

从数据库分析OpenStack创建虚机流程
source link: https://www.sdnlab.com/21244.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:李金葵,邮箱:[email protected]
治大国若烹小鲜,学OpenStack亦是如此。每一个深入学习OpenStack的人都会从虚拟机创建流程开始自己的OpenStack代码分析之旅,因为它贯穿核心组件,覆盖了大部分OpenStack通用技术。食材的做法有煎、炒、烹、炸,把虚拟机创建流程比作食材,本文就给它换个做法,给读者呈现不同的口味。

基本介绍
在OpenStack创建虚拟机的过程中,可能会涉及到的数据库有三个,分别是:
- nova
- nova_api
- nova_cell0
下图是OpenStack的所有的数据库
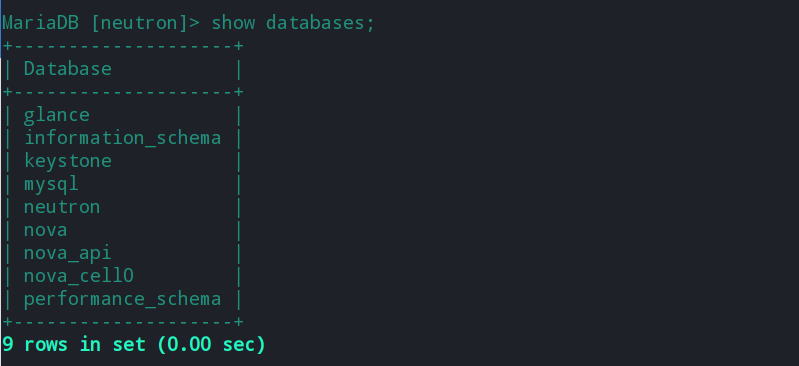
这三个数据库里存放的表主要有:
- nova
早期的OpenStack只有nova一个数据库,里面存放了所有的关于虚拟机的表。如instance表:存放每一个主机主机信息(后面会介绍到);quotas表:项目配额信息 ;fixed_ips表;块存储设备表等。 - nova_api
从nova数据库中移除的一部分全局数据表组成的数据库,如flavors、key_pairs、quotas等。noav_api的出现是为了解决大规模时消息队列和数据库瓶颈问题。 - nova_cell0
nova_cell0数据中存放了所有创建失败的instance。虚拟机创建失败后不属于任何一个cell,那么就记录在nova_cell0中。
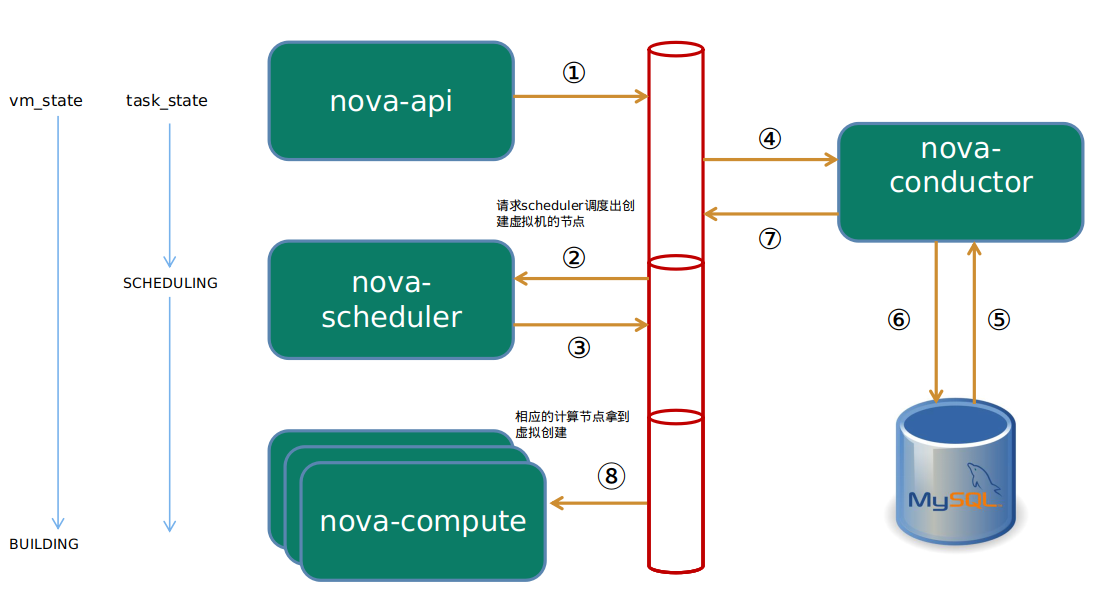
OpenStack创建虚拟机的过程可以分为三个大的部分:
- 界面或命令行发送请求到nova-api;
- nova-api接收到请求,经过nova-scheduler,nova-condutor等模块拿到创建虚拟机的计算节点信息,发送到相应节点;
- 计算节点的nova-compute请求glance、neutron、cinder等服务获取创建的必要数据,然后调用底层Hypervior创建虚拟机;
代码流程
OpenStack版本众多,本文使用的是Newton。创建虚拟机对应的代码流程大致如下,其中双冒号后面是类名,单冒号后面是函数名。
下面就从虚拟机创建的三个部分结合代码流程,逐个分析在整个过程中数据库的变化。
一、接收请求
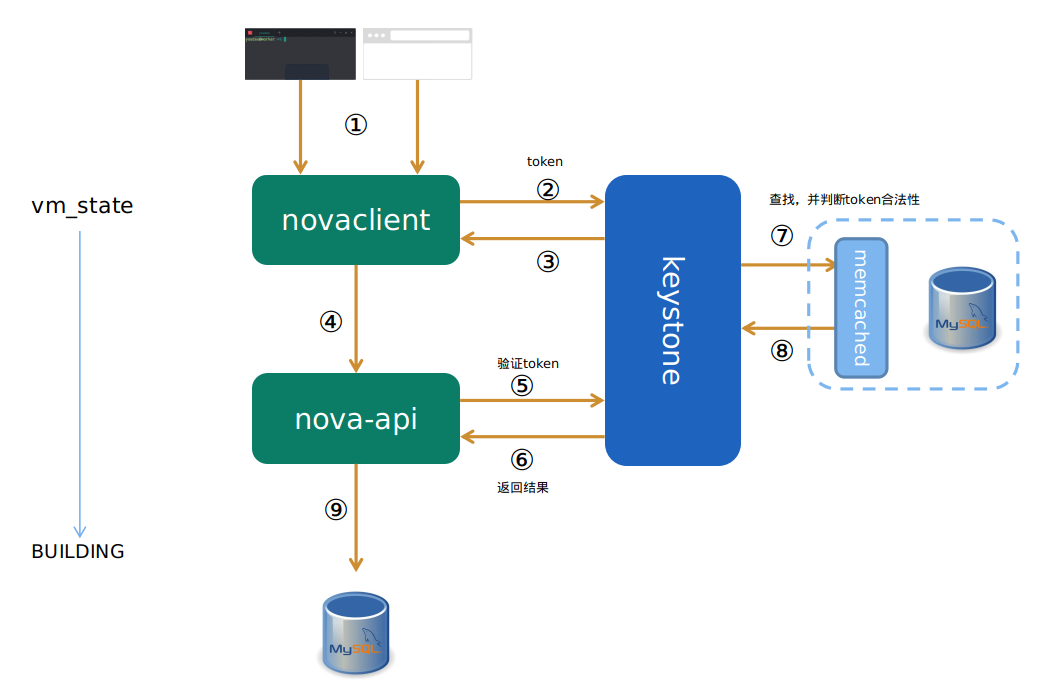
工作流程
Dashborad或者CLI命令行请求创建虚拟机,novaclient收到创建命令,将token发送到keystone去验证。keystone通过查询memcached和数据库中的token,返回token的有效性,然后novaclient发送请求到nova-api。nova-api 同样验证token,最后进入到创建虚拟机的第一个函数当中去,即nova/api/OpenStack/compute/servers.py文件下
controller类中的create方法。这里就是虚拟机创建的入口,万里长征的第一步。
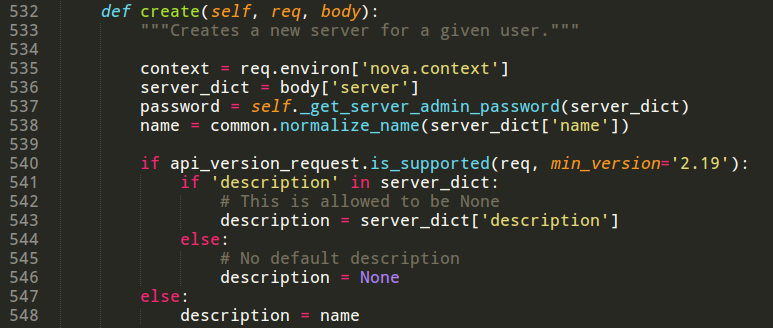
这个方法主要是对传入的虚拟机的参数做简单验证,检查字段合法性、可用域等信息。nova/compute/api.py中的create方法检查是否创建多个实例,是否指定IP,是否指定端口等信息。最后谈一下nova-api模块的一个重要的函数_create_instance()。该函数完成了很多数据库操作。
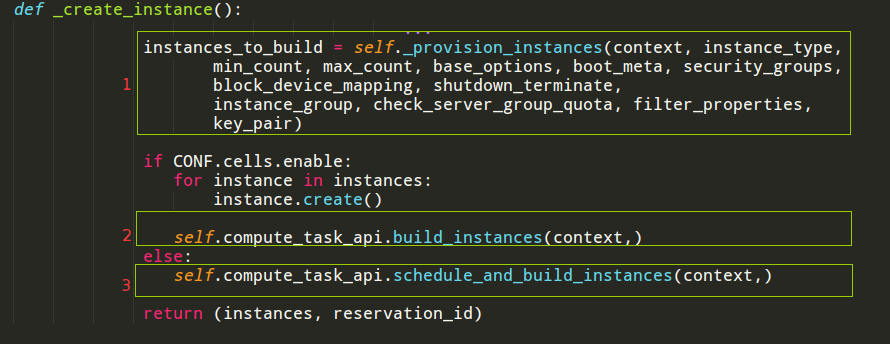
如上图中,2是为虚拟机指定了创建的域要执行的代码,3是未指定创建的域,需要任务调度完成的代码。不管是否需要调度,创建之前都要将创建虚拟机的参数写入到数据库中,1就是完成这个任务。1中的函数具体的工作如下:
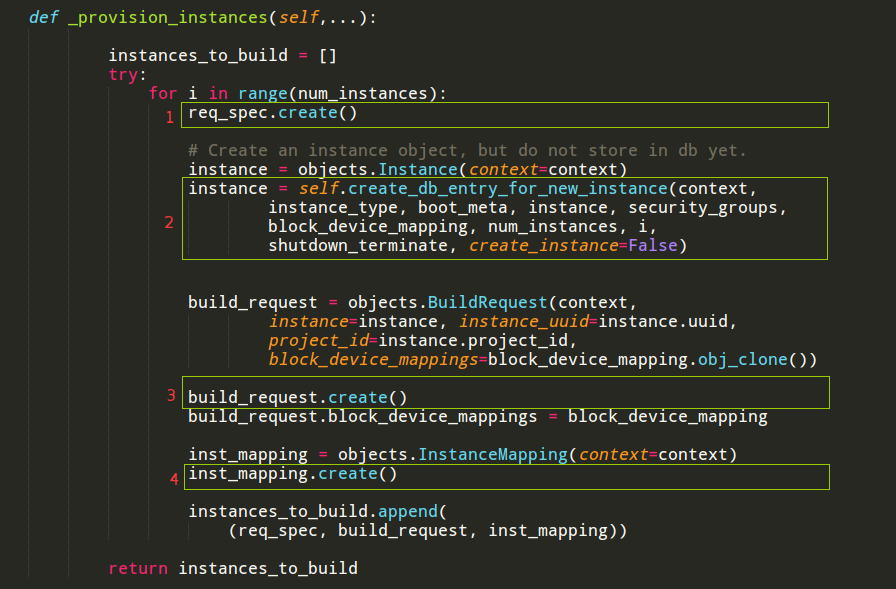
从上图可见创建了4个数据表记录,分别是:req_spec、instance、build_request、
inst_mapping。下面分析四张表的重要意义。
instance表
创建虚拟机之前的工作,主要是写入虚拟机的原始数据。
req_spec表
虚拟机调度需要的信息,如虚拟机个数,uuid,类型,安全组等。
build_request表
创建虚拟机时nova-api不会把初始化数据直接保存到nova数据库的instances表中,而是保存到nova_api数据库的build_requests表。
inst_mapping表
实例映射表,不同cell之间的实例映射
instance表是一张基本表,很多表都依赖于instance表,由于instance表意义重大,下面分析instance表的具体字段。
instance字段分析
从创建instance表的函数传入的数据可以看到,参数有instance_type、image、instance、security_group、block_device_mapping、num_instances、index等字段。

如下是完整的instances表,有多达52个字段。这里给读者一个读后小任务—-分析instances中自己感兴趣的字段,如果能够分析清楚,功力肯定更进一步。
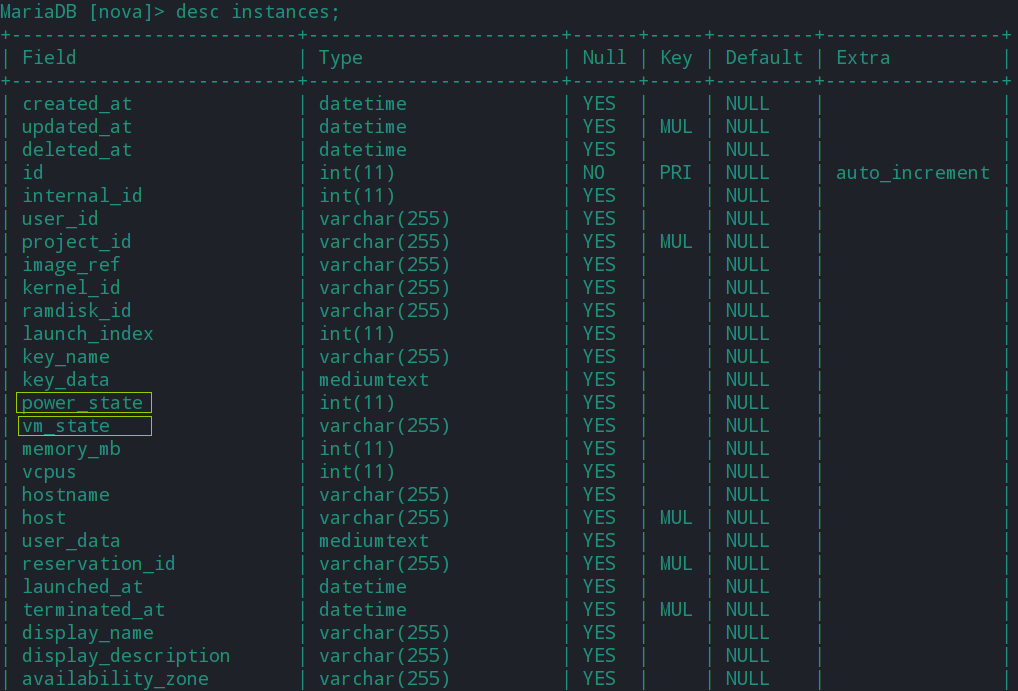
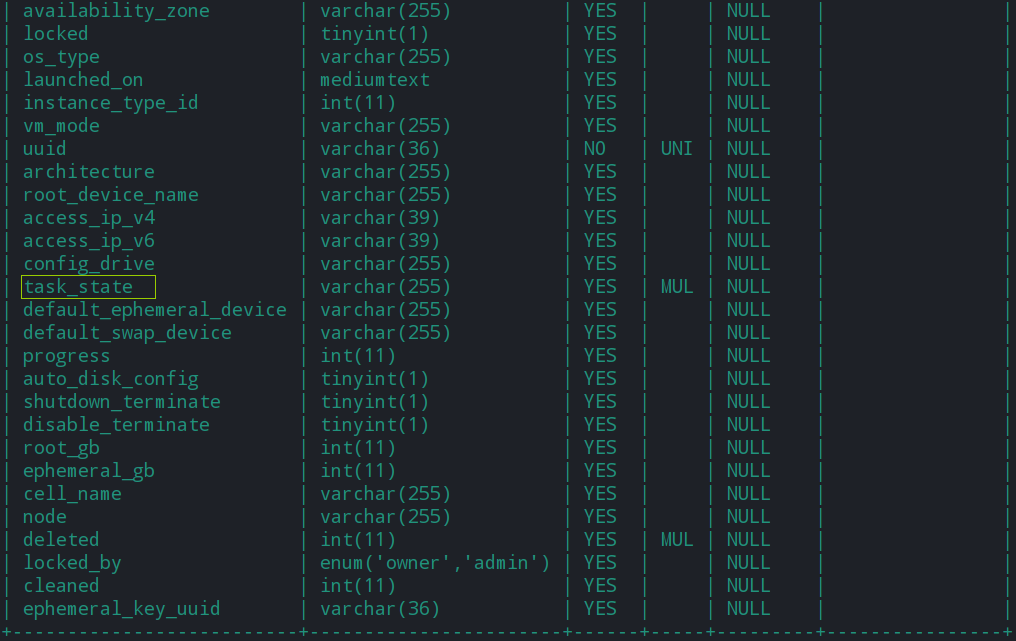
多余的字段暂且不讨论,与创建虚拟机密切相关的字段有三个,分别是:
- power_state 从Hypervisor获取的虚拟机的状态
- vm_state 虚拟机通过api产生的状态,有Active、Error、Reboot、Build、Shutoff五种
- task_state 表示虚拟机正在执行的某种操作
通过这三个字段的变化,能够完整的描述虚拟机创建的过程。如流程图所示,从instance表创建时,vm_state的字段就填入值:Building。power_state和task_state暂时还没有数据。下面的分析就以这个三个字段为主线,串联整个流程。
二、虚机调度
工作流程
nova-api接收到创建请求之后,通过RPC调用nova-conductor写入数据库信息,然后调用nova-scheduler选定创建虚拟机的主机,最后调用nova-compute完成虚拟机的创建。
主要代码是在RPC调用中,下面简单分析nova-conductor中的RPC调用。首先api.py发起调用,使用nova-conductor的客户端。
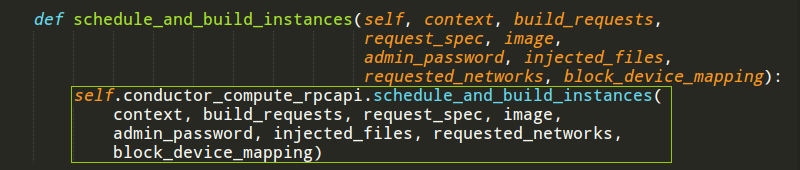
客户端封装好参数之后直接调用服务端
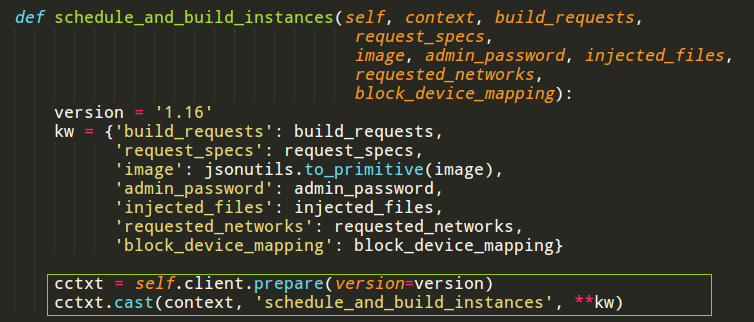
服务端收到调用,接收参数,完成处理。
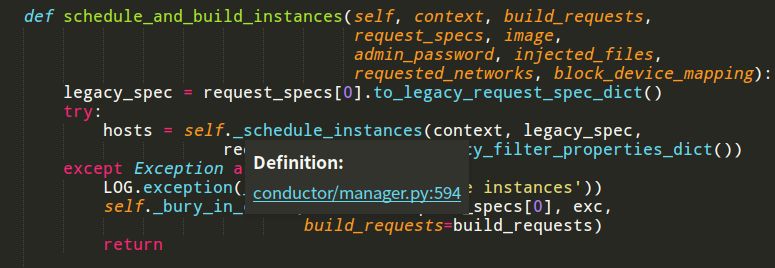
在这个过程中,vm_state一直处于Building的状态,task_state则会有一个调度的任务。
在nova/compute/api.py文件下的API.py类的populate_instance_for_create方法中将instance表中的vm_state设置成BUILDING,将task_state设置成SCHEDULING,表明该过程在调度。
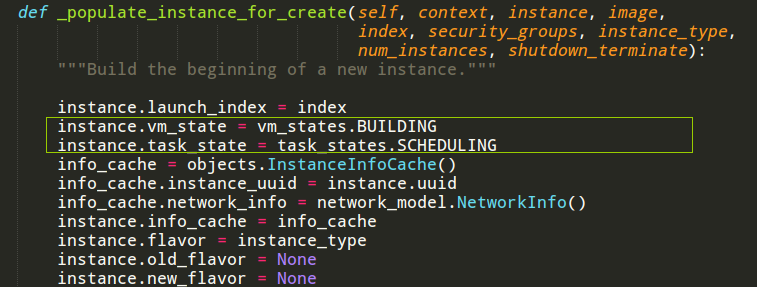
调度过程不再详细描述,在整个第二部分中数据的读写有很多。读者有兴趣再做分析。
三、获取创建资源
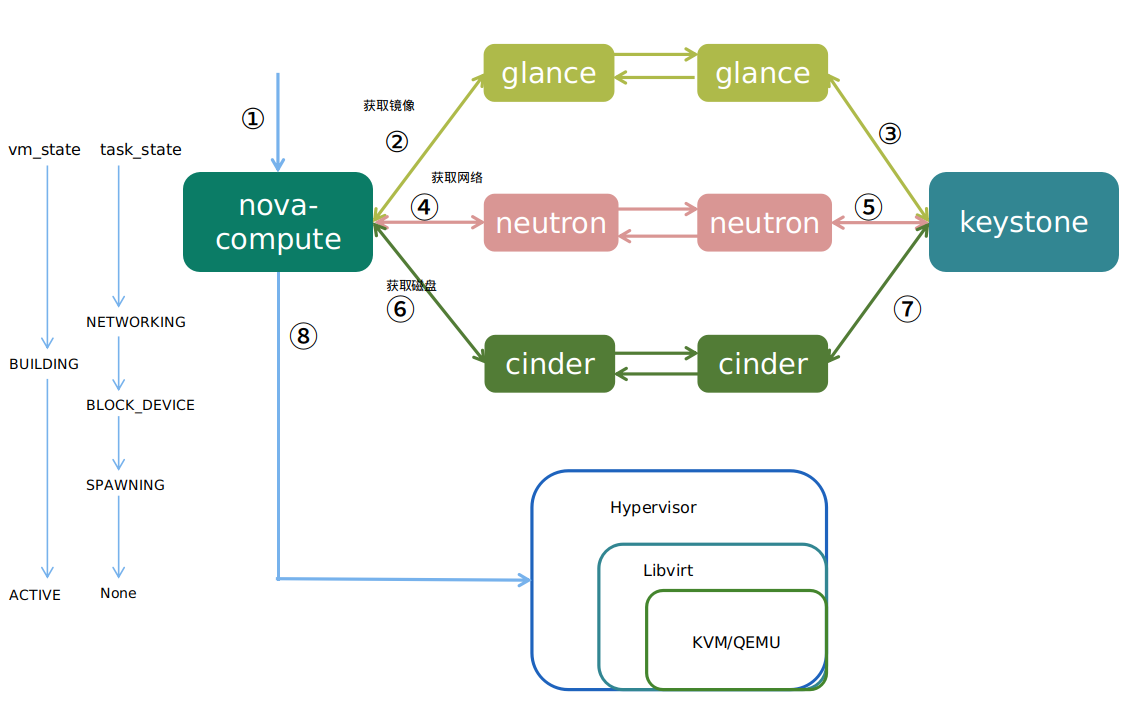
工作流程
当nova-compute接收到创建虚拟机的请求之后,会调用nova-conductor获取虚拟机的创建参数,如cpu,内存,磁盘,镜像,网络等。接着从glance服务获取镜像,从neutron服务获取网络,从cinder服务获取磁盘(如果安装了cinder服务)。最后调用底层的Hypervisor完成虚拟机创建。
底层创建好之后vm_state的状态会从building变成active,而task_state的状态在获取网络时是NETWORKING,获取磁盘时是BLOCK_DEVICE,最后变成spawning孵化中。
数据表字段变化
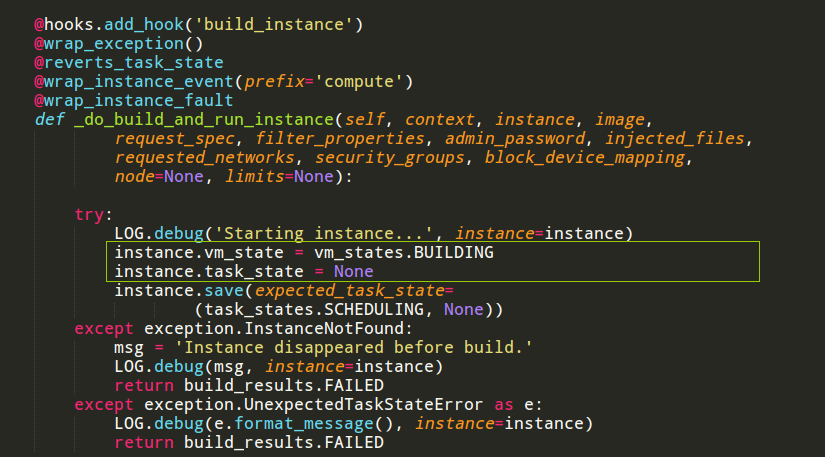
进入nova-compute模块之后,在nova/compute/manager.py文件ComputeManager类的_do_build_and_run_instance函数中,instance表中要写入vm_states和task_state的状态。
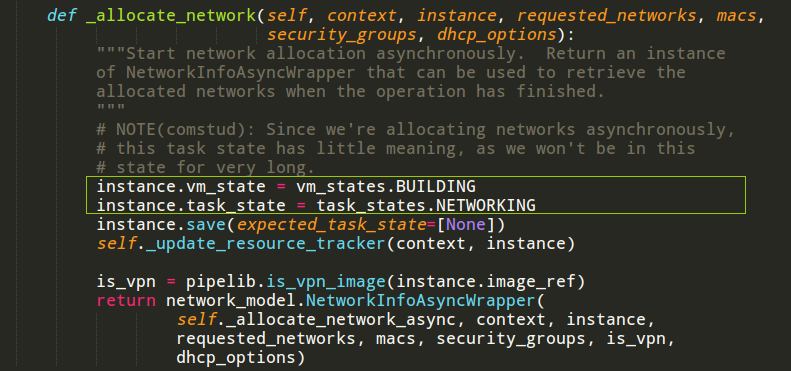
在compute代码模块下的_build_resource函数是为了获取网络资源和磁盘资源。

获取网络时,task_state变成NETWORKING
在neutron服务中,当其收到来自nova_compute的请求之后,会创建网卡对应的port表,在post中填充IP地址时会从ipallocationpools中选择相应网络的网段ip。然后将已经分配过的ip地址写入到ipallocations表中。
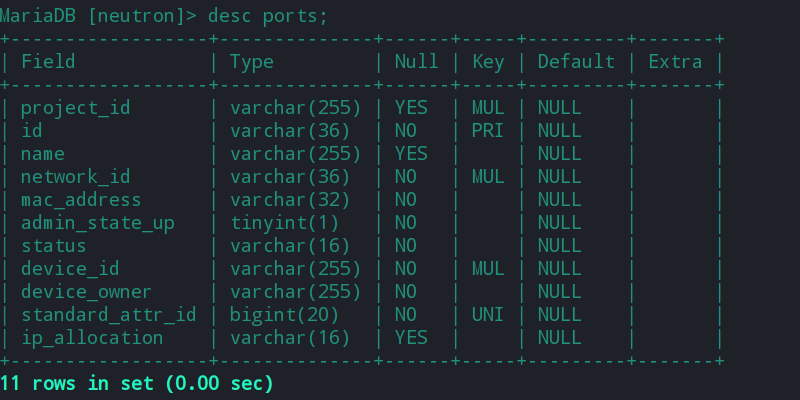
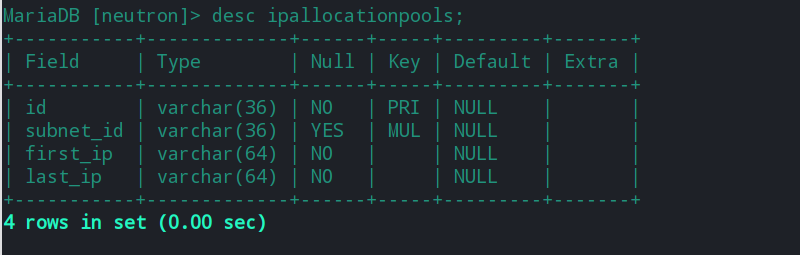
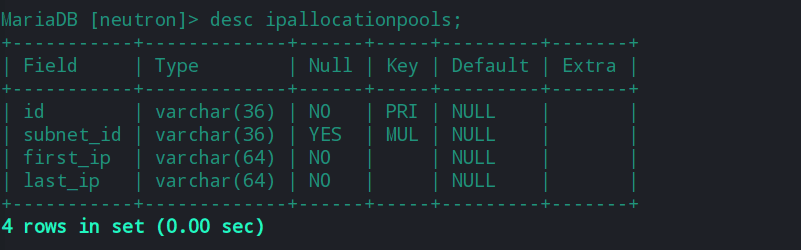
更多neutron数据库的内容,可参考如下文章:
https://www.cnblogs.com/goldsunshine/p/7941970.html
获取磁盘时,task_state变成BLOCK_DEVICE_MAPPING
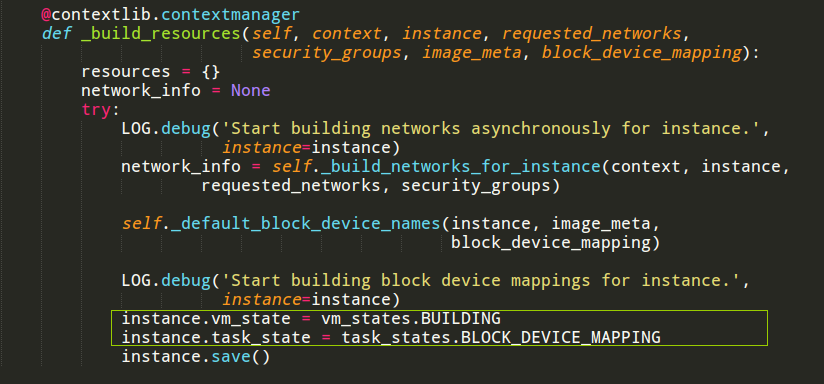
当所有的资源都获取完成之后,nova-compute会调用底层Hypervisor完成创建,这时task_state的任务会变成孵化状态,这个状态也是持续时间最长的。


当底层驱动创建好虚拟机之后,spwaning的任务完成,instance表中的task_state字段变成none,同时vm_state变成Active,power_state变成Running,虚拟机的创建就完成了。
总结
OpenStack 创建虚拟机流程的分析就到这里结束了,希望数据库读写能够辅助读者更好理解这个过程。一篇文章要分析整个流程是远远不够的,只能是描述一个大概轮廓。由于OpenStack版本众多,代码上可能会有小的出入,读者需仔细辨别。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK