

MySQL系列:缓冲池Buffer Pool的设计思想
source link: https://www.51cto.com/article/768849.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
MySQL系列:缓冲池Buffer Pool的设计思想
我们主要讲了InnoDB的存储引擎,其中主要的一个组件就是缓存池Buffer Pool,缓存了磁盘的真实数据,然后基于缓存做增删改查操作,同时配合了后续的redo log、刷磁盘等机制和操作。如下图:
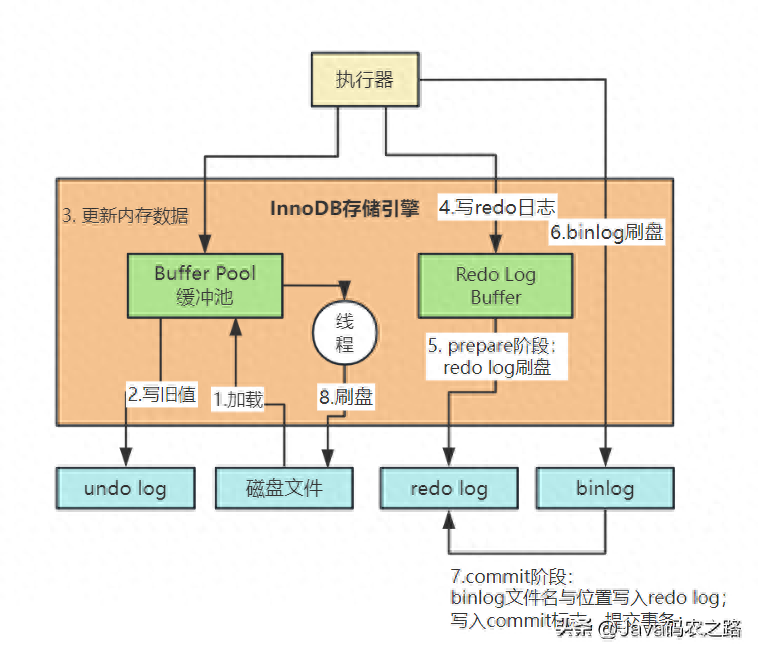
这一篇,深入该组件内部,学习一下其设计思想。
2. Buffer Pool数据结构
Buffer Pool本质其实就是数据库的一个内存组件,默认情况下是128MB,如果我们的数据库如果是16核32G的机器,那么你就可以给Buffer Pool分配个2GB的内存,使用下面的配置就可以了
innodb_buffer_pool_size = 2147483648
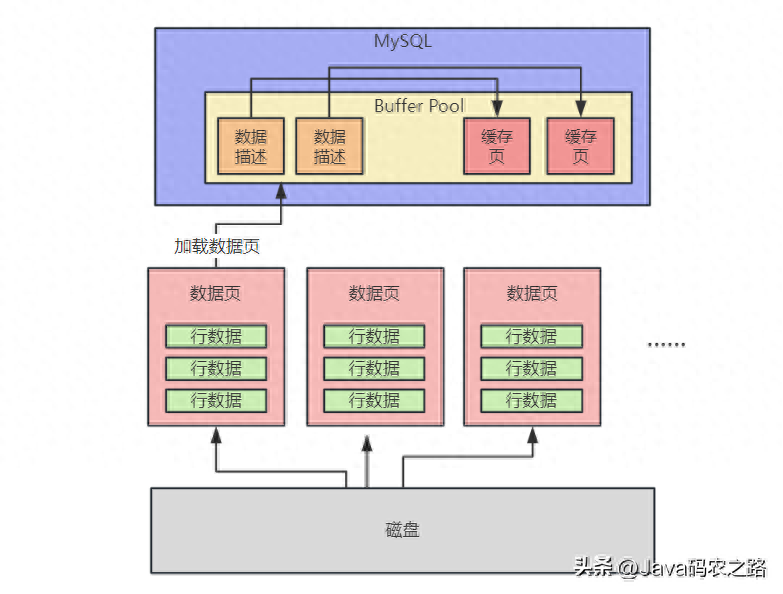
磁盘加载数据页到缓存,数据页在缓存中被定义为缓存页,缓存页与缓存页默认16KB,每个缓存页有对应的描述数据,描述了这个数据页所属的表空间、数据页的编号、这个缓存页在Buffer Pool中的地址等。在Buffer Pool中,每个缓存页的描述数据放在最前面,各个缓存页放在后面。Buffer Pool中的描述数据大概相当于缓存页大小的5%左右,也就是每个描述数据大概是800个字节左右的大小,然后假设你设置的buffer pool大小是128MB,实际上Buffer Pool真正的最终大小会超出一些,可能有个130多MB的样子,因为他里面还要存放每个缓存页的描述数据。
数据结构如下图:
3. free链表
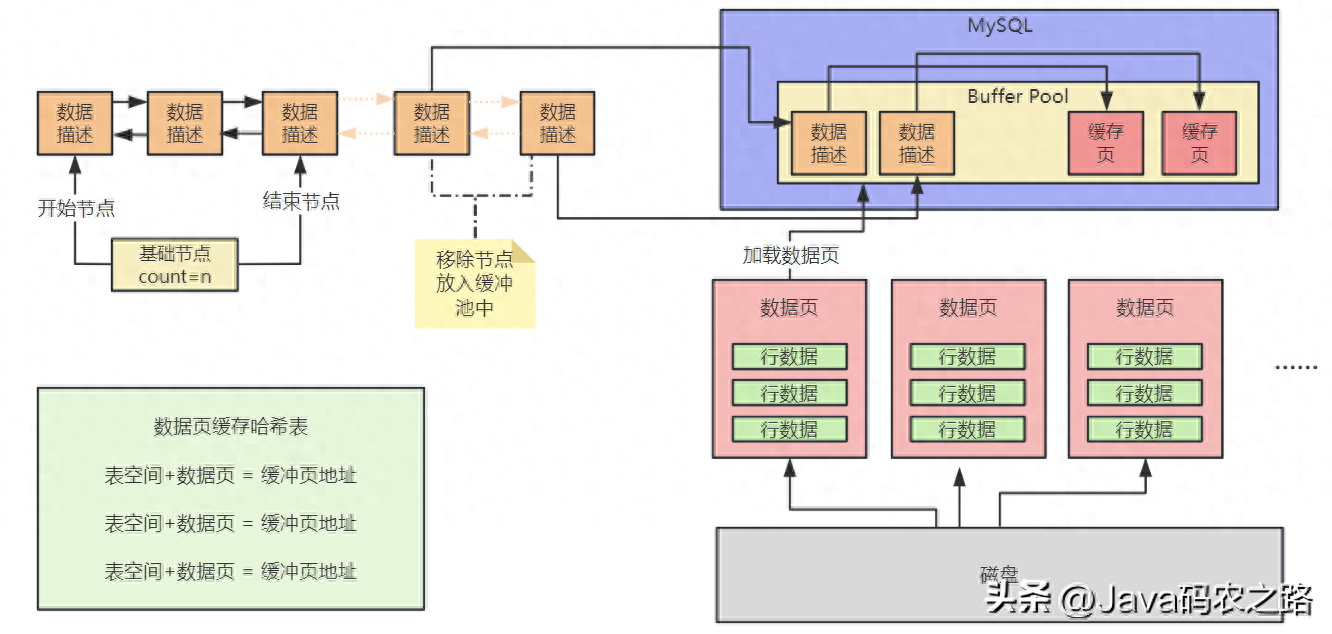
接着我们来看下一个问题,当数据库运行起来之后,肯定会不停的执行增删改查的操作,此时就需要不停的从磁盘上读取一个一个的数据页放入Buffer Pool中的对应的缓存页里去,把数据缓存起来,那么以后就可以对这个数据在内存里执行增删改查了。但是此时在从磁盘上读取数据页放入Buffer Pool中的缓存页的时候,必然涉及到一个问题,就是哪些缓存页是空闲的?
所以数据库会为Buffer Pool设计一个free链表,他是一个双向链表数据结构,这个free链表里,每个节点就是一个空闲的缓存页的描述数据块的地址,也就是说,只要你一个缓存页是空闲的,那么他的描述数据块就会被放入这个free链表中。如果要把数据页写入缓存页,就从链表中摘除这个节点,将该节点的描述数据写到Buffer pool,再把写入对应的缓存页。
写入之前还会判断该数据页是否已经被缓存,引入哈希表数据结构,他会用表空间号+数据页号,作为一个key,然后缓存页的地址作为value,当要使用一个数据页的时候,通过“表空间号+数据页号”作为key去这个哈希表里查一下,如果没有就读取数据页,如果已经有了,就说明数据页已经被缓存了。
如下图所示:
4. flush链表
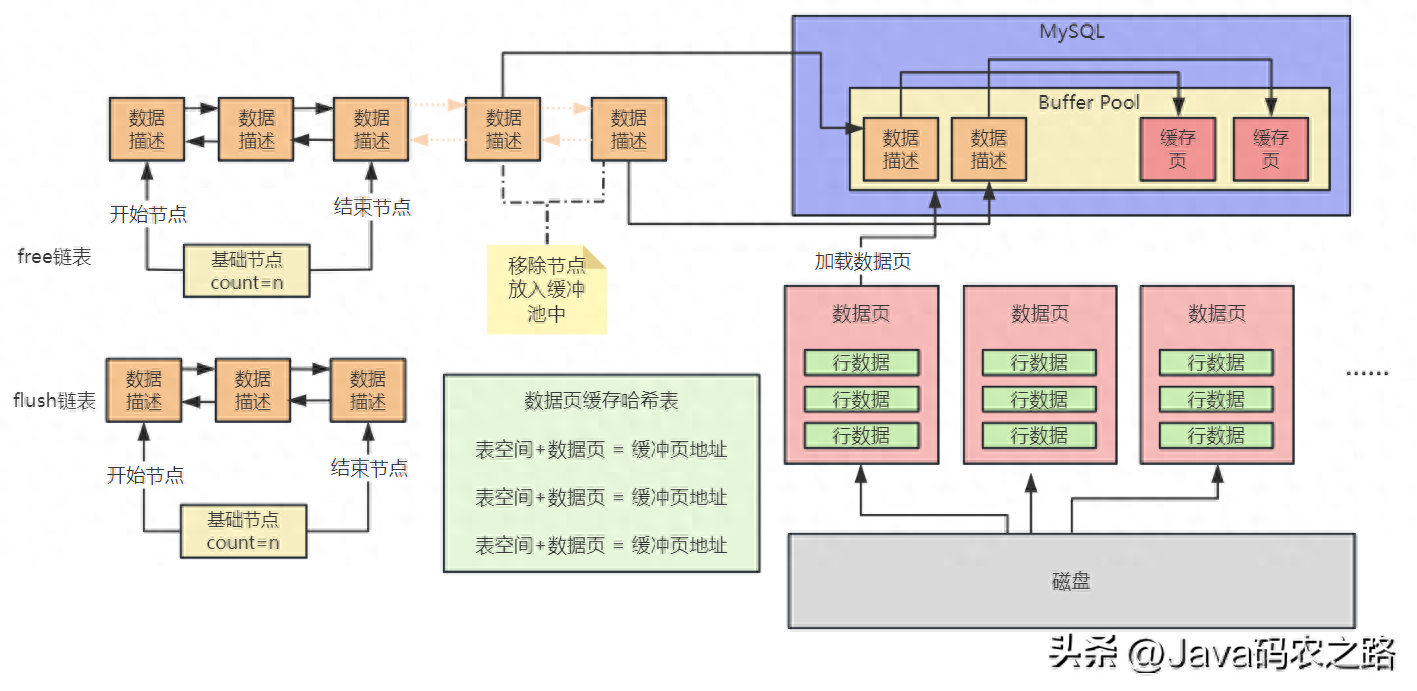
更新过的缓存页与磁盘不一致,需要刷到磁盘的缓冲页构成的双向链表;也叫待刷盘的脏页数据页链表;如下图所示
5. lru链表
如果所有的缓存页都被塞了数据了,此时无法从磁盘上加载新的数据页到缓存页里去了,那么此时你只有一个办法,就是淘汰掉一些缓存页。引入LRU链表来判断哪些缓存页是不常用的。这个所谓的LRU就是Least Recently Used,最近最少使用的意思。
假设某个缓存页的描述数据块本来在LRU链表的尾部,后续你只要查询或者修改了这个缓存页的数据,也要把这个缓存页挪动到LRU链表的头部去,也就是说最近被访问过的缓存页,一定在LRU链表的头部。如下图所示
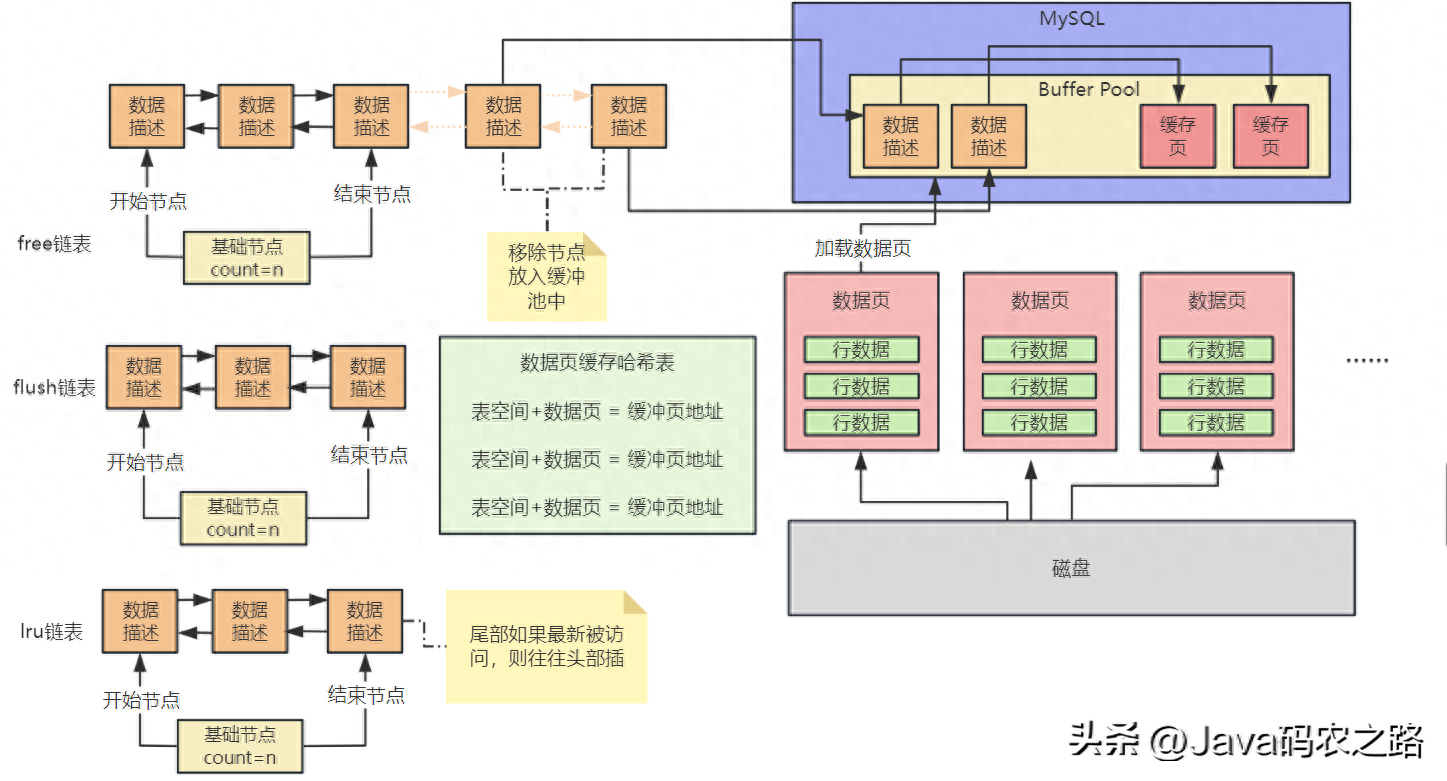
淘汰不常用的缓存页,尾部淘汰冷数据,头部插入热数据。
6. 数据页预读带来的问题
MySQL为提升读取性能,引入了预读机制,就是当从磁盘上加载一个数据页的时候,他可能会连带着把这个数据页相邻的其他数据页,也加载到缓存里去!
举个例子,假设现在有两个空闲缓存页,然后在加载一个数据页的时候,连带着把他的一个相邻的数据页也加载到缓存里去了,正好每个数据页放入一个空闲缓存页!但是接下来呢,实际上只有一个缓存页是被访问了,另外一个通过预读机制加载的缓存页,其实并没有人访问,此时这两个缓存页可都在LRU链表的前面。
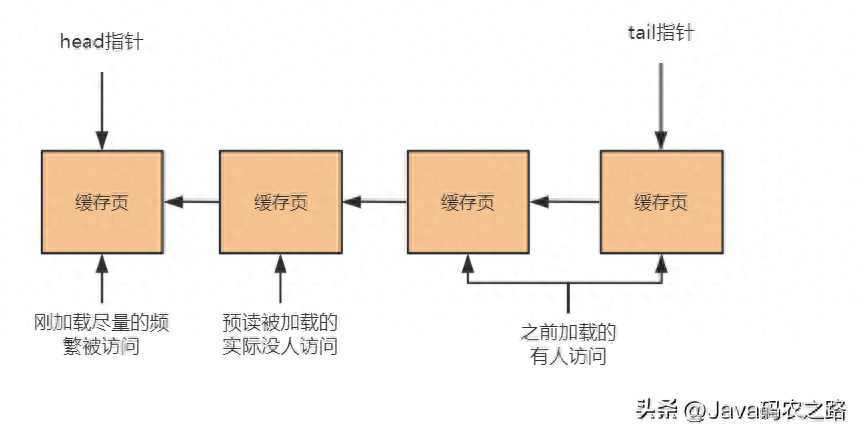
我们可以看到,这个图里很清晰的表明了,前两个缓存页都是刚加载进来的,但是此时第二个缓存页是通过预读机制捎带着加载进来的,他也放到了链表的前面,但是他实际没人访问他。除了第二个缓存页之外,第一个缓存页,以及尾巴上两个缓存页,都是一直有人访问的那种缓存页,只不过上图代表的是刚刚把头部两个缓存页加载进来的时候的一个LRU链表当时的情况。
哪些场景会导致预读呢?
(1)有一个参数是innodb_read_ahead_threshold,他的默认值是56,意思就是如果顺序的访问了一个区里的多个数据页,访问的数据页的数量超过了这个阈值,此时就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存里去。
(2)如果Buffer Pool里缓存了一个区里的13个连续的数据页,而且这些数据页都是比较频繁会被访问的,此时就会直接触发预读机制,把这个区里的其他的数据页都加载到缓存里去。
这个机制是通过参数innodb_random_read_ahead来控制的,他默认是OFF,也就是这个规则是关闭的。
(3)接着我们讲另外一种可能导致频繁被访问的缓存页被淘汰的场景,那就是全表扫描。
这个所谓的全表扫描,意思就是类似如下的SQL语句:SELECT * FROM USERS,此时他没加任何一个where条件,会导致他直接一下子把这个表里所有的数据页,都从磁盘加载到Buffer Pool里去。这个时候他可能会一下子就把这个表的所有数据页都一一装入各个缓存页里去!此时可能LRU链表中排在前面的一大串缓存页,都是全表扫描加载进来的缓存页!那么如果这次全表扫描过后,后续几乎没用到这个表里的数据呢?此时LRU链表的尾部,可能全部都是之前一直被频繁访问的那些缓存页!然后当你要淘汰掉一些缓存页腾出空间的时候,就会把LRU链表尾部一直被频繁访问的缓存页给淘汰掉了,而留下了之前全表扫描加载进来的大量的不经常访问的缓存页。
7. 解决预读带来的问题
所以为了解决上一讲我们说的简单的LRU链表的问题,真正MySQL在设计LRU链表的时候,采取的实际上是冷热数据分离的思想。
所以真正的LRU链表,会被拆分为两个部分,一部分是热数据,一部分是冷数据,这个冷热数据的比例是由innodb_old_blocks_pct参数控制的,他默认是37,也就是说冷数据占比37%。
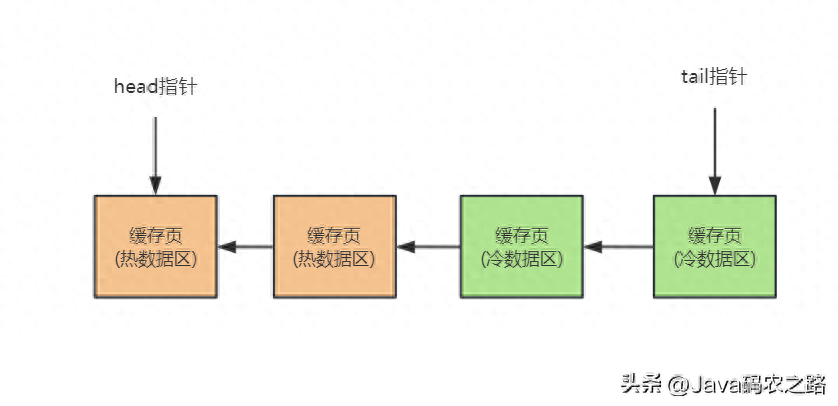
第一次被加载了数据的缓存页,都会不停的移动到冷数据区域的链表头部。冷数据区域的缓存页什么时候会放到热数据区域呢?实际上肯定很多人会想,只要对冷数据区域的缓存页进行了一次访问,就立马把这个缓存页放到热数据区域的头部行不行呢?
其实这也是不合理的,如果你刚加载了一个数据页到那个缓存页,他是在冷数据区域的链表头部,然后立马(在1ms以内)就访问了一下这个缓存页,之后就再也不访问他了呢?难道这种情况你也要把那个缓存页放到热数据区域的头部吗?
所以MySQL设定了一个规则,他设计了一个innodb_old_blocks_time参数,默认值1000,也就是1000毫秒。也就是说,必须是一个数据页被加载到缓存页之后,在1s之后,你访问这个缓存页,他才会被挪动到热数据区域的链表头部去。因为假设你加载了一个数据页到缓存去,然后过了1s之后你还访问了这个缓存页,说明你后续很可能会经常要访问它,这个时间限制就是1s,因此只有1s后你访问了这个缓存页,他才会给你把缓存页放到热数据区域的链表头部去。
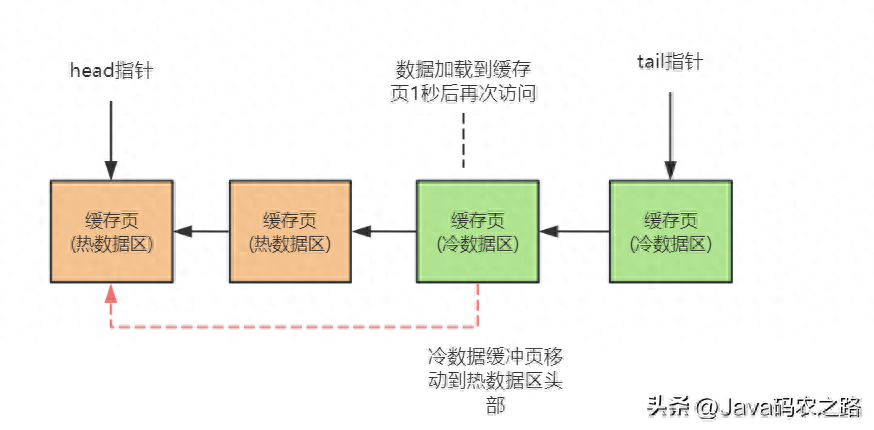
该思想通过冷热分离+时间访问限制,解决了误淘汰热数据的问题。吸收冷热隔离思想,结合项目场景,可以优化缓存中的冷热数据。
LRU链表的热数据区域是如何进行优化的呢?
热数据区域里的缓存页可能是经常被访问的,所以这么频繁的进行移动是不是性能也并不是太好?也没这个必要。
所以说,LRU链表的热数据区域的访问规则被优化了一下,即你只有在热数据区域的后3/4部分的缓存页被访问了,才会给你移动到链表头部去。如果你是热数据区域的前面1/4的缓存页被访问,他是不会移动到链表头部去的。举个例子,假设热数据区域的链表里有100个缓存页,那么排在前面的25个缓存页,他即使被访问了,也不会移动到链表头部去的。但是对于排在后面的75个缓存页,他只要被访问,就会移动到链表头部去。这样的话,他就可以尽可能的减少链表中的节点移动了。
本节主要讲了三链表的作用,free链表记录空闲缓存页,flush链表记录脏页,即待刷盘缓存页,当free链表没有空闲时,lru链表淘汰最近不常用的缓存页。三链表动态执行过程可以表述为:free链表移除结点,lru链表冷数据区头部加入该节点;如果修改了缓存页,flush加入这个脏页,lru表中还可能会从冷数据区域移动到热数据区域的头部去;如果查询了缓存页,会把这个缓存页在lru链表中移动到热数据区域去,或者在热数据区域中也有可能会移动到头部去。总之,要么free链表移除节点,flush链表加节点,lru链表移动节点;要么free加节点,flush减节点,lru减节点。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK