

图像识别泛化能力人机对比:CNN比人类还差得远
source link: https://www.jiqizhixin.com/articles/091601?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
深度神经网络在很多任务上都已取得了媲美乃至超越人类的表现,但其泛化能力仍远不及人类。德国蒂宾根大学等多所机构近期的一篇论文对人类和 DNN 的目标识别稳健性进行了行为比较,并得到了一些有趣的见解。机器之心对该论文进行了编译介绍。
-
论文地址:https://arxiv.org/pdf/1808.08750.pdf
-
项目地址:https://github.com/rgeirhos/generalisation-humans-DNNs
摘要
我们通过 12 种不同类型的图像劣化(image degradation)方法,比较了人类与当前的卷积式 深度神经网络 (DNN)在目标识别上的稳健性。首先,对比三种著名的 DNN(ResNet-152、VGG-19、GoogLeNet),我们发现不管对图像进行怎样的操作,几乎所有情况下人类视觉系统都更为稳健。我们还观察到,当信号越来越弱时,人类和 DNN 之间的分类误差模式之间的差异会逐渐增大。其次,我们的研究表明直接在畸变图像上训练的 DNN 在其所训练的同种畸变类型上的表现总是优于人类,但在其它畸变类型上测试时,DNN 却表现出了非常差的泛化能力。比如,在椒盐噪声上训练的模型并不能稳健地应对均匀白噪声,反之亦然。因此,训练和测试之间噪声分布的变化是深度学习视觉系统所面临的一大关键难题,这一难题可通过终身机器学习方法而系统地解决。我们的新数据集包含 8.3 万个精心度量的人类心理物理学试验,能根据人类视觉系统设置的图像劣化提供对终身稳健性的有用参考。
 图 1:在(有可能畸变的)ImageNet图像上从头开始训练的 ResNet-50 的分类表现。(a)在标准的彩色图像上训练后的模型在彩色图像上的测试表现接近完美(优于人类观察者)。(b)类似地,在添加了均匀噪声的图像上训练和测试的模型也优于人类。(c)显著的泛化问题:在添加了椒盐噪声的图像上训练的模型在具有均匀噪声的图像上进行测试时,表现时好时坏——即使这两种噪声类型在人眼看来并没有太大的区别。
图 1:在(有可能畸变的)ImageNet图像上从头开始训练的 ResNet-50 的分类表现。(a)在标准的彩色图像上训练后的模型在彩色图像上的测试表现接近完美(优于人类观察者)。(b)类似地,在添加了均匀噪声的图像上训练和测试的模型也优于人类。(c)显著的泛化问题:在添加了椒盐噪声的图像上训练的模型在具有均匀噪声的图像上进行测试时,表现时好时坏——即使这两种噪声类型在人眼看来并没有太大的区别。
1 引言
1.1 作为人类目标识别模型的 深度神经网络
人类在日常生活中进行的视觉识别速度很快,似乎也毫不费力,而且很大程度无关视角和物体的方向 [Biederman (1987)]。在单次注视过程中完成的主要由中心凹进行的快速识别被称为「核心目标识别(coreobject recognition)」[DiCarlo et al. (2012)]。比如,在查看「标准的」图像时,我们能够在不到 200 毫秒的单次注视内可靠地辨别出视野中心的目标。[DiCarlo et al. (2012); Potter (1976); Thorpe et al. (1996)]。由于目标识别速度很快,所以研究者常认为核心目标识别主要是通过前馈处理实现的,尽管反馈连接在灵长类大脑中无处不在。灵长类大脑中的目标识别据信是通过腹侧视觉通路实现的,这是一个由区域 V1-V2-V4-IT 组成的分层结构,来自视网膜的信息会首先传递至 V1 的皮层 [Goodale and Milner (1992)]。
就在几年前,动物视觉系统还是已知的唯一能够进行种类广泛的视觉目标识别的视觉系统。但这种情况已然改变,在数百万张有标注图像上训练之后的脑启发式 深度神经网络 已经在自然场景图像中的物体分类上达到了人类水平 [Krizhevsky et al. (2012)]。DNN 现在可用于各种类型的任务,并且创造了新的当前最佳,甚至在一些几年前还被认为需要数十年时间才能通过算法解决的任务上取得了超越人类的表现 [He et al. (2015); Silver et al. (2016)]。因为 DNN 和人类能达到相近的准确度,所以已有一些工作开始研究 DNN 和人类视觉的相似和不同之处。一方面,由于大脑本身的复杂性和神经元的多样性,所以 DNN 的网络单元得到了很大的简化 [Douglas and Martin (1991)]。另一方面,一个模型的能力往往并不取决于对原有系统的复现,而在于模型取得原系统的重要方面并将其从实现的细节中抽象出来的能力 [如 Box (1976); Kriegeskorte (2015)]。
人类视觉系统最显著的性质之一是稳健的泛化能力。即使输入分布发生很大的变化(比如不同的光照条件和天气类型),人类视觉系统也能轻松应对。比如,即使在一个物体前面有雨滴或雪花,人类对物体的识别也基本不会出错。尽管人类在一生中肯定会遇到很多这样的变化情况(对于 DNN,即是我们所说的「训练时间」),但似乎人类的泛化方式非常普适,并不局限于之前看过的同种分布。否则我们将无法理解存在某些全新之处的场景,之前未见过的噪声也会让我们束手无策。即使一个人的头上还从未被撒过彩片碎纸,但他仍然可以毫无压力地辨认出花车巡游中的目标。很自然,这样通用稳健的机制并不只是动物视觉系统所需的,要让人工视觉系统具备超出其训练时间所用分布的「眼界」,从而处理各种各样的视觉任务,也将需要类似的机制。用于自动驾驶的深度学习可能就是其中一个突出案例:即使系统在训练时间从没见过彩片碎纸雨,在花车巡游时也需要有稳健的分类表现。因此,从机器学习角度看,因为终身机器学习所需的泛化能力并不依赖于在测试时间使用独立同分布(i.i.d.)样本的标准假设,所以对一般噪声的稳健性可用作终身机器学习的高度相关的案例 [Chen and Liu (2016)]。
1.2 泛化能力比较
DNN 的泛化效果一般很好:首先,DNN 能够在训练分布上学习到足够一般的特征,能在独立同分布的测试分布上得到很高的准确度;尽管 DNN 也有足够的能力完全记忆训练数据 [Zhang et al. (2016)],。有很多研究致力于理解这一现象 [如 Kawaguchi et al. (2017); Neyshabur et al. (2017); Shwartz-Ziv and Tishby (2017)]。其次,在一个任务上学习到特征往往只会迁移到有所相关的任务上,比如从分类任务迁移到显著性预测任务 [Kümmerer et al. (2016)]、情绪识别任务 [Ng et al. (2015)]、医学成像任务 [Greenspan et al. (2016)] 以及其它很多迁移学习任务 [Donahue et al. (2014)]。但是,在用于新任务之前,迁移学习仍然需要大量训练。这里,我们采用第三种设定:终身机器学习角度的泛化 [Thrun (1996)]。即当一个视觉学习系统在学习过处理一种特定类型的图像劣化后,在处理新类型的图像劣化时效果如何?作为一种目标识别稳健性的度量方法,我们可以测试分类器或视觉系统能够忍受输入分布的变化达到一定程度的能力,即在一定程度上不同于训练分布的测试分布上评估时的识别表现是否够好(即在接近真实的情况下测试,而非在独立同分布上测试)。使用这种方法,我们可以衡量 DNN 和人类观察者应对由参数化图像处理所造成的原始图像逐渐畸变的能力。
首先,我们将评估在ImageNet上训练的表现最好的 DNN,即 GoogLeNet [Szegedy et al. (2015)]、 VGG-19 [Simonyan and Zisserman (2015)] 和 ResNet-152 [He et al. (2016)],并会在 12 种不同的图像畸变上比较这些 DNN 与人类的表现,看各自在之前未见过的畸变上的泛化能力如何。图 2 展示了这些畸变类型,包含加性噪声或相位噪声等。
在第二组实验中,我们会直接在畸变图像上训练网络,看它们在一般意义上处理有噪声输入的效果究竟如何,以及在畸变图像上进行多少训练就能以数据增强的形式助力对其它畸变形式的处理。研究者已对人类在目标识别任务上的行为进行了很多心理物理学研究,这些任务包括在不同颜色(灰度和彩色)或对比度以及添加了不同量的可见噪声的图像上测量准确度。研究表明,这种方法确实有助于对人类视觉系统的探索,能揭示出有关其中内部计算和机制的信息 [Nachmias and Sansbury (1974); Pelli and Farell (1999); Wichmann (1999); Henning et al. (2002); Carandini and Heeger (2012); Carandini et al. (1997); Delorme et al. (2000)]。因此,类似的实验也许同样能让我们了解 DNN 的工作方式,尤其是还能通过与人类行为的高质量测量结果来进行比较。
特别需要指出,我们实验中的人类数据是从受控的实验环境中获得的(而没有使用 Amazon Mechanical Turk 等服务,因为这些服务无法让我们充分地控制展示时间、显示器校准、视角和参与者在实验中的注意力)。我们精心测量得到的行为数据集共包含 12 个实验的 82880 次心理物理学试验,这些数据以及相关材料和代码都已公开:https://github.com/rgeirhos/generalisation-humans-DNNs
2 方法
这一节将报告所用的范式、流程、图像处理方法、观察者和 DNN 的核心元素;这里的信息足以让读者了解相关实验和结果。更深入的解读请参阅补充材料,其中有更详细的细节,可帮助研究者重现我们的实验。
2.1 范式、流程和 16-class-ImageNet
为了本研究,我们开发了一种实验范式,旨在使用一种强制选择的图像分类任务来尽可能公平地比较人类观察者和 DNN。实现公平的心理物理学比较面临着一些难题:首先,很多表现优良的 DNN 是在 ILSRVR 2012 数据库 [Russakovsky et al. (2015)] 上训练的,这个数据库有 1000 种细粒度的类别(比如,超过 100 种狗)。如果让人类说出这些目标的名称,他们基本上很自然地会使用大类的名称(比如会说这是「狗」,而不是说是「德国牧羊犬」)。因此,我们使用 WordNet 的层次结构 [Miller (1995)] 开发了一种映射方法,将 16 种大类类别(比如狗、车或椅子)映射到了它们对应的ImageNet类别。我们将这个数据集称为 16-class-ImageNet,因为它将ImageNet的一个子集分组成了 16 个大类,即:飞机、两轮车、船舶、小车、椅子、狗、键盘、烤箱、熊、鸟、瓶子、猫、钟表、象、刀具、卡车)。然后,在每次试验中都会有一张图像显示在计算机屏幕上,观察者必须通过点击这 16 个类别中的 1 个来选出正确的类别。对于预训练的 DNN,则是计算映射到特定大类的所有 softmax 值的总和。然后,具有最高总和的大类被用作该网络的最终决定。
另一个难题是实际上标准的 DNN 在推理时间仅会使用前馈式计算,而循环连接在人脑中无处不在 [Lamme et al. (1998); Sporns and Zwi (2004)]。为了防止这种差异在我们的实验比较中成为混淆结果的主要原因,给人类观察者的呈现时间被限制在了 200ms。在展示完一张图像之后,还会呈现 200ms 的 1/f 噪声掩模——在心理物理学上,已知这种方法能够尽可能地最小化大脑中的反馈影响。
2.2 观察者和预训练的 深度神经网络
来自人类观察者的数据与三个预训练的 DNN 的分类表现进行了比较,即 GoogLeNet、 VGG-19 和 ResNet-152。对于我们进行的 12 个实验中的每一个,都有 5 或 6 个观察者参与(只有彩色图像的实验除外,该实验仅有三位观察者参与,因为已有很多研究执行过类似的实验 [Delorme et al. (2000); Kubilius et al. (2016); Wichmann et al. (2006)]。观察者的视力或矫正后视力处于正常水平。
2.3图像处理方法
我们在一个控制良好的心理物理学实验室环境中进行了总共 12 个实验。在每个实验中,都会在大量图像上施加(可能是参数化的)图像畸变,这样信号强度的范围就从「没有畸变/全信号」到「有畸变/(更)弱信号」不等。然后我们测量了分类准确度随信号强度的变化情况。我们使用的图像处理方法中有三种是二分式的(彩色与灰度、真色与反色、原始与均衡化的功率谱);一种处理方式有 4 个不同层级(旋转 0、90、180、270 度);还有一种方式有 7 个层级(0、30……180 度的相位噪声);其它畸变方法则各有 8 个不同层级。这些方法为:均匀噪声(受表示像素层面加性均匀噪声的边界的「width」参数控制)、对比度下降(对比度从 100% 到 1% 不等)以及三种来自 Eidolon 工具箱的三种不同的处理方法 [Koenderink et al. (2017)]。这三个 Eidolon 实验都对应于一种参数化图像处理的不同版本,「reach」参数控制了畸变的强度。此外,对于在畸变上训练的实验,我们也评估了在具有椒盐噪声的刺激上的表现(受参数p 控制,该参数表示将一个像素设置成黑或白色的概率;p∈[0,10,20,35,50,65,80,95]%)。
更多有关不同图像处理方法的信息请参阅补充材料,其中也包含各种不同处理方法和畸变等级的图例。图 2 则展示了每种畸变的一个图例。整体而言,我们选择使用的图像处理方法能够代表很多不同类型的可能畸变。
 图 2:一张鸟图像在经过所有类型的畸变处理后的结果。从左至右的图像处理方法依次为:(上面一行):彩色原图(未畸变)、灰度、低对比度、高通、低通(模糊)、相位噪声、功率均衡;(下面一行):反色、旋转、Eidolon I、Eidolon II、Eidolon III、加性均匀噪声、椒盐噪声。补充材料中提供了所用到的所有畸变等级。
图 2:一张鸟图像在经过所有类型的畸变处理后的结果。从左至右的图像处理方法依次为:(上面一行):彩色原图(未畸变)、灰度、低对比度、高通、低通(模糊)、相位噪声、功率均衡;(下面一行):反色、旋转、Eidolon I、Eidolon II、Eidolon III、加性均匀噪声、椒盐噪声。补充材料中提供了所用到的所有畸变等级。
2.4 在畸变图像上训练
除了在畸变图像上评估标准的预训练的 DNN(结果见图 3),我们还直接在畸变图像上训练了神经网络(图 4)。这些网络是在 16-class-ImageNet上训练的,这是标准ImageNet数据集的一个子集,详见 2.1 节。这将未受扰动的训练集规模减小到了大约原来的五分之一。为了校正每个类别的高度不平衡的样本数量,我们使用了一个与对应类别的样本数量成正比的权重给损失函数中的每个样本加权。这些实验中训练的所有网络都使用了类似 ResNet 的架构,与标准 ResNet-50 的不同之处仅有输出神经元的数量——从 1000 降至了 16,以对应数据集的 16 个大类。权重使用了一个截断的正态分布进行初始化,均值为零,标准差为,其中 n 是一层中输出神经元的数量。
在从头开始训练时,我们使用图像处理方法的不同组合在训练过程中执行了数据增强。当在多种类型的图像处理上训练网络时(图 4 中的 B1-B9 和 C1-C2 模型),图像处理的类型(包括未畸变图像,即标准的彩色图像)是均匀选取的,而且我们每次仅应用一种处理(即网络永远不会看到同时应用了多种图像处理方法的单张图像,但注意某些图像处理方法本质上已经包含了其它处理方法:比如均匀噪声,总是在进行灰度转换并将对比度降至 30% 后添加的)。对于一个给定的图像处理方法,扰动量是根据测试时间所用的等级均匀选取的(参见图 3)。
训练过程的其它方面都遵循在ImageNet上训练 ResNet 的标准训练流程:我们使用了动量为 0.997 的 SGD,批大小为 64,初始学习率为 0.025。在 30、60、80 和 90 epoch 后(当训练 100 epoch 时)或 60、120、160、180 epoch 后(当训练 200 epoch 时),学习率乘以 0.1。我们使用了TensorFlow 1.6.0 [Abadi et al. (2016)] 进行训练。在训练实验中,除了 Eidolon 刺激(因为这些刺激的生成对ImageNet训练而言的计算速度实在太慢)之外,所有的图像处理方法都有超过两个层级。为了进行比较,我们额外添加了彩色与灰度和椒盐噪声的对比(因为椒盐噪声方面没有人类的数据,但均匀噪声和椒盐噪声之间不正式的比较说明人类的表现是相近的,参见图 1(c))。
3 人类和预训练后的 DNN 对图像畸变的泛化能力
为了评估信号更弱时的泛化能力,我们测试了 12 种不同的图像劣化方法。然后将这些不同信号强度的图像呈现给实验室环境中的人类观察者以及预训练的 DNN(ResNet-152、GoogLeNet 和 VGG-19)进行分类。图 3 给出了可视化的结果比较。
 图 3:GoogLeNet、VGG-19 和 ResNet-152 以及人类观察者的分类准确度和响应分布熵。「熵」是指响应/决定分布(16 类)的香农熵。这里衡量了与特定类别的偏差:使用一个在每个类别的图像数量方面平衡的测试数据集,对所有 16 个类别进行同等频率的响应能得到 4 bit 的最大可能熵。如果网络或观察者更偏爱响应其中某些类别,则熵会降低(如果是一直响应单个类别的极端情况,则会降至 0 bit,不管基本真值的类别如何)。人类表现的「误差线」表示了所有参与者的结果的整个区间。2.3 节将解释图像处理方法,可视化结果请参阅补充材料。
图 3:GoogLeNet、VGG-19 和 ResNet-152 以及人类观察者的分类准确度和响应分布熵。「熵」是指响应/决定分布(16 类)的香农熵。这里衡量了与特定类别的偏差:使用一个在每个类别的图像数量方面平衡的测试数据集,对所有 16 个类别进行同等频率的响应能得到 4 bit 的最大可能熵。如果网络或观察者更偏爱响应其中某些类别,则熵会降低(如果是一直响应单个类别的极端情况,则会降至 0 bit,不管基本真值的类别如何)。人类表现的「误差线」表示了所有参与者的结果的整个区间。2.3 节将解释图像处理方法,可视化结果请参阅补充材料。
虽然在仅有相对较小的与颜色相关的畸变时(比如灰度转换或反色)人类和 DNN 的性能接近,但我们发现人类观察者对其它所有畸变都更稳健:在低对比度、功率均衡和相位噪声图像上有少许优势,在均匀噪声、低通、高通、旋转和三种 Eidolon 实验上优势更大。此外,由响应分布熵衡量的误差模式存在很大的差异(这表明存在对特定类别的偏差)。当信号越来越弱时,人类参与者的响应在 16 个类别上或多或少是均等分布的,而三个 DNN 都表现出了对特定类别的偏差。这些偏差并不能完全通过先验类别概率解释,而且因具体畸变而各不相同。比如,对于有很强均匀噪声的图像,ResNet-152 几乎只能预测瓶子类别(与基本真值类别无关),而对于有严重相位噪声的图像则只能预测狗或鸟类别。人们可能会想到一些降低 DNN 和人类的响应分布熵之间的差异的简单技巧。一种可能的方法是增大 softmax 温度参数并假设模型的决定是从这个 softmax 分布采样的,而不是取自 argmax。但是,以这种方式增大响应 DNN 分布熵会极大降低分类准确度,因此需要一定的权衡(参见补充材料图 8)。
这些结果与之前报告的 DNN 中对颜色信息的处理与人类类似的发现一致 [Flachot and Gegenfurtner (2018)],但 DNN 识别的准确度会因噪声和模糊等图像劣化而显著下降 [Vasiljevic et al. (2016); Dodge and Karam (2016, 2017a, 2017b); Zhou et al. (2017)]。整体而言,在各种图像畸变情况下,DNN 在泛化到更弱信号上的表现比人类更差。尽管人类的视觉系统随进化过程和生命周期已经遇到了大量畸变,但我们显然没遇到过我们的测试中很多确切的图像处理方式。因此,我们的人类数据表明原则上高水平的泛化能力是可能的。我们发现,人类与 DNN 的泛化能力差异的可能原因有很多:在当前所使用的网络架构方面是否存在局限性(正如 Dodge and Karam (2016) 假设的那样),使得 DNN 无法匹敌人脑中错综复杂的计算?训练数据是否存在问题(Zhou et al. (2017) 就这样认为)?还是说当今的训练方法/优化方法不足以实现稳健和通用的目标识别?为了理解我们发现的差异之处,我们进行了另一批实验——直接在畸变图像上训练网络。
4 直接在畸变图像上训练 DNN
 图 4:使用可能畸变的数据训练的网络的分类准确度(百分数)。行表示中等难度的不同测试条件(括号中给出了具体条件,单位同图 3)。列对应按不同方式训练的网络(最左列:用于比较的人类观察者;没有人类在椒盐噪声方面的数据)。所有的网络都是在(可能处理过的)16-class-ImageNet上从头开始训练得到的。红框标记了对应网络的训练数据中使用的处理方法;此外,加上了下划线的结果表示「灰度」是训练数据的一部分,因为某些畸变方法包含了完全对比度的灰度图像。模型 A1-A9:在单一畸变上训练的 ResNet-50(100 epoch)。模型 B1-B9:在均匀噪声和另一种畸变上训练的 ResNet-50(200 epoch)。模型 C1 和 C2:在除一种畸变外的所有畸变上训练的 ResNet-50(200 epoch)。随机选中的几率是十六分之一,即 6.25%。
图 4:使用可能畸变的数据训练的网络的分类准确度(百分数)。行表示中等难度的不同测试条件(括号中给出了具体条件,单位同图 3)。列对应按不同方式训练的网络(最左列:用于比较的人类观察者;没有人类在椒盐噪声方面的数据)。所有的网络都是在(可能处理过的)16-class-ImageNet上从头开始训练得到的。红框标记了对应网络的训练数据中使用的处理方法;此外,加上了下划线的结果表示「灰度」是训练数据的一部分,因为某些畸变方法包含了完全对比度的灰度图像。模型 A1-A9:在单一畸变上训练的 ResNet-50(100 epoch)。模型 B1-B9:在均匀噪声和另一种畸变上训练的 ResNet-50(200 epoch)。模型 C1 和 C2:在除一种畸变外的所有畸变上训练的 ResNet-50(200 epoch)。随机选中的几率是十六分之一,即 6.25%。
我们为每种畸变直接在 16-class-ImageNet图像(有可能进行了图像处理)上从头开始训练一个网络。图 4(A1-A9)展示了训练的结果。我们发现,这些特定的网络在其所训练的图像处理类型上总是优于人类观察者的表现(即图中对角线上的优良结果)。这表明,当前所用的架构(比如 ResNet-50)和训练方法(标准的优化器和训练过程)足以「解决」独立同分布的训练/测试条件下的畸变。我们不仅能解决 Dodge and Karam (2017a) 观察到的人类与 DNN 表现的差异问题(他们在畸变上对网络进行了精细调节,但得到的 DNN 未达到人类水平),而且能在这方面超越人类的水平。尽管人类视觉系统的结构肯定更为复杂 [Kietzmann et al. (2017)],但看起来对处理这类图像处理问题来说似乎并不是必需的。
但是,正如之前指出的那样,稳健的泛化能力的关键不是解决事先已知的特定问题。因此,我们测试了在特定畸变类型上训练的网络在另一些畸变上的表现。图 4 A1-A9 中非对角线上的数据即为实验结果。整体而言,我们发现,在一些案例中,在特定畸变上训练能稍微提升在其它畸变上的表现,但也有一些案例给出了相反的结果(比较对象是在彩色图像上训练的纯 ResNet-50,即图中的 A1)。所有网络在椒盐噪声以及均匀噪声上的表现都接近随机乱选,即使是在各自相应的其它噪声模型上直接训练的网络也是如此。因为这两种类型的噪声在人眼看来其实差别并不大(如图 1(c) 所示),所以这一结果可能还是颇让人惊讶。因此,在一种畸变类型上训练的网络并不总是能实现在其它畸变上的表现提升。
因为只在单一一种畸变上训练似乎不足以为 DNN 带来强大的泛化能力,所以我们还在另外两种设置上训练了同样的架构(ResNet-50)。图 4 中 B1-B9 模型展示了在一种特定的畸变与均匀噪声的组合上训练后的结果(来自每种图像处理方法的训练数据各 50%)。选择均匀噪声的原因是这似乎是对所有网络而言最困难的畸变,因此将这种特定畸变纳入训练数据可能是有益的。此外,我们还在除去了一种畸变(除去了均匀噪声或椒盐噪声)之外的所有畸变上训练了模型 C1 和 C2。
我们发现,相比于模型 A1-A9,模型 B1-B9 的目标识别表现有所提升——不管是它们实际训练的畸变上(图 4 中的对角线上的红框),还是在其它未在训练数据中出现的畸变上。但是,这一提升的原因很大程度上可能是模型 B1-B9 训练了 200 epoch,而不是像 A1-A9 那样训练了 100 epoch,因为模型 B9(在均匀噪声上训练和测试,200 epoch)的表现也由于模型 A9(在均匀噪声上训练和测试,100 epoch)。因此,当存在严重畸变时,训练更长时间可能更有用,但将其它畸变集成到训练过程中却似乎并不具有普适的益处。此外,我们还发现,即使对于单个模型来说,在其所训练的所有 8 种畸变上都达到较高的准确度也是可能(模型 C1 和 C2),但是对于剩下的两种畸变(均匀噪声或椒盐噪声),目标识别准确度却仅有 11%-14%;比起在同一畸变上训练得到的专用网络(准确度超过 70%),这一准确度离随机乱选要近得多。
总的来说,这些发现表明仅使用畸变来进行数据增强可能不足以克服我们发现的泛化问题。问题也许应该变一变了——不再是「为什么 DNN 的泛化能力这么好(在独立同分布条件下)?」[Zhang et al. (2016)],而变成「为什么 DNN 的泛化能力这么糟(在非独立同分布条件下)?」目前被视为人类目标识别的计算模型的 DNN 将如何解决这一难题?还有待未来研究。这个激动人心的领域处于认知科学/视觉感知和深度学习领域的交叉点,会从这两个领域同时汲取灵感和新思想:计算机视觉的域适应子领域(参阅 Patel et al. (2015) 的综述)正在研究不受输入分布变化所影响的稳健型机器推理方法,同时人类视觉研究领域也正在积累证据证明局部增益控制机制的优势。这些标准化过程似乎对动物和人类的稳健视觉的很多方面而言都至关重要 [Carandini and Heeger (2012)],也能预测人类视觉数据 [Berardino et al. (2017); Schütt and Wichmann (2017)],并以证明可用于计算机视觉[Jarrett et al. (2009); Ren et al. (2016)]。神经标准化过程与 DNN 的泛化能力之间是否存在关联?这将是值得未来研究一个有趣方向。
5 总结
我们基于 12 种不同的图像畸变,对人类和 DNN 的目标识别稳健性进行了行为比较。我们发现,与人类观察者相比,在ImageNet上训练的三种知名 DNN(ResNet-152、GoogLeNet 和 VGG-19)的表现会随着图像畸变所造成的信噪比的减小而迅速降低。此外,我们还发现当信号越来越弱时,人类与 DNN 的分类误差模式的差别会逐渐增大。我们在良好控制的实验室条件下进行了 82880 次心理物理学试验,结果表明人类与当前 DNN 处理目标信息的方式仍存在显著区别。在我们的设置中,这些区别无法通过在畸变图像上进行训练(即数据增强)而克服:尽管 DNN 能完美应对其所训练过的特定畸变,但对于它们之前未曾见过的畸变类型,它们仍然束手无策。因为潜在畸变的类型基本上是无穷无尽的(不管是理论上还是实际应用中都是如此),所以不可能在所有畸变上都训练一遍。当超出常规的独立同分布假设时(通常是不现实的),DNN 就会遇到泛化问题。我们相信,不管是为了创造稳健的机器推理,还是为了更好地理解人类目标识别,解决这一泛化问题都至关重要。我们希望我们的发现以及我们精心测量并免费公开的行为数据能为 DNN 稳健性的提升提供一个有用的新基准,并能激励神经科学家找到大脑中负责这一出色的稳健性机制。
理论 计算机视觉 卷积神经网络 泛化
相关数据
Neural Network
(人工)神经网络是一种起源于 20 世纪 50 年代的监督式机器学习模型,那时候研究者构想了「感知器(perceptron)」的想法。这一领域的研究者通常被称为「联结主义者(Connectionist)」,因为这种模型模拟了人脑的功能。神经网络模型通常是通过反向传播算法应用梯度下降训练的。目前神经网络有两大主要类型,它们都是前馈神经网络:卷积神经网络(CNN)和循环神经网络(RNN),其中 RNN 又包含长短期记忆(LSTM)、门控循环单元(GRU)等等。深度学习是一种主要应用于神经网络帮助其取得更好结果的技术。尽管神经网络主要用于监督学习,但也有一些为无监督学习设计的变体,比如自动编码器和生成对抗网络(GAN)。
来源:机器之心
Deep neural network
深度神经网络(DNN)是深度学习的一种框架,它是一种具备至少一个隐层的神经网络。与浅层神经网络类似,深度神经网络也能够为复杂非线性系统提供建模,但多出的层次为模型提供了更高的抽象层次,因而提高了模型的能力。
来源:机器之心 Techopedia
Computer Vision
计算机视觉(CV)是指机器感知环境的能力。这一技术类别中的经典任务有图像形成、图像处理、图像提取和图像的三维推理。目标识别和面部识别也是很重要的研究领域。
来源:机器之心
ImageNet
Learning rate
在使用不同优化器(例如随机梯度下降,Adam)神经网络相关训练中,学习速率作为一个超参数控制了权重更新的幅度,以及训练的速度和精度。学习速率太大容易导致目标(代价)函数波动较大从而难以找到最优,而弱学习速率设置太小,则会导致收敛过慢耗时太长
来源:Liu, T. Y. (2009). Learning to rank for information retrieval. Foundations and Trends® in Information Retrieval, 3(3), 225-331. Wikipedia
Image processing
图像处理是指对图像进行分析、加工、和处理,使其满足视觉、心理或其他要求的技术。 图像处理是信号处理在图像领域上的一个应用。 目前大多数的图像均是以数字形式存储,因而图像处理很多情况下指数字图像处理。
来源: 维基百科
Machine Learning
机器学习是人工智能的一个分支,是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。
来源:Mitchell, T. (1997). Machine Learning. McGraw Hill.
Mapping
映射指的是具有某种特殊结构的函数,或泛指类函数思想的范畴论中的态射。 逻辑和图论中也有一些不太常规的用法。其数学定义为:两个非空集合A与B间存在着对应关系f,而且对于A中的每一个元素x,B中总有有唯一的一个元素y与它对应,就这种对应为从A到B的映射,记作f:A→B。其中,y称为元素x在映射f下的象,记作:y=f(x)。x称为y关于映射f的原象*。*集合A中所有元素的象的集合称为映射f的值域,记作f(A)。同样的,在机器学习中,映射就是输入与输出之间的对应关系。
来源: Wikipedia
Loss function
在数学优化,统计学,计量经济学,决策理论,机器学习和计算神经科学等领域,损失函数或成本函数是将一或多个变量的一个事件或值映射为可以直观地表示某种与之相关“成本”的实数的函数。
来源: Wikipedia
Momentum
优化器的一种,是模拟物理里动量的概念,其在相关方向可以加速SGD,抑制振荡,从而加快收敛
neurons
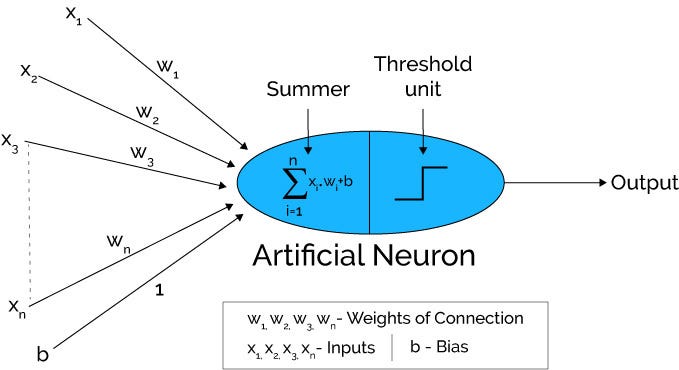
(人工)神经元是一个类比于生物神经元的数学计算模型,是神经网络的基本组成单元。 对于生物神经网络,每个神经元与其他神经元相连,当它“兴奋”时会向相连的神经元发送化学物质,从而改变这些神经元的电位;神经元的“兴奋”由其电位决定,当它的电位超过一个“阈值”(threshold)便会被激活,亦即“兴奋”。 目前最常见的神经元模型是基于1943年 Warren McCulloch 和 Walter Pitts提出的“M-P 神经元模型”。 在这个模型中,神经元通过带权重的连接接处理来自n个其他神经元的输入信号,其总输入值将与神经元的阈值进行比较,最后通过“激活函数”(activation function)产生神经元的输出。
来源: Overview of Artificial Neural Networks and its Applications. (2018). medium.com.
{kind=link}
neuroscience
神经科学,又称神经生物学,是专门研究神经系统的结构、功能、发育、演化、遗传学、生物化学、生理学、药理学及病理学的一门科学。对行为及学习的研究都是神经科学的分支。 对人脑研究是个跨领域的范畴,当中涉及分子层面、细胞层面、神经小组、大型神经系统,如视觉神经系统、脑干、脑皮层。
来源: 维基百科
Optimizer
优化器基类提供了计算梯度loss的方法,并可以将梯度应用于变量。优化器里包含了实现了经典的优化算法,如梯度下降和Adagrad。 优化器是提供了一个可以使用各种优化算法的接口,可以让用户直接调用一些经典的优化算法,如梯度下降法等等。优化器(optimizers)类的基类。这个类定义了在训练模型的时候添加一个操作的API。用户基本上不会直接使用这个类,但是你会用到他的子类比如GradientDescentOptimizer, AdagradOptimizer, MomentumOptimizer(tensorflow下的优化器包)等等这些算法。
来源: 维基百科
object recognition
计算机视觉领域的一个分支,研究物体的识别任务
self-driving
从 20 世纪 80 年代首次成功演示以来(Dickmanns & Mysliwetz (1992); Dickmanns & Graefe (1988); Thorpe et al. (1988)),自动驾驶汽车领域已经取得了巨大进展。尽管有了这些进展,但在任意复杂环境中实现完全自动驾驶导航仍被认为还需要数十年的发展。原因有两个:首先,在复杂的动态环境中运行的自动驾驶系统需要人工智能归纳不可预测的情境,从而进行实时推论。第二,信息性决策需要准确的感知,目前大部分已有的计算机视觉系统有一定的错误率,这是自动驾驶导航所无法接受的。
来源: 机器之心
perception
知觉或感知是外界刺激作用于感官时,脑对外界的整体的看法和理解,为我们对外界的感官信息进行组织和解释。在认知科学中,也可看作一组程序,包括获取信息、理解信息、筛选信息、组织信息。与感觉不同,知觉反映的是由对象的各样属性及关系构成的整体。
来源: 维基百科
Transfer learning
迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。 迁移学习对人类来说很常见,例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。
来源:机器之心Pan, S. J., & Yang, Q. (2010). A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22(10), 1345–1359.
Weight
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。
来源:Google AI Glossary
Deep learning
深度学习(deep learning)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。 深度学习是机器学习中一种基于对数据进行表征学习的算法,至今已有数种深度学习框架,如卷积神经网络和深度置信网络和递归神经网络等已被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
来源: LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. nature, 521(7553), 436.
Tensor
张量是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数,这些线性关系的基本例子有内积、外积、线性映射以及笛卡儿积。其坐标在 维空间内,有 个分量的一种量,其中每个分量都是坐标的函数,而在坐标变换时,这些分量也依照某些规则作线性变换。称为该张量的秩或阶(与矩阵的秩和阶均无关系)。 在数学里,张量是一种几何实体,或者说广义上的“数量”。张量概念包括标量、矢量和线性算子。张量可以用坐标系统来表达,记作标量的数组,但它是定义为“不依赖于参照系的选择的”。张量在物理和工程学中很重要。例如在扩散张量成像中,表达器官对于水的在各个方向的微分透性的张量可以用来产生大脑的扫描图。工程上最重要的例子可能就是应力张量和应变张量了,它们都是二阶张量,对于一般线性材料他们之间的关系由一个四阶弹性张量来决定。
来源: 维基百科
TensorFlow
TensorFlow是一个开源软件库,用于各种感知和语言理解任务的机器学习。目前被50个团队用于研究和生产许多Google商业产品,如语音识别、Gmail、Google 相册和搜索,其中许多产品曾使用过其前任软件DistBelief。
来源: 维基百科

机器之心是国内领先的前沿科技媒体和产业服务平台,关注人工智能、机器人和神经认知科学,坚持为从业者提供高质量内容和多项产业服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK