

实例演示如何使用CCE XGPU虚拟化 - 华为云开发者联盟
source link: https://www.cnblogs.com/huaweiyun/p/18107964
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文分享自华为云社区《CCE XGPU虚拟化的使用》,作者: 可以交个朋友。
在互联网场景中,用户的AI训练和推理任务对GPU虚拟化有着强烈的诉求。GPU卡作为重要的计算资源不管是在算法训练还是预测上都不可或缺,而对于常见的算法训练业务或智能业务都有往容器迁移演进的趋势,所以如何更好的利用GPU资源成了容器云平台需要解决的问题。云厂商如果提供GPU虚拟化可以为用户带来的如下收益:
- 提高资源利用率(GPU/显存)。GPU共享后,总利用率接近运行任务利用率之和,减少了资源浪费。
- 提高服务质量(QoS),增强公平性。多个任务既可以同时开始享受资源,也可以单独保证某一个任务的运行。
- 减少任务排队时间和总任务的消耗时间。假设两个任务结束时间分别是x,y,通过GPU共享,两个任务全部结束的时间小于x+y。
- 集群中可以运行更多任务,通过分时复用,减少抢占。
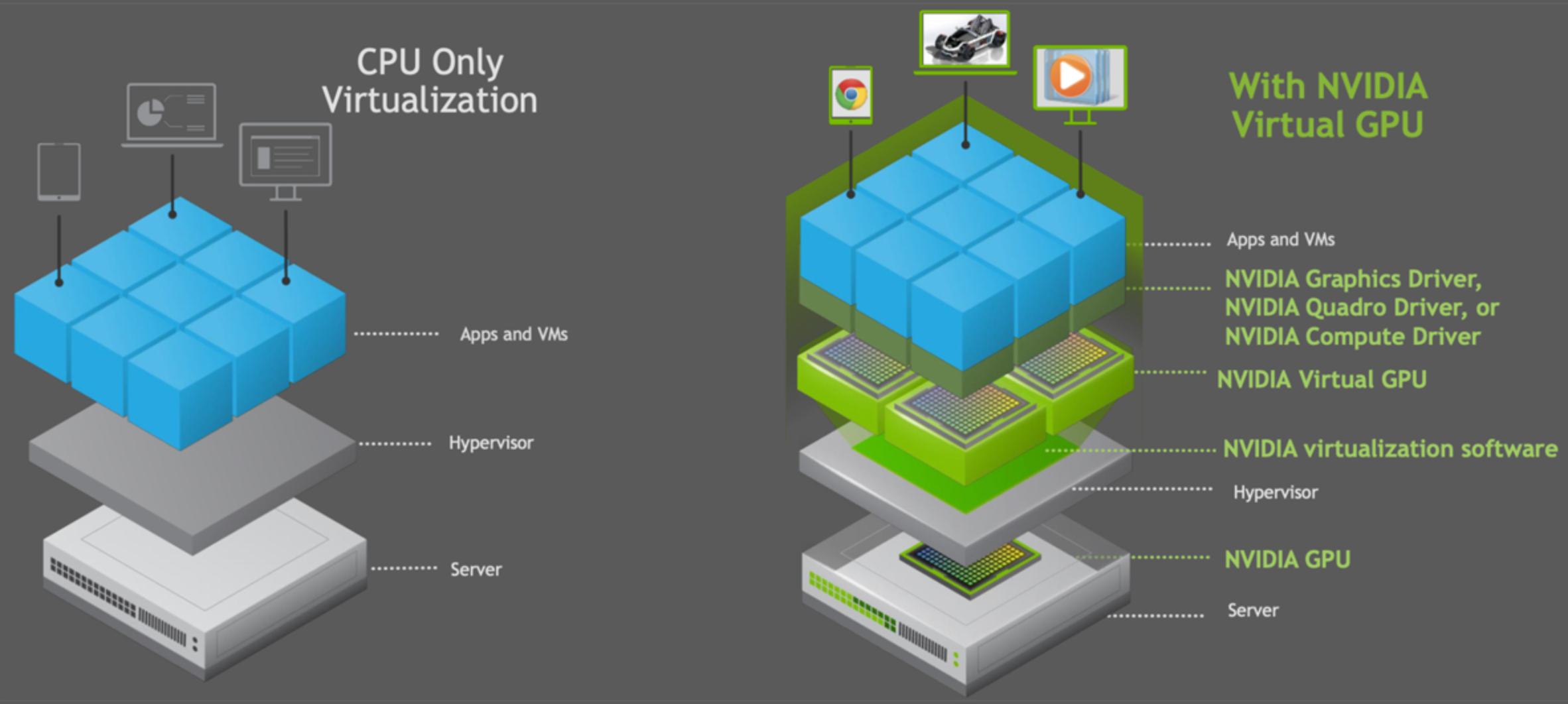
二 CCE平台上GPU虚拟化的优势
CCE GPU虚拟化采用自研xGPU虚拟化技术,能够动态对GPU设备显存与算力进行划分,单个GPU卡最多虚拟化成20个GPU虚拟设备。相对于静态分配来说,虚拟化的方案更加灵活,最大程度保证业务稳定的前提下,可以完全由用户自己定义使用的GPU量,
- 灵活:精细配置GPU算力占比及显存大小,算力分配粒度为5%GPU,显存分配粒度达MB级别。
- 隔离:支持显存和算力的严格隔离,支持单显存隔离,算力与显存同时隔离两类场景。
- 兼容:业务无需重新编译,无需进行CUDA库替换,对业务无感。
三 CCE上如何更好的使用xGPU能力
建议用户在使用GPU资源时,提前创建好对应规格型号的GPU节点资源池,方便后期管理和调度。
3.1 安装插件
GPU的使用需要借助CCE插件能力实现,前往CCE 插件市场进行插件的安装。
安装Volcano调度器插件
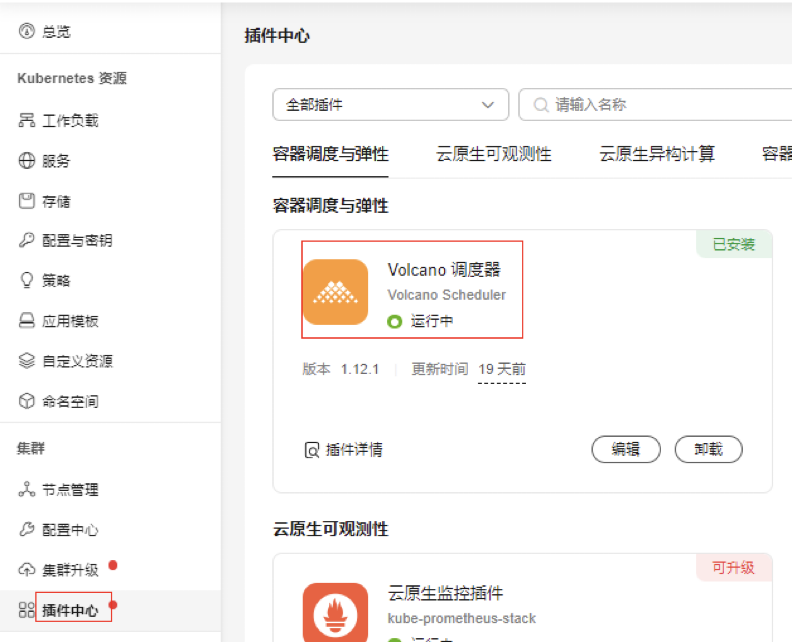
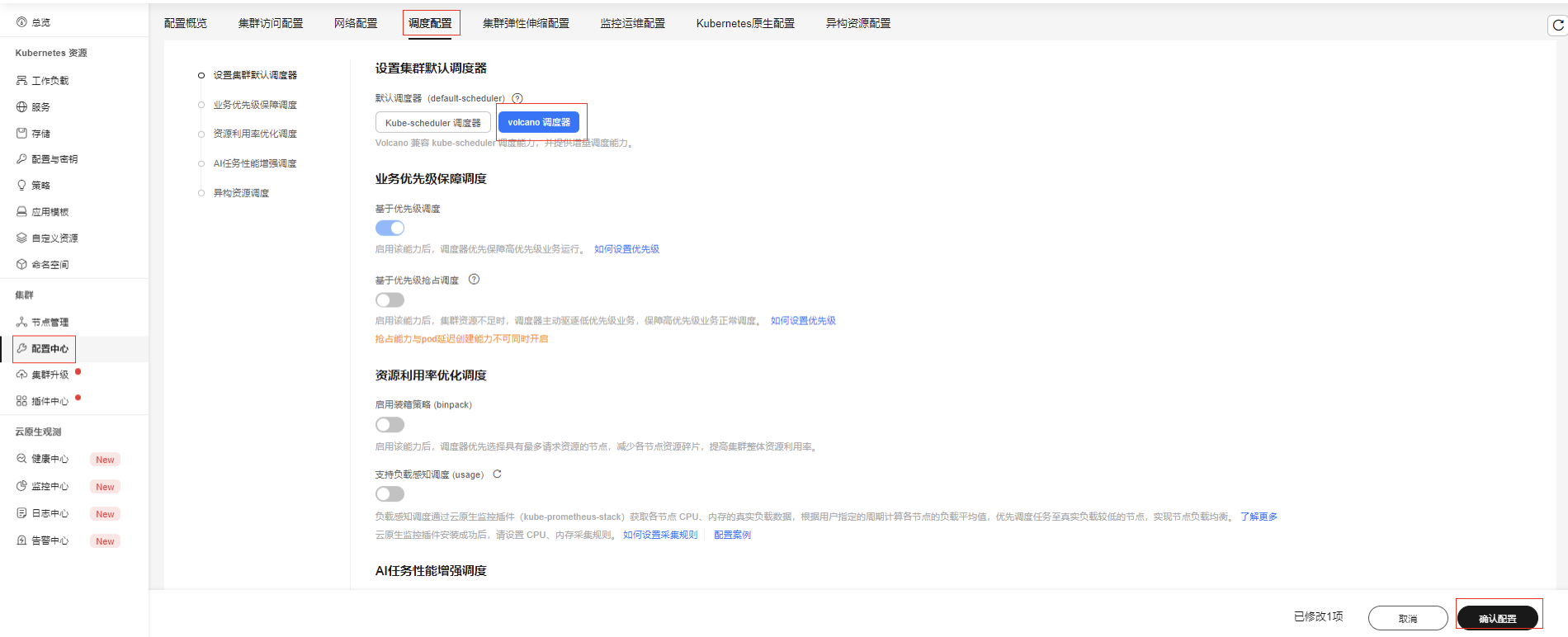
插件安装完成后,可前往配置中心-调度设置,设置默认调度器为Volcano,如果不设置需要在负载yaml中指定调度器spec.schedulerName: volcano
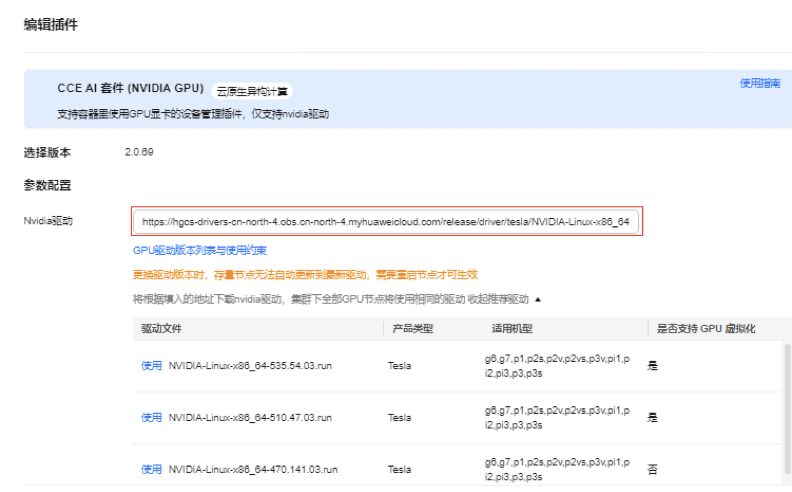
安装GPU插件(CCE AI 套件)
插件中心安装GPU插件,CCE平台已经提供多个版本的驱动,在列出的驱动列表中选择使用即可,支持不同节点池选择不同驱动版本。也支持自行配置其它版本的驱动,需要自行提供驱动下载链接。
3.2 创建负载任务调用xGPU资源
根据xGPU支持虚拟化维度进行操作实践
注意: 未开启volcano作为全局调度器时,需要在yaml指定调度器为volcano
3.2.1 xGPU模式之显存隔离如何使用
创建负载app01.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app01
spec:
replicas: 1
selector:
matchLabels:
app: app01
template:
metadata:
labels:
app: app01
spec:
containers:
- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:
- containerPort: 80
resources:
limits:
volcano.sh/gpu-mem.128Mi: '16'
requests:
volcano.sh/gpu-mem.128Mi: '16'
schedulerName: volcano
volcano.sh/gpu-mem.128Mi: '16': 显存申请量等于 128Mi x 16=2048Mi=2Gi;也当前负载最多只能使用2Gi的显存资源。
查看Pod信息,pod yaml自动生成两条注解,同样也标注了负载使用了2Gi显存
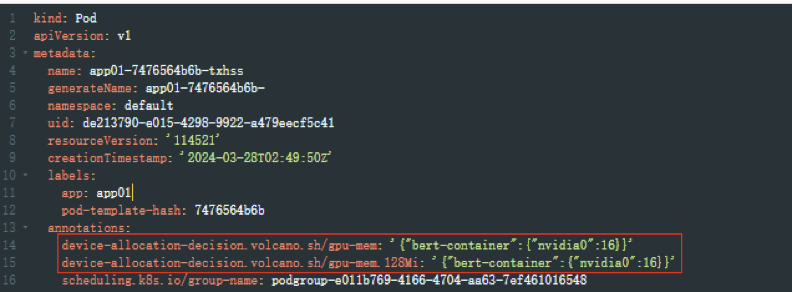
容器内使用nvidia-smi查看显存,表现最大显存为2Gi,显存隔离生效
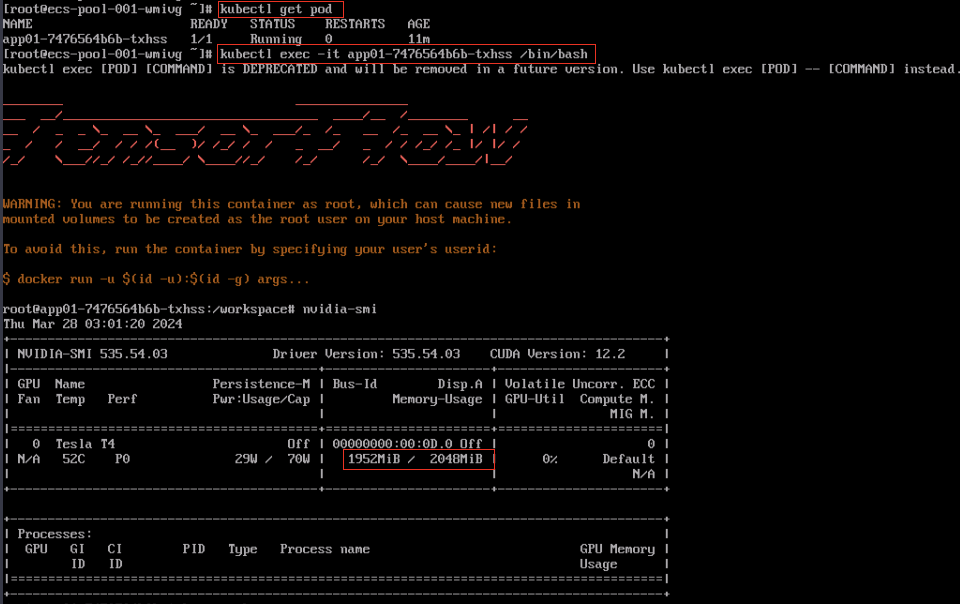
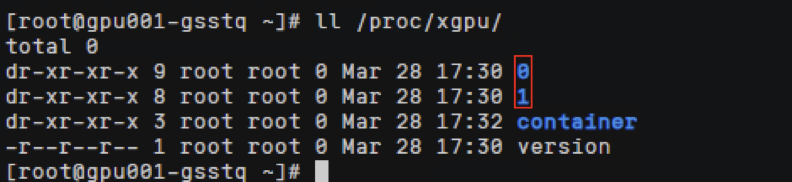
xGPU显存隔离能力通过在HCE2.0上实现,在节点上查看/proc/xgpu目录,0表示使用的物理gpu显卡的序列号(如果是多个卡则有多个目录,文件名从0开始,各个文件对应相关下标的GPU卡),container目录下存放使用gpu虚拟化的 容器信息。
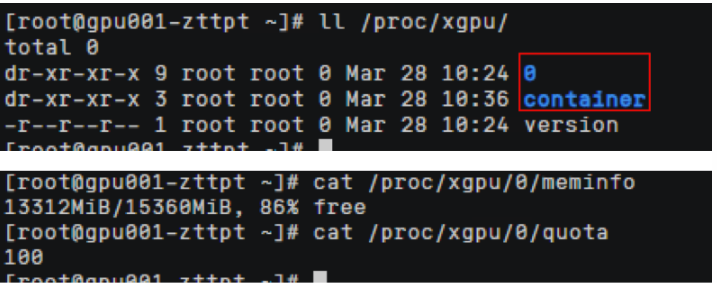
查看容器ID对应命令,查看meminfo和quota文件,可以看到HCE2.0控制给容器GPU卡显存和算力的上限配置。

meminfo :容器分配显存为2Gi,quota :容器分配的算力,0代表不限制算力可以使用到整卡的算力路径中
xgpu3: 代表虚拟gpu卡的卡号 每创建一个新的容器都会按次序生成一个新的虚拟gpu卡号
3.3.2 单节点多张gpu卡场景分析
购买多gpu卡机型
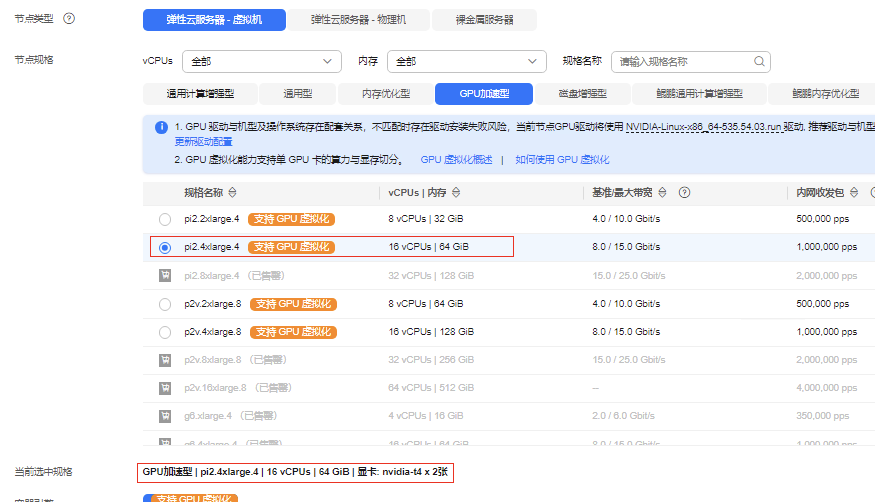
虚拟化模式下不支持单pod申请超过一张卡的gpu资源,如单pod需要使用多卡资源请关闭gpu虚拟化;同时多卡调度,也不支持1.x,2.x 形式,需要为大于1的整数
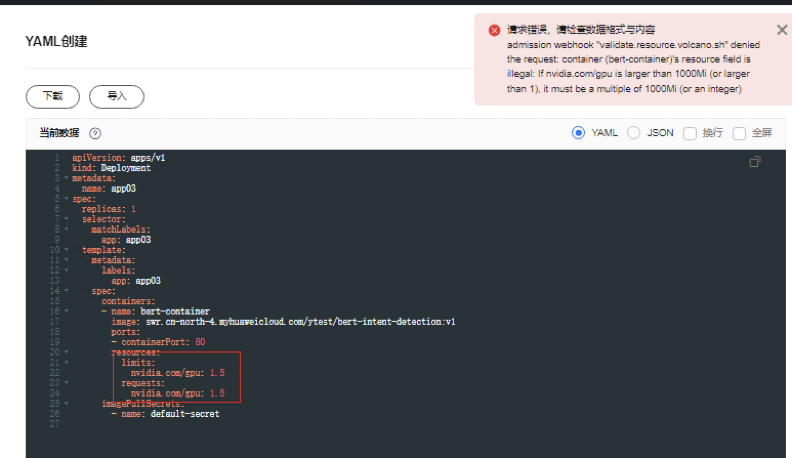
节点上能看到两张gpu物理卡编号
看到容器资源显存隔离生效,xGPU1是从0号gpu卡上软件连接过来的

3.2.3 xGPU模式之显存算力均隔离如何使用
创建负载app02,yaml如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: app02
spec:
replicas: 1
selector:
matchLabels:
app: app02
template:
metadata:
labels:
app: app02
spec:
containers:
- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:
- containerPort: 80
resources:
limits:
volcano.sh/gpu-mem.128Mi: '32'
volcano.sh/gpu-core.percentage: '20'
requests:
volcano.sh/gpu-mem.128Mi: '32'
volcano.sh/gpu-core.percentage: '20'
schedulerName: volcano
volcano.sh/gpu-mem.128Mi: '32': 显存申请量等于 128Mi x 32=4096Mi=4Gi
volcano.sh/gpu-core.percentage: '20' : 算力申请量等于整卡算力的20%表示当前负载最多只能使用4Gi的显存,算力上限为20%。
查看Pod信息,yaml文件自动生成3条注解,标注了负载使用了4Gi显存,算力可使用整卡算力的20%
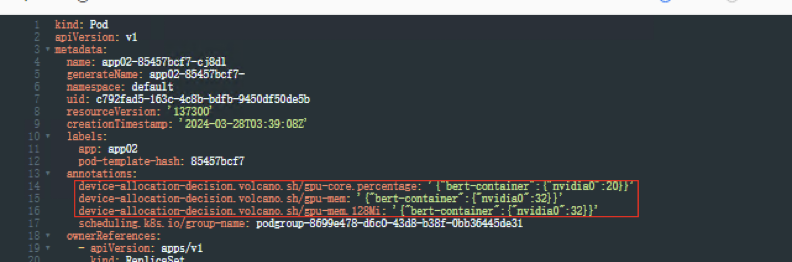
容器内执行nvidia-smi 命令查看显卡驱动信息也可发现显存为4Gi
前往宿主机查看GPU资源使用状况
节点上/proc/xgpu/container 目录下查看相关容器的xGPU的配额,发现可用显存为4Gi,可用算力为20%

3.3.3 xGPU兼容GPU共享模式
如果您在集群中已使用nvidia.com/gpu资源的工作负载,可在gpu-device-plugin插件配置中选择“虚拟化节点兼容GPU共享模式”选项,即可兼容Kubernetes默认GPU调度能力。
开启该兼容能力后,使用nvidia.com/gpu配额时等价于开启虚拟化GPU显存隔离,可以和显存隔离模式的工作负载共用一张GPU卡,但不支持和算显隔离模式负载共用一张GPU卡。
创建工作负载app03,yaml如下,使用整卡调度
apiVersion: apps/v1
kind: Deployment
metadata:
name: app03
spec:
replicas: 1
selector:
matchLabels:
app: app03
template:
metadata:
labels:
app: app03
spec:
containers:
- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:
- containerPort: 80
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
schedulerName: volcano
查看Pod信息,yaml文件中自动生成2条注解,算力可使用整卡百分之100的算力
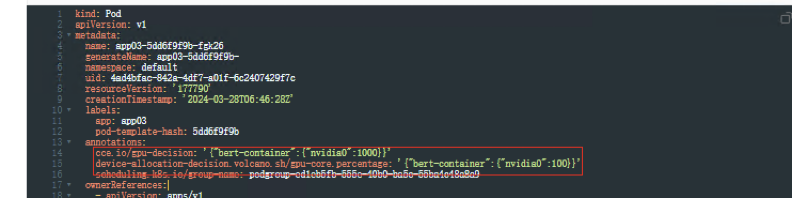
容器内执行 nvidia-smi命令查看显卡驱动信息
可以发现当我们申请1张GPU整卡时,容器里的显存上限为整卡的显存配额
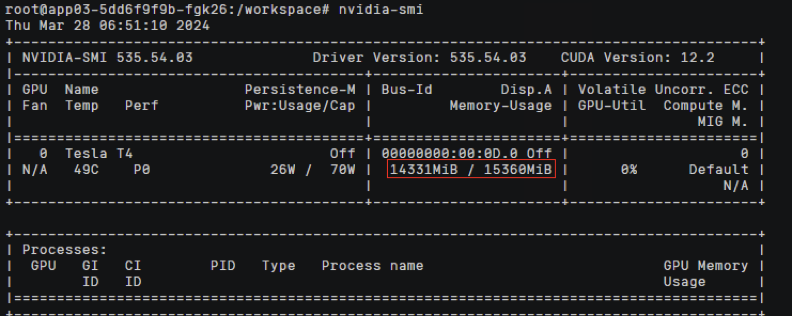
节点上查看/proc/xgpu/container/ 目录下为空,容器使用到整卡的显存和算力资源
创建工作负载app04, yaml如下,使用分卡共享调度
apiVersion: apps/v1
kind: Deployment
metadata:
name: app04
spec:
replicas: 1
selector:
matchLabels:
app: app04
template:
metadata:
labels:
app: app04
spec:
containers:
- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:
- containerPort: 80
resources:
limits:
nvidia.com/gpu: 0.4
requests:
nvidia.com/gpu: 0.4
schedulerName: volcano
注意:兼容Kubernetes默认GPU调度模式时,如使用nvidia.com/gpu: 0.1参数,最终计算后 ,指定的显存值如非128MiB的整数倍时会向下取整,例如:GPU节点上的显存总量为24258MiB,而24258MiB * 0.1 = 2425.8MiB,此时会向下取整至128MiB的18倍,即18 * 128MiB=2304MiB
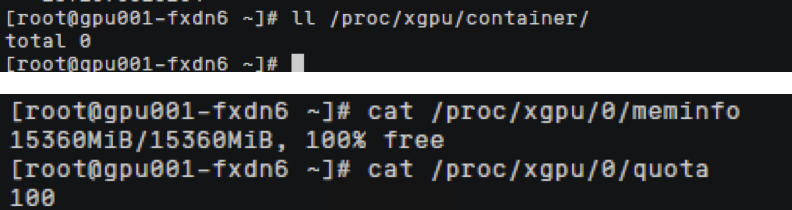
查看Pod信息,yaml文件自动转换成显存隔离,算力不隔离
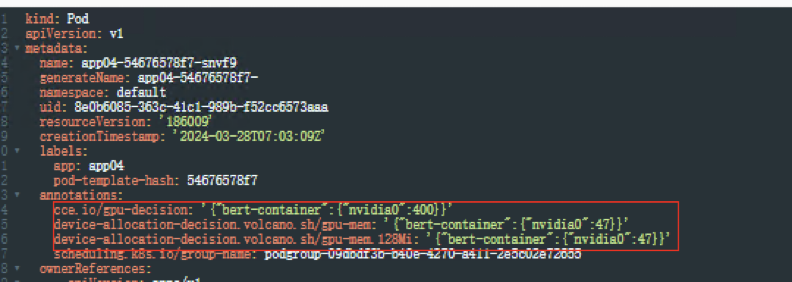
容器内执行 nvidia-smi 命令查看容器中使用的显卡信息
可以发现容器中显存配额为整卡百分之40显存资源
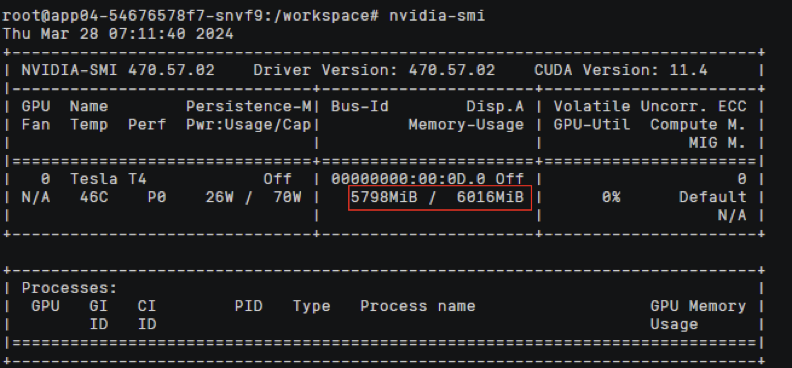
前往节点 /proc/xgpu/container 目录查看分配的xGPU的信息
可以发现对应的容器限制效果为:显存隔离生效算力不进行隔离

3.3.4 单pod中多个容器(显存隔离)
创建工作负载app05,yaml如下:apiVersion: apps/v1
kind: Deployment
metadata:
name: app05
spec:
replicas: 1
selector:
matchLabels:
app: app05
template:
metadata:
labels:
app: app05
spec:
containers:
- name: bert-container
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
ports:
- containerPort: 80
resources:
limits:
volcano.sh/gpu-mem.128Mi: '16'
requests:
volcano.sh/gpu-mem.128Mi: '16'
- name: bert-container2
image: swr.cn-north-4.myhuaweicloud.com/container-solution/bert-intent-detection:v1
command:
- /bin/bash
args:
- '-c'
- while true; do echo hello; sleep 10;done
ports:
- containerPort: 81
resources:
limits:
volcano.sh/gpu-mem.128Mi: '16'
requests:
volcano.sh/gpu-mem.128Mi: '16'
schedulerName: volcano
查看Pod信息,yaml文件注解中会有两个容器的资源使用2Gi+2Gi、
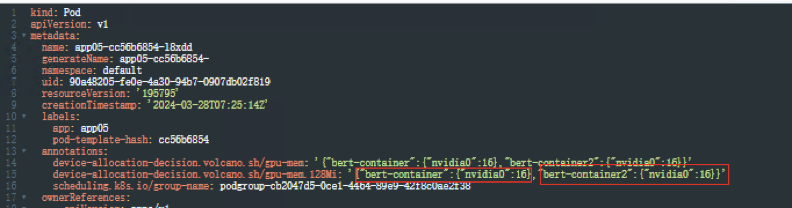
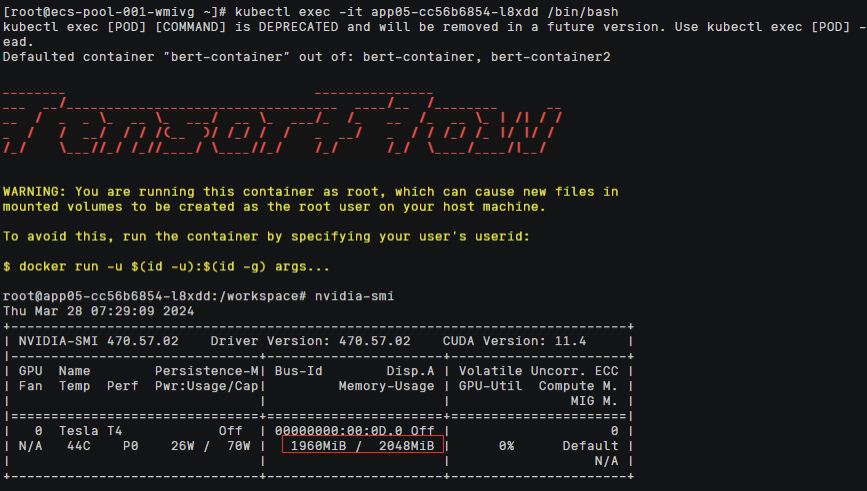
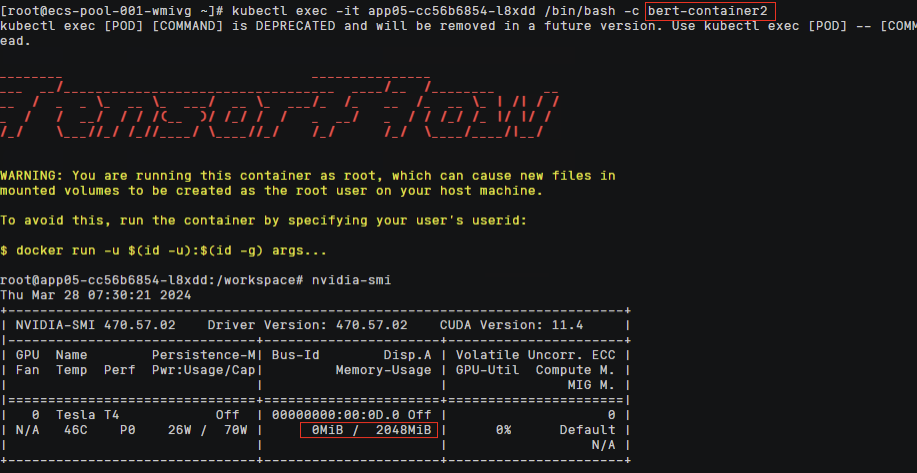
容器中执行nvidia-smi命令,查看容器中显存分配信息
两个容器中各自都看到有2Gi显存的资源
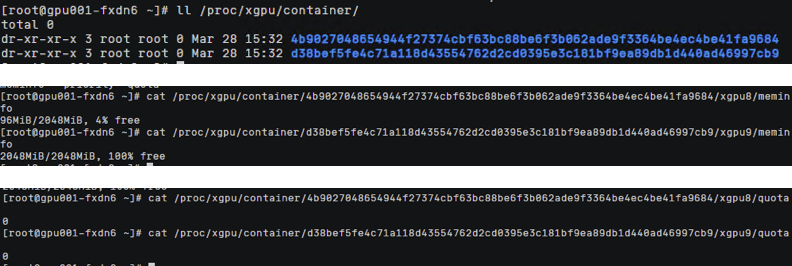
节点查看 /proc/xgpu/congtainer目录下生成两个容器文件,显存隔离都为2Gi,算力都没有做限制
3.4 GPU监控相关指标
查看监控指标需要安装kube-prometheus-stack插件的server模式
xGPU核心监控指标
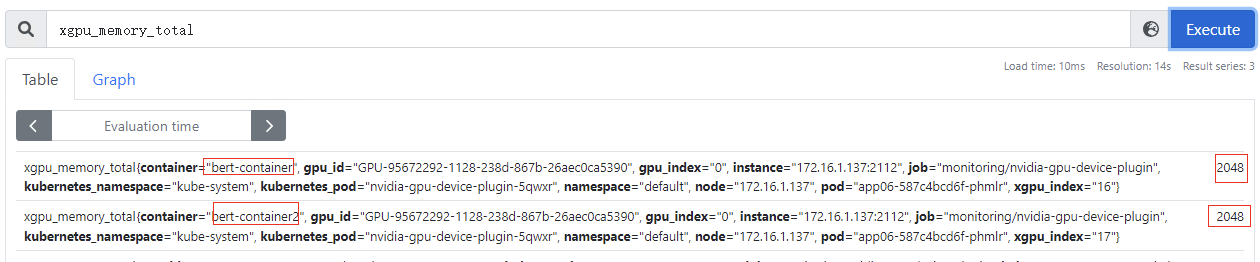
xgpu_memory_total:容器GPU虚拟化显存总量,该指标为container级别
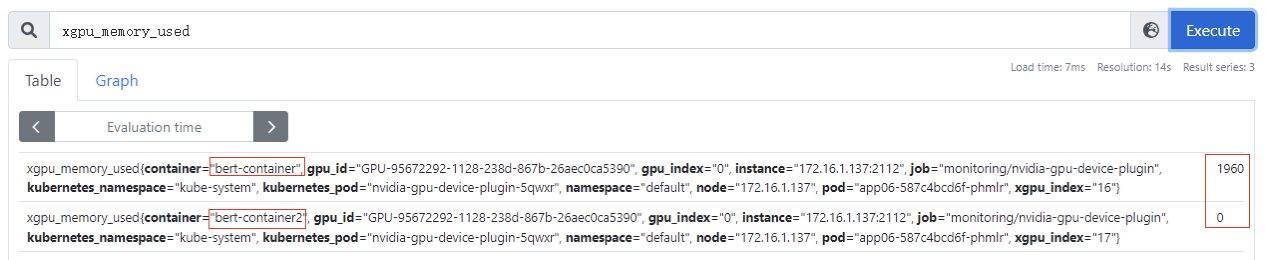
xgpu_memory_used:容器使用GPU虚拟化显存使用量,该指标为container级别
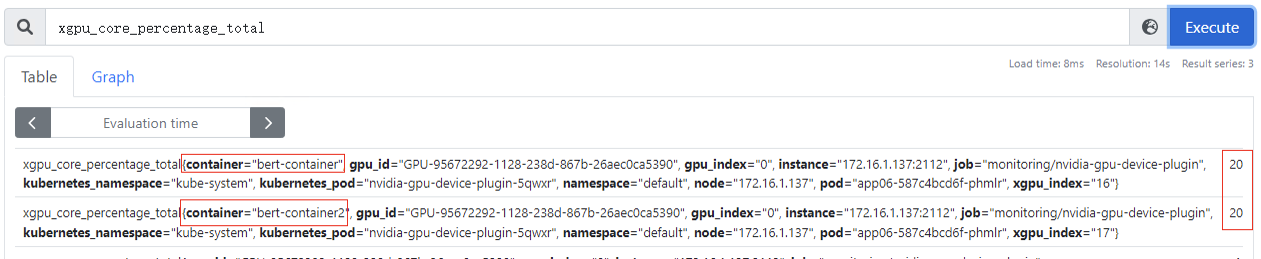
xgpu_core_percentage_total:容器GPU虚拟化算力总量,该指标为container级别,20代表可以使用整卡算力的20%,该指标为container级别
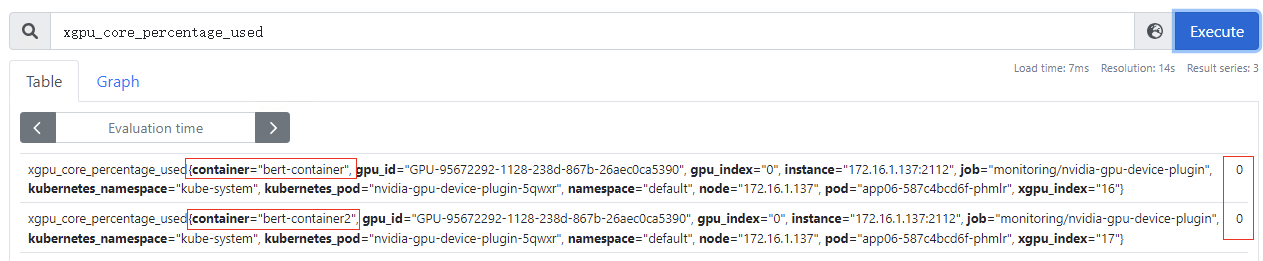
xgpu_core_percentage_used:容器GPU虚拟化算力使用量,该指标为container级别,目前使用量为0
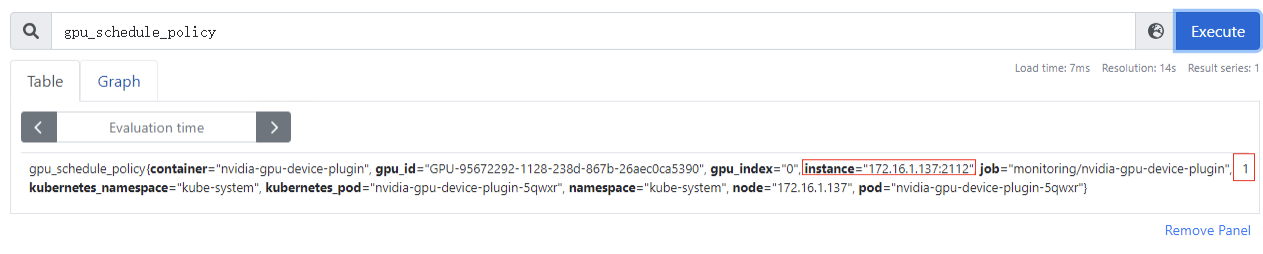
gpu_schedule_policy:GPU虚拟化分三种模式(0:显存隔离算力共享模式、1:显存算力隔离模式、2:默认模式,表示当前卡还没被用于GPU虚拟化设备分配),该指标为节点级别
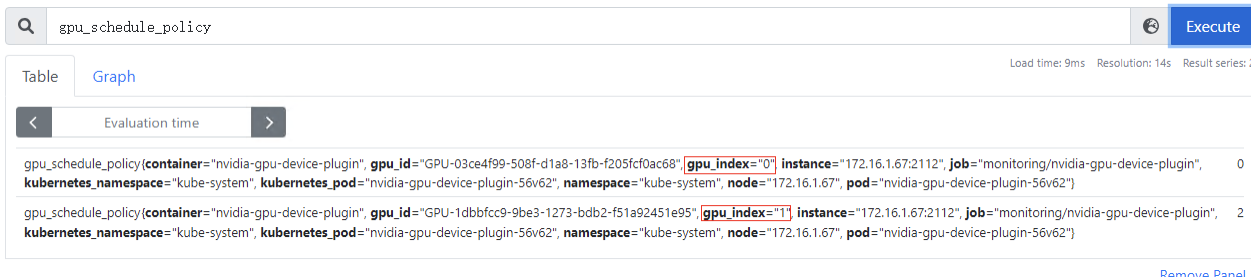
多卡场景,gpu_index字段为gpu物理卡的编号
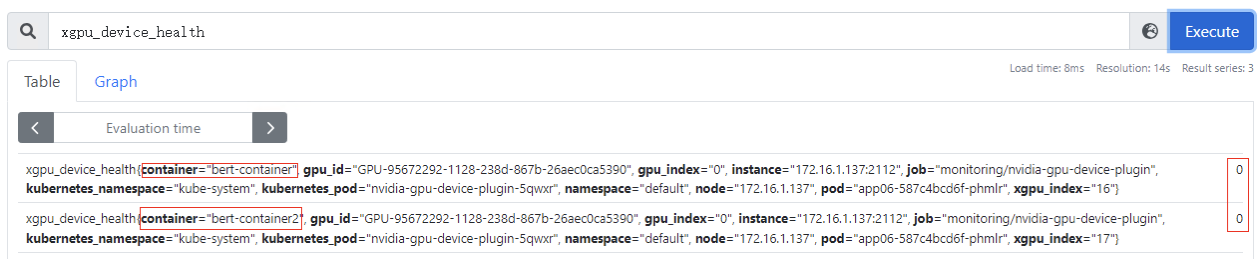
xgpu_device_health:GPU虚拟化设备的健康情况,0:表示GPU虚拟化设备为健康状态;1:表示GPU虚拟化设备为非健康状态。该指标为container级别
其他监控指标请参考:https://support.huaweicloud.com/usermanual-cce/cce_10_0741.html
3.5 升级GPU驱动版本
Nvidia driver驱动程序定期会发布新版本,如果负载需要使用新版本驱动,可以通过CCE AI套件的能力进行驱动版本的更新
1.编辑gpu插件 点击使用获取535.54.03版本的驱动下载链接
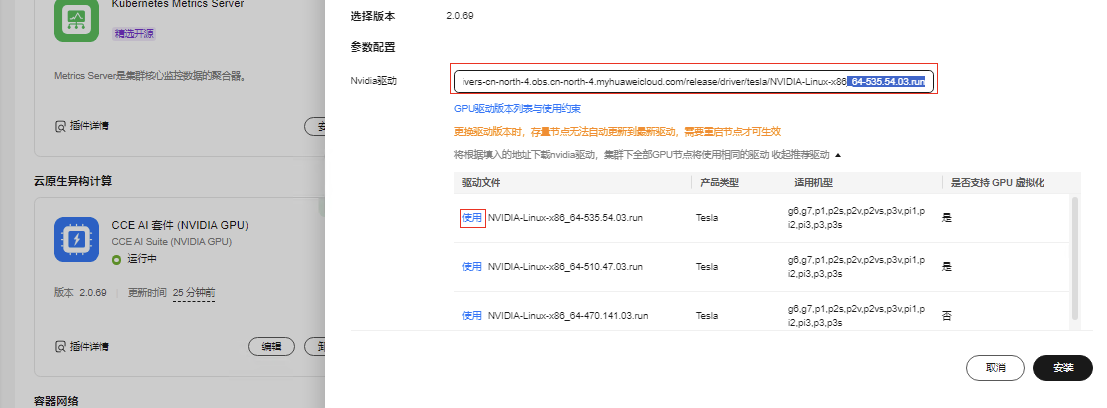
https://hgcs-drivers-cn-north-4.obs.cn-north-4.myhuaweicloud.com/release/driver/tesla/NVIDIA-Linux-x86_64-535.54.03.run
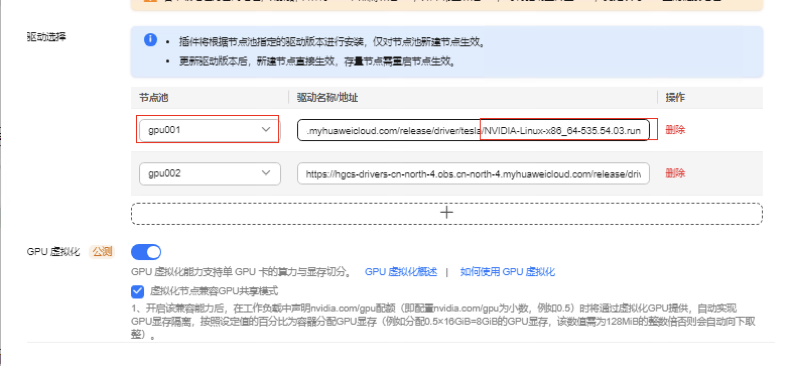
2.更改gpu001节点池的下载驱动链接为535.54.03版本
3.插件升级完成后必须手动重启gpu节点才能生效
注意:重启节点会造成该节点上业务中断,需要提前将该节点设置禁止调度,然后扩容该节点上关键业务,再进行驱逐处理,最后重启节点,恢复调度。
节点重启中

节点驱动升级完成

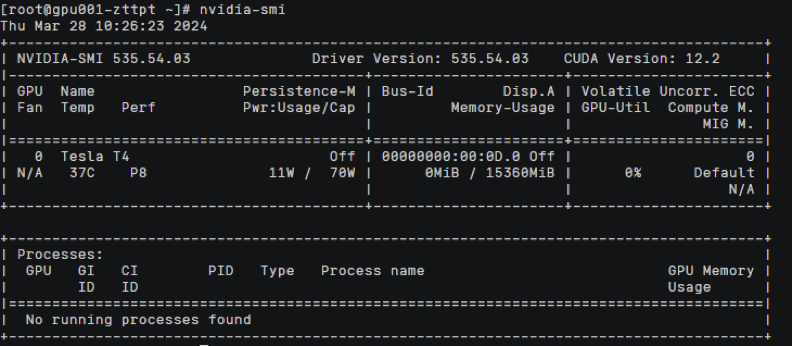
验证:gpu驱动升级成功到535.54.03版本
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK