrase, I talked about one simple trick that will make current programming language research much more interesting . The trick is that we should not be looking at programs or programming languages , but instead, we should be thinking about the programming process . This can still be done mathematically. Rather than treating programs as syntactic expressions, we should treat programs as results of a series of interactions that were used to create the program. Those interactions include writing code, but also refactoring, copy and paste or running a bit of program in REPL or a notebook system. By considering these as part of the process, we can create a richer notion of programming language that lets us focus on making programming easier.

I recently joined the fantastic Programming Languages and Systems group at the University of Kent . We are always looking for PhD students and I'm also working on getting money for a post-doc position, so if any of the ideas in this blog post sound interesting to you, please get in touch!
All of these are open ended and there are many forms this could take. I'm also interested in hearing from anyone who has done something related or knows of references that I missed! You can ping me at @tomaspetricek or send an email [email protected].
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK