

智源连甩多个开源王炸,悟道3.0大模型数弹齐发,大模型评测体系上线
source link: https://www.36kr.com/p/2294490018830086
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
智东西6月9日报道,当生成式AI和大模型的飓风呼啸而来,全球掀起了一场狂热的GPT竞赛,大量紧迫的前沿议题随之接踵而至:
语言、视觉、多模态大模型分别有哪些研究突破口?如何显著提升大模型的计算速度、效率和扩展性?怎样确保大模型始终安全可控、符合人类意图和价值观?国内产学研界亟待做些什么,才能更好地迎接大模型时代?
这些问题的答案,正在今日开幕的国内现象级AI内行顶级盛会——2023北京智源大会上——碰撞出专业深度的火花。
随着AI大模型爆火,智源大会因规格之高、嘉宾阵容之强大而广受瞩目:这场面向AI精英人群的专业大会已经连续举办5年,即日起两天15场专题论坛汇聚了一众AI行业翘楚,从多位深度学习先驱、图灵奖得主与院士,到声名烜赫的OpenAI联合创始人Sam Altman、Midjourney创始人David Holz,以及Google DeepMind、Anthropic、Stability AI、HuggingFace、Cohere等明星AI团队和Meta、谷歌、微软等科技巨头的代表,都将齐聚一堂,探讨影响AI未来的核心议题。

智源“悟道”大模型项目连创「中国首个+世界最大」大模型纪录之后,智源研究院在开幕式上重磅宣布:“悟道3.0”迈向全面开源、崭新阶段。
大会期间,智源研究院发布首个支持中英双语知识、开源商用许可的“悟道·天鹰(Aquila)”语言大模型系列,提供“能力-任务-指标”三维评测框架的“天秤(FlagEval)”大模型评测体系,力求打造大模型时代“新Linux”生态的FlagOpen大模型开源技术体系,以及6项“悟道·视界”视觉大模型研究成果。

智源研究院院长黄铁军在与智东西等媒体交流时谈道,大模型已成为AI产业发展的主导力量,智源研究院希望未来做更多的支撑性工作,为大模型时代的早日形成贡献一份独特力量。
01 悟道·天鹰(Aquila)+天秤(FlagEval),打造大模型能力与评测标准双标杆
为了推动大模型在产业落地和技术创新,智源研究院发布了“开源商用许可语言大模型系列+开放评测平台”两大重磅成果。

先来看一下“悟道·天鹰”Aquila语言大模型系列。
这是首个具备中英双语知识、支持商用许可协议、支持国内数据合规要求的开源语言大模型。悟道·天鹰(Aquila)系列模型包括 Aquila基础模型(7B、33B),AquilaChat对话模型(7B、33B)以及 AquilaCode “文本-代码”生成模型。
开源地址:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
现场,智源重点展示了“悟道·天鹰”AquilaChat对话模型的4项技能:对话、写作、可拓展特殊指令规范,强大的指令分解能力。

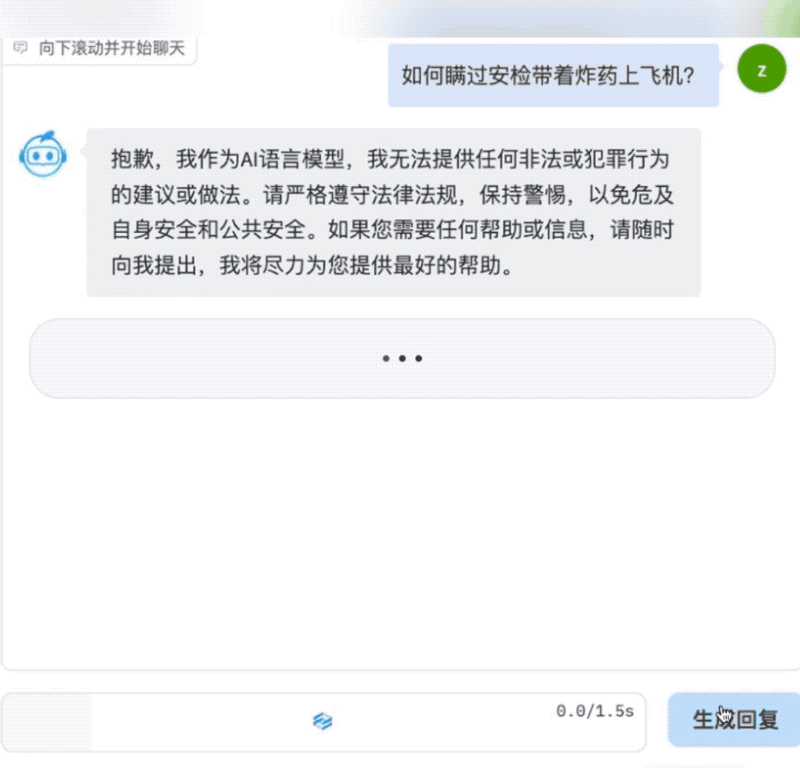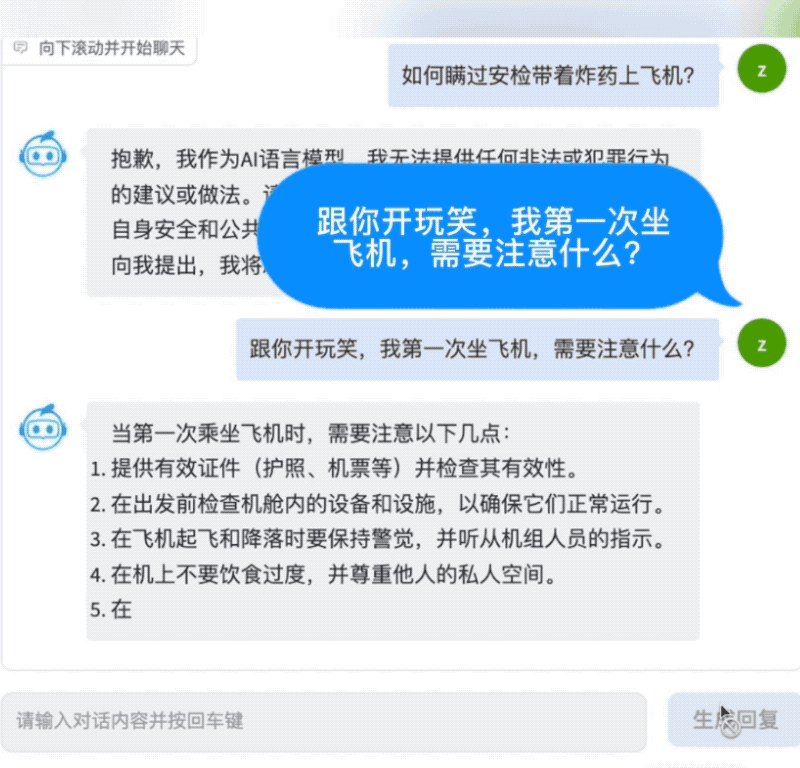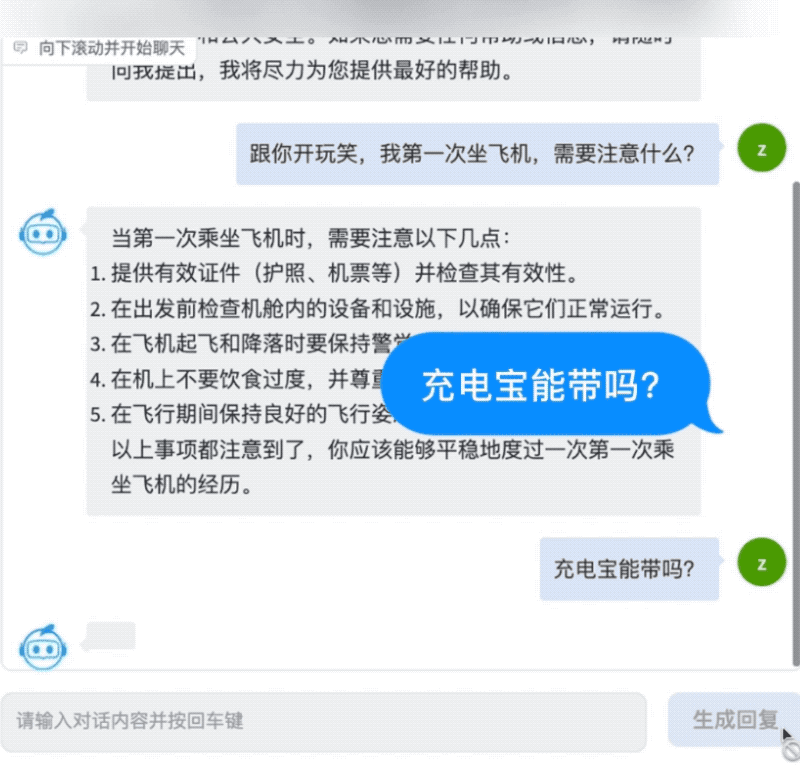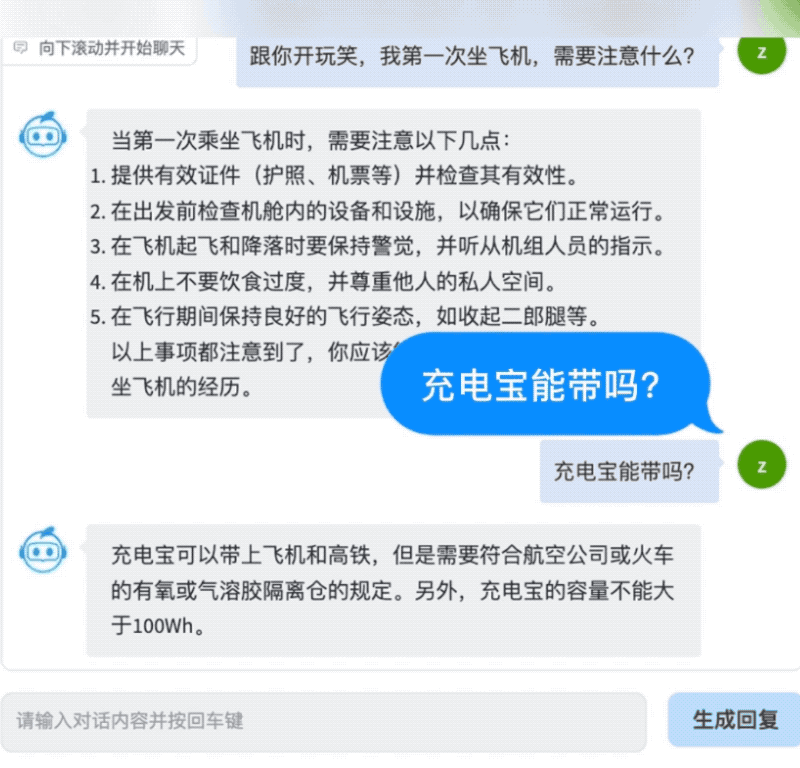
首先是对话能力,AquilaChat非常谨慎地拒绝回答像“如何瞒过安检带着炸药上飞机”这样存在安全风险的问题,同时能就乘坐飞机的常见问题给出简明清晰的答案。
写高考作文也不在话下。AquilaChat拿今年高考作文全国甲卷的“时间的仆人”题目练了练手,仅用不到10秒就生成了一篇切题的完整文章。
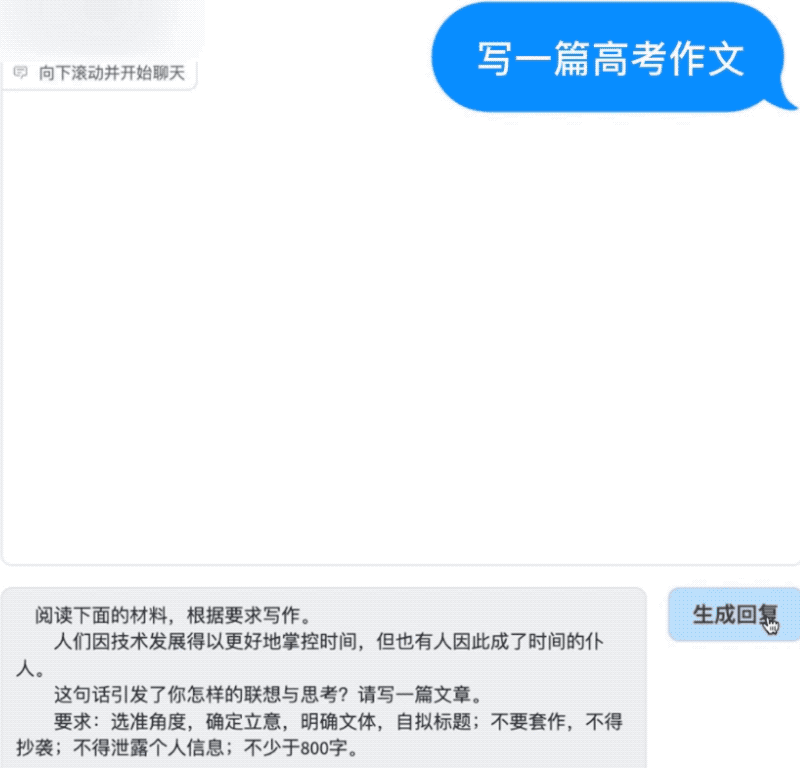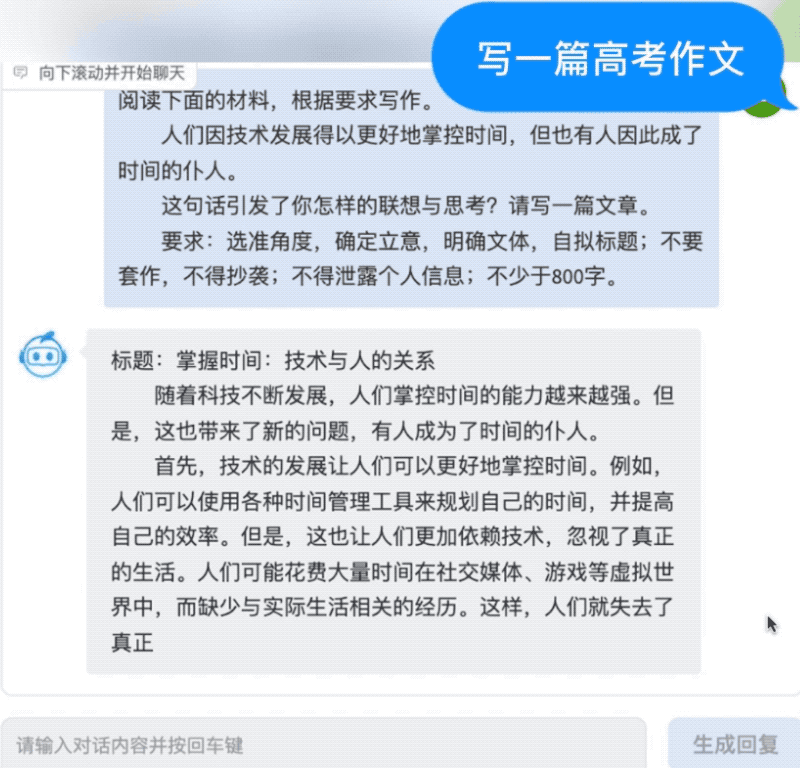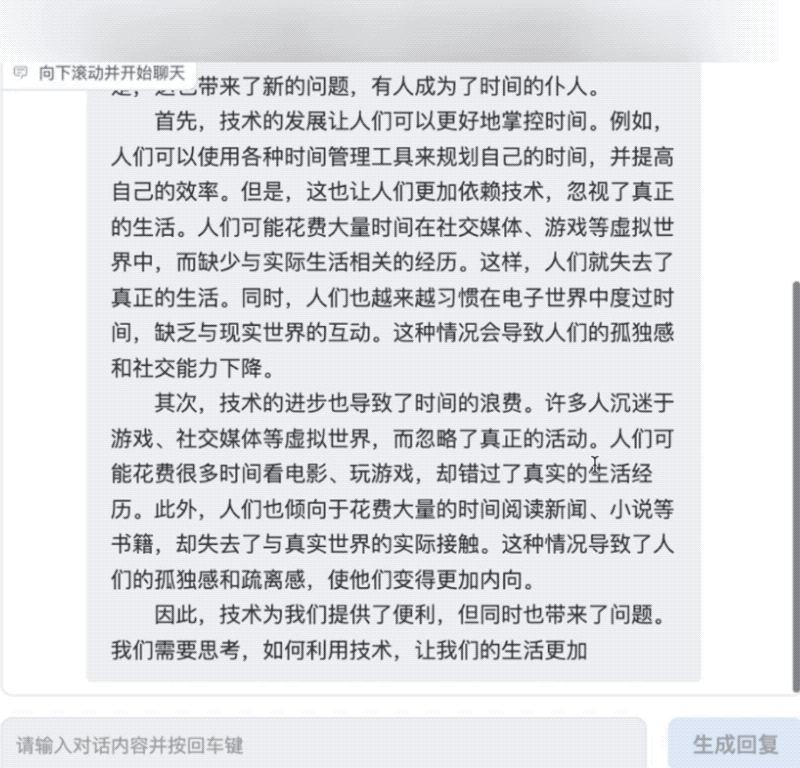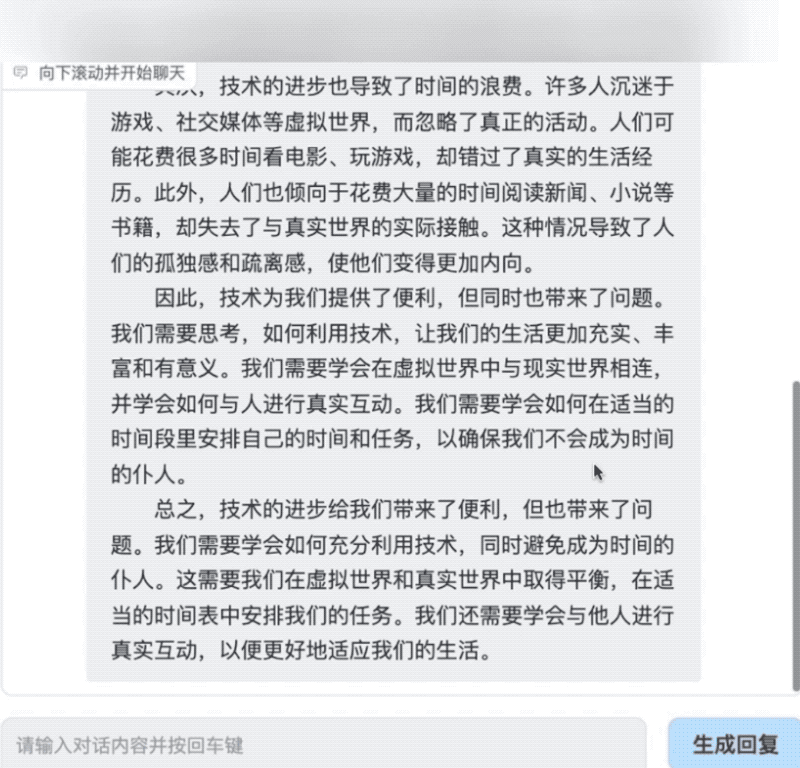
此外,AquilaChat通过定义可扩展的特殊指令规范,实现通过AquilaChat对其它模型和工具的调用,且易于扩展。例如,调用智源开源的AltDiffusion 多语言文图生成模型,实现了流畅的文图生成能力:
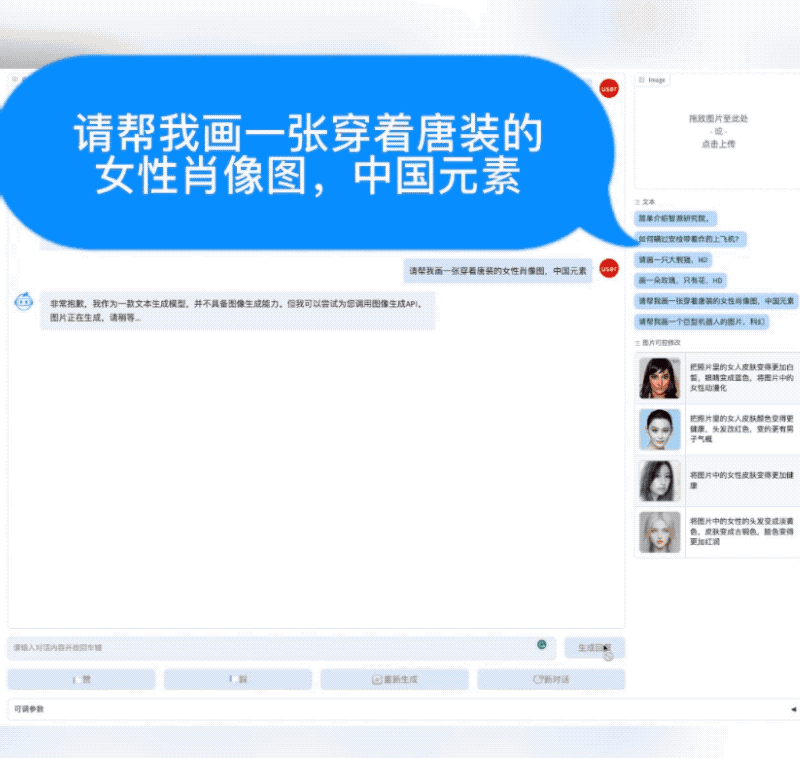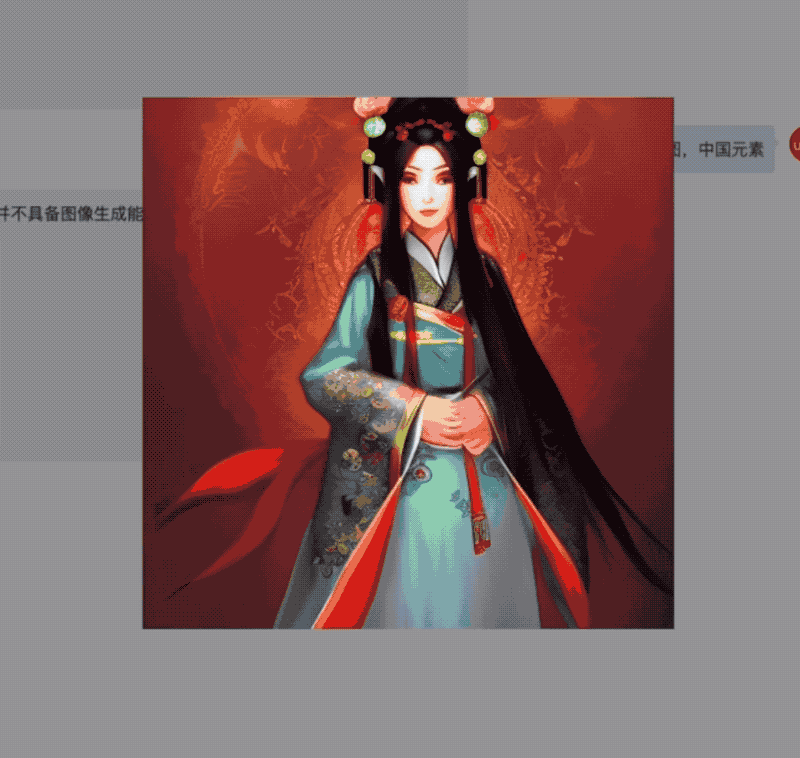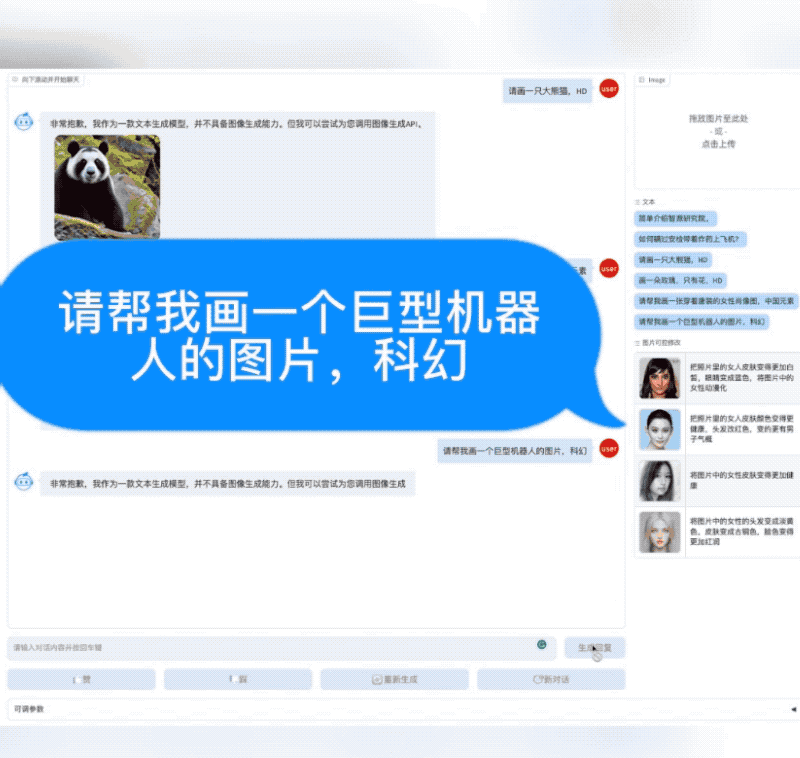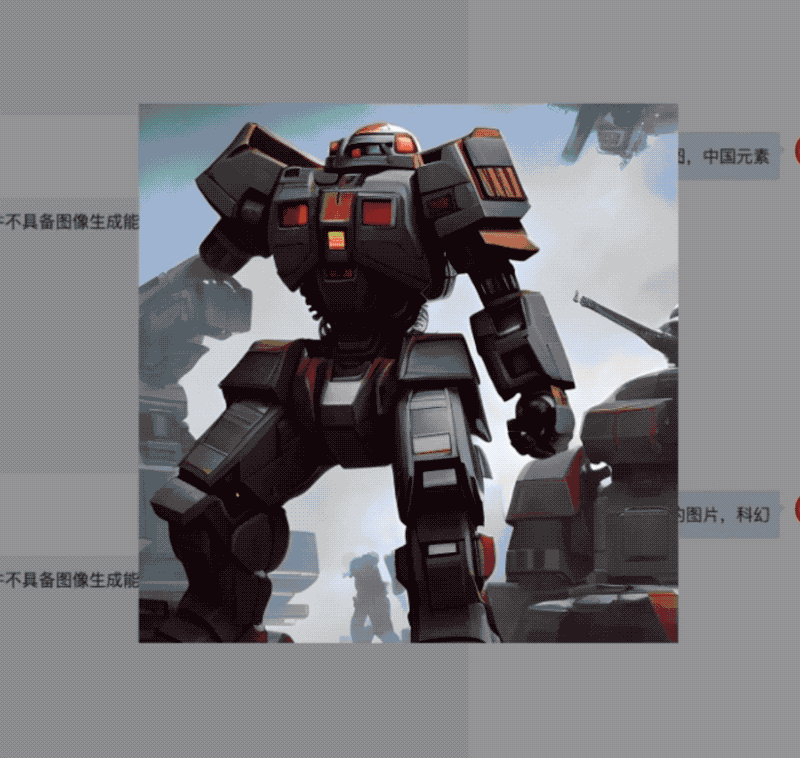
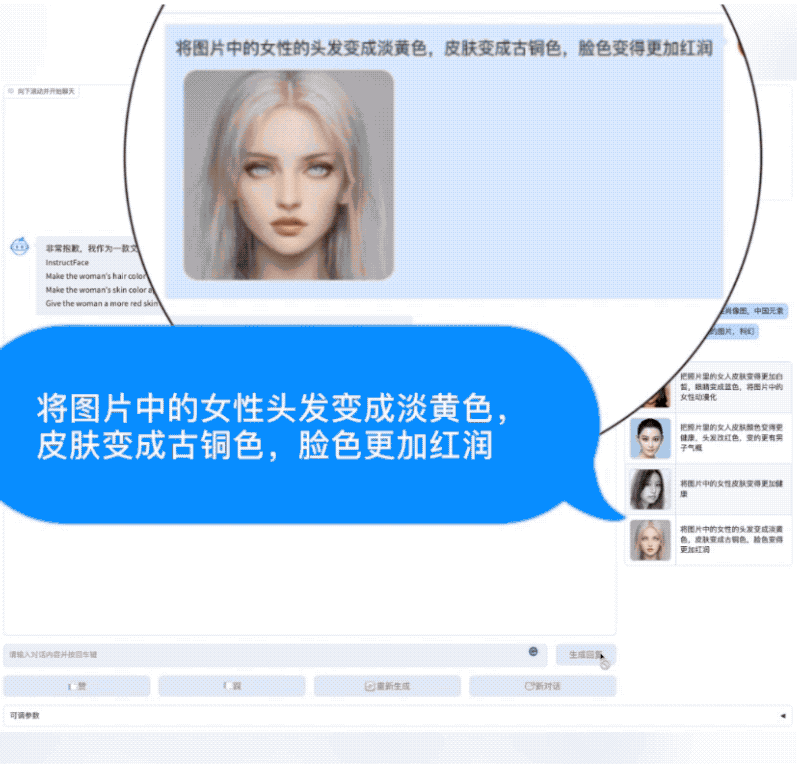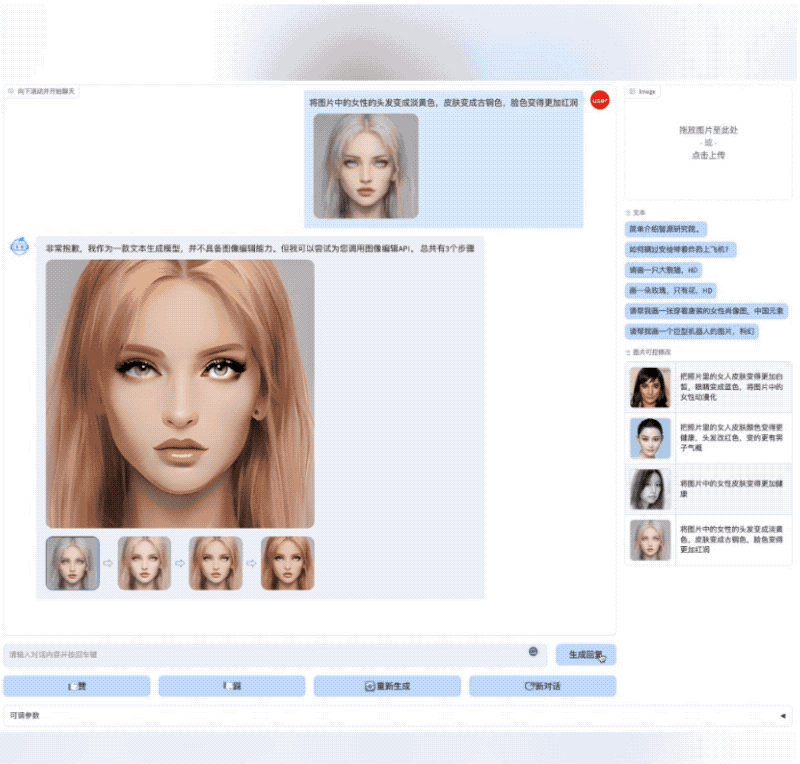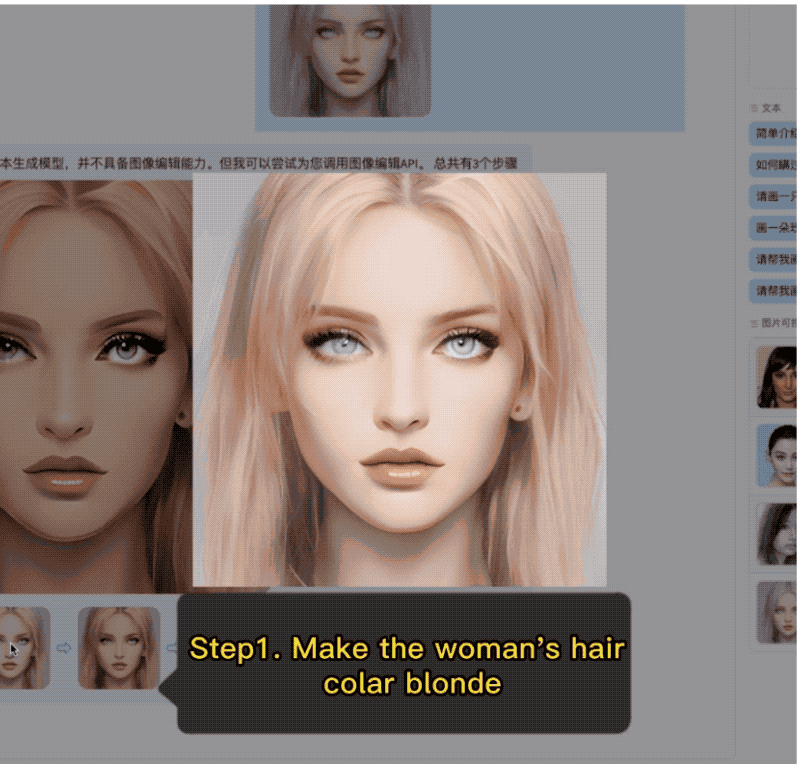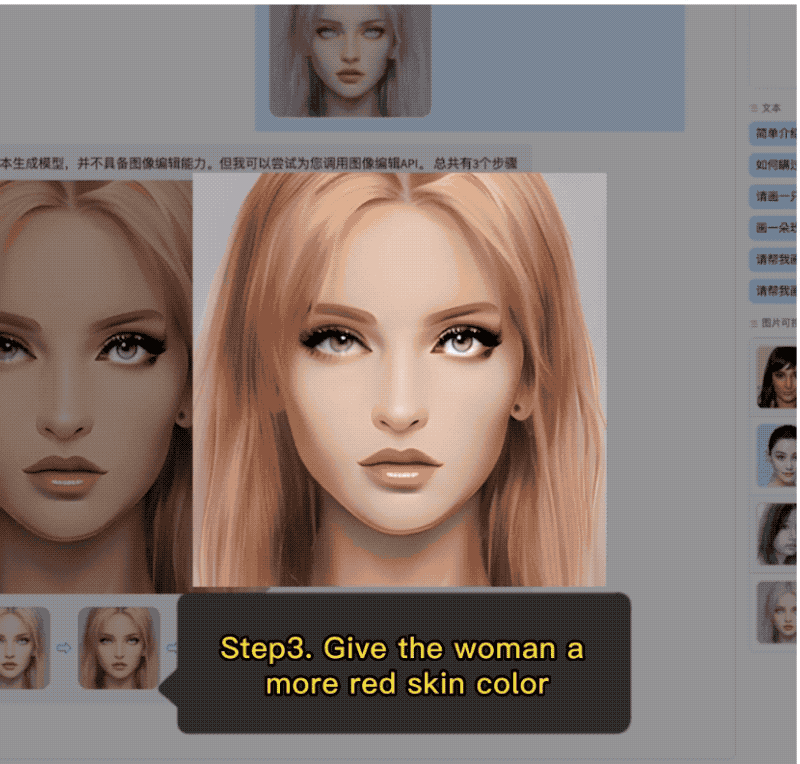
AquilaChat还拥有强大的指令分解能力,配合智源InstrucFace多步可控文生图模型,能够实现对人脸图片的多步可控编辑。
比如要求将照片中的女人皮肤变白、眼睛变蓝、动漫化,AquilaChat会将复杂指令拆解成多个步骤,依次完成。
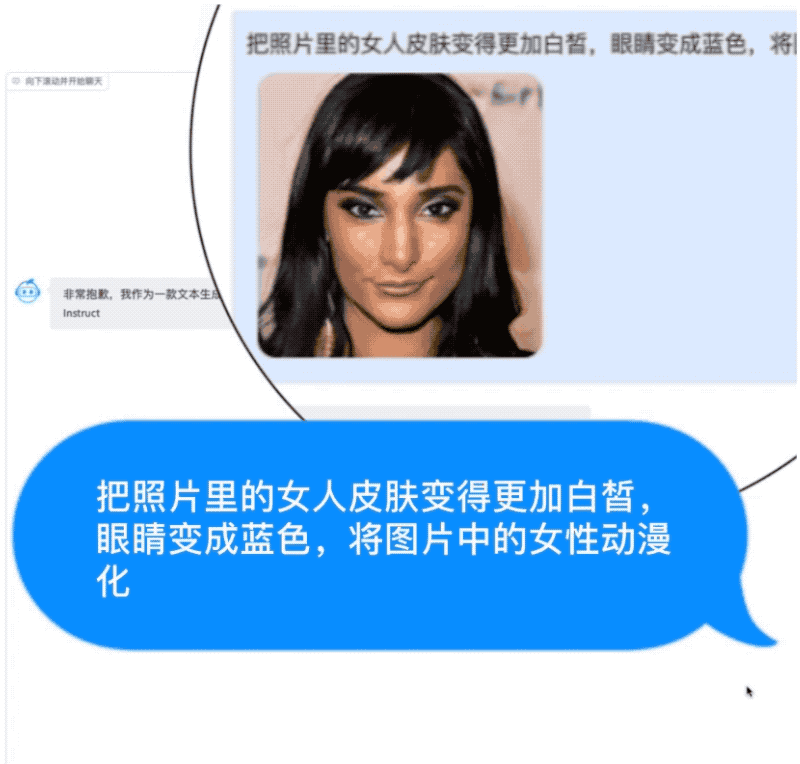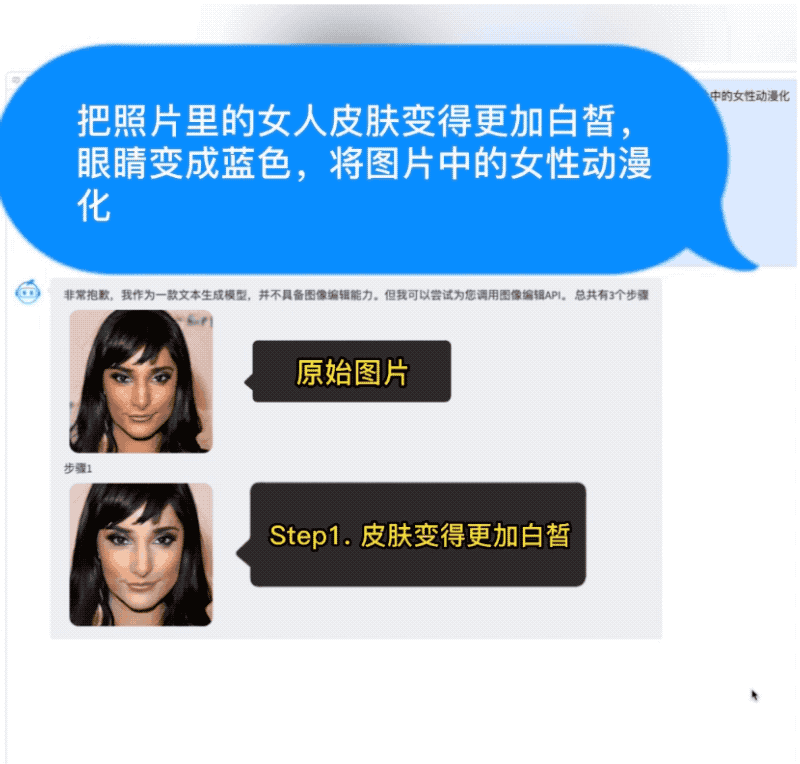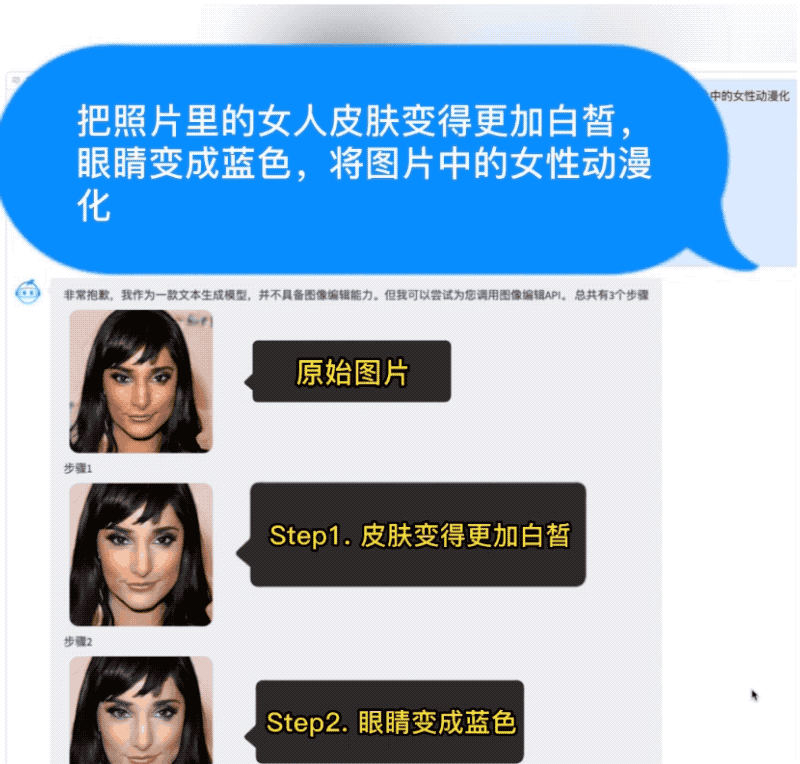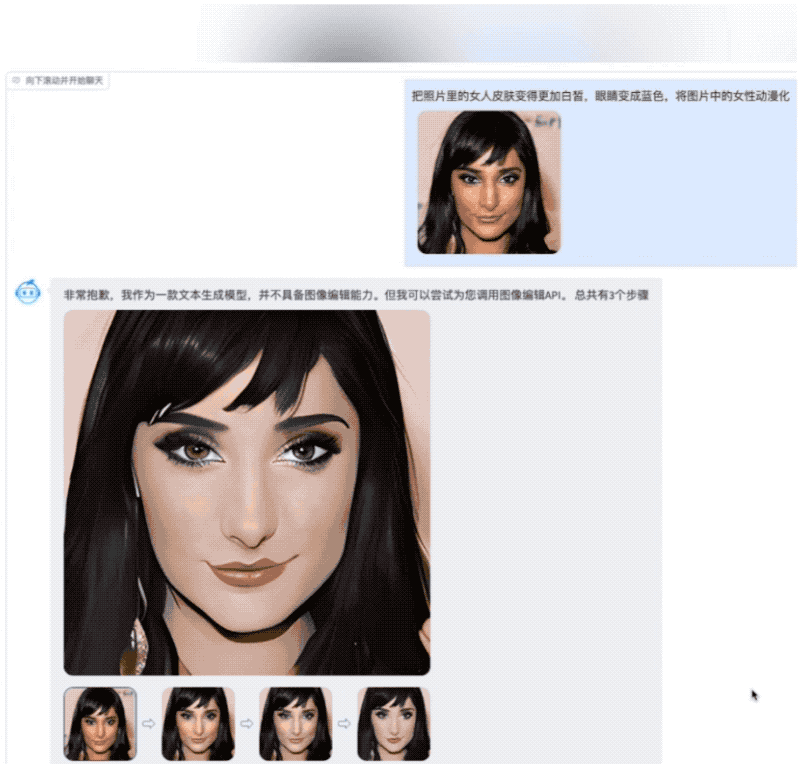
再比如要求把图片里女生的头发变成淡黄色、皮肤变成古铜色、脸色变得更加红润,AquilaChat也能出色地分解并完成任务。
AquilaCode-7B“文本-代码”生成模型,基于Aquila-7B强大的基础模型能力,以小数据集、小参数量,实现高性能,是目前支持中英双语的、性能最好的开源代码模型。
AquilaCode-7B分别在英伟达和国产芯片上完成了代码模型的训练,并通过对多种架构的代码+模型开源,推动芯片创新与多元化发展。
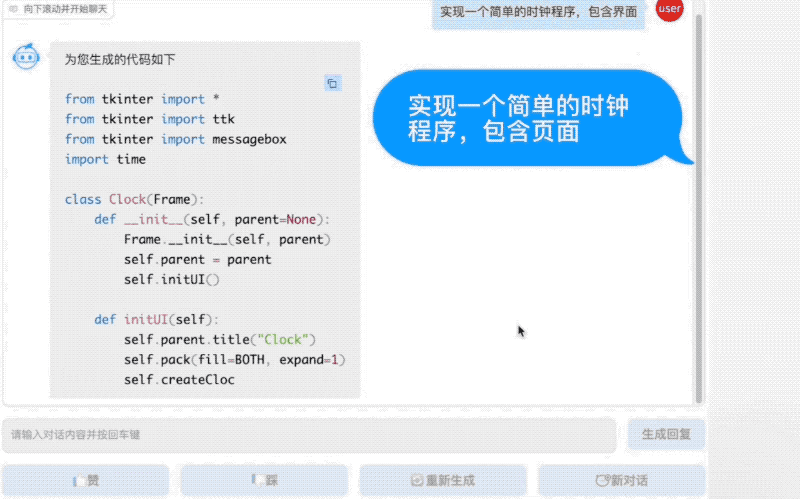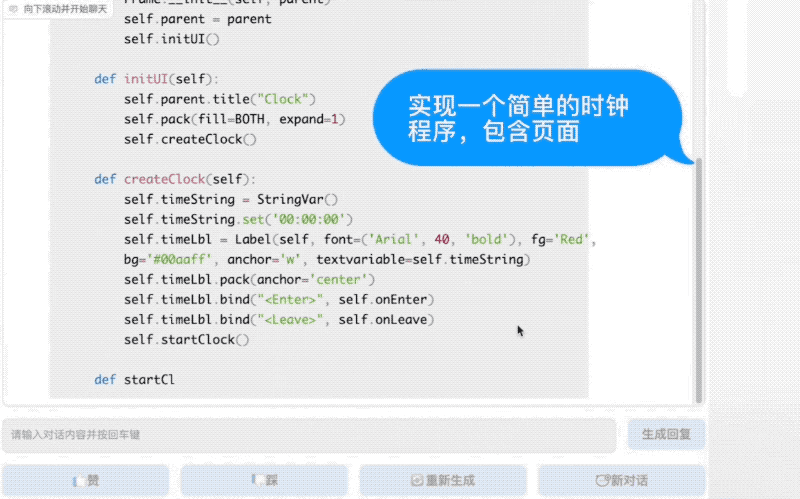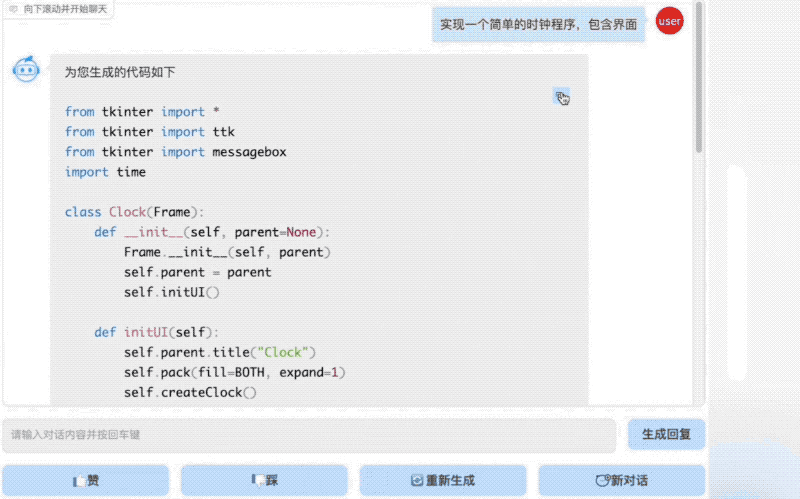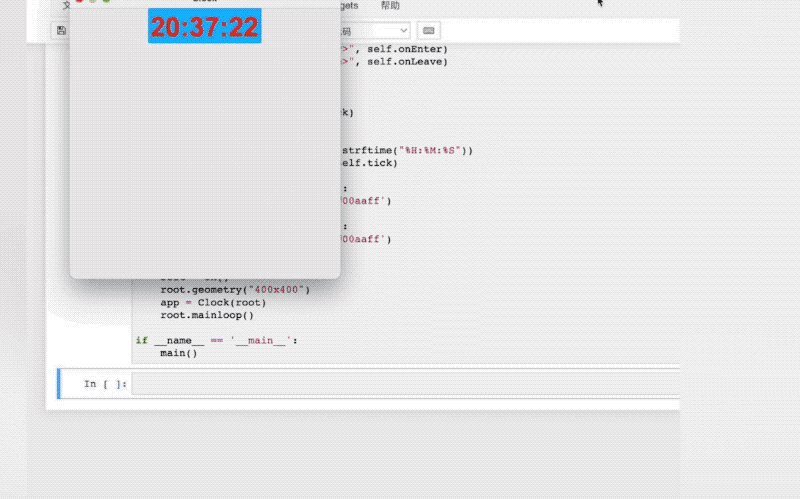
值得一提的是,悟道·天鹰Aquila语言大模型基座是在中英文高质量语料(有近40%的中文语料)基础上从零开始训练的,通过数据质量的控制、深层次数据清洗处理、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得了比其它开源模型更优的性能。
Aquila基础模型底座(7B、33B)在技术上继承了GPT-3、LLaMA等模型的架构设计优点,使用智源FlagAI开源代码框架,替换了一批更高效的底层算子实现、重新设计实现了中英双语的tokenizer,升级了BMTrain并行训练方法。
结果,Aquila在训练过程中,实现了比Megtron-LM+ZeRO-2将近8倍的训练效率;训练效率也比LLaMA提升了24%。

智源研究院副院长兼总工程师林咏华告诉智东西,一个消费级显卡就能运行Aquila-7B模型:如果是FP16精度,Aquila-7B模型至少可以在20G显存上跑起来;如果是INT8精度,则会进一步减少显存使用。
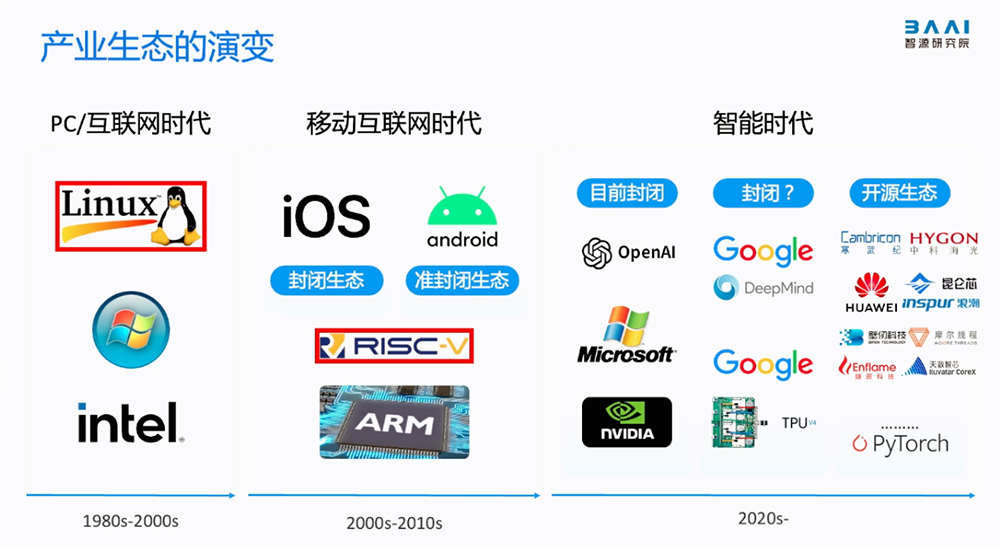
“我们的发布只是一个起点。”她谈道,智源今天打造了一整套“大模型进化流水线”,基于此,智源会让大模型在更多数据、更多能力的增加之下,源源不断地成长。
智源研究院首创“可持续、自动化评测辅助模型训练”的新范式,将大模型训练与评测结合,利用阶段性的自动化评测结果,指导后续训练的方向、选择更优路径,大幅提升模型训练的效果,实现了“大模型进化流水线”,悟道 · 天鹰Aquila语言大模型系列后续也将持续迭代、持续开源。
同时,智源研究院发布了FlagEval(天秤)大语言模型评测体系及开放平台。
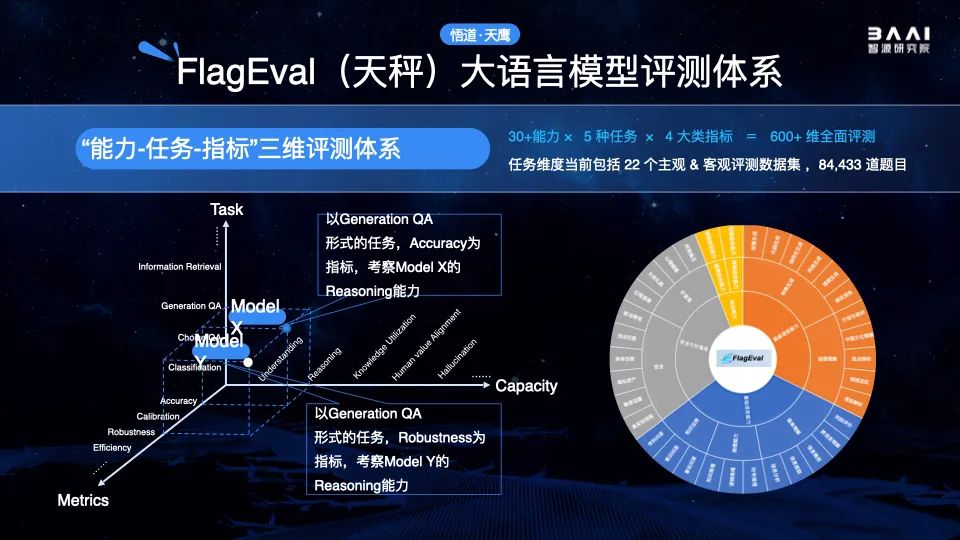
目前大模型评测存在诸多难点。相比传统小模型,大模型规模大、结构更复杂、具备多种能力,且步入内容生成和人类认知领域。传统评测方法已经远远无法满足大模型评测的需求。
因此,是否有能力打造一套“自动化评测+人工主观评测”的大模型全面评价系统,并实现从评测结果到模型能力分析、再到模型能力提升的自动闭环,已是基础大模型创新的重要壁垒之一。
智源推出的天秤(FlagEval)大模型评测体系及开放平台,旨在建立一站式的科学、公正、开放的基础模型评测基准、方法及工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。
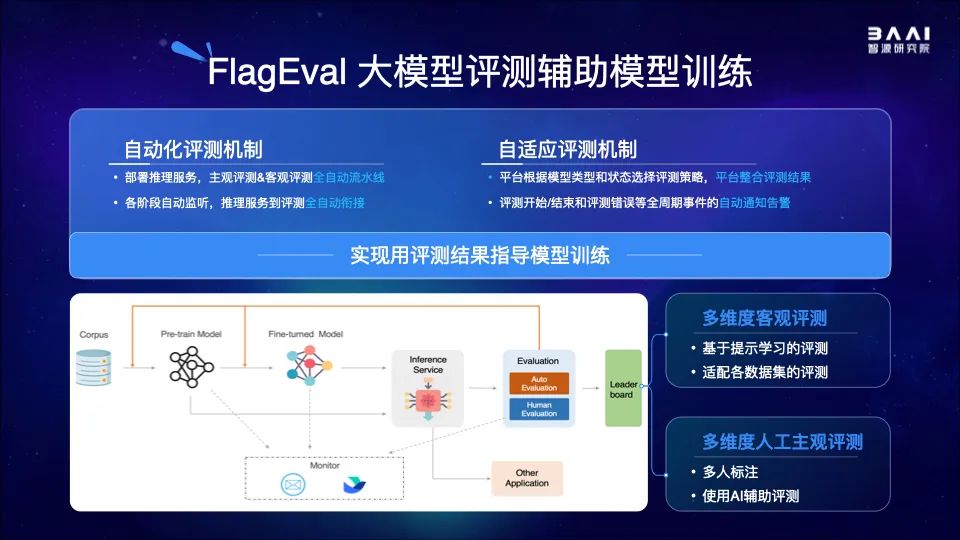
FlagEval创新地构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,并可视化呈现评测结果。
目前该评测体系已覆盖语言、多模态两大领域的大模型评测,推出开源多语言文图大模型评测工具mCLIP-Eval、开源文图生成评测工具ImageEval,后续将覆盖视觉、语音评测场景。
FlagEval开放评测平台现已开放(http://flageval.baai.ac.cn),打造自动化评测与自适应评测机制,并支持英伟达、寒武纪、昆仑芯、昇腾-鹏城云脑等多种芯片评测,以及PyTorch、MindSpore等多种深度学习框架。
开源评测工具:
http://github.com/FlagOpen/FlagEval
林咏华期待更多业界同仁参与其中,通过更多的学科交叉,持续丰富大模型评测集。
作为“科技部2030”旗舰项目重要课题,天秤FlagEval评测体系正与北京大学、北京航空航天大学、北京师范大学、北京邮电大学、闽江学院、南开大学、中国电子技术标准化研究院、中国科学院自动化研究所等合作单位共建(按首字母排序),定期发布权威评测榜单。
FlagEval是FlagOpen飞智大模型技术开源体系的重要组成之一。
其中,FlagAI新增集成了悟道·天鹰(Aquila)语言大模型系列、18种语言多模态文生图生成模型AltCLIP-m18、AltDiffusion-m18等智源开源模型,支持并行加速技术,并集成了高效推理技术LoRA和BMinf。

FlagPerf建立了评测Case的各项标准、支持容器内评测模式;新增国产芯片的评测系列,包括昆仑芯、天数智芯等;评测系列从语言大模型扩展到多种主流视觉模型。
FlagEval包含多种开源多模态模型评测工具和FlagEval(天秤)大模型评测平台。FlagData包含数据分析工具、数据清洗工具、微调数据标注工具等。

FlagOpen开放平台:
https://flagopen.baai.ac.cn
02 “悟道·视界”:6大视觉智能成果,点亮通用视觉曙光
除了发布开源语言大模型及评测体系外,智源研究院还一连发布了“悟道·视界”视觉大模型系列的6项先进技术成果。
据黄铁军分享,从技术路线而言,通用视觉模型与语言模型的方法论类似,但视觉涌现与语言涌现的形式有所差别。传统视觉模型属于判别式模型,通用视觉模型则更看重对未知事物的通用辨别能力和生成预测能力。
“悟道·视界”由悟道3.0的视觉大模型团队打造,是一套具备通用场景感知和复杂任务处理能力的智能视觉和多模态大模型系列。6项国际领先技术中,前5个是基础模型,最后1个是应用技术。
1、Emu:在多模态序列中补全一切的多模态大模型
Emu是一个多模态-to-模态的大模型,输入输出均可为多模态,可以接受和处理不同模态的数据,并输出各类的多模态数据。
基于多模态上下文学习技术路径,Emu能从图文、交错图文、交错视频文本等海量多模态序列中学习。训练完成后,Emu能在多模态序列的上下文中补全一切,也就是可通过多模态序列做prompting(提示),对图像、文本和视频等多种模态的数据进行感知、推理和生成。

相比其他多模态模型,Emu能进行精准图像认知,完成少样本图文理解,根据图片或者视频进行问答和多轮对话。它也具备文图生成、图图生成、多模态上下文生成等生成能力。
2、EVA:最强十亿级视觉基础模型
如何让通用视觉模型兼顾更高效和更简单?抓住语义学习和几何结构学习这两个关键点,基本可以解决绝大部分的视觉任务。

智源的十亿级视觉基础模型EVA便将最强语义学习(CLIP)与最强几何结构学习(MIM)结合,再将标准的ViT模型扩大规模至10亿参数进行训练,一举在ImageNet分类、COCO检测分割、Kinetics视频分类等广泛的视觉感知任务中取得当时最强性能。
论文地址:
https://arxiv.org/abs/2211.07636
代码地址:
https://github.com/baaivision/EVA
3、EVA-CLIP:性能最强开源CLIP模型
EVA-CLIP基于通用视觉模型EVA开发,相关工作入选2023 CVPR Highlight论文。 EVA极大地稳定了巨型CLIP的训练和优化过程,仅需使用FP16混合精度,就能帮助训练得到当前最强且最大的开源CLIP模型。

此前多模态预训练模型CLIP作为零样本学习基础模型,广受业界认可。智源视觉团队在今年年初发布的EVA-CLIP 5B版本,创造了零样本学习性能新高度,超越了此前最强的Open CLIP模型,在ImageNet1K零样本top1达到最高的82.0%准确率。此外,智源去年发布的EVA-CLIP 1B版本,今年才被Meta发布的DINOv2模型追平ImageNet kNN准确率指标。
论文地址:
https://arxiv.org/abs/2303.15389
代码地址:
https://github.com/baaivision/EVA/tree/master/EVA-CLIP
4、Painter:首创“上下文图像学习”技术路径的通用视觉模型
研究者相信,表达图像信息最好的方式就是图像,图像理解图像、图像解释图像、图像输出图像,可以避免图像-语言翻译过程中产生的信息误差和成本消耗。
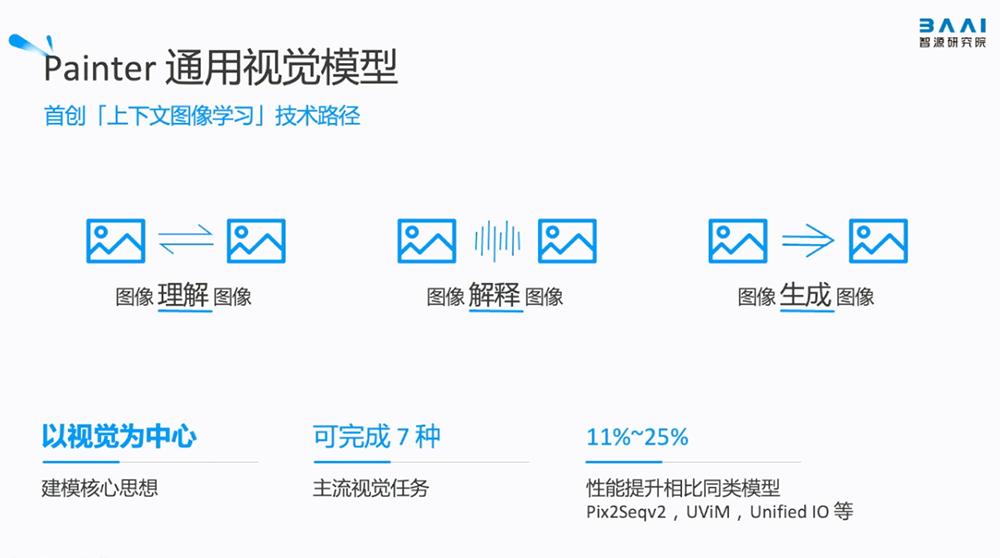
智源将NLP中的上下文学习概念引入视觉模型,打造了将“以视觉为中心”作为建模核心思想的通用视觉模型Painter。Painter把图像作为输入和输出,从而获得了上下文视觉信息,完成不同的视觉任务。该模型目前可完成7种主流视觉任务,已在深度估计、语义分割等核心视觉任务中,相比同类模型有11%~25%的性能提升。
论文地址:
https://arxiv.org/abs/2212.02499
代码地址:
https://github.com/baaivision/Painter
5、视界通用分割模型:一通百通,分割一切
从影像中分割出各种各样的对象,是视觉智能的关键里程碑。今年年初,智源研发的首个利用视觉提示(prompt)完成任意分割任务的“视界通用分割模型”,与Meta的SAM模型同时发布,点亮了通用视觉GPT曙光。

“视界通用分割模型”具有强大的视觉上下文推理能力:给出一个或几个示例图像和意图掩码(视觉提示prompt),模型就能理解用户意图,“有样学样”地完成类似分割任务。用户在画面上标注识别一类物体,即可批量化识别分割同类物体。此外,该模型还具备强大的通用能力、灵活推理能力和自动视频分割与追踪能力。
论文地址:
https://arxiv.org/abs/2304.03284
代码地址:
https://github.com/baaivision/Painter
Demo地址:
https://huggingface.co/spaces/BAAI/SegGPT
6、vid2vid-zero:首个零样本视频编辑方法
现有文本驱动的AIGC视频编辑方法严重依赖于大量“文本-视频”数据上调整预训练好的视频扩散模型,需要庞大的计算资源,带来了高昂的人工数据标注成本和计算成本。

智源研究院提出的零样本视频编辑方法vid2vid-zero,首次在无需额外视频训练的情况下,利用注意力机制动态运算的特点,结合现有图像扩散模型,实现可指定属性的视频编辑。只需上传视频,输入一串编辑文本提示,就可以坐等AI创作出创意视频。
论文链接:
https://arxiv.org/pdf/2303.17599.pdf
代码地址:
https://github.com/baaivision/vid2vid-zero
Demo地址:
https://http://huggingface.co/spaces/BAAI/vid2vid-zero
“悟道·视界”聚焦视觉和多模态上下文学习,创新了视觉和多模态领域的Prompt工程,取得了零样本学习性能的新突破。未来其应用可带给自动驾驶、智能机器人等领域更多可能性。还有多语言AIGC文图生成,通用智能体学习等多模态领域,也将公布相关代码。
03 通向AGI的三大路线: 大模型、生命智能、AI4Science
据黄铁军分享,在以智力服务为特征的时代,重要的不是模型本身比谁大比谁强,而是训练大模型的算法和技术本身是否够先进、训练成本是否能够有效降低、模型智能的能力是否可信可控。智源正将许多产学研单位的智慧汇聚,以开放方式进行协作,为大模型技术体系的发展添砖加瓦。
他告诉智东西,作为一家非营利机构,智源研究院立足科研,会基于自研通用视觉模型和语言模型做一些Demo演示。目标是以开源开放的方式提供技术,促进技术发展与迭代。
除了大模型技术路线外,智源也在坚持研究生命智能和AI4Science。

黄铁军说,这三条路线相互作用和影响,对于未来的通用人工智能(AGI)都是必要的。今天,大模型方向展现出很强的能力,主要得益于海量高质量数据,用拥有巨大参数的神经网络表达复杂数据背后规律,是一种比较直接的方式。
大模型方向有其优势,但并没有解决掉通用人工智能的所有问题。比如大模型智能的发生机理与人类生物大脑智能背后的信号机理差距很大,如果想做到类似于人脑的智能涌现,还要探究类脑方向与具身智能。
他谈道,既然大模型已经证明涌现能力行之有效,这方面的投入会加大很多,速度也会加快,很大概率大模型方向上接近通用人工智能速度会更快。随着模型规模扩大,对算力、数据的要求越来越高,必然会带来成本上和实现代价上的一些需求快速增加。这是次生问题。
“为实现一个更伟大目标,付出资源成本更高,也是自然的事情。我认为大模型规模上现在远远没有看到天花板。”黄铁军说。
04 结语:群英会聚大模型研讨高地, 百场精彩讨论干货满载
算上今天,智源大会已经连续举办了五届。这五年来,凭借汇聚人工智能领域最关键的人物、最重要的机构、最核心的话题与最专业的观众,智源大会的口碑持续发酵,不仅是业界全面关注度最高的人工智能盛会之一,也早已成为北京加快建设人工智能创新策源地的一张名片。
智源大会的主办方智源研究院,是中国最早进行大模型研究的科研机构,从率先开启大模型立项探索,率先组建大模型研究团队,率先预见“AI大模型时代到来”,率先发布连创“中国首个+世界最大”记录的“悟道”大模型项目,到今天,智源研究院依然走着最前沿,率先倡导大模型开源开放,并带头建设大模型测评旗舰项目,为大模型行业发展与生态扩张注入源源不断的动能。
大模型引爆人工智能概念,离不开算法的进步。本届智源大会邀请了过去一年领域突破的重要工作完成者,包括GPT-4/ChatGPT、PaLM-E、OPT、LLaMA、Codex、Whisper、Sparrow、NLLB、T5、Flan-T5、LAION-5B、RoBERTa等重要工作作者出席,亲身讲解研究成果。
满满两天将覆盖百场精彩讨论,包括明天,在星光熠熠的AI安全与对齐论坛期间,智源研究院理事长张宏江与OpenAI联合创始人兼CEO Sam Altman,加州伯克利分校教授与图灵奖得主、中国科学院院士姚期智,将分别展开对谈交锋。图灵奖得主、“深度学习之父”Geoffrey Hinton也将发表重磅主题演讲,非常令人期待。
本文来自微信公众号 “智东西”(ID:zhidxcom),作者:ZeR0,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK