

Under the hood of GraalVM JIT optimizations
source link: https://www.tuicool.com/articles/hit/bYrInub
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Previously we looked at the performance of Java Streams API on the GraalVM in comparison with JavaHotSpot VM. GraalVM is a high-performance virtual machine, and in those experiments we got performance improvements from 1.7x to 5x when running sample benchmarks of Java Streams API usage on GraalVM compared to Java HotSpot VM. Of course the exact performance boost as always will depend on the code and workload, so please try GraalVM on your code before making any definite conclusions.
In this article we look deeper into the internals of how GraalVM does just-in-time compilation.
GraalVM JIT optimizations
Let’s take a look at some of the high-level optimizations performed by the GraalVM compiler. In this article, we present only the most relevant optimizations, and give a short example for each of them. To learn more, a good overview of the GraalVM compiler optimizations for collections and Streams is given in the paper entitled Making collection operations optimal with aggressive JIT compilation .
Inlining
If we exclude ahead-of-time compilation, most JIT compilers found in today’s VMs do intraprocedural analysis. This means that they analyze code within a single method at a time. The reason for this is that intraprocedural analysis is much faster than whole program interprocedural analysis, which is usually infeasible for the time budget given to a JIT compiler. In a JIT compiler that does intraprocedural optimizations (i.e. optimizes code within a single method at a time), inlining is one of the fundamental optimizations. Inlining is important because it effectively makes a method larger, meaning that the compiler sees more optimization opportunities between parts of the code that used to be in seemingly unrelated methods.
Take, for example, the volleyballStars method introduced in the previous post.
The following figure shows a part of the intermediate representation of that method in GraalVM, immediately after it gets parsed from the corresponding Java bytecode:
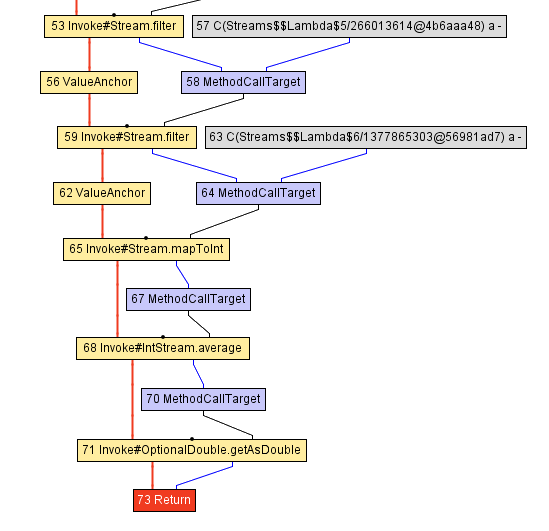
You can think of the intermediate representation (IR) in Graal as if it were an abstract syntax tree , but on steroids — it enables performing certain optimizations more easily. It is not important to understand exactly how this intermediate representation works, but if you would like to learn more about this representation, the paper Graal IR: An Extensible Declarative Intermediate Representation explains it well.
The most important takeaway is that the control flow in that method, represented by the yellow nodes and the red lines, successively invokes different Stream functions, such as Stream.filter , Stream.mapToInt and IntStream.average . Without knowing exactly what the code within those methods is, the compiler does not know how to simplify this method — so inlining comes to the rescue!
The inlining transformation is by itself straightforward — simply identify a method call, and replace it with the body of the inlined method. Let’s look at the IR of the volleyballStars after inlining some methods. Note that we show only the part after the call to IntStream.average .
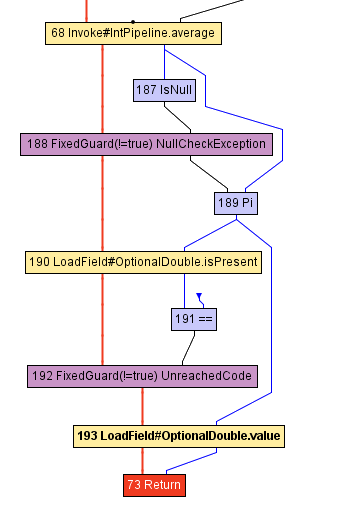
Above, we can see that the getAsDouble call (node 71) disappeared from the intermediate representation. Note that the getAsDouble method of the OptionalDouble object returned by IntStream.average (the last call in our volleyballStars method) is defined as follows in the JDK:
public double getAsDouble() {
if (!isPresent) {
throw new NoSuchElementException("No value present");
}
return value;
}
We can identify the loading of the isPresent field in the code above (the LoadField node 190), as well as the read of the value field. However, there is no sign of the NoSuchElementException or the code that throws that exception.
This is because the GraalVM compiler speculates that, in the volleyballStars method, the exception will never get thrown. This knowledge would generally not be available when compiling the getAsDouble method on its own — many different parts of the program could be calling getAsDouble , and the exception could be thrown for those other invocations. However, in the volleyballStars method, the exception is unlikely to be thrown, because the set of potential volleyball stars is non-empty. For this reason, GraalVM removes the branch, and inserts a FixedGuard node that deoptimizes the code if the speculation is incorrect. This example is quite minimal, and there are many, many much more complex examples of how inlining enables other optimizations.
We note that the call tree of a program can generally be very deep or even infinite, and inlining must stop at some point — it has a finite time and memory budget. With this in mind, deciding when and what to inline is anything but simple.
Polymorphic inlining
Inlining only works if the compiler can decide on the exact method that a method call is targeting. Java code typically has a lot of indirect calls — calls to methods whose implementations are not known statically, and which are resolved at runtime using virtual dispatch.
As an example, consider the implementation of the IntStream.average method. Its basic implementation is just this:
@Override public final OptionalDouble average() {
long[] avg = collect(
() -> new long[2],
(ll, i) -> { ll[0]++; ll[1] += i; },
(ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; });
return avg[0] > 0 ?
OptionalDouble.of((double) avg[1] / avg[0]) :
OptionalDouble.empty();
}
However, don’t be fooled by its apparent simplicity! This method is implemented in terms of the collect call, where all the magic happens. The call tree of this method (i.e. its call hierarchy) rapidly expands as we dive deeper into collect , as shown in the following sequence of figures:
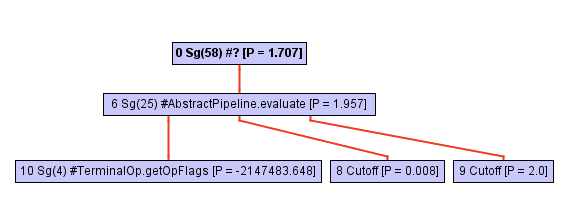
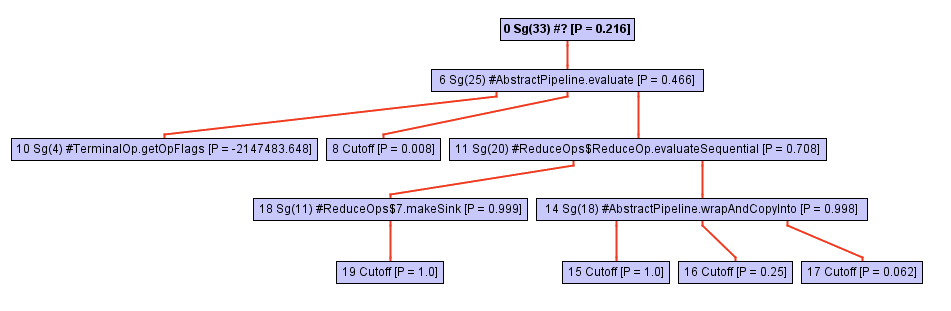
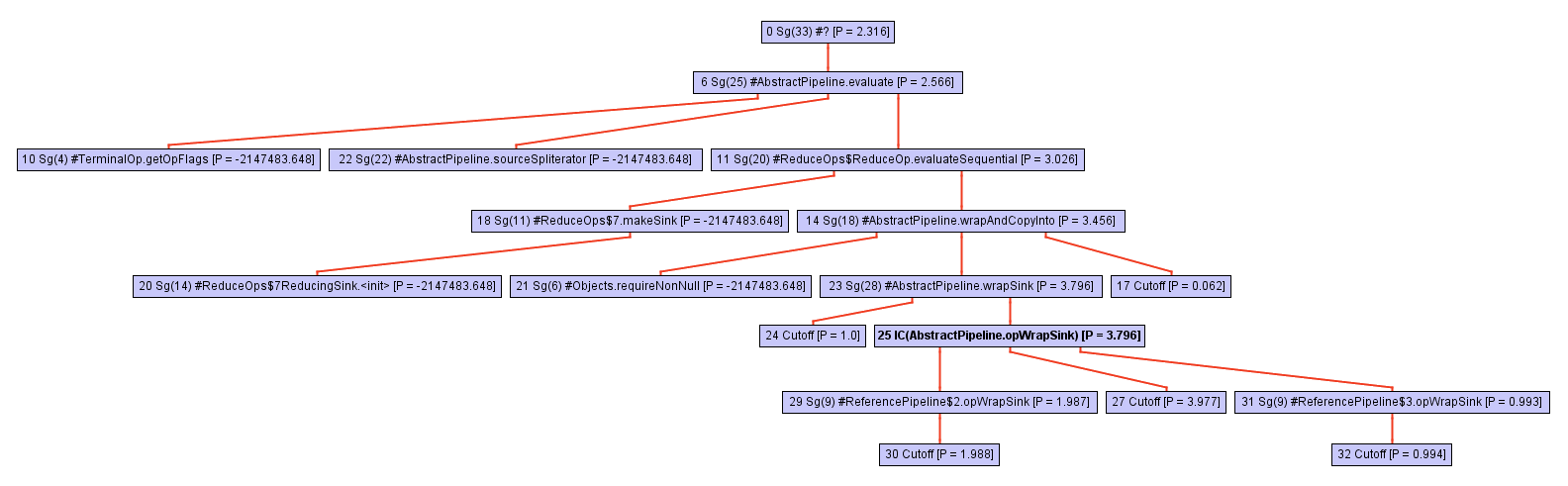
At some point, while exploring the call tree, the inliner stumbles upon a call to opWrapSink from the Stream framework, which is an abstract method:
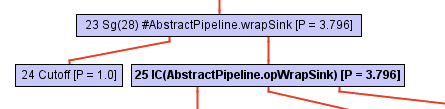
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
Normally, an inliner cannot proceed at this point, since the call is not direct — the target resolution occurs during the execution of the program, so the inliner does not know what to inline.
However, GraalVM maintains a receiver type profile for every callsite that is not direct. This profile is essentially a table that says how many times each of the implementations of wrapSink was called. In our case, the profile is aware of 3 different implementations in the anonymous classes ReferencePipeline$2 , ReferencePipeline$3 and ReferencePipeline$4 . These implementations occur with probabilities 50%, 25% and 25%, respectively.
0.500000: Ljava/util/stream/ReferencePipeline$2; 0.250000: Ljava/util/stream/ReferencePipeline$4; 0.250000: Ljava/util/stream/ReferencePipeline$3; notRecorded: 0.000000
This information is invaluable for the compiler, since it allows emitting a typeswitch — a short switch -statement that checks the type of the method at runtime, and calls a concrete method in each case. The following part of the intermediate representation shows the typeswitch (the three If nodes) that checks if the receiver type is either ReferencePipeline$2 , ReferencePipeline$3 and ReferencePipeline$4 . Each of the direct calls in the successful branch of each of the InstanceOf checks can now be inlined, and enable other optimizations. If none of the types match, the code is deoptimized by the Deopt node (or, alternatively, a virtual dispatch occurs).
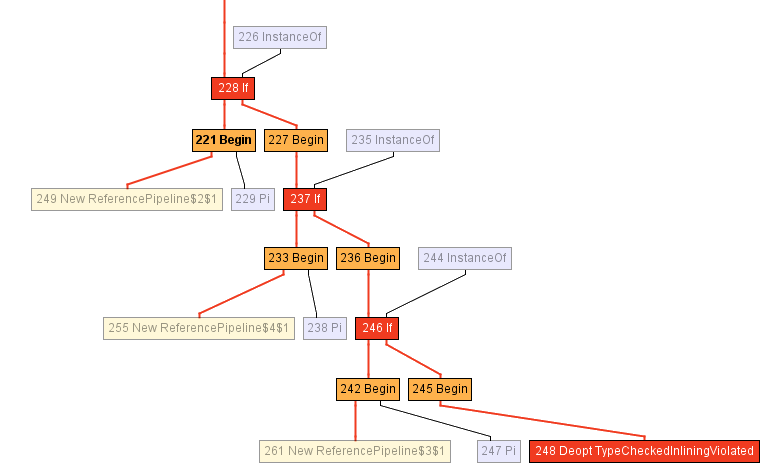
To learn more about polymorphic inlining, we recommend the classic paper on this topic, Inlining of Virtual Methods .
Partial escape analysis
Let’s come back to our volleyball example. Note that none of the Person objects that are allocated in the lambda passed to the map function ever leaves the scope of the volleyballStars method. In other words, by the time that the volleyballStars method returns, no part of the live memory will point to the allocated Person objects. In particular, the write of the getHeight value to these new objects is subsequently only used to filter the person’s height.
At some point during the compilation of the volleyballStars method, we arrive at the following intermediate representation. The a block starting with the Begin node 1621 starts by allocating a Person object (in the Alloc node), and initializes it with the age field value incremented by 1, and the previous value of the height field. The height field is previously read by the LoadField node 1539. The result of the allocation is then encapsulated in the AllocatedObject (node 2137), and forwarded to the call to the accept method (node 1625). There is nothing else that the compiler can do at this point — from the point of view of the compiler, the object effectively escapes the volleyballStars method.
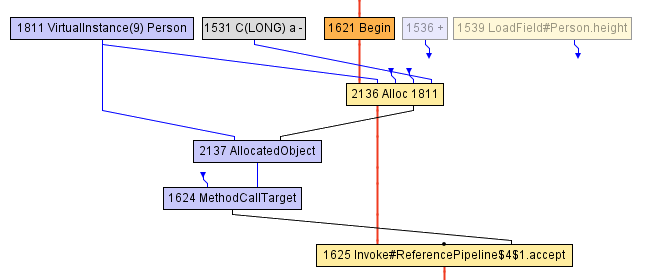
After that, the compiler decides to inline the call to accept , since it decides that it might be useful. We arrive at the following IR:
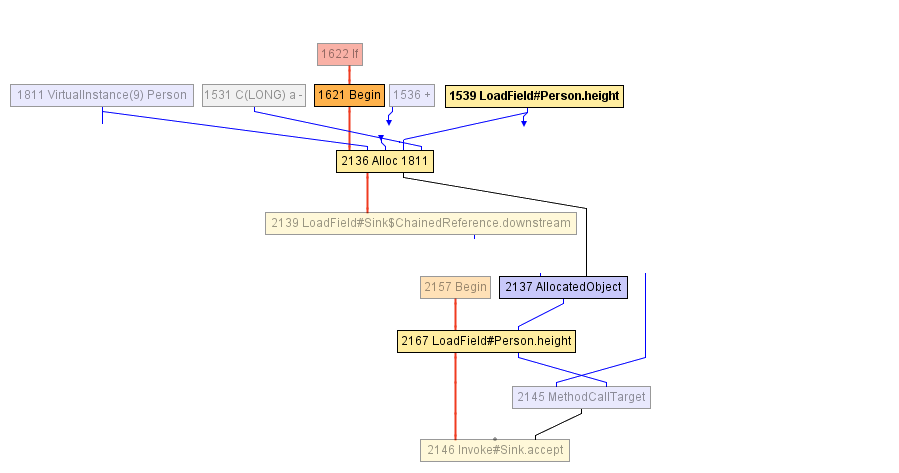
At this point, the JIT compiler executes the partial escape analysis optimization — it notices that the AllocatedObject node is only ever used to read the height field (recall that the height is then used by the filter condition to check if it is greater than 198). Therefore, the compiler can rewire the read of the height field (node 2167) to point directly to the node that was previously written into the Person object ( Alloc node 2136), and that is the LoadField node 1539. Furthermore, the Alloc node is at this point not used as input to any other node, so it can be simply removed — it’s dead code!
This optimization is, in fact, the main reason why we get a 5x speedup with GraalVM on the volleyballStars example. Even though all the Person objects are discarded immediately after they are created, they still need to be allocated on the heap, and their memory needs to be initialized. Partial escape analysis allows eliminating allocations, or delaying the object allocations by moving them into the branches of the code where the objects really escape, and which occur less frequently.
You can learn more about how partial escape analysis works in the paper entitled Partial Escape Analysis and Scalar Replacement for Java .
Summary
In this article we looked at some of the optimizations in GraalVM: inlining, polymorphic inlining, and partial escape analysis, but there are many more — loop unrolling, loop peeling, path duplication, strength reduction, global value numbering, constant folding, dead code elimination, conditional elimination, and branch speculation, to name just a few.
If you would like to know more about how GraalVM works, please feel free to check out our publication page . And if you want to check whether GraalVM can improve performance of your applications, you can get the GraalVM binary on the website: graalvm.org/downloads .
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK