

AI+网络安全:机器学习文本分类技术在恶意代码检测中的应用
source link: https://www.sdnlab.com/22378.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
机器学习文本分类技术在恶意代码检测中的应用相比较于传统恶意代码检测,不仅提高了恶意代码检测的的效率,能够对大量恶意代码样本进行及时、高效和准确检测,同时也具有一定的泛化能力,能够检测一定的未知样本。这篇中科院的硕士论文,基于文本分类技术的恶意代码检测工具,为我们介绍了它的工作原理。

前言
恶意代码对人们的工作和生活带来了严重的威胁,对恶意代码进行检测也变 得越来越重要。一种有效的恶意代码检测方式是借鉴机器学习技术,训练检测模型并使用其检测新样本中是否含有恶意代码。为达到此目的,使用操作码特征的检测方法近年来深受欢迎。它从可执行样本中提取操作码特征用以表示样本,进而输入到机器学习分类模型中训练恶意代码检测模型。然而,我们在研究过程中 发现目前这种基于操作码特征的恶意代码检测的性能深受训练样本量不足的影响。造成这种问题的主要原因是其依赖于目前流行的反汇编工具 IDA Pro。该工具能保守地输出高精度反汇编代码,然而实际工作中样本的复杂性会降低该工具 的反汇编成功率。
“飞鼠”恶意代码检测系统
针对此问题,论文根据线性扫描反汇编算法实现了低精度的反汇编工具D-light,用于高效、可配置地反汇编多种平台多种格式类型的可执行样本,避免基于递归下降反汇编算法的 IDA Pro 遇到的各种问题;论文还重新设计和实现了“飞鼠”恶意代码检测系统,自动化地采集、标记、处理样本,在兼容 IDA Pro的基础上,同时支持线性扫描反汇编工具 D-light,并能够根据配置选择相应算法实现恶意代码检测。论文通过实验分析指出,使用线性扫描反汇编算法提取操作码特征,能够在允许一定程度的反汇编代码不准确的情况下,提高反汇编成功 率,增加可利用的样本数目;训练数据集样本量的大幅增加可以弥补样本反汇编 质量小幅度降低的损失,最终超越,或保持,基于 IDA Pro 的检测模型的检测效果。实验中还发现,使用多项式核函数的支持向量机分类算法在实践中有着更好的性能和应用价值。
互联网与病毒发展现状
随着计算机技术的高速发展和计算机网络的不断普及,计算机和互联网已经深入到人们日常生活和工作的方方面面。根据中国互联网信息中心(China Internet Network Information Center,CNNIC)在2018年01月份发布的《第41次中国互联网络发展状况统计报告》来看,截至 2017 年 12 月,我国网民规模达7.72 亿,全年共计新增网民 4074 万人,互联网普及率达 55.8%,相比较于 2016年底提升了 2.6%。同时我国在线政务服务用户规模达到 4.85 亿,占总体网民的62.9%,通过支付宝或微信城市服务平台获得政务服务的使用率为 44.0% 。
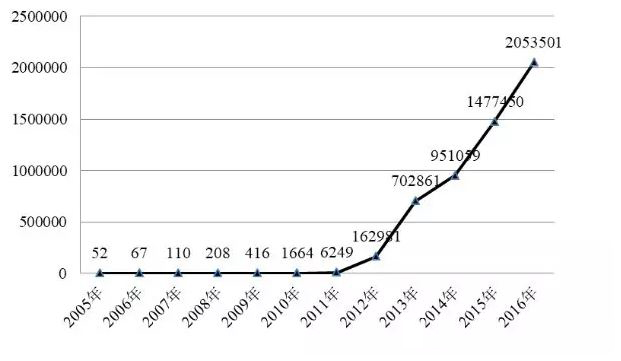
日益便捷的网络互联环境和成熟的计算机技术,也为网络攻击的产生与传播 提供了极大的便利条件,每年新增的软件数量呈现出持续性增长的趋势。在赛门铁克(Symantec)公司 2010 年发布的安全报告中指出,赛门铁克公司相比 于 2008 年捕获到 169323 个新型软件,2009 年共捕获到了2895802个新型软件。根据中国互联网应急响应中心(National Internet Emergency Center,CNCERT 或CNCERT/CC)在 2017 年 05 月份发布的《2016 年中国互联网网络安全报告》来 看,CNCERT/CC 通过自主捕获以及与厂商交换获得的移动互联网恶意程序数量约205万个,相比较于2015年增长39个百分点,并且近7年一直保持高速增长, 如图1所示。
“飞鼠”的设计
基于特征码的静态恶意代码检测流程如图 2所示。通常可以分为三部分, 首先需要获取恶意代码,然后对现有已知的恶意代码进行特征分析,提取相应的 特征码;然后汇总整理,将提取的特征码存入特征库;最后,在对未知的可执行 样本进行检测时,根据特征库中的特征码逐项进行匹配。如果待检测样本中包含 特征库中的特征信息,则认为该样本是恶意代码,反之,则认为是非恶意代码。

“飞鼠”系统特征训练检测模型
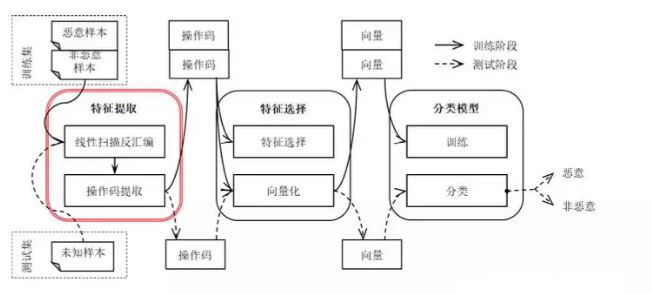
在获取到包含恶意代码样本和非恶意代码样本的原始实验数据集,并进行预 处理和数据集划分之后,对训练集数据首先使用线性扫描反汇编工具进行反汇编 处理。然后从反汇编代码中提取操作码特征。在完成操作码特征提取之后,会首 先根据训练集中操作码特征的数据特征选择一定的操作码特征对样本进行向量 化表示。最后将描述样本的特征向量输入分类模型中进行训练,得到用于恶意代 码检测的恶意代码检测模型。测试阶段,使用相同的线性扫描反汇编方法对未知 样本进行反汇编提取其操作码特征。根据训练阶段选择出来的操作码特征子集对 未知样本进行向量化描述。最后将该描述向量输入到训练阶段得到的恶意代码检 测模型进行检测,得到最终的恶意代码检测结果,恶意代码或者非恶意代码。
“飞鼠”系统实验结果
实验的结果如图 4所示。在图 4 中,横坐标表示四种不同的衡量 指标,用来评估分类检测模型的性能,从左到右依次为 Accuracy、TPR、FPR 和G-mean;纵坐标表示四种衡量指标相应的结果取值,取值范围从 0 到 100(%)。
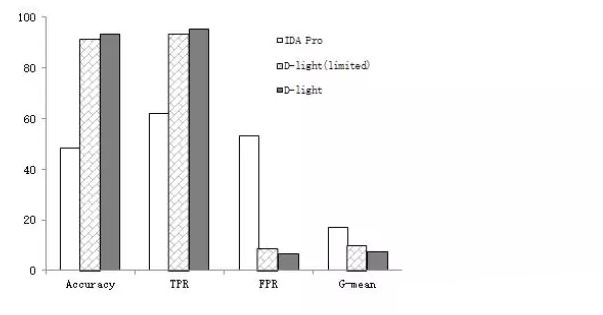
在图 4中,三种不同的柱状图分别表示了三组不同的实验结果,其中白色 柱表示使用 IDA Pro 进行反汇编的检测结果,即 Group 1;砖块状表示使用D-light(limited)进行反汇编训练模型得到的检测结果,即 Group 2;黑色状表示使 用 D-light 对全部样本进行反汇编训练模型得到的检测结果,即 Group 3。首先看 白色柱状结果,按照横坐标顺序左右到右依次表示使用 IDA Pro 反汇编得到的操 作码进行训练得到的恶意代码分类检测模型的 Accuracy 指标为 48.4%,TPR 指 标为 61.93%,FPR 指标为 53.23%,G-mean 指标结果为 0.17。再来观察块状柱结果,按照横坐标顺序左右到右依次表示使用 D-light(limited)反汇编得到的操作 码进行训练得到的恶意代码分类检测模型的 Accuracy 指标为 91.23%,TPR 指标 为 93.30%,FPR 指标为 8.81%,G-mean 指标结果为 0.10。最后观察黑色柱结果,按照横坐标顺序左右到右依次表示使用 D-light 反汇编得到的操作码进行训练得 到的恶意代码分类检测模型的 Accuracy 指标为 93.46%,TPR 指标为 95.17%,FPR 指标为 6.75%,G-mean 指标结果为 0.08。
回归到这四个指标本身的含义上,可以看到图4很直观地展现出 D-light 相比IDA Pro 在恶意代码检测上有着更好的检测性能。此外,从图4中还可以看到:
1)对训练集样本的数量进行限制,会对训练得到的分类模型最终的检测结 果产生很大影响;
2)在使用相同的数据进行训练的情况下,从结果来看,可以发现使用 D-light进行反汇编比 IDA Pro 进行反汇编得到的分类模型检测性能要好。
通过以上分析,可以得出反汇编代码的数量相比训练集样本的质量对恶意代码检测模型的性能影响更大。
总结
论文提出的解决方案,主要思想是通过训练样本数量的大幅增长来弥补操作码特征略微不准确的问题,所以在该解决方案中通过 D-light 反汇编工具获取大量稍微有些不准确的反汇编代码提取操作码特征来训练恶意代码检测模型。在对反汇编代码的质量和数量对恶意代码检测性能影响的实验研究中,通过使用D-light反汇编提取操作码特征训练得到的恶意代码检测模型与使用IDA Pro反汇编提取操作码特征训练得到的恶意代码检测模型进行对比分析,发现使用 D-light反汇编提取操作码特征训练得到的恶意代码检测模型的检测性能更好一些,验证了本文提出的使用线性扫描反汇编算法提取操作码特征训练恶意代码检测模型的解决方案是有效和可行的。此外,在对比分析实验中,本文还发现使用多项式核函数支持向量机分类算法的恶意代码检测模型在实践中检测性能表现最好。
转载自人工智能开放创新平台
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK