

传统交换机支持OpenFlow的变身大法
source link: https://www.sdnlab.com/20974.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者:洪建明,深圳市泰信通信息技术有限公司解决方案总监,曾在国内知名网络厂商任职十多年,对网络芯片架构有较深的造诣。
OpenFlow 定义的交换机包括报文多元组的匹配,进行查找和转发,交换机可以对各种类型报文任意bit进行匹配,即进行查找。任何交换的基本原理都是查找、转发。而查找是核心。
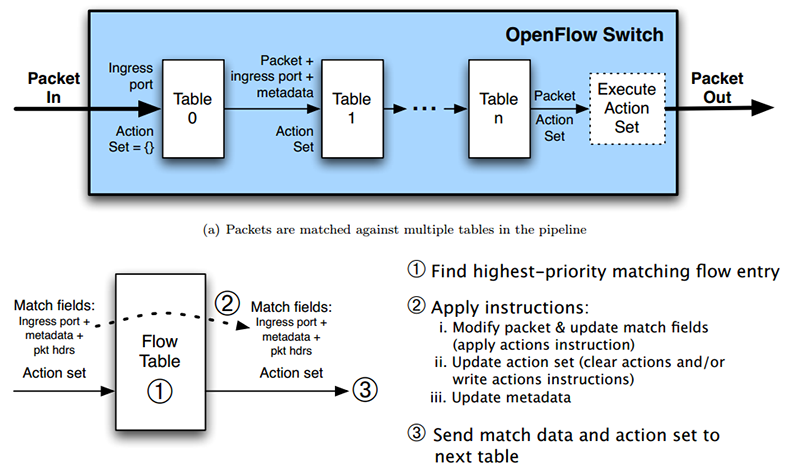
当前各大网络设备厂商纷纷推出自己支持OpenFlow的交换机,而这些交换机是如何支持OpenFlow复杂的报文查找呢?
硬件搭台,软件唱戏,任何软件的功能基石都是硬件,软件没有硬件的支持都是空中楼阁。目前SDN交换机主要有两类,采用传统商用芯片和专门开发支持OpenFlow的ASIC,其中最方便快捷推出的就是采用传统商用芯片的SDN交换机。传统芯片里面除了二层表,三层表,还有一个叫ACL表的查找模块,该模块采用TCAM结构,基本可以实现报文任意bit的匹配,也就可以用来进行OpenFlow对现有字段的匹配,甚至可以进行未来需要变化的新增种类报文的匹配。
TCAM是Ternary Content Addressable Memory的缩写,中文:三重内容可寻址内存。memory是根据地址来访问存储的内容,而TCAM恰好相反,它是根据内容去找到地址。memory中每个bit都只能表示两个值:0或1,而TCAM每个bit可表示三个值:0,1和X,X表示don't care,这个X其实是靠一个对应的mask bit来控制的,实际上TCAM每个bit物理上是2个bit。
根据内容去找到地址怎么理解呢?平常的memory是根据地址来访问存储的内容,好比说酒店里301房间住的客人叫张三,我们想知道301住着谁,就查下301房间的登记的人员,一看叫张三。而根据内容去找到地址刚好反过来,有人到酒店说,我们找一个叫张三的,酒店前台就挨个查看酒店每个房间登记的客人名单,最后查出张三在301,这个过程可比查301住的谁要复杂,因为要一个房间一个房间的确认客人叫什么。
有人问,那这个有啥复杂的,挨个看不就行了。可是我们现在时间比较急,想尽快知道张三在哪,所以酒店就通过消防广播对所有房间同时进行呼叫,说请张三听见就答应一声,酒店里所有人都听见了,除了张三其他人都没有答复,只有张三回复了下前台说,我住301,然后前台的人就知道了张三住301,这就是TCAM的查找原理。
回到memory存储的数据上,假设存储器的4个地址存着四个数据,如下
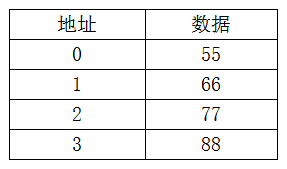
CPU访问时,输出地址0,就得到55这个数据。输出地址2就得到77这个数据,这就是正常的存储器访问。我们如果需要知道77存在哪里地址,CPU只能是先发地址0,读出55,发现不是我们需要的,再发地址1,读出数据是66,发现还不是我们需要的,再发地址2,读出数据是77,这就是我们需要的数据77,CPU一共进行了3次读取操作。如果我们需要知道88存在哪个地址,CPU就必须读4次才能知道地址是3。如果是10万个地址呢?
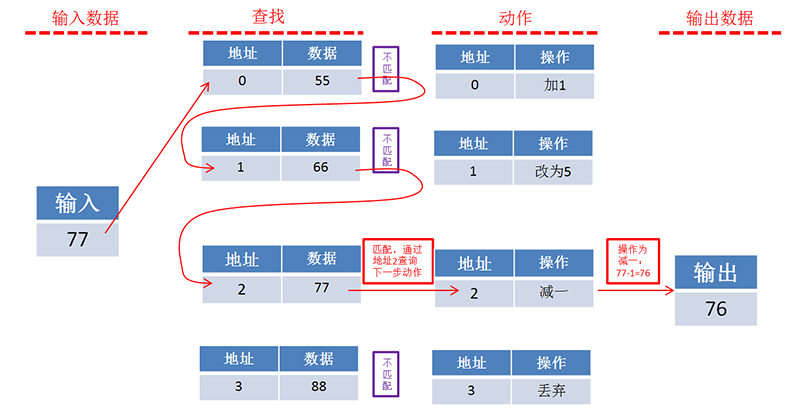
而TCAM的操作是这样的,收到需要匹配的数据和所有地址存储的数据同时(注意,是同时)进行比较,哪个地址存储的数据匹配上了就输出其地址,没有匹配的就不输出。输出地址就是下一步动作的索引。
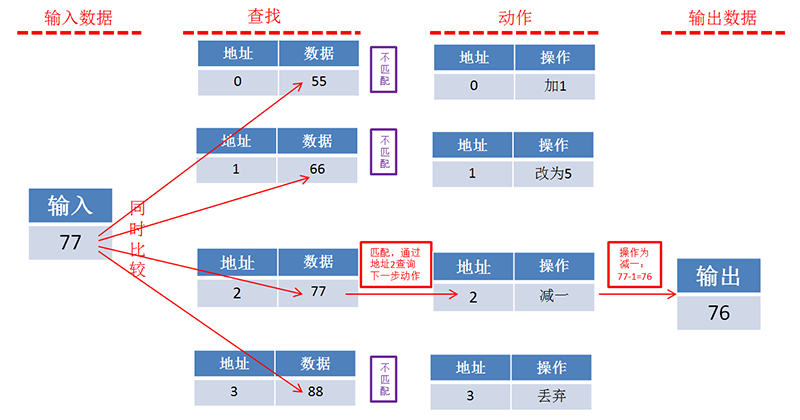
查找某个数据在哪个地址,用TCAM的办法一次就搞定了,而不论有多少个地址。那么代价呢?CPU逐个查找的方式虽然慢,但是只需要重复读出来、比较的动作,只需要能对一个数据进行对比即可。TCAM的方式是有100个数据,则需要支持100个数据同时比较,如果有10000个数据,则需要支持10000个数据同时比较,耗费的资源也就按比例线性增加。
TCAM的三重内容指的是除了上面说到的数据匹配,还有和数据一样多的一个mask控制数据,以便对不需要匹配的bit进行过滤,也就是匹配的数据无论多少,再翻一倍……
回到我们采用TCAM方式来实现OpenFlow,假设按照OpenFlow要求,我们需要对数据包的前100bit进行任意匹配,那么我们就需要每个地址存储100bit的数据以便进行匹配,而我们需要进行10000种不同的包类型进行匹配,那么就需要10000个地址来存储,每个地址100bit,也就是我们需要能够同时对100*10000=1000000bit进行比较,找出对应的地址,加上三重内容,同时比较的数据就变成了2000000bit。这就变成了一个非常庞大的比较芯片。
当我们查出某个数据存在的地址后,这个地址就可以作为一个索引,也就是另外一个标准memory的地址,该地址里面就存在这个包要做什么操作,例如转发到某个端口,或者修改某个特征,然后再转发。也就是OpenFlow规定的action,这个其实非常简单,复杂的就是前面说的所有地址空间的数据同时进行匹配。
完成一次匹配需要大量的比较资源,传统芯片这部分匹配模块就不能做的太大容量,一般也就支持4K流表,也就是对4K种不同类型的输入数据进行匹配。对于一个支持成千上万用户的传统交换机来说,变成支持OpenFlow的SDN交换机后,居然只能支持4K流表,简直就是沦为玩具一般,似乎就不太实用了。专门进行OpenFlow流表的新兴ASIC呢?大部分似乎也是基于TCAM这种方式,同样由于上面说的TCAM的原因,依然流表数量有限。
流表数量不足,是否说传统交换机就不能支持OpenFlow了?然而并不是的,例如泰信通SDN控制器的一体化转发设计,不再被芯片的TCAM限制,在使用传统芯片架构的交换机的情况下突破4K的TCAM限制,实现控制转发分离的一体化转发模式,真正兼容传统,焕发SDN的光彩。如需了解更详细的方案介绍,欢迎您与泰信通联系!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK