

即时配送的ETA问题之亿级样本特征构造实践 -
source link: https://tech.meituan.com/GBDT.html?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

即时配送的ETA问题之亿级样本特征构造实践
ETA(Estimated time of Arrival,预计送达时间)是外卖配送场景中最重要的变量之一(如图1)。 我们对ETA预估的准确度和合理度会对上亿外卖用户的订单体验造成深远影响,这关系到用户的后续行为和留存,是用户后续下单意愿的压舱石。ETA在配送业务架构中也具有重要地位,是配送运单实时调度系统的关键参数。对ETA的准确预估可以提升调度系统的效率,在有限的运力中做到对运单的合理分配。在保障用户体验的同时,对ETA的准确预估也可以帮助线下运营构建有效可行的配送考核指标,保障骑手的体验和收益。

图1. ETA的业务价值
最近几年,ETA在互联网行业中的运用取得了令人瞩目的进展,其中以外卖行业和打车行业最令人关注。但与打车行业相比,ETA在外卖行业中的业务场景更为复杂。如图2所示,从业务要素来看,打车涉及到两方——乘客和司机,而外卖行业则涉及了三方——骑手、商家、用户,这使得问题的处理难度提升了一个量级。从业务的环节来看,打车分为派单、接人、送达三个环节,是一个司机接单到达指定地点接送乘客到达目的地的过程;而外卖则主要分为接单、到店、取餐、送达四个环节,是一个用户、骑手、商家来回交错的场景。业务环节的增加带来了更多的复杂性和不确定性,如骑手操作在各个环节中存在较多的不可控因素,商家可能出餐较慢,此外还有运力规划和天气因素的不确定性等,这就直接导致了外卖ETA采取了端到端(下单到接单)的预估方式,相比于拆分成四个环节单独预估具有更强的容错性。无论从业务所涉及的要素还是从业务环节来看,外卖业务的复杂程度远远高于打车业务,对ETA预估的难度更大。
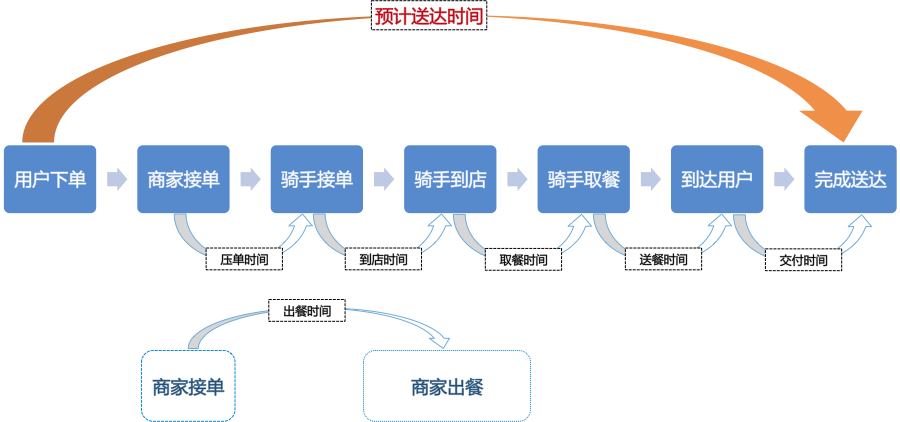
图2. ETA架构图
ETA中比较常用的模型是以GBDT(Gradient Boost Decision Tree,梯度提升决策树)、RF(RandomForest,随机森林)和线性回归为主的回归预测模型。GBDT是利用DT Boosting的思路,通过梯度求解的方式追踪残差,最终达到利用弱分类器(回归器)构造强分类器(回归器)的目的。RF在DT Bagging的基础之上通过加入样本随机和特征随机的方式引入更多的随机性,解决了决策树泛化能力弱的问题。而线性回归作为线性模型,很容易并行化,处理上亿条训练样本不是问题。但线性模型学习能力有限,需要大量特征工程预先分析出有效的特征、特征组合,从而去间接增强线性回归的线性学习能力。
在回归模型中,特征组合非常重要,但只依靠业务理解和人工经验不一定能带来效果提升,这导致在实际应用中存在特征匮乏的问题。所以如何发现、构造、组合有效特征,并弥补人工经验的不足,成了ETA中重要的一环。
Facebook 2014年的文章介绍了通过GBDT解决LR的特征组合问题。[1]GBDT思想对于发现多种有区分性的特征和组合特征具有天然优势,可以用来构造新的组合特征。在Facebook的文章中,会基于样本在GBDT中的输出节点索引位置构造0-1特征,实现特征的丰富化。新构造的0-1特征中,每一个特征对应样本在每棵树中可能的输出位置,它们代表着某些特征的某种逻辑组合。例如一棵树有n个叶子节点,当样本在第k个叶子节点输出时,则第k个特征输出1,其余n-1个特征输出0,如图3所示。
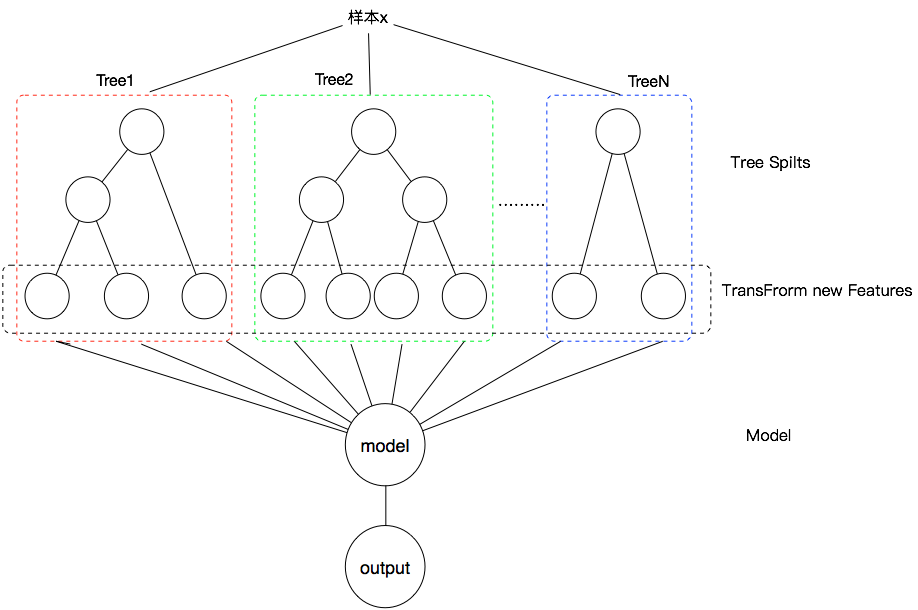
图3. GBDT(Gradient Boost Decision Tree)特征构造方法
至于构造新特征的规模,需要由具体业务规模而决定。当GBDT中树的数量较多或树深较深时,构造的特征规模也会大幅增加;当业务中所用的数据规模较小时,大规模的构造新特征会导致后续训练模型存在过拟合的可能。所以构造特征的规模需要足够合理。
在ETA场景中,由于业务场景复杂,所以特征的丰富性决定了ETA最终效果的上限。在目前所拥有的特征中,在特征工程的基础阶段,我们依靠业务理解、人工分析和经验总结来构造特征。但从特征层面来看仍然存在欠缺,需要让特征更加丰富化,深度挖掘特征之间的潜在价值。
基础特征构建

图4. 基础特征构成
特征作为ETA中的重要部分,决定了ETA的上限。我们基于人工经验和业务理解构建了不同的离线特征和在线特征。
(1) 离线特征
a. 商户画像:商户平均送达时长、到店时长、取餐时长、出餐状况、单量、种类偏好、客单价、平均配送距离。
b. 配送区域画像:区域运力平均水平、骑手规模、单量规模、平均配送距离。
(2) 在线特征
a. 商家实时特征:商家订单挤压状况、过去N分钟出单量、过去N分钟进单量。 b. 区域实时特征:在岗骑手实时规模、区域挤压(未取餐)单量、运力负载状况。 c. 订单特征:配送距离、价格、种类、时段。 d. 天气数据:温度、气压、降水量。
其中区域实时特征和商家实时特征与配送运力息息相关,运力是决定配送时长和用户体验的重要因素。
GBDT模型训练和特征构造
利用基础特征,训练用于构造新特征的GBDT模型。在GBDT中,我们每次训练一个CART(Classification And Regression Trees)回归树,基于当前轮次CART树的损失函数的逆向梯度,拟合下一个CART树,直到满足要求为止。
(1) 超参数选择
a. 首先为了节点分裂时质量和随机性,分裂时所使用的最大特征数目为 √n。
b. GBDT迭代次数(树的数量)。
* 树的数量决定了后续构造特征的规模,与学习速率相互对应。通常学习速率设置较小,但如果过小,会导致迭代次数大幅增加,使得新构造的特征规模过大。
* 通过GridSearch+CrossValidation可以寻找到最合适的迭代次数+学习速率的超参组合。
c. GBDT树深度需要足够合理,通常在4~6较为合适。
* 虽然增加树的数量和深度都可以增加新构造的特征规模。但树深度过大,会造成模型过拟合以及导致新构造特征过于稀疏。
(2) 训练方案
将训练数据随机抽样50%,一分为二。前50%用于训练GBDT模型,后50%的数据在通过GBDT输出样本在每棵树中输出的叶子节点索引位置,并记录存储,用于后续的新特征的构造和编码,以及后续模型的训练。如样本x通过GBDT输出后得到的形式如下:x → [25,20,22,….,30,28] ,列表中表示样本在GBDT每个树中输出的叶子节点索引位置。
OneHotEncoder(新特征热编码)
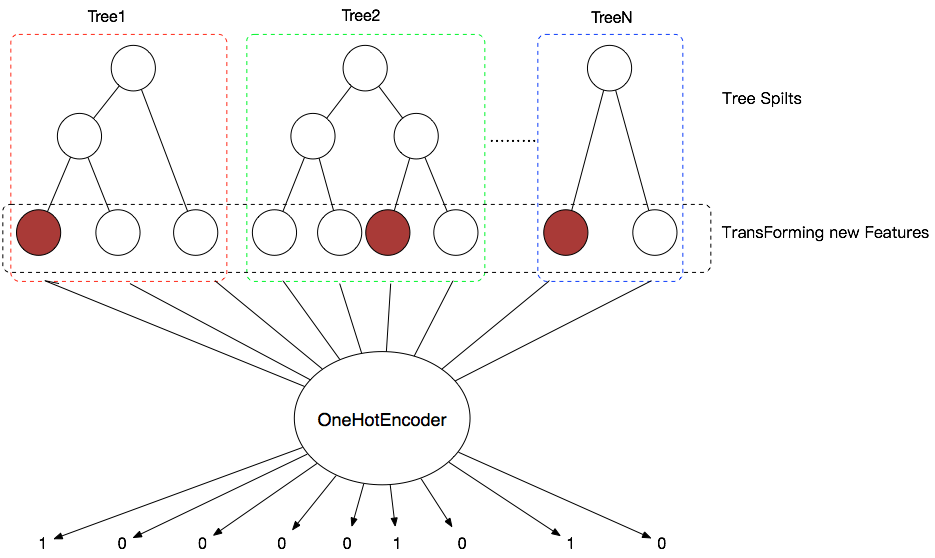
图5. OneHotEncoder(新特征热编码)使用方法
由于样本经过GBDT输出后得到的x → [25,20,22,….,30,28] 是一组新特征,但由于这组新特征是叶子节点的ID,其值不能直接表达任何信息,故不能直接用于ETA场景的预估。为了解决上述的问题,避免训练过程中无用信息对模型产生的负面影响,需要通过独热码(OneHotEncoder)的编码方式对新特征进行处理,将新特征转化为可用的0-1的特征。
以图5中的第一棵树和第二棵树为例,第一棵树共有三个叶子节点,样本会在三个叶子节点的其中之一输出。所以样本在该棵树有会有可能输出三个不同分类的值,需要由3个bit值来表达样本在该树中输出的含义。图中样本在第一棵树的第一个叶子节点输出,独热码表示为{100};而第二棵树有四个叶子节点,且样本在第三个叶子节点输出,则表示为{0010}。将样本在每棵树的独热码拼接起来,表示为{1000010},即通过两棵CART树构造了7个特征,构造特征的规模与GBDT中CART树的叶子节点规模直接相关。
基于独热码编码新特征完成后,加上原来的基础特征,特征规模达到1000+以上,实现特征丰富化。
与传统的回归问题不同,ETA与实际业务深度耦合,所以需要基于业务因素考虑更多的评估指标,以满足各端(C端、R端)用户利益。
① N分钟准确率:订单实际送达时长与预估时长的绝对误差在N分钟内的概率。
业务含义:
- 在N分钟准确率中,N的判定方法来源于绝对误差与用户满意度的关系曲线。通常绝对误差在一定范围内,用户满意度不会有明显波动。如果发现当误差大于K分钟时,用户满意度出现明显下滑,则可以将K做为N分钟准确率中N的取值依据。
- 预估时长等同于平台提供给C端用户对送餐快慢的心理预期,如果N分钟准确率越高,证明预估时长愈发接近用户的心理预期,表示C端用户体验越好。
计算方法:
- Xi:样本i的绝对误差=abs(实际送达时长-预估时长)。
- 计算每个样本的误差的是否在N分钟内,并统计概率P(Xi <= N),如图6、图7所示。
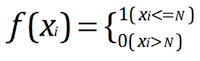
图6.判定订单预估是否准确的计算方法
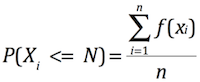
图7.N分钟准确率计算方法
② N分钟业务准时率:实际送达时长与预估时长的差值在N分钟内的概率。 1. 业务含义: * N分钟业务准时率中N的判定方法与N分钟准确率类似。 * N分钟业务准时率是一种合理考核骑手以及保障骑手绩效收益的指标。ETA场景与其它回归场景相比,在预估准确的同时,预估合理性同样很重要。N分钟准确率虽然有效地量化C端用户体验指标,但无法衡量R端骑手体验。所以N分钟业务准时率是一个很好的补充指标。 2. 计算方法: * Xi,样本i的有偏差值=(实际送达时长-预估时长)。 * 若Xi < 0 ,表示骑手提前送达,等同于业务准时。 * 若0 < Xi <= N , 表示骑手在超时N分钟内送达,等同于业务准时;但如果Xi > N ,表示骑手超时N分钟以上送达,从指标层面看,该订单骑手配送业务超时。 * 统计订单配送不超时的概率P(Xi <= N),计算方法与N分钟准确率(图7)类似。
实践效果对比
我们在此之前已经做了很多特征工程和优化方面的工作,本次我们在不增加任何额外特征的情况下,仅通过模型架构的变化进行优化。在对全量订单进行评估对比的同时,我们对一些高价值和午高峰期间的订单进行重点评估。
① 高价值订单:高价值订单仅占全量订单的5%。这部分订单用户满意度较低、配送体验较差,属于长尾订单范畴,优化难度高于其它类型订单。 ② 午高峰订单:午高峰运单业务占比高达40%。午高峰期间,商家存在堂食和外卖资源争抢问题,造成出餐时间不稳定,导致业务中存在更多不确定性,预估难度明显大于非高峰期。
将GBDT构造特征+Ridge与老版本base model(GBDT)进行对比。从结果上来看,构造新特征后,可以对ETA预估带来更好的效果,其中在高价值订单中,骑手的N分钟业务准时率提升显著。具体结论如下:
① 全量订单 平均偏差(MAE)减少了3.4%,误差率减少1.7个百分点,N分钟准确率提升2.2个百分点,N分钟业务准时率持平。 ② 高价值订单 平均偏差(MAE)减少了2.56%,误差率减少1个百分点,N分钟准确率提升1.6个百分点,N分钟业务准时率提升3.46个百分点。 ③ 午高峰订单 平均偏差(MAE)减少了3.1%,误差率减少1.4个百分点,N分钟准确率提升1.7个百分点,N分钟业务准时率持平。
从上述效果来看,GBDT构造特征可以给ETA场景带来更多的提升,在线上使用时,也需要在性能和构造特征的规模上做出取舍。考虑到骑手的主观能动性等因素,通常上线后,线上效果比线下试验效果要更加乐观。
ETA 作为是外卖配送场景中最重要变量之一,是一个复杂程度较高的机器学习问题,其特征的丰富性决定了ETA的上限。在业务特征相对匮乏的情况下,GBDT+OneHotEncoder可以实现特征的丰富化,深度挖掘出特征的潜在价值。实验结果显示,在特征丰富化的情况下,ETA的准确度明显提高。
与此同时,我们也在尝试进行更多的探索。我们认为时序关系也是ETA场景的重要特征,并尝试将该关系特征化加入到目前的模型和策略中,改善特征质量,提高ETA的预估能力上限。同时引入深度学习和增强学习,在提高上限的同时,用更好的模型去接近这个新的预估上限,为ETA的场景提升打下坚实的基础。
[1] He X, Pan J, Jin O, et al. Practical Lessons from Predicting Clicks on Ads at Facebook[C]. Proceedings of 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2014: 1-9. [2] https://www.csie.ntu.edu.tw/~r01922136/kaggle-2014-criteo.pdf. [3] GitHub,guestwalk.
美团外卖配送策略组长期招聘机器学习领域有识之士。come on,快到我碗里来!简历发送至邮箱:gaojiuchong#meituan.com
</div
Recommend
-
15
CVE2015-0057漏洞样本构造探索 cssembly
-
64
近来即时配送迎来新一轮投资高潮—8 月9日,达达-京东到家宣布完成最新一轮5亿美元融资,投资方分别是京东与沃尔玛;8月6日,UU跑腿获东方汇富·...
-
77
本文订单分配问题为例,阐述该问题的本质特点、模式变迁、方案架构和关键要点,为大家在解决业务优化问题上提供一个案例参考。 最近两年,外卖的市场规模持续以超常速度发展。近期美团外卖订单量峰值达到1600万,是全球规模最大的外卖平台。目前各外卖平台正在优质...
-
51
唆麻 • 2019-05-19 09:05 与其说是巨头纷纷扎堆即时配送,不如说是借此机会进一步稳固业务根基,形成“基础设施级”的业务板块,在行业整体转向 B...
-
64
7月25日消息,即时配送服务商“快先森”宣布已于今年7月完成数千万元的Pre-A轮融资,由梅花创投领投,英诺天使跟投。本轮融资将用于公司市场拓展、团队扩充、新零售基础设施以及“城市前置仓”的全方位打造,并向更多的省会城市进驻。 据了...
-
39
快递只分两种,顺丰和其他快递。在快递领域,顺丰已经凭借优质的服务和高效成为标杆,它也开始将目光投向普通快递以外的物流市场,10 月 24 日,顺丰在深圳举行发布会,宣布成立新公司「顺丰同城急送」,后者在品牌和业务上均独立运营。
-
33
编者按:本文来自微信公众号
-
39
原标题:即时配送:巨头厮杀正酣 作者:杨俏 核心观点 1、即时配送市场格局经过多重并购与整合后,呈现出美团、蜂...
-
2
Foundation Medicine 42万例样本库分析KRAS泛癌种突变特征得出了这些结论 ...
-
7
回归元学习,基于变分特征聚合的少样本目标检测实现新SOTA 作者:机器学习 2023-02-07 14:10:19 腾讯优图实验室联合武汉大学提出了基于变分特征聚合的少样本目标检测模型 VFA,大幅刷新了 FSOD 指标。本工作已入选...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK