

OVS DataPath Classifier反向设计
source link: https://www.sdnlab.com/20966.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:Mr Huang,SDN/NFV研发工程师 技术方向:SDN 、NFV、Openstack
1.问题定义
ovs datapath classifier是原生ovs实现快速转发的核心功能模块。本文主要分析该模块的具体实现细节。

2.设计考虑
2.1.整体数据结构
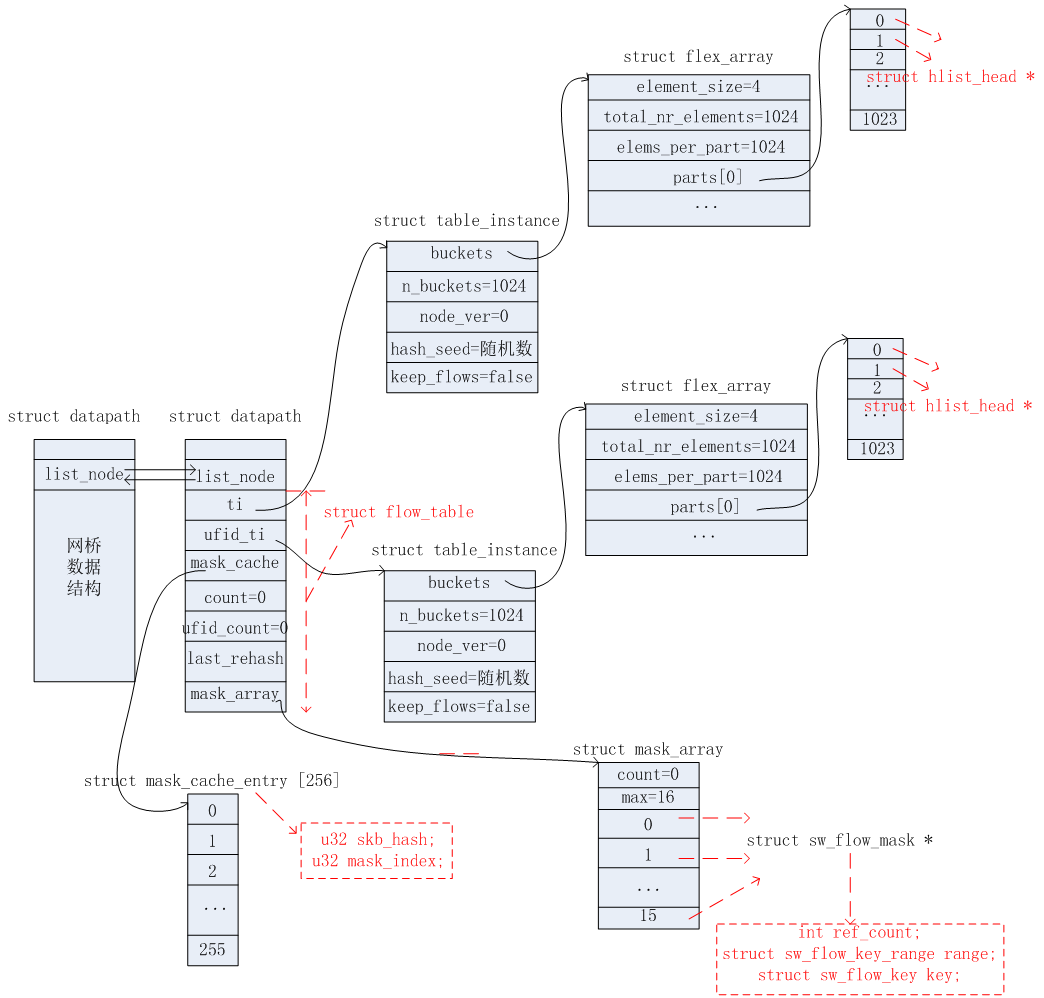
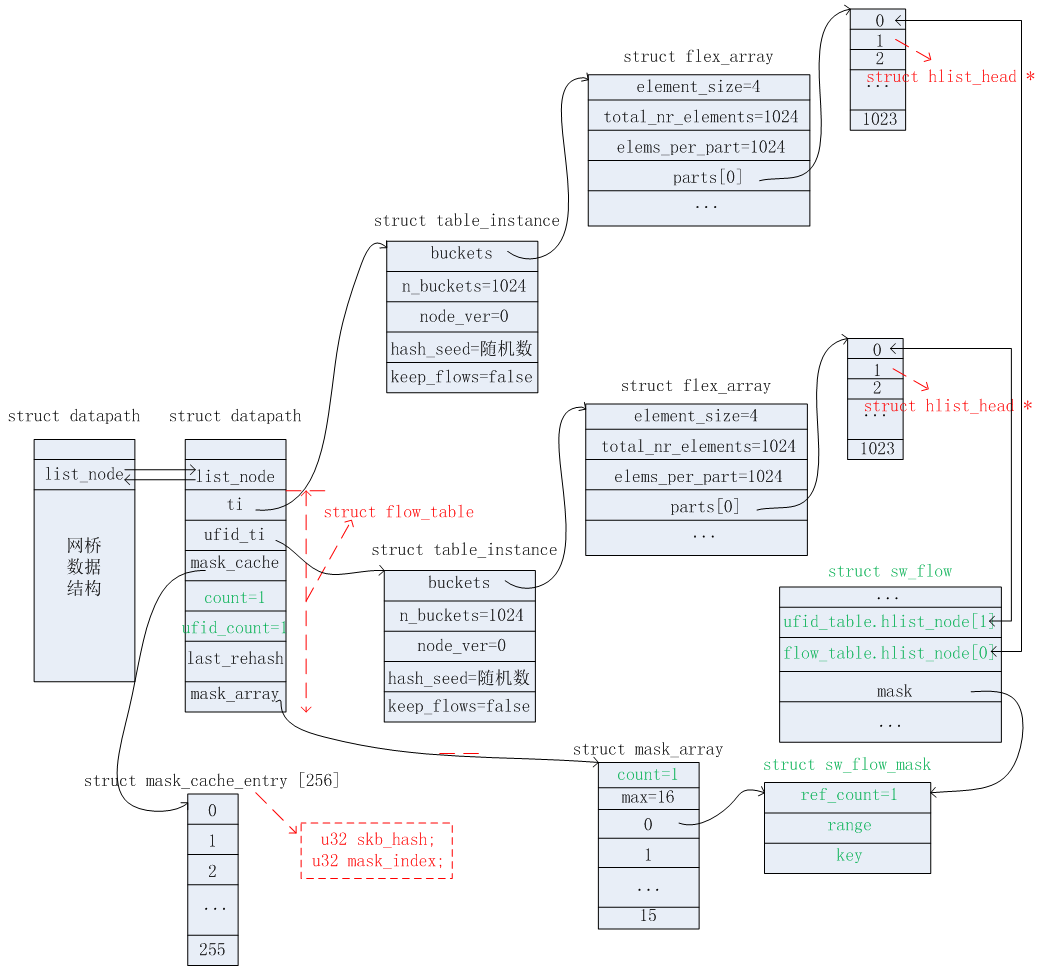
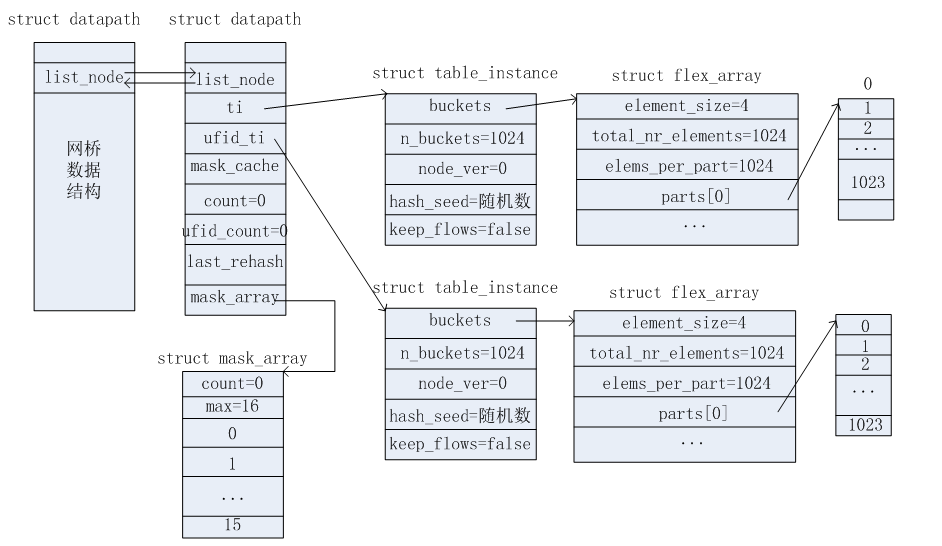
ovs datapath classifier涉及的数据结构主要有如下。
网桥数据结构
流表数据结构
流表实例数据结构
掩码信息列表数据结构
struct mask_array { struct rcu_head rcu; /* 当前已存储的掩码信息数目 */ int count; /* 一共可以存储掩码信息的总数目 */ int max; /* 具体的掩码信息 */ struct sw_flow_mask *masks[]; }
struct sw_flow_mask { /* 引用计数 */ int ref_count; struct rcu_head rcu; /* 匹配关键字的有效范围,下文会具体解释 */ struct sw_flow_key_range range; /* 匹配关键字信息 */ struct sw_flow_key key; }
掩码信息缓存表数据结构
哈希桶数据结构
struct flex_array { union { struct { /* 实际等于sizeof(struct hlist_head) */ int element_size; /* 一共有多少个struct hlist_head指针. */ int total_nr_elements; /* 每个part(页)可以存储多少个struct hlist_head指针 */ int elems_per_part; u32 reciprocal_value reciprocal_elems; /* 具体存储struct hlist_head指针的缓冲区 */ struct flex_array_part *parts[]; }; /* 填充字段.代表了整个结构的大小=页大小(4096字节) */ char padding[FLEX_ARRAY_BASE_SIZE]; } }
struct flex_array_part { /* 缓冲区.一个页大小,即:4096字节 */ char elements[FLEX_ARRAY_PART_SIZE]; };
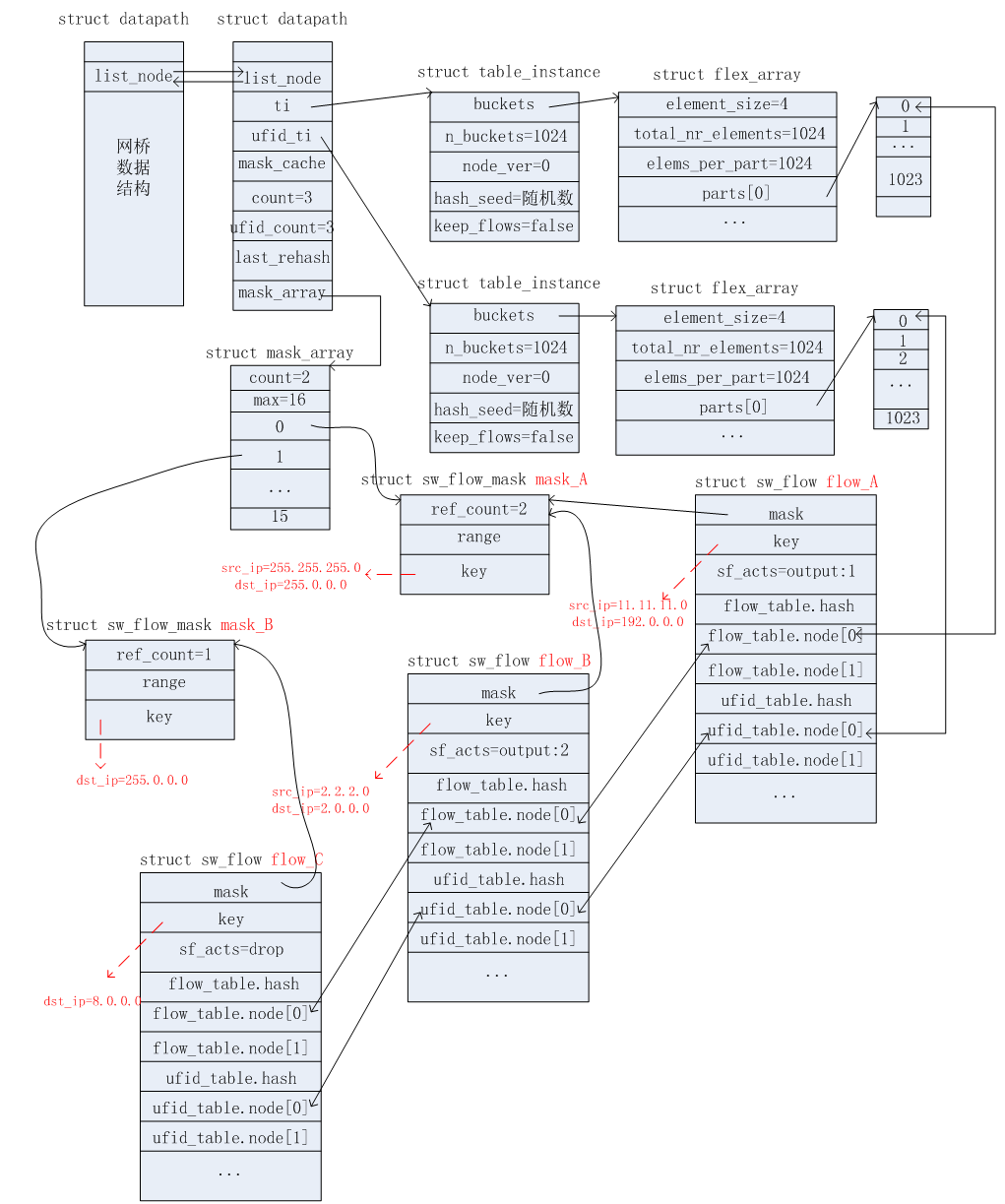
上述这些数据结构是在源码中的ovs_flow_tbl_init函数里面进行初始化操作的。初始化后以及上述这些数据结构之间的关系如下图所示。
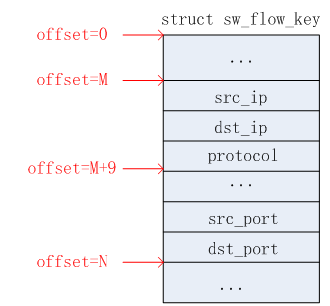
2.2.关键信息范围
从上面2.1节可知,掩码信息(struct sw_flow_mask结构)中记录了一个范围(struct sw_flow_key_range结构),该范围用于标识需要匹配的关键信息最小偏移和最大偏移。为什么需要这样做?个人感觉和ovs-dpdk datapath classifier中描述的miniflow类似,即:匹配过程中并非使用报文的所有字段去匹配,而是使用部分字段,例如使用报文的五元组信息(源IP、目的IP、协议号、源端口、目的端口)。那么使用sw_flow_key_range结构来标识这五元组信息中最小偏移和最大偏移。实际源码中,关键信息是使用struct sw_flow_key结构来描述的。由于该结构字段较多,这里不详细给出。以报文五元组信息为例,这里给出的五元组信息所在sw_flow_key结构的位置和实际源码对应的位置是不相同的,这里只是给出计算最小偏移和最大偏移的概念,如下图所示,关键信息的有效范围为:
最小偏移=M,最大偏移=N
2.3.更新过程
在源码中,对应更新过程的入口函数是:ovs_flow_cmd_new。这个入口函数是处于内核模块中,在接收到报文时,通过下面2.4节所述的查找过程,查找失败时,会将报文的相关信息upcall到用户空间,在用户空间通过查找”慢路径”将对应的actions和mask信息下发到内核空间,在内核空间,处理的入口函数正是ovs_flow_cmd_new。下面将对这个函数的处理过程作详细描述。描述之前,先掌握一些相关的数据结构,如下所示:
struct sw_flow { struct rcu_head rcu; /* 哈希桶链表 */ struct { struct hlist_node node[2]; u32 hash; } flow_table, ufid_table; int stats_last_writer; /* 关键信息.经过掩码运算后的 */ struct sw_flow_key key; /* 流id信息 */ struct sw_flow_id id; /* 指向的掩码信息 */ struct sw_flow_mask *mask; /* 指向的流动作信息 */ struct sw_flow_actions *sf_acts; struct flow_stats *stats[]; }
struct sw_flow_id { u32 ufid_len; union { /* ufid为128比特,共16字节 */ u32 ufid[4]; struct sw_flow_key *unmasked_key; } }
struct sw_flow_actions { struct rcu_head rcu; size_t orig_len; u32 actions_len; struct nlattr actions[]; }
struct sw_flow_match { struct sw_flow_key *key; struct sw_flow_key_range range; struct sw_flow_mask *mask; }
具体流程如下所示:
1)初始化struct sw_flow *new_flow。分配空间给new_flow,并设置部分的成员值,如下:
new_flow->sf_acts = null;
new_flow->mask = null;
new_flow->id.ufid_len=0;
new_flow->id.unmasked_key=null;
2)构建struct sw_flow_match match信息。根据接收到的关键信息和掩码信息,存储在match.key和match.mask中。
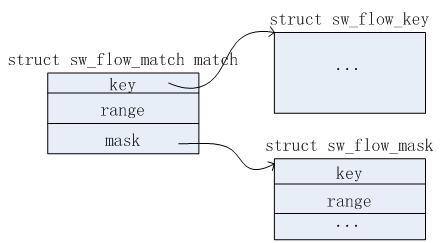
3)计算new_flow->key = match.key & match.mask。
4)将ufid信息提取出来存储在new_flow->id.ufid_len和new_flow->id.ufid中。如果未提供任何的UFID信息(此时的new_flow->id.ufid_len为0),则将match.key信息拷贝一份到new_flow->id.unmasked_key中存储。
5)将actions信息存储在变量struct sw_flow_actions acts中。
6)根据接收到的dp_ifindex获取struct datapath dp信息。
7)如果new_flow->id.ufid_len不为0,则使用new_flow->id.ufid信息去dp->table.ufid_ti指向的哈希桶中找到对应的struct sw_flow信息。假设找不到。
8)而如果new_flow->id.ufid_len为0,则需要在dp->table.ti,同时配合在2)中构建出来的match.key和dp->table.mask_array配合找出对应的struct sw_flow信息。这个详细过程可以参考下面的2.4节。这里也假设找不到。
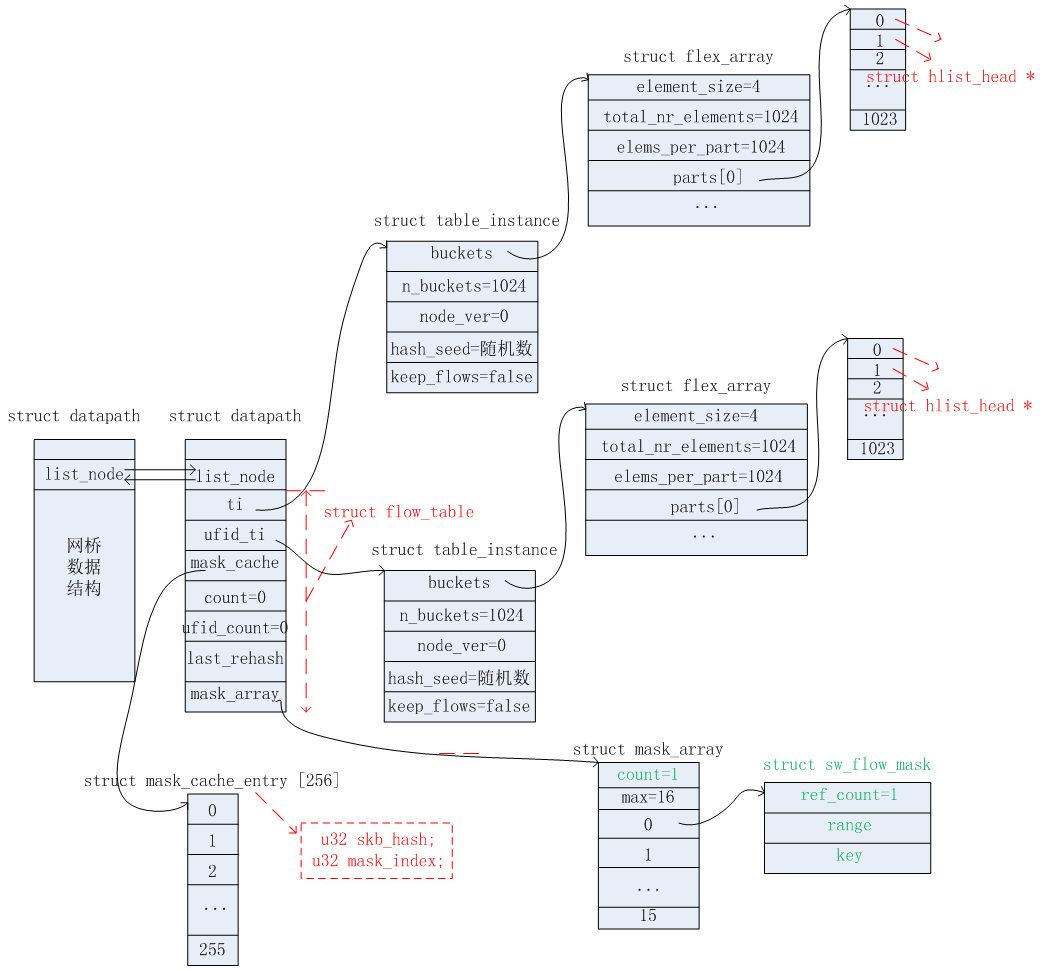
9)经过上面7)和8)步都没找到对应的struct sw_flow信息。首先设置new_flow->sf_acts=acts(在5)步中获取)。然后使用match.mask去dp->table.mask_array中查找是否已存在该match.mask信息。如果不存在则接着分配一个struct sw_flow_mask *mask。设置mask->key=match.mask->key, mask->range=match.mask->range, mask->ref_count=1。并且在dp->table.mask_array.masks[i]中存储该mask的地址。添加完毕之后,如下图所示。变化的地方用绿色标注出来了。同时new_flow->mask=mask。
10)根据new_flow->key和new_flow->mask.range计算出new_flow->flow_table.hash值。
11)在dp->table.ti->buckets指向的哈希桶中插入new_flow。如下图所示(假设插入的位置为part[0]对应的第0个位置)。dp->table.count。
12)如果new_flow->id.ufid_len不为0,则使用new_flow->id.ufid信息计算出new_flow->ufid_table.hash。然后根据这个hash值在dp->table.ufid_ti->buckets中找到合适的哈希桶存储对应的new_flow信息。这里假设找到的位置为parts[0]的第0个位置。如下图所示。插入new_flow信息之后,dp->table.ufid_count。
到此为止,更新过程完毕。
2.4.查找过程
在源码中,对应查找过程的入口函数是:ovs_vport_receive。具体过程如下:
1)从接收到的报文信息中提取出关键信息。存储到struct sw_flow_key key。
2)从接收到的报文信息中获取struct vport信息,再从vport信息获取struct datapath信息,假设为dp。
3)如果接收到的报文中未带有skb_hash值信息,则执行:
遍历每一个掩码,即:dp->table.mask_array->masks[i]。这里简单记为mask。将1)提取出来的关键新key与这个掩码mask做逻辑与运算,得出掩码过的信息,记为masked_key。通过masked_key和mask.range信息计算出hash值在dp->table.ti->buckets中找到对应的哈希桶,并遍历该桶上的所有struct sw_flow信息,记为flow。执行比较:如果flow->mask指向的是mask,flow->flow_table.hash值和计算出的hash值相等,且flow->key和masked_key信息在mask.range指定的范围内完全相同,则认为成功匹配,返回flow信息。否则匹配失败,返回NULL。
4)如果接收到的报文中带有skb_hash值信息,则执行:
4)-1:根据旧的skb_hash值和key->recirc_id值重新计算出新的skb_hash值。
4)-2:将skb_hash值分成4段,每段1字节,记为hash。遍历每一段的hash值,执行:获取dp->table.mask_cache[hash]表项,记为entry,如果entry.skb_hash值和skb_hash值相等,则使用entry.mask_index指向的掩码信息去dp->table.ti->buckets中找到对应的struct sw_flow信息(过程和上述第3)步相同)。如果找到对应的flow,则返回flow,过程中会更新entry.mask_index值来实际指向具体的掩码信息索引。否则,匹配失败,将entry.skb_hash值置0,返回NULL。而如果每一个entry.skb_hash值和skb_hash值不相等,则遍历完每一段hash值之后,从中选择最佳候选entry,最佳候选的条件是:其skb_hash值最小者,假设记为ce。最后使用ce.mask_index指向的掩码信息去dp->table.ti->buckets中找到对应的struct sw_flow信息(过程和上述第3)步相同)。如果找到对应的flow,则返回flow,同时将ce->skb_hash值更新为skb_hash值。当然在查找的过程中(上述第3)步),也会更新ce->mask_index来指向实际的掩码信息索引。
5) 如果在上述第3)和第4)步中都匹配失败了,则需要将报文的信息upcall到用户空间,由用户空间负责查找对应的流动作信息,返回给内核。这个过程具体请参考上述2.3节。
到此为止,查找过程结束。
2.5.执行过程
在2.4节查找过程中,如果查找成功,则需要执行对应的流动作。入口函数是:ovs_execute_actions。
而如果查找失败,upcall到用户空间,找到对应的流动作之后,调用执行,到内核空间,入口函数对应的是:ovs_packet_cmd_execute。该函数最终会调用到ovs_execute_actions。
2.6.掩码信息比较
在上述2.3和2.4节所述的更新过程和查找过程中都会遇见用新构造的掩码信息与datapath结构的table.mask_array作比较,以检测掩码信息是否需要新增。而比较的方法如下:
假设新构造的掩码信息为mask,与table.mask_array->masksi比较:
1)mask.range.start和exist_mask.range.start相等。
2)mask.range.end和exist_mask.range.end相等。
3)mask和exist_mask在range范围内完全相同。
同时符合上面三个条件才认为两个掩码完全相同。
2.7.流信息比较
在上述2.4节所述的查找过程中,对接收到的报文进行匹配表项时,需要对流信息作比较。假设接收到的报文提取出来的关键信息为key,匹配的掩码信息为mask,通过mask & key计算出掩码后的报文关键信息,记为masked_key,通过masked_key和mask.range计算出hash值。根据这个hash值找到对应的哈希桶,遍历这个哈希桶中存储的每一个流信息,记为flow。现在需要比较flow信息进而找到匹配的流表项。比较如下:
1)flow->mask指向的是mask。
2)flow->flow_table.hash和计算出的hash值相等。
3)flow->key和masked_key在mask.range范围内完全相同。
同时符合上面三个条件才认为找到匹配的流表项。
2.8.mask_cache表项
在ovs_dp_process_packet函数中查找匹配的流表项时,如果报文的skb中已经带有skb_hash值,则将这个skb_hash值(32比特)分为4段,每段8比特,每段的哈希值暂记为hash,用这个hash值去datapath结构中的table.mask_cache缓存表中查找对应的掩码信息索引。每个表项(struct mask_cache_entry结构)存储了skb_hash和mask_index信息。初始化的时候,这个缓存表中所有表项都置0,因此,用报文的skb_hash值,分4段去查找,都无法找到合适的表项。这时需要从中选出最佳候选的表项,而最佳候选的表项为其skb_hash值最小。因此,初始化的时候,最终会选择table.mask_cache[0]为最佳候选表项。
接着根据上述2.4节所述的查找过程,找到合适的流表项信息。如果匹配成功,则最佳候选表项table.mask_cache[0].mask_index记录了掩码信息索引(index),即:table.mask_array->masks[index]。同时table.mask_cache[0].skb_hash赋值为skb_hash。假设index为0,则对应如下图所示。
后续如果收到的报文带的skb_hash值与table.mask_cache[0].skb_hash值相等时,则首先使用table.mask_cache[0].mask_index索引的掩码信息去找匹配的流表信息。当然,如果匹配成功,table.mask_cache[0].mask_index可能并非为0(之前存储的值),有可能更新为其他值。而如果匹配失败,则table.mask_cache[0].skb_hash置0。
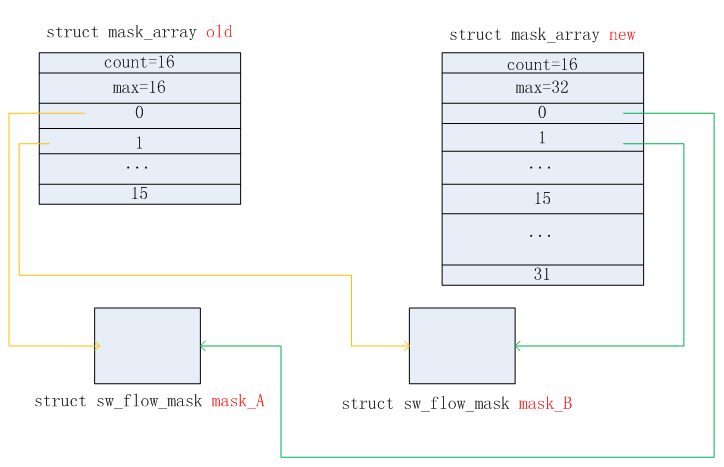
2.9.mask_array扩充
当datapath结构中的table.mask_array->count >= table.mask_array->max时,则需要扩充mask_array空间。已当前table.mask_array->max * 2的大小进行扩充。扩充前后的效果如下图所示。橙色线指向的掩码信息在扩充之后,会释放掉old的掩码信息空间。扩充总是按照当前max数值的2倍大小进行扩充,例如:16 -> 32 -> 64 -> 128 -> …。从源码中暂时未看到这个扩充的最大值。
2.10.table_instance扩充
table_instance扩充有两个条件触发:
1)当datapath结构中的table.count > table.ti->n_buckets时,触发扩充。
2)datapath结构中的table.last_rehash记录了上次执行扩充或初始化table时系统的jiffies值。如果超过10分钟,则需要重新扩充,只是这次的扩充并非增大空间,而是以相同的大小重新分配空间。觉得这样做的意义是重新生成table_instance结构中的hash_seed值,重新安排哈希桶的链表长度,分散存储,减少匹配的比较次数。
我们主要以第一种条件为例,描述扩充的过程。这种扩充是在原有的哈希桶数目(n_buckets)基础之上,以2倍的大小进行扩充。扩充前后,table_instance结构的变化如下图所示。
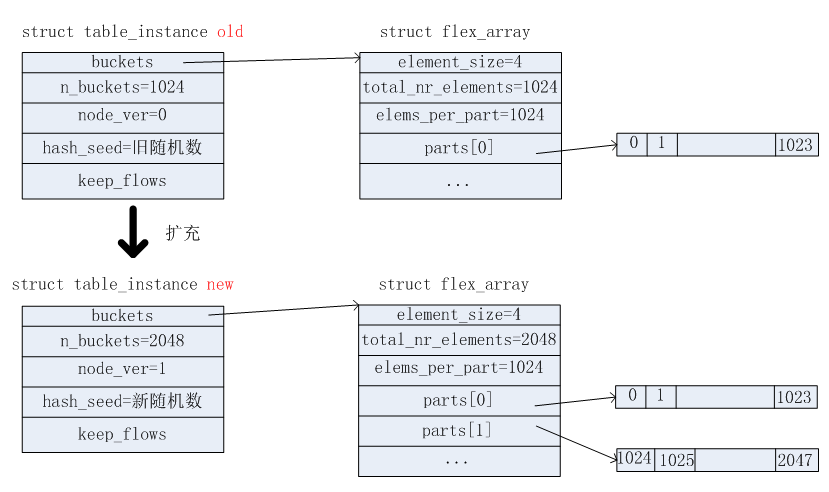
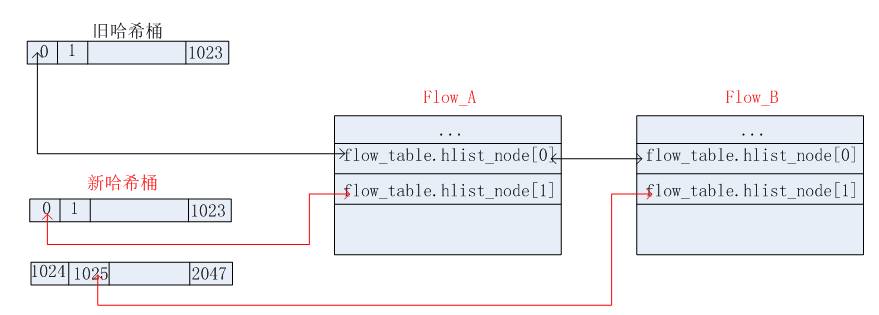
根据上图可知,扩充之后,table_instance中的hash_seed更新为新的随机数了。这样,在从旧的table_instance将哈希桶中对应的各个流信息拷贝到新的table_instance时,需要重新计算哈希桶的位置,重新安排了。这样做的好处时:可以重新分散每个哈希桶中流信息链表的长度,减少在匹配时流的比较次数。如下图所示,之前Flow_A和Flow_B都位于第0个哈希桶,扩充之后,Flow_A处于了第0个哈希桶,而Flow_B则处于第1025个哈希桶了。这样在查找Flow_B的时候,比较的次数就减少了一次。在大规模查找的过程中,这种改变可以大大提高查找的效率。
2.11.示例
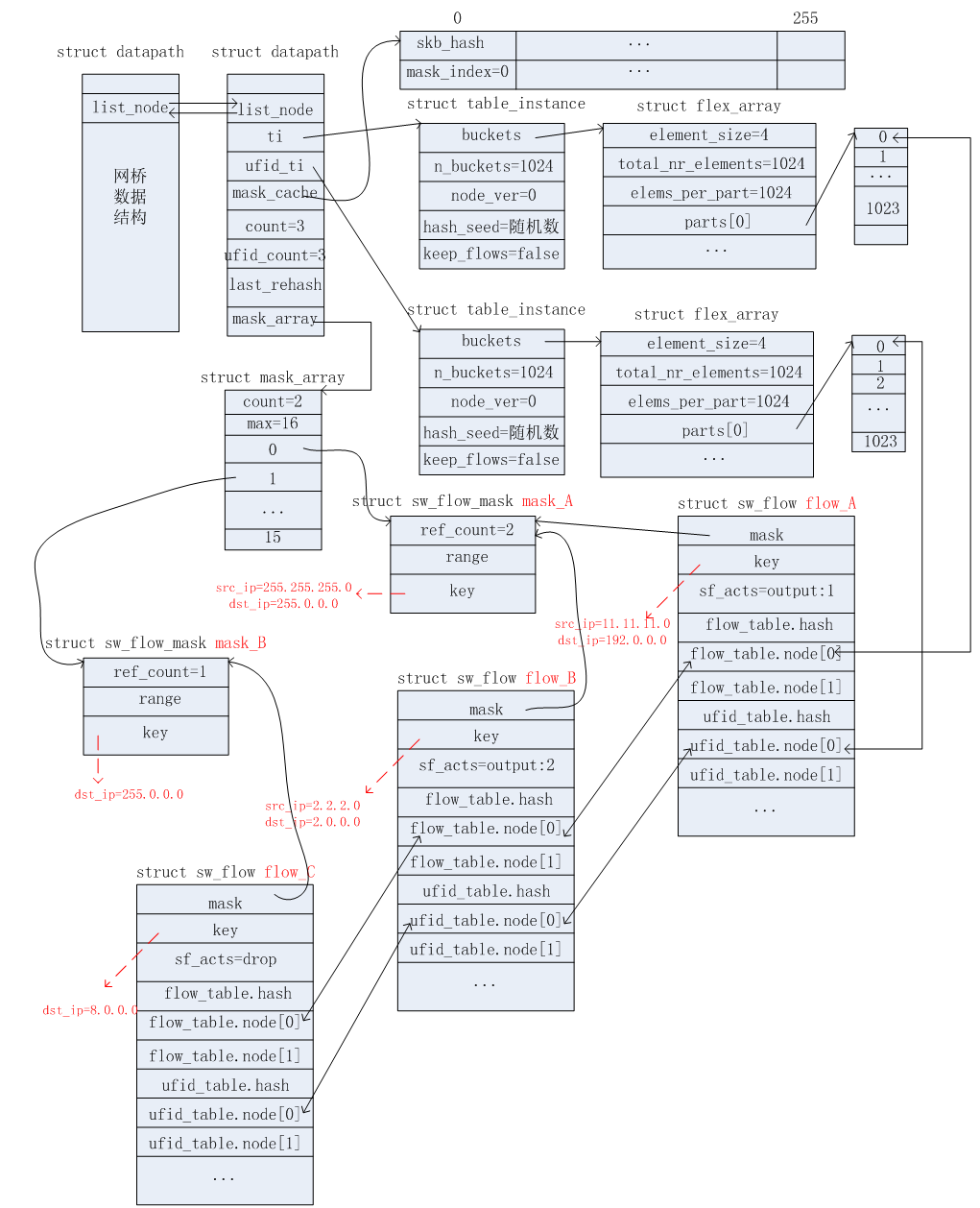
假设ovs用户空间的”慢路径”存储的流表信息如下所示:
初始化的时候,ovs内核空间的”快路径”没有存储任何的流路径信息。如下图所示:
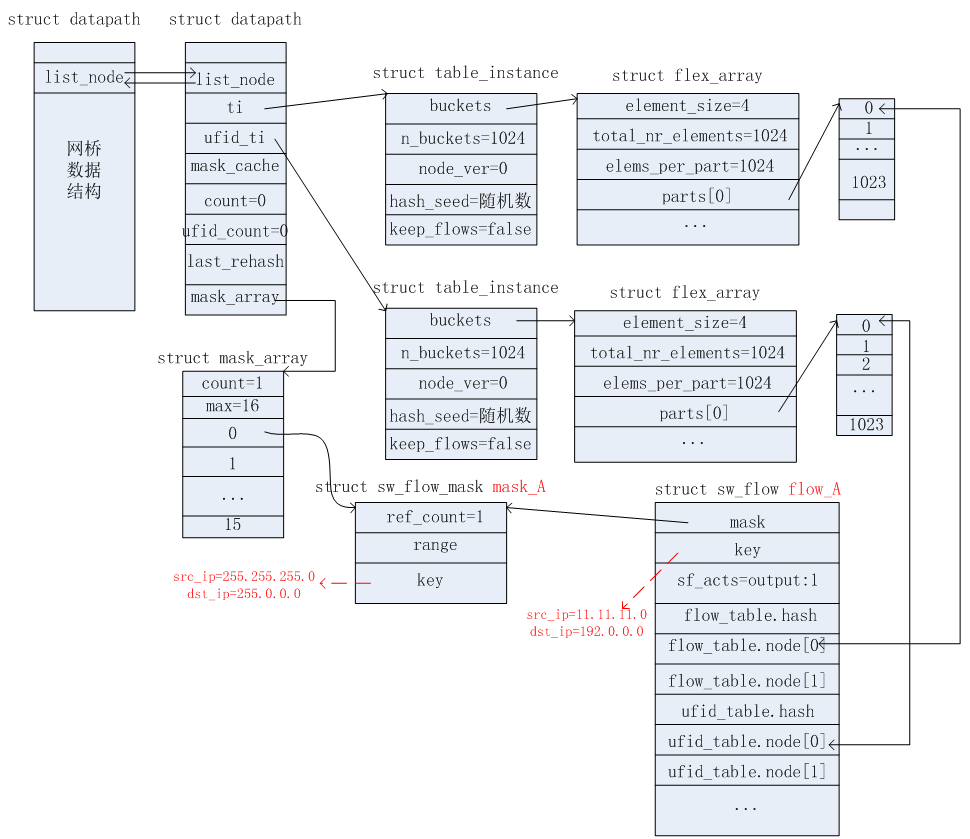
收到第一个报文:src_ip=11.11.11.25, dst_ip=192.1.1.1
收到第一个报文,匹配结果Miss,upcall到用户空间,查表将结果发送回内核空间的datapath。根据上述2.3节所述的更新过程,会新增相应的掩码信息(mask_A)和流信息(flow_A)。如下图所示。
收到第二个报文:src_ip=11.11.11.63, dst_ip=192.168.7.8
根据上述2.4节所述的查找过程,匹配成功。
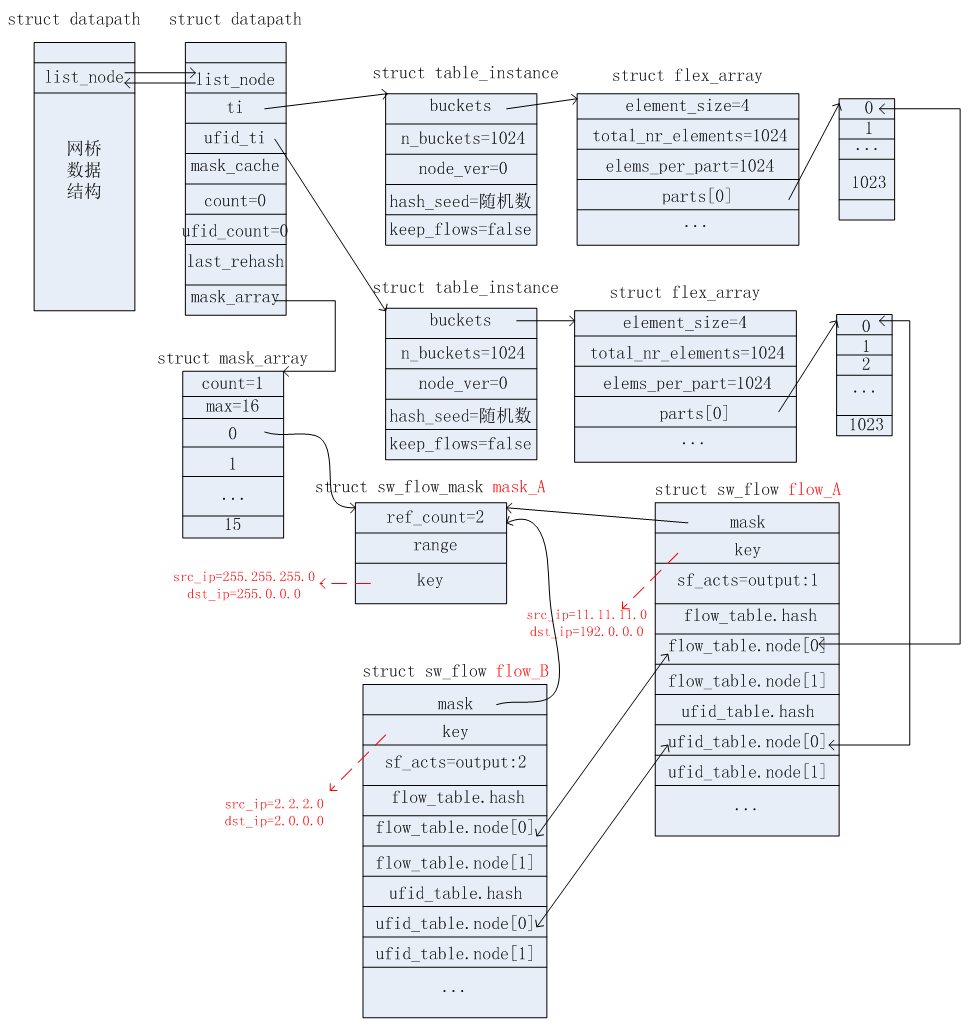
收到第三个报文:src_ip=2.2.2.4, dst_ip=2.7.7.7
根据上述2.4节所述的查找过程,匹配失败。因为掩码信息和mask_A完全相同,因此无需新增掩码信息,只需要将mask_A的ref_count引用计数加1即可。但是需要新增相应的流信息(flow_B),如下图所示。
收到第四个报文:dst_ip=8.12.34.56
根据上述2.4节所述的查找过程,匹配失败。需要新增相应的掩码信息(mask_B)和流信息(flow_C)。如下图所示
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK