

不可思议!亿级数据竟然如此轻松同步至ES!
source link: https://www.51cto.com/article/785426.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
1 这是一个背景
最近接了一个需求,要提供一个随意组合多个条件来查询订单数据的功能,看着数据库里过亿的订单量,头发不争气的又脱落了两根代表这个需求不简单。
 图片
图片
脱落的两根头发,不是技术实现上很难,其实技术实现上清晰明了,就是通过数据异构,将数据同步到ES,利用ES的倒排索引、缓存等能力,提供多条件复杂查询的能力,而ES集群我们已经有了。
但有些数据,在目前的ES索引中是不存在的,也就是说,我需要将过亿的订单数据从订单数据库重新刷一遍到ES中,而这一顿操作下来得需要一周的时间!
什么?你不信,那咱们来捋一捋。
2 捋一捋订单数据同步到ES中的复杂度
2.1 数据同步ES索引流程
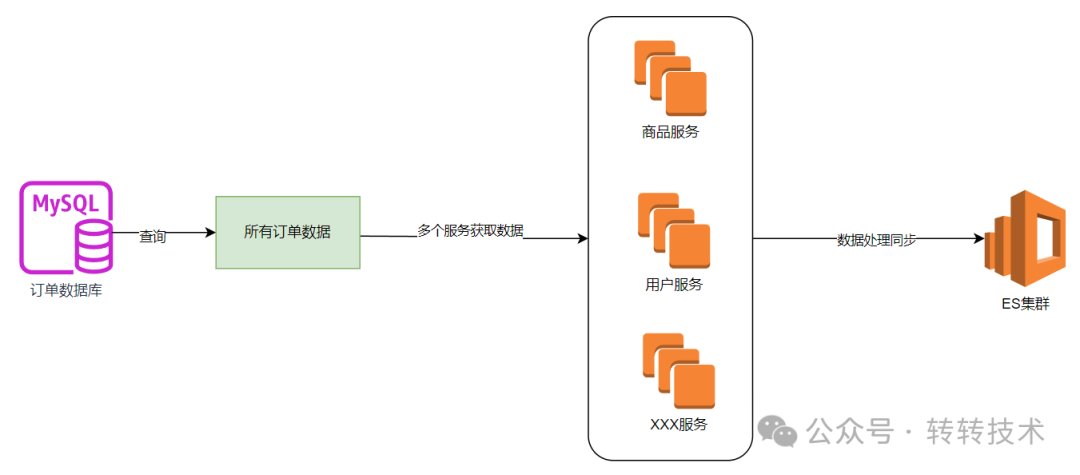
图片
如上图所示,就是将数据同步到ES索引的过程。
首先需要从订单数据库查询所有的订单数据,然后根据订单数据上保存的用户ID,商品ID等信息从用户服务,商品服务查询相关信息,经过处理与组装后落到ES集群中。
之所以要查询用户信息和商品信息,是因为异构在ES索引中的订单数据,并不会与mysql中的数据一一对应,有很多根据商品类目,用户信息等查询订单信息的诉求存在,因此在这里就需要查询很多的上游服务来组装信息。
2.2 来梳理下是否有难点?
- 从数据库把上亿的订单数据读取出来。这个操作不能影响到线上业务,因此查询的订单数据库一般是从库,OK,配置多数据源来读取数据吧,而且上亿的订单一般采用的都是分库分表来存储的,我们是分了16个库,每个库16个表,总共256张表,嘿嘿。
- 上亿的订单数据不能一次性全部读取到内存吧,不然内存冒烟都存不下啊。所以得考虑分页,分页直接limit也不好,随着数据量越大,速度越慢,所以得考虑一个游标,嗯,选一个字段当游标吧,游标最好唯一且递增。
- 从多个服务获取数据,这些数据所在的服务一般都属于公司的其它部门,读取数据的时候也不能影响到人家的服务吧,你这里查询的是嘎嘎猛,一看人家的服务都崩了,这个黑锅就飞来了。所以这里得考虑限流吧,得考虑隔离吧?不说全链路隔离,成本太高,起码关键服务得隔离一下。
- 数据同步一段时间,产品来问,同步多久了啊,大概还有多久能完成啊,数据量大概是多少啊,一脸懵,不知道啊。
- 如果中途同步失败了,咋处理啊,是不是得重试,咋重试,重试策略是啥?失败有没有报警,能不能及时感知并处理啊?如果同步一段时间中断了咋整啊?有没有记录从哪中断的?能否从中断处继续同步啊,不然从头开始又得N天,哭了。
- 同步了一部分,发现有问题需要暂停一会,咋整?
- 如果只想同步部分数据不一致的订单数据,可能就2,3个订单,咋整,是不是还得提供按照手动输入订单ID同步ES数据的能力?
- 同步过程是咋样的?开始时间?结束时间?共耗时多久?操作人是谁?这些统计数据从哪来?
- 想夜深人静的时候同步数据,这有时候对业务的影响小,定个闹钟晚上起?
- 现在不单需要同步订单的数据了,还需要同步商品ES集群的数据,这些逻辑还得重新写一遍?
啊啊啊啊,想想都头疼啊!
所以,一些事情看着简单,其实并没有那么简单。
3 神奇的服务
为了让头发更有归属感,针对上述的难点开发了一款神奇的服务,那就是ECP。它可以将整个流程自动化、可视化的处理,降低数据异构到ES的成本任务界面如下所示:
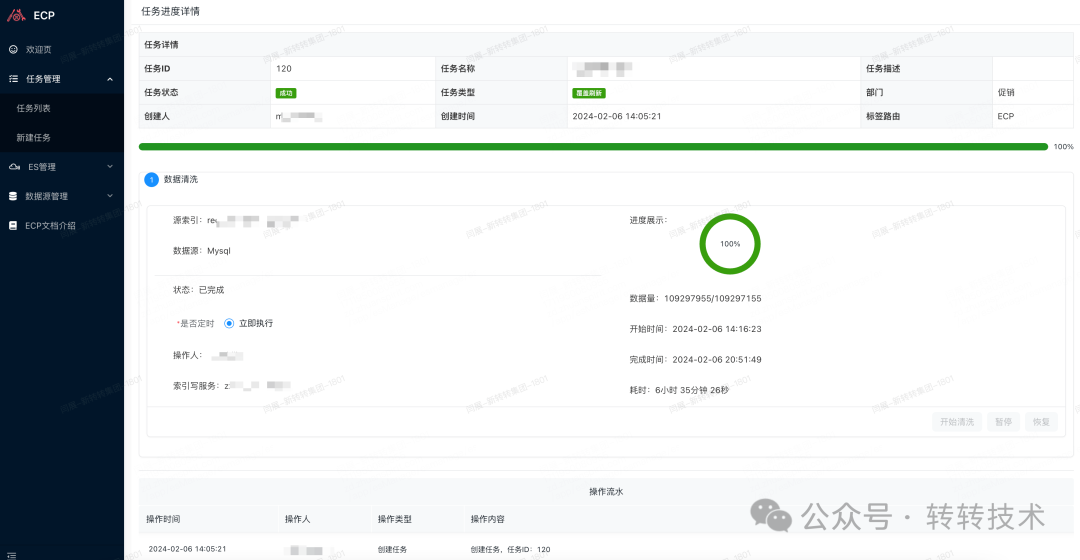
图片
3.1 ECP的简单运行流程
简单来说,ECP的作用就是将数据从数据源读取出来,然后推送给ES写服务。因为数据处理的逻辑因不同的业务而异,ES写服务由各个对接方来实现,因此一个简单的流程如下图:

图片
这里面涉及到一些技术细节,比如如何进行多数据源数据读取,数据源配置,sql校验,动态限流、SPI机制、重试策略与故障感知、探活与故障恢复,环境隔离等等。
下面一一介绍下:
3.2 多数据源数据读取
ECP支持目前支持三个数据源数据的读取,分别为ID源,文本源、以及脚本源。
3.2.1 ID源
有个文本框用来输入ID。这种场景适用于小数据的数据同步,比如发现一些数据库和ES的数据不一致了,就简单的刷一下数据。
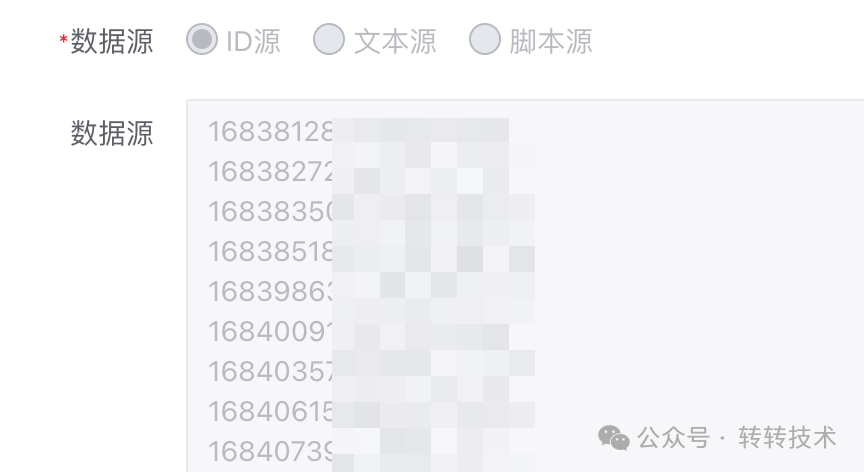
图片
3.2.2 文件源
文件源指的是数据源来源于文本文件,适合中等数据的同步。ECP和对象存储进行了对接,用户可以上传文件至对象存储,在任务执行时,ECP会读取对象存储中的文本数据。
这种情况需要注意的是,用户上传的文件有可能会比较大,直接都读取到内存再处理不现实,因此这里采用的是流的方式进行读取,读取一批处理一批,再释放一批,不会造成OOM。

图片
简化的处理方式如下:
try (Response response = OK_HTTP_CLIENT.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("Unexpected code " + response);
}
// 以流的方式读取文件数据
InputStream inputStream = response.body().byteStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
}3.2.3 脚本源
脚本源适用于大数据量的数据同步。
脚本本质上就是SQL和数据源的结合。
用户在ECP中配置数据库的连接信息,然后配置SQL。ECP会执行该SQL,将数据从配置的数据库中读取出来,推送到ES写服务中。
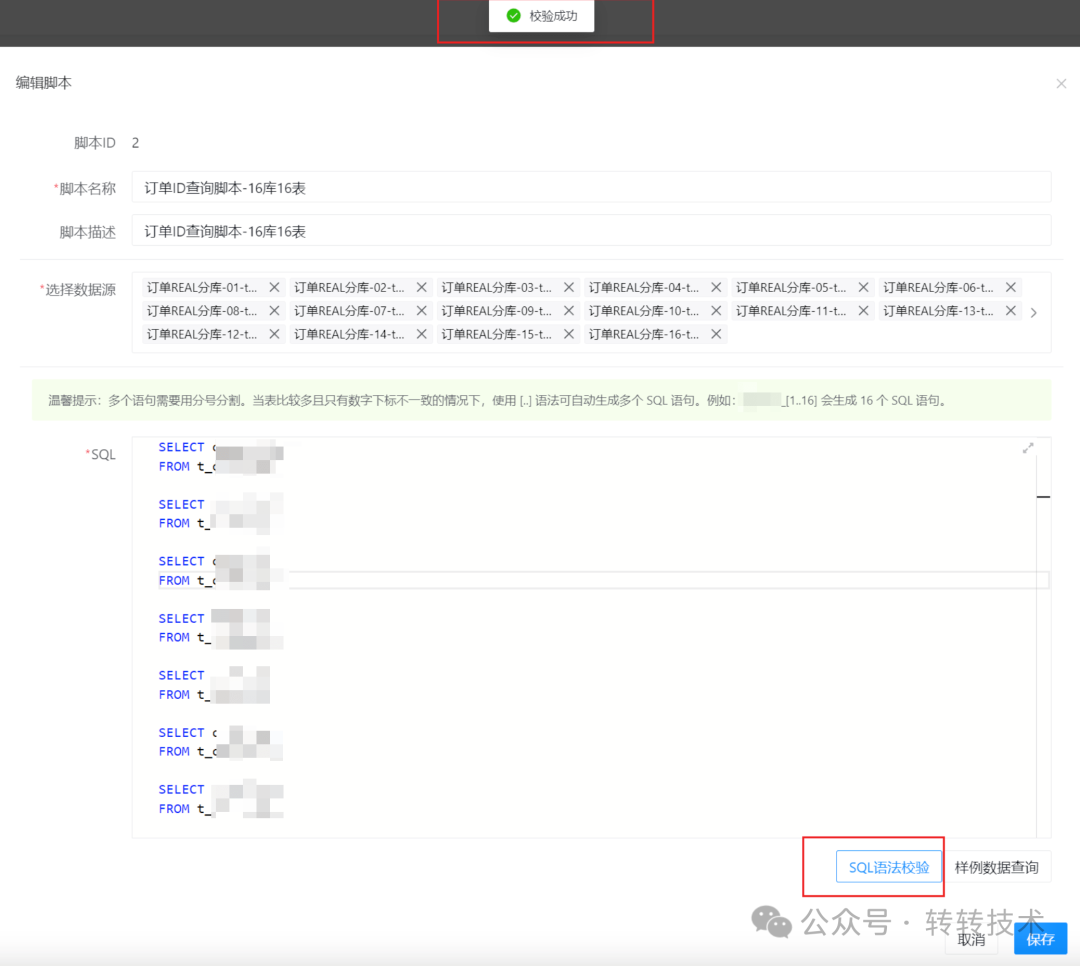
脚本源可以支持上亿数据的读取与推送,如下图为订单库(分库分表)配置的脚本信息:
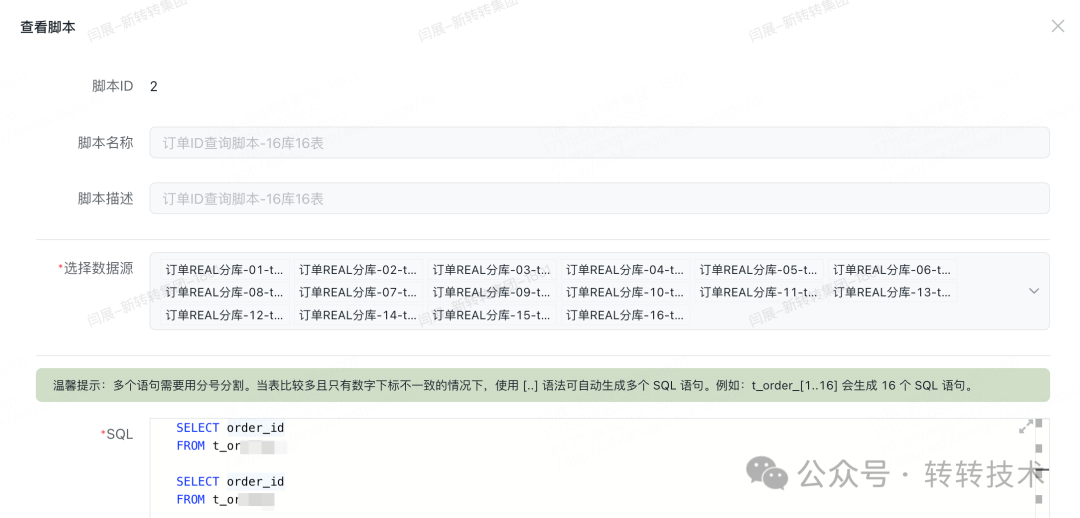
图片
3.2.4 脚本源大数据读取的实现
将几亿数据读取到内存中来处理显然不可能,因此采用局部数据的读取与处理才是正道。
在业务中,经常使用的是分页,但分页如果仅是使用limit offset,size,待offset的值比较大时,性能会急剧下降,形成慢SQL,甚至拖累整个数据库的性能。
因此在分页数量比较大时,需要指定一个有索引的字段作为游标,该游标可以提高分页的性能,如在订单表中,若在订单ID是递增的且有设置了索引,SQL就可以这么写:select * from t_order where order_id > xxx order by order_id desc limit 10; 利用order_id值的变化就可以起到分页的效果。
这种方式虽好,但让用户选定游标索引无疑增加了使用的门槛,因此ECP没有采用上述分页的形式来读取大数据,而是采用JDBC游标查询的方式,如下所示:
// 建立连接
conn = DriverManager.getConnection(url, param.getDsUsername(), param.getDsPassword());
// 创建查询
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY, java.sql.ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(param.getFetchSize());游标查询每次读取fetchSize大小的数据量,可以很好的避免读取大数据量导致的OOM问题。
3.3 SQL的解析与校验
用户配置SQL脚本,ECP需要对该SQL脚本进行校验与修改,传统的字符串处理(比如正则)虽然在一定情况下可以满足需求,但是容易出错。因此ECP采用的是Druid的SQL解析工具包,可以将SQL解析成AST语法树,以便对SQL进行各种处理。如下图所示:
图片
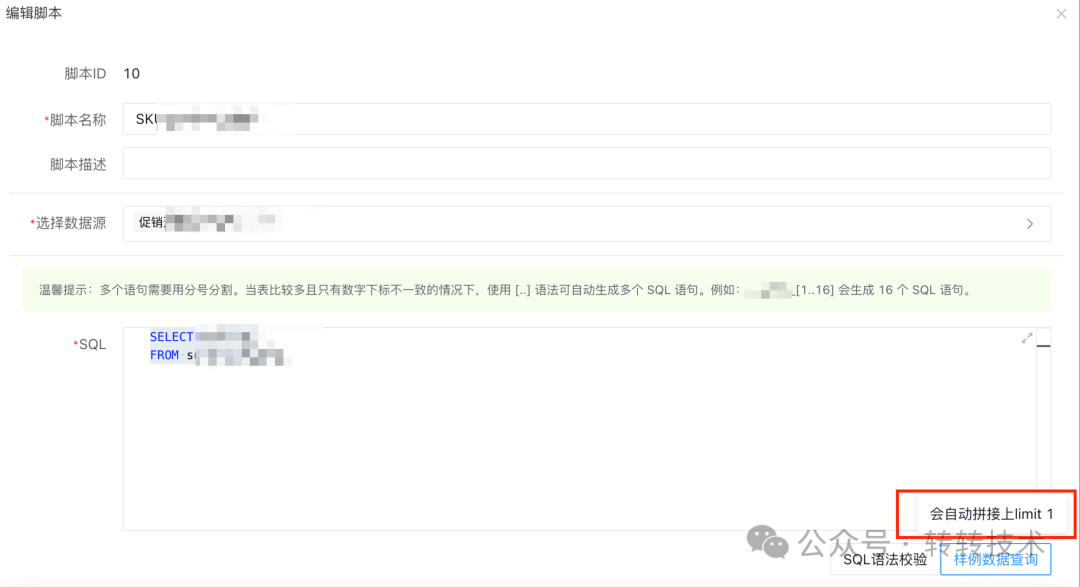
ECP提供的数据样例查询,会对SQL自动拼接上limit 1。
图片

图片
3.4 动态限流的实现
限流分集群限流和单机限流,经过评估,在能简单就简单的原则下,我们采用的是单机限流,限流组件使用的是guava的RateLimiter。
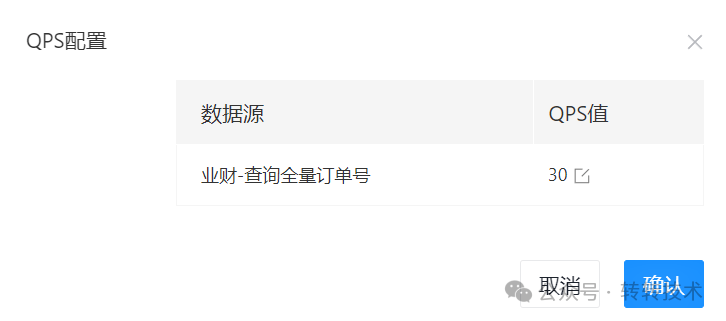
图片
当在页面上修改QPS的值时,会将该值同步到数据库中,有个调度任务会不断地扫描该值的变动,将变动的值同步到RateLimiter组件中。
当然,也可以采用数据监听的策略(比如广播MQ),让变动值同步到RateLimiter更及时,但这种方式还需引入其它组件,复杂度嗷嗷上升,不符合我们简单实现的策略。
动态限流的实现流程如下:
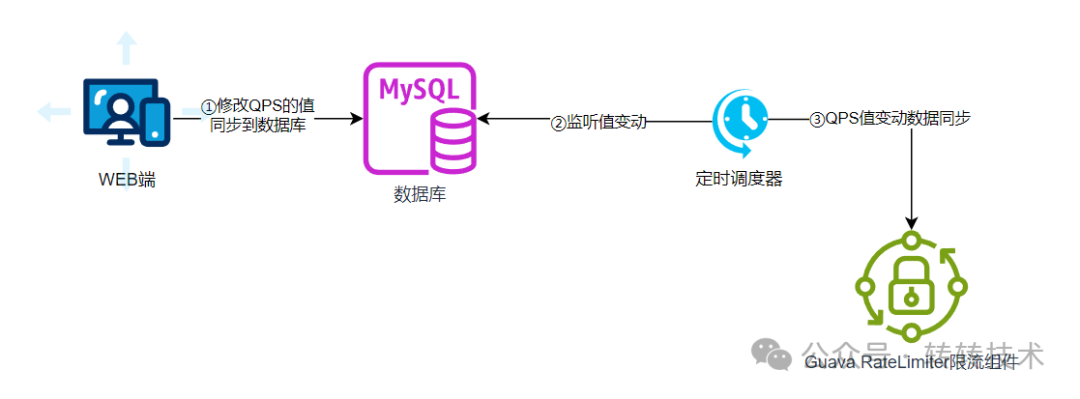
图片
如下图是在不同的时间点修改了限流值后的QPS变化图:
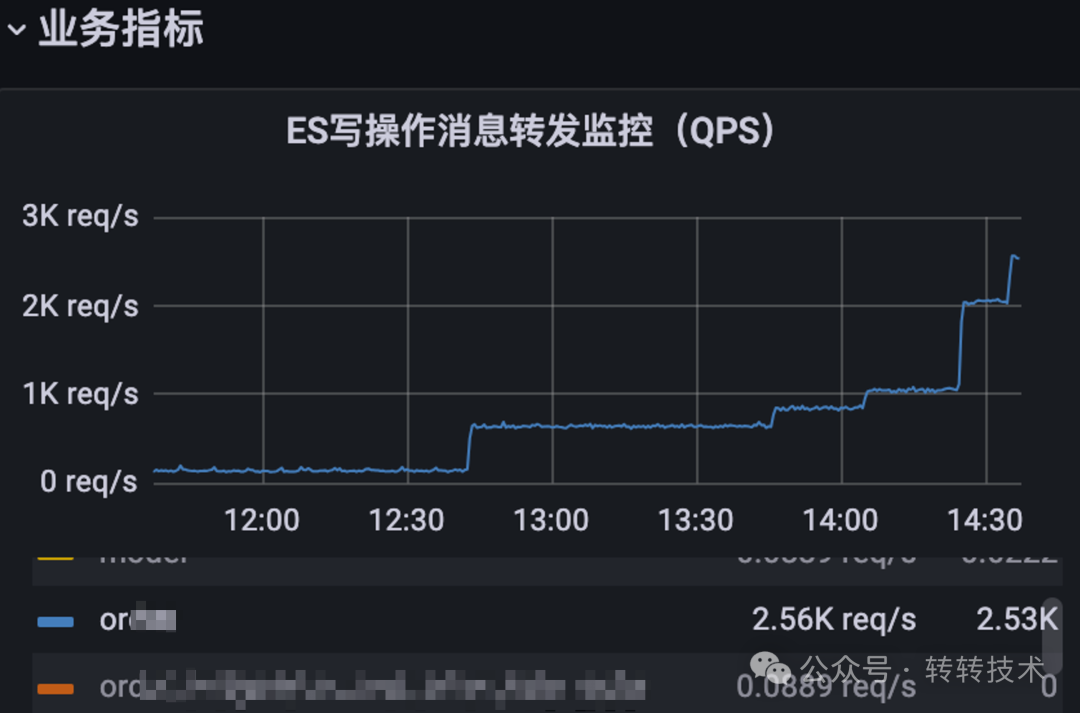
图片
3.5 重试策略与故障感知
ES中和DB中的数据要尽可能的保证实时一致性,但最终一致性是必须要保证的,所以数据推送、处理失败的时候要进行重试,如何重试?
首先需要了解下失败的类型,制定合适的重试策略,知彼知己,百战不殆嘛!
一、网络抖动导致的接口调用超时。在调用微服务RPC接口的时候,由于网络抖动等情况,会导致接口调用超时,但很快就会恢复,通常情况下也就偶尔一次,下一次调用就会正常。
二、数据处理逻辑异常。这种情况下,异常没办法自恢复,只能人工介入。
三、上游服务异常。如上游服务压力过大导致接口调用失败,这时候就需要我们缓一缓再继续处理,不能一个劲的调用导致上游服务崩溃掉。
结合上面的失败类型的特点,斐波那契数列的重试策略就非常适合 斐波那契数列的特点是:1,1,2,3,5,8,13,21,34,55,89…
当第一次失败的时候,延时1秒后就重试,如果此时是网络抖动导致的超时,重试就成功了,不影响数据处理的速度 若失败的次数越多,重试的间隔时间就会越长,这也会兼顾到上述二、三的失败类型。
重试组件使用的是Guava Retry,简单的伪代码如下:
// 重试组件配置
private final Retryer<Boolean> RETRYER = RetryerBuilder.<Boolean>newBuilder()
// 对中断类的异常不重试
.retryIfException(input -> !isPauseException(input))
// 1,1,2,3,5,8,13,21,33...
.withWaitStrategy(WaitStrategies.fibonacciWait(1000, 30, TimeUnit.SECONDS))
// 重试次数达到一定的次数后,不再重试
.withStopStrategy(StopStrategies.stopAfterAttempt(MAX_RETRY_TIMES))
.withRetryListener(new RetryListener() {
@Override
public <V> void onRetry(Attempt<V> attempt) {
if (attempt.hasException()) {
log.error("act=【DataFlushRpcCallRetry】desc=【重试】重试次数=【{}】重试异常=【{}】", attempt.getAttemptNumber(), attempt.getExceptionCause());
// 重试超过阈值进行报警提醒
alarmIfExceedThreshold(attempt);
}
}
})
.build();
// 将执行逻辑抽象为Runnable,对外暴露该方法
public void execute(Runnable runnable) {
innerExecute(runnable,RETRYER);
}
private void innerExecute(Runnable runnable, Retryer<Boolean> retryer) {
try {
retryer.call(() -> {
runnable.run();
return true;
});
} catch (Exception e) {
log.error("act=【DataFlushRpcCallRetry】desc=【重试异常】error=【{}】", e);
throw new IllegalStateException(e);
}
}若重试到一定次数之后依然是失败的话,则会将错误信息发送到报警群。根据推送的信息,可以明确知道错误的类型,重试的次数,以及任务的创建人等等信息,无需查看日志,即可定位大部分的问题。如下图:
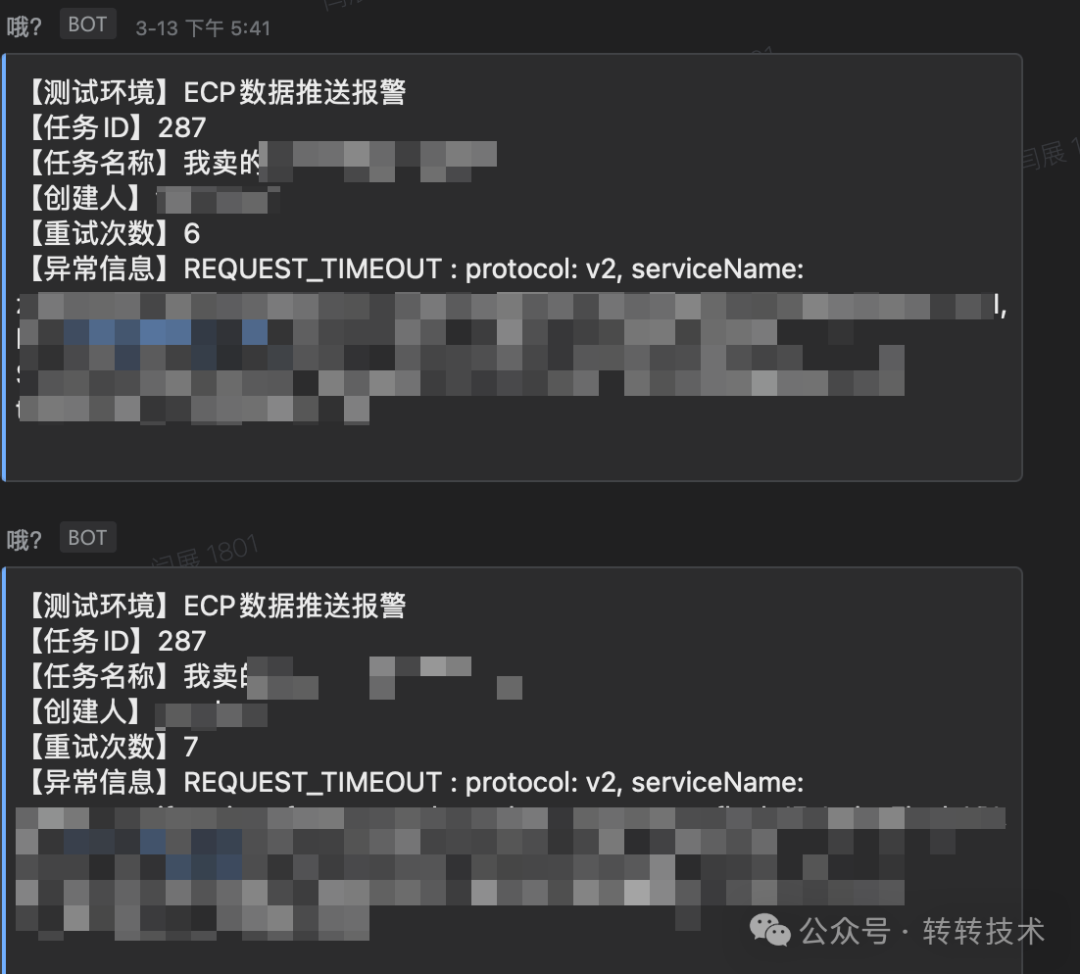
图片
3.6 将数据推送给哪个服务来处理?-SPI机制
ECP是个通用的服务,因此需要将共性功能收拢在一起做成成品,将非共性的功能抽象一下,交给各个对接方去实现。
从简单实现的角度来看,若有某个服务想要对接ECP,我们在ECP上开发一下,调用该服务的接口,将数据推送给该服务,思路虽清晰明了,但对接及维护成本极高,且没有一个统一的规范,因此不可取,其流程如下图:
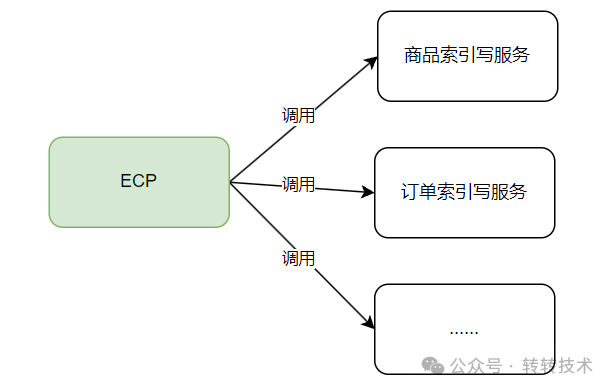
图片
Java上有个很好的思想可以解决这个问题,那就是SPI。因此由ECP提供一个接口,制定一个规范,具体的ES索引数据的组装逻辑由各个对接方去实现。
这样,若有一个新的对接方接入,只要实现接口即可,ECP无需做任何改动。
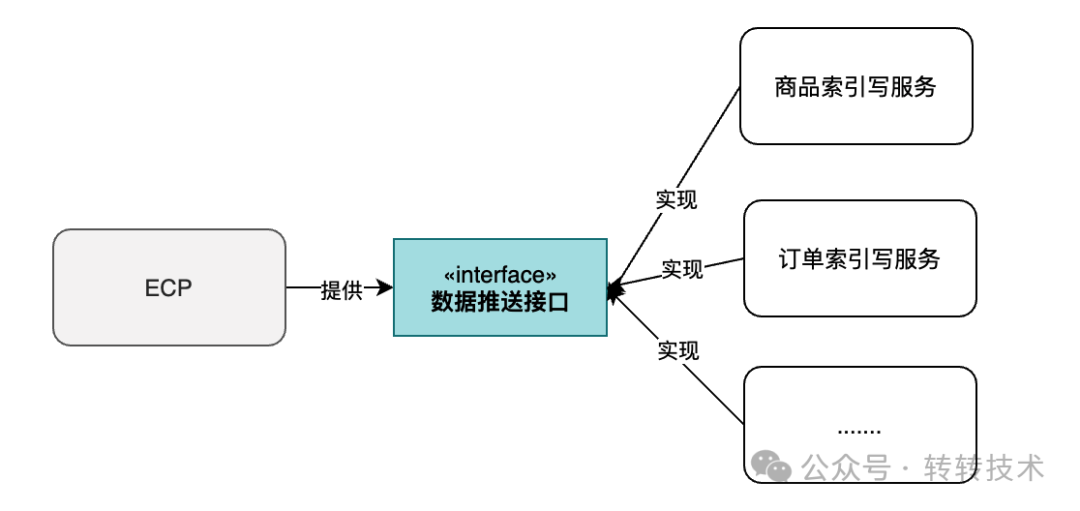
图片
至于服务发现,ECP采用的配置的方式,也就是在新建任务的时候,选择数据推送的消费方服务,如下图:
图片
对于实现方式,得益于公司内部自研的RPC框架,提供了动态指定调用服务的方式,伪代码如下:
Reference<IEsIndexFlushAPI> reference = new Reference<>();
// 设置调用的服务名
reference.setServiceName(serviceName);
// 设置接口名
reference.setInterfaceClass(IEsIndexFlushAPI.class);
// 设置上下文
reference.setApplicationConfig(applicationConfig);
// 获取接口实例
IEsIndexFlushAPI iEsIndexFlushAPI = ES_INDEX_FLUSH_API_MAP.computeIfAbsent(serviceName, s -> reference.refer());
// 接口调用
log.info("act=【EsIndexFlushApiInvoker】desc=【请求值】serviceName=【{}】dataListSize=【{}】indexNameList=【{}】tag=【{}】", serviceName,request.getDataList().size(),request.getIndexNameList(),request.getTag() );
EMApiResult<FlushResponse> result = iEsIndexFlushAPI.flush(request);3.7 环境隔离
同步数据是个比较重的操作,这个操作不应该影响到线上业务 因此,同步数据的服务应当与线上服务隔离开 ECP整合了架构组提供的标签路由功能,可以在整个请求链路中调用指定标签的服务,实现环境隔离。
ECP标签路由配置图:

图片
如下图,若在ECP上配置任务的标签路由为FLUSH,则在同步任务执行过程中,会自动调用链路中绑定了FLUSH标签的服务分组。

图片
若某些服务没有配置为FLUSH标签的分组,这时就会自动请求该服务的线上正常环境。这样,就可以做到一定程度上的环境隔离。
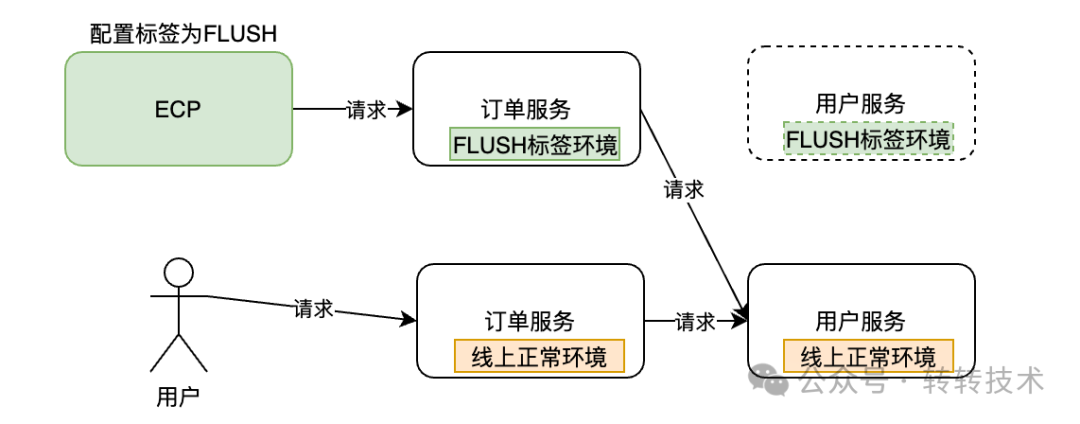
图片
3.8 探活与任务故障恢复机制
在推送数据的过程中,若发生了不可描述的事情导致任务中断,咋整?
到了需求DeadLine,发现任务在某年某月某日进度为1%的时候停了,哭了。
而且工作时间紧,任务重,总不能一定盯着任务,看有没有中断吧?这不适合,也不礼貌。
当然,这种情况在ECP是不会发生的,因为ECP是有“自救包”的。下面聊下ECP的任务探活和中断恢复机制。
如下图,在ECP中有探活和任务故障恢复两大组件 探活组件负责监控当前任务线程的执行状态,若任务线程正在执行,则对该任务的存活时间进行续期 任务故障恢复组件负责扫描当前未完成的任务,若任务上次存活时间大于指定的阈值时,则拉取该任务恢复执行。
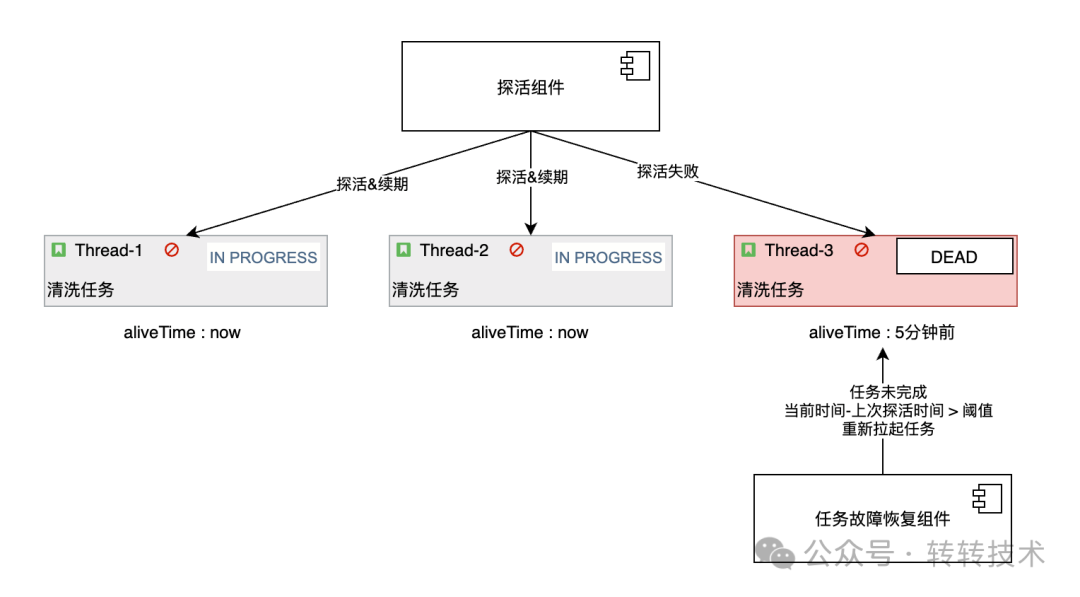
图片
续期的伪代码如下:
@Scheduled(fixedDelay = ScheduleTimeConstants.KEEP_ALIVE_MILLS)
public void renewal(){
futureMap.forEach((taskId,future)->{
if (!future.isDone()){
log.info("act=【renewal】desc=【任务续期】taskId=【{}】续期时间=【{}】",taskId, DateUtils.dateToString(new Date(),DateUtils.PATTERN));
contextService.renewal(taskId);
}else {
log.info("act=【renewal】desc=【任务结束】taskId=【{}】",taskId);
futureMap.remove(taskId);
}
});
}任务故障恢复的伪代码如下:
@Scheduled(fixedDelay = ScheduleTimeConstants.RESTART_TASK_MILLS)
public void restartTask(){
// 1.查询当前未完成的任务
List<TaskFlushExecuteContextPO> contextPOS = contextService.queryRunningTask();
for (TaskFlushExecuteContextPO contextPO : contextPOS) {
// 2.计算上次存活到当前的时间
Integer durationMin = calculateTimeSinceLastAlive();
// 3.若时间大于指定阈值 则对任务重新拉起
if (durationMin >= MAX_DURATION_MIN){
log.info("act=【restartTask】desc=【任务重新拉起】taskId=【{}】",contextPO.getTaskId());
// 4.更新alive_time进行锁定 防止并发执行
int i = contextExtMapper.casUpdateAliveTime();
if (i >0){
// 5.重新拉起任务
restart0(contextPO, aliveTime);
}
}
}
}3.9 平滑迁移的实现
将数据同步到ES,通常有两种方式:
- 直接把数据同步到原索引上。
- 新建一个索引,利用双写以及切换别名的方式实现流量的平滑迁移。
对于新建一个索引的场景,往往是索引Mapping的改变,或者是为了不影响原索引,保证操作可回滚。
针对这种场景,ECP分析了历来大家手动操作刷ES索引的步骤,将流程进行抽象,归纳了以下几个步骤,如下图:
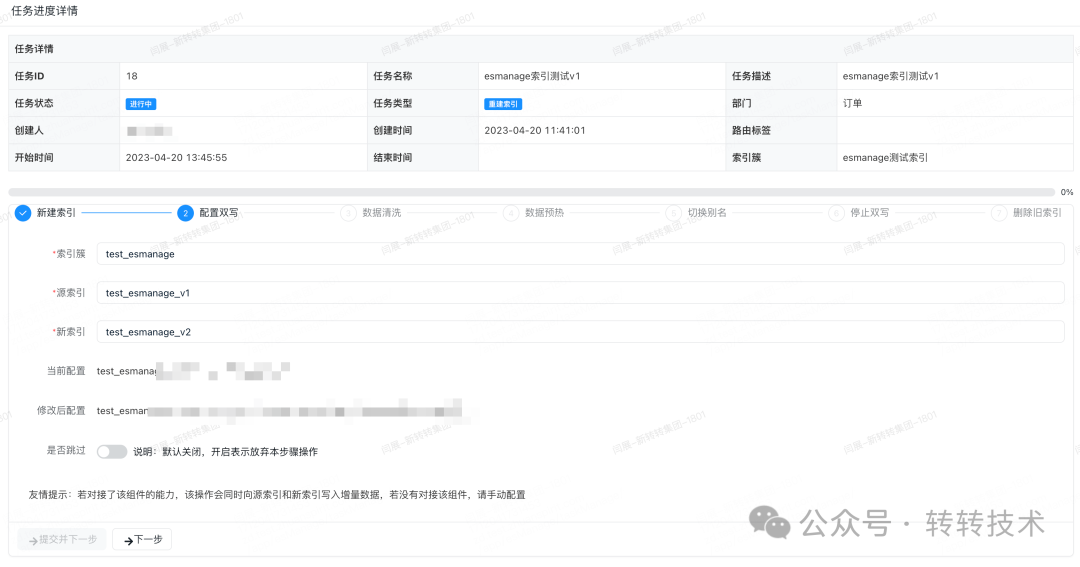
图片
ECP提供了平滑迁移组件,其内部整合了Apollo配置中心实现推送能力,其简要的实现流程如下图:
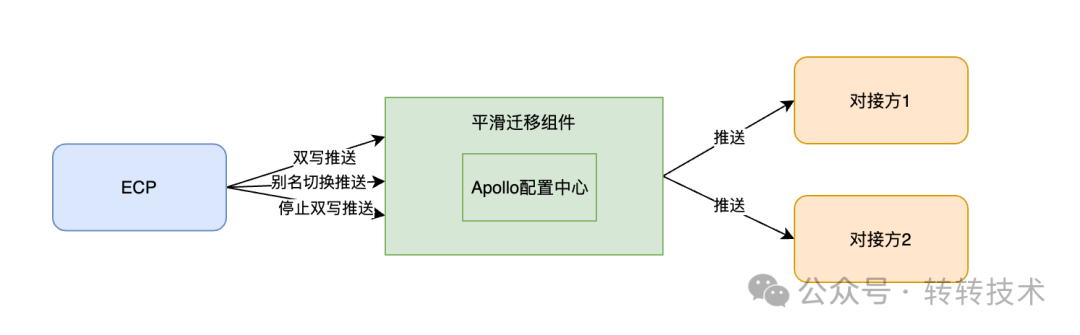
图片
3.10 优雅的日志记录
如下图所示展示了该任务操作的日志,原则上日志记录为非核心业务,需要与核心业务代码进行剥离,因此使用注解式流水记录是个很好的选择。
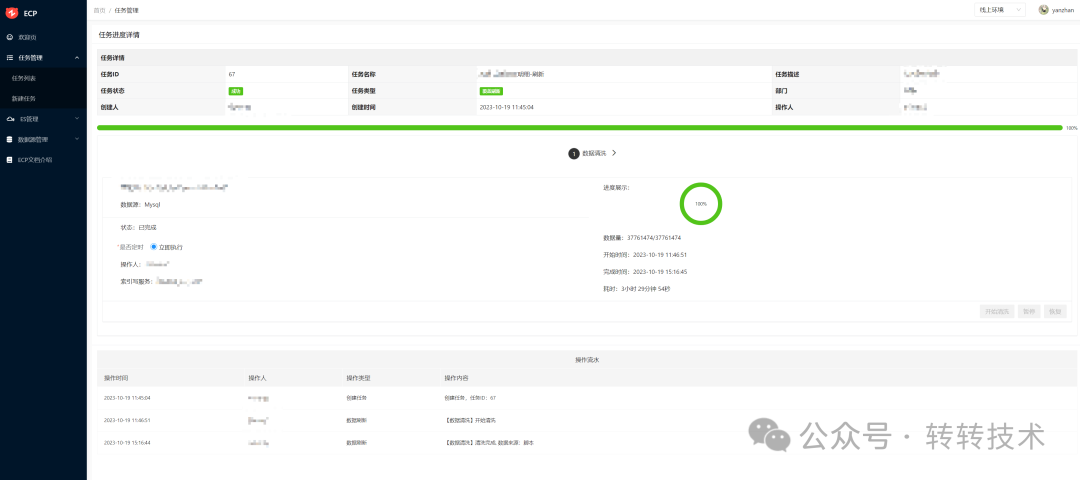
图片
但注解式流水记录有个问题,就是在很多的场景下,流水里面的值需要动态获取,利用注解可以实现吗? 答案是可以的,在上图所示中,任务ID、数据来源都是动态数据,那如何实现的呢?看下面代码:
@Flow(subjectIdEp = "#taskPO.id",subjectType = SubjectTypeEnum.TASK,operateFlowType = OperateFlowTypeEnum.CREATE_TASK,content = "'创建任务,任务ID:' + #taskPO.id ")
public void saveTaskWithUser(TaskPO taskPO) {
String name = LoginUserContext.get().getName();
taskPO.setCreator(name);
taskPO.setModifier(name);
taskMapper.insertSelective(taskPO);
}subjectIdEp为流水主题ID,#taskPo.id为一个表达式,可用动态获取参数taskPo中的id值,这里利用了springEl表达式的能力。
content = "'创建任务,任务ID:' + #taskPO.id " 为流水信息,同样利用了springEL表达式,动态获取请求参数taskPo中的id信息。
但有些信息需要一系列的计算才可以获取到,而不是单纯的从对象中取值,这也是可以实现的。如下:
@Flow(subjectIdEp = "#contextPO.taskId",
subjectType = SubjectTypeEnum.TASK,
operateFlowType = OperateFlowTypeEnum.DATA_FLUSH,
content = "'【数据同步】异常中断任务恢复执行,中断时间:' + T(com.zhuanzhuan.esmanage.utils.DateUtils).dateToStringSimple(#aliveTime)")
@Transactional(rollbackFor = Exception.class,isolation = Isolation.REPEATABLE_READ)
public void restart0(TaskFlushExecuteContextPO contextPO, Date aliveTime) {
log.info("act=【restartTask】desc=【任务重新拉起】taskId=【{}】原aliveTime=【{}】", contextPO.getTaskId(), aliveTime);
dsProcessorExecutor.executeAndKeepAliveMonitor(contextPO.getTaskId());
}其中T(com.zhuanzhuan.esmanage.utils.DateUtils).dateToStringSimple(#aliveTime) 代表执行的是DateUtils.dateToStringSimple 方法,也就是说表达式是可以调用方法的,包括从spring容器中获取对象,调用对象的方法均可。
这种注解式流水的实现原理,就是利用SPEL表达式和Spring Aop的特性,写一个切面,拦截自定义的flow注解即可,伪代码如下:
// 定义切面,拦截FLOW注解
@Around("@annotation(com.zhuanzhuan.esmanage.entity.annotation.Flow)")
public Object around(ProceedingJoinPoint point) throws Throwable {
// 调用目标方法
Object result = null;
try {
result = point.proceed();
recordFlow(point,result);
return result;
} catch (Throwable e) {
recordException(point,e);
throw e;
}
}
// 流水记录的实现
private void recordFlow(ProceedingJoinPoint point, Object result) {
// try catch 防止影响主逻辑
//TODO 看是否需要写在一个事务中,主要评估流水的重要性
try {
MethodSignature signature = (MethodSignature) point.getSignature();
Flow flowAnnotation = getFlowAnnotation(signature);
// 组装参数上下文
EvaluationContext evaluationContext = buildContext(point, signature);
evaluationContext.setVariable("result",result);
// ID表达式
String subjectIdEp = flowAnnotation.subjectIdEp();
// content表达式
String content = getContent(flowAnnotation, evaluationContext);
// SPEL解析表达式
Expression expression = PARSER.parseExpression(subjectIdEp);
Integer subjectId = (Integer)expression.getValue(evaluationContext);
record(flowAnnotation, subjectId, content);
} catch (Exception e) {
log.error("记录操作流水失败", e);
}
}总得来说,ECP的实现中有很多的技术细节需要考虑,技术难度一般。
实际上,在我们大部分的项目中,考验的就是对细节的把控。
ps:感谢ChatGPT对本文名称的大力支持
闫展,转转交易中台研发工程师
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK