

Hinton提出的经典防过拟合方法Dropout,只是SDR的特例
source link: https://www.jiqizhixin.com/articles/2018-08-27-12?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

机器之心 原创
2018/08/27 2:10Noah Frazier-Logue、Stephen José Hanson 作者 Geek AI、王淑婷 编译 arXiv 选自
Hinton提出的经典防过拟合方法Dropout,只是SDR的特例
Hinton 等人提出的 Dropout 方案在避免神经网络过拟合上非常有效,而本文则提出,Dropout 中的按概率删除神经元的原则只是二项随机变量的特例。也就是说,研究者用神经元权重的连续分布替换了原先的二值(零/非零)分布,实现了广义的 Dropout——随机 delta 规则(SDR)。基准实验表明,SDR 能显著降低分类误差和损失值,并且收敛得更快。
1 引言
多层神经网络在文本、语音和图像处理的多种基准任务上都取得了令人瞩目的效果。尽管如此,这些深层神经网络也会产生难以搜索的高维、非线性 超参数 空间,进而导致过拟合以及泛化能力差。早期的神经网络使用反向传播算法,它们会由于缺乏足够的数据、梯度损失恢复以及很可能陷入性能较差的局部最小值而失效。深度学习(Hinton et al,2006)引入了一些创新技术来减少、控制这些过拟合和过度参数化问题,包括用线性整流单元(ReLU)来减少连续梯度损失,用 Dropout 技术避免陷入局部最小值,以及通过有效的模型平均技术来增强泛化能力。尽管数据海啸可以为各种各样的分类和回归任务提供大量的数据,在本文中,作者仍将重点讨论深层神经网络的过度参数化问题。Dropout 可以用来缓解过度参数化以及过度参数化引起的深度学习应用过拟合问题,还能够避免陷入性能较差的局部最小值。具体而言,Dropout 实现了一个概率为 p(有偏的 0-1 抽签法)的伯努利随机变量,在每一轮更新时从网络架构中随机删除隐藏单元及其连接,从而产生一个稀疏的网络架构——其中剩余权重被更新并保留到下一个 dropout 步骤中。在学习结束时,通过计算每个权重p_w_ij 的期望值,重构了深度学习网络,这样的做法近似于对指数级数量的一组神经网络进行模型平均。在大多数情况下,带 Dropout 机制的深度学习能够在常见的基准测试中降低 50% 以上的误差率。
在本文余下的部分中,作者将介绍一种通用类型的 Dropout 技术,它能够在权值级别上进行操作并在每轮更新中注入依赖于梯度的噪声,这种技术被称为随机 delta 规则(SDR,参见 Murray & Andrews, 1991)。SDR 为每个权重实现了一个随机变量,并且为随机变量中的每个参数提供了更新规则,本文使用了带自适应参数的高斯分布(均值为µ_w_ij,标准差为 σ_w_ij)。尽管所有的 SDR 可以作用于任意的随机变量(gamma 分布、beta 分布、二项分布等)。本文将说明,Dropout 是一个带有固定参数(np, np(1 − p)) 的二项随机变量的特例。最后,作者将用高斯 SDR 在标准基准(例如,CIFAR-10 和 CIFAR-100)中测试 DenseNet 框架,并且说明其相对于二项分布的 Dropout 具有很大的优势。
论文:Dropout is a special case of the stochastic delta rule: faster and more accurate deep learning

论文地址:https://arxiv.org/pdf/1808.03578v1.pdf
摘要:多层神经网络在文本、语音和图像处理的各种基准任务中都取得了令人瞩目的效果。然众所周知,层次模型中的非线性参数估计存在过拟合问题。Dropout(Srivastava, et al 2014, Baldi et al 2016)是一种用来解决这种过拟合以及相关问题(局部最小值、共线性、特征发现等)的方法。这种方法在每轮更新中通过带有概率 p 的伯努利随机变量删除隐藏单元。在本文中,我们说明了 Dropout 是一种更加通用的模型特例,这种被称为随机 delta 规则(「SDR」, Hanson, 1990)的模型于 1990 年被首次发表。SDR 用一个均值为µ_w_ij、标准差为 σ_w_ij 的随机变量将网络中的权值参数化。这些随机变量在每一次前馈激活中通过采样得到,从而建立指数级数量的共享权值的潜在网络。这两个参数都会根据预测误差而更新,从而实现了反映预测误差局部历史的权值噪声注入和高效的模型平均。因此,SDR 对每个权值实现了一个局部梯度依赖的模拟退火,从而收敛为一个贝叶斯最优网络。使用改进版的 DenseNet 在标准基准(CIFAR)上进行测试的结果显示,SDR 相较于标准 dropout 误差率降低了 50% 以上,损失也减少了 50% 以上。此外,SDR 的实现在指定的解决方案上收敛得更快,而且,采用 SDR 的 DenseNet-40 只需要训练 15 个 epoch 就实现误差率为 5% 的目标,而标准 DenseNet-40 实现这一目标需要训练 94 个 epoch。
5 实验结果

表 1:采用 SDR 的 DenseNet 与采用 dropout 的 DenseNet 误差率对比
上述结果表明,在 DenseNet 测试中,用 SDR 替换 dropout 技术会使所有 CIFAR 基准测试的误差减少 50 % 以上,降幅高达 64%。原始 DenseNet 实现的误差结果低于原始 DenseNet 论文中的误差结果,因为我们发现使用更大的批处理会带来更高的总体准确率。

表 2:达到训练误差率为 15%,10%,5% 分别所需的 epoch 数量。
如表 2 所示,使用 SDR 后,在训练中将误差率降到 15%,10%,5% 所需的时间明显缩短。使用了 SDR 的 DenseNet-40 只需要原本 1/6 的 epoch 就能够取得 5% 的误差率,而使用了 SDR 的 DenseNet-100 则只需原来 60% 的 epoch 就能实现 5% 的误差率。

图 3:采用 dropout 的 DenseNet-100 训练 100 个 epoch 之后的准确率(橙色曲线)和采用 SDR 的 DenseNet-100 训练 100 个 epoch 的准确率(蓝色曲线)。比起 dropout,SDR 不仅能够更快地提高训练准确率(训练 17 个 epoch 达到了 96% 的准确率,drouout 达到相同的准确率需要 33 个 epoch),而且还能够在训练 40 个 epoch 后达到 98% 的准确率。

图 4:表示采用 SDR 的 DenseNet-100 的第 21 层第 1 块的权重值频率的直方图,其中每个切片都是来自训练一个 epoch 的 snapshot,而最上面的切片是来自第一个 epoch 的 snapshot。在训练 100 个 epoch 的过程中,随着权值的标准差趋近于零,曲线变窄。
2 随机 delta 规则
众所周知,实际的神经传播包含噪声。如果一个皮质分离的神经元周期性地受到完全相同的刺激,它永远不会产生相同的反应(如烧伤等刺激)。设计 SDR 的部分原因是生物系统中通过神经元传递信号的随机性。显然,平滑的神经速率函数是建立在大量的刺激试验基础上的。这让我们想到了一种实现方法,即两个神经元之间的突触可以用一个具有固定参数的分布来建模。与这种分布相关的随机变量在时域内可能是一个 Gamma 分布(或在分级响应中,参见泊松分布)。在这里,我们假设有一个符合中心极限定理的独立同分布集合,并且采用高斯分布作为一般形式。尽管如此,对于独立成分分析(ICA)来说,同等情况下,长尾分布可能更具优势。

图 1:SDR 采样
如图 1 所示,我们按照图中的方法实现采用均值为 µwij、标准差为 σwij 的高斯随机变量的 SDR 算法。因此,将从高斯随机变量中采样得到每个权值,作为一种前馈运算。实际上,与 Dropout 类似,指数级别的网络集合通过训练期间的更新采样获取。与 Dropout 在这一点上的区别是,SDR 会调整每个权重上附加的隐藏单元的权重和影响,以便在更新时随误差梯度自适应地变化。这里的效果也与 Dropout 相类似,除了每个隐藏单元的响应会分解到权重上(与分类误差对信用分配的影响成比例)。因此,每个权重梯度本身也是基于隐藏单元预测性能的随机变量,它让系统能够:(1)在相同的例程/刺激下接受多值响应假设,(2)保留一个预测历史,与 Dropout 不同,Dropout 是局部的隐藏单元权重,在某个集合上是有条件的,甚至是一个特定的例程(3)可能返回由于贪婪搜索得到的性能较差的局部最小值,但是同时也远离了更好的局部最小值。局部噪声注入的结果对网络的收敛具有全局影响,并且为深度学习提供了更高的搜索效率。最后一个优点是,如 G. Hinton 所说,局部噪声注入可能通过模型平均平滑误差表面的沟壑,使模型能够更快更稳定地收敛到更好的局部最小值。

图 2:Dropout 采样
相关数据
Neural Network
(人工)神经网络是一种起源于 20 世纪 50 年代的监督式机器学习模型,那时候研究者构想了「感知器(perceptron)」的想法。这一领域的研究者通常被称为「联结主义者(Connectionist)」,因为这种模型模拟了人脑的功能。神经网络模型通常是通过反向传播算法应用梯度下降训练的。目前神经网络有两大主要类型,它们都是前馈神经网络:卷积神经网络(CNN)和循环神经网络(RNN),其中 RNN 又包含长短期记忆(LSTM)、门控循环单元(GRU)等等。深度学习是一种主要应用于神经网络帮助其取得更好结果的技术。尽管神经网络主要用于监督学习,但也有一些为无监督学习设计的变体,比如自动编码器和生成对抗网络(GAN)。
来源:机器之心
Back-propagation
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。 在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
Convergence
在数学,计算机科学和逻辑学中,收敛指的是不同的变换序列在有限的时间内达到一个结论(变换终止),并且得出的结论是独立于达到它的路径(他们是融合的)。 通俗来说,收敛通常是指在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
Hyperparameter
在机器学习中,超参数是在学习过程开始之前设置其值的参数。 相反,其他参数的值是通过训练得出的。 不同的模型训练算法需要不同的超参数,一些简单的算法(如普通最小二乘回归)不需要。 给定这些超参数,训练算法从数据中学习参数。相同种类的机器学习模型可能需要不同的超参数来适应不同的数据模式,并且必须对其进行调整以便模型能够最优地解决机器学习问题。 在实际应用中一般需要对超参数进行优化,以找到一个超参数元组(tuple),由这些超参数元组形成一个最优化模型,该模型可以将在给定的独立数据上预定义的损失函数最小化。
来源: Wikipedia
Gaussian distribution
正态分布是一个非常常见的连续概率分布。由于中心极限定理(Central Limit Theorem)的广泛应用,正态分布在统计学上非常重要。中心极限定理表明,由一组独立同分布,并且具有有限的数学期望和方差的随机变量X1,X2,X3,...Xn构成的平均随机变量Y近似的服从正态分布当n趋近于无穷。另外众多物理计量是由许多独立随机过程的和构成,因而往往也具有正态分布。
来源: Wikipedia
Image processing
图像处理是指对图像进行分析、加工、和处理,使其满足视觉、心理或其他要求的技术。 图像处理是信号处理在图像领域上的一个应用。 目前大多数的图像均是以数字形式存储,因而图像处理很多情况下指数字图像处理。
来源: 维基百科
Independent Component Analysis
在统计学中,独立成分分析或独立分量分析(Independent components analysis,缩写:ICA) 是一种利用统计原理进行计算的方法。它是一个线性变换。这个变换把数据或信号分离成统计独立的非高斯的信号源的线性组合。独立成分分析是盲信号分离(Blind source separation)的一种特例。
来源: 维基百科
neurons
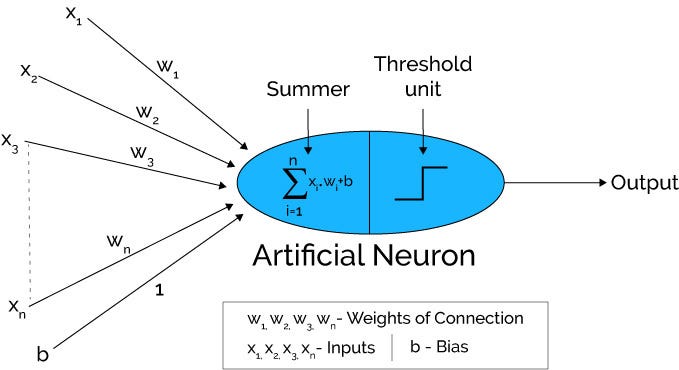
(人工)神经元是一个类比于生物神经元的数学计算模型,是神经网络的基本组成单元。 对于生物神经网络,每个神经元与其他神经元相连,当它“兴奋”时会向相连的神经元发送化学物质,从而改变这些神经元的电位;神经元的“兴奋”由其电位决定,当它的电位超过一个“阈值”(threshold)便会被激活,亦即“兴奋”。 目前最常见的神经元模型是基于1943年 Warren McCulloch 和 Walter Pitts提出的“M-P 神经元模型”。 在这个模型中,神经元通过带权重的连接接处理来自n个其他神经元的输入信号,其总输入值将与神经元的阈值进行比较,最后通过“激活函数”(activation function)产生神经元的输出。
来源: Overview of Artificial Neural Networks and its Applications. (2018). medium.com.
Weight
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。
来源:Google AI Glossary
Deep learning
深度学习(deep learning)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。 深度学习是机器学习中一种基于对数据进行表征学习的算法,至今已有数种深度学习框架,如卷积神经网络和深度置信网络和递归神经网络等已被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
来源: LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. nature, 521(7553), 436.
Refactoring
代码重构(英语:Code refactoring)指对软件代码做任何更动以增加可读性或者简化结构而不影响输出结果。 软件重构需要借助工具完成,重构工具能够修改代码同时修改所有引用该代码的地方。在极限编程的方法学中,重构需要单元测试来支持。
来源: 维基百科
Accuracy
分类模型的正确预测所占的比例。在多类别分类中,准确率的定义为:正确的预测数/样本总数。 在二元分类中,准确率的定义为:(真正例数+真负例数)/样本总数
Central limit theorem
中心极限定理是概率论中的一组定理。中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件。
来源: 维基百科
机器之心是国内领先的前沿科技媒体和产业服务平台,关注人工智能、机器人和神经认知科学,坚持为从业者提供高质量内容和多项产业服务。



{kind=link}
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK