

特征平台 | 李乾坤的博客
source link: https://qiankunli.github.io/2022/06/27/feature_platform.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
特征平台 | 李乾坤的博客
美团外卖特征平台的建设与实践 未全明白,比较全面。
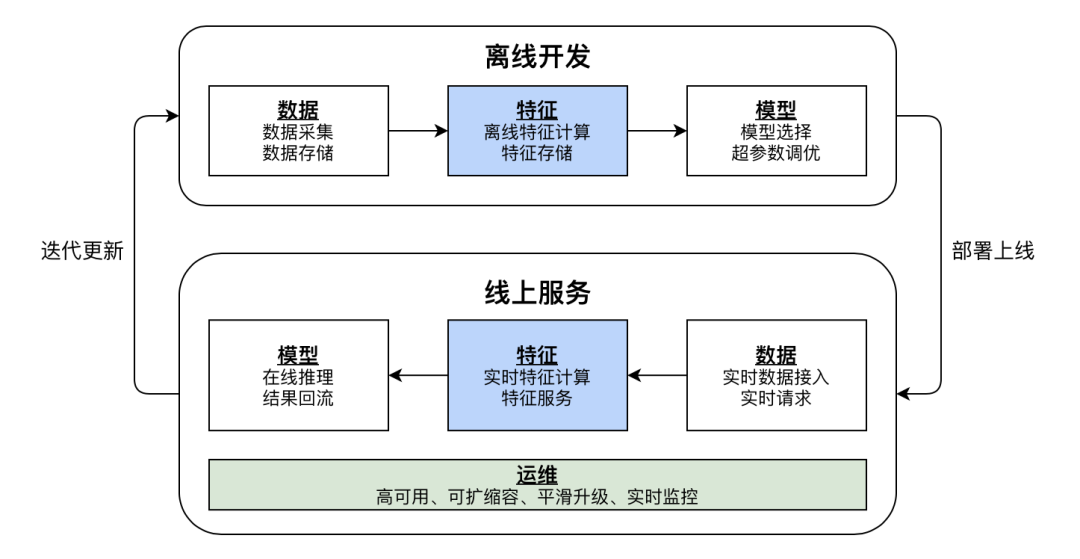
如何提高模型效果?
- Model-centric: 以调整模型代码、调优模型超参数为主的系统调优策略,在这种策略下,可以认为数据集是固定的 Data-centric:
- 与Model-centric相对,以调整数据集为主的系统调优策略,在这种策略下,可以认为模型是固定的(只对数据集作适应性调整) Andrew认为,在搭建模型时,特征生产与模型训练的时间占比应该是8:2,然而目前大部分AI研究的文章(>99%),均发力于模型探索方面。人们很容易认为模型效果不好,是因为模型不好,却忽略了数据集本身对模型效果的巨大影响。如何在工程中实现Data-centric策略?MLOps。
你真的需要特征存储吗?有三种方法可以确保在训练期间所做的预处理在预测期间是相同的
- 将预处理代码放在模型中,比如tf 有专门的feature_column库
- 优点,不需要额外的基础设施,预处理步骤将自动成为模型的一部分,如果需要在边缘或在另一个云上部署模型,不需要做什么特别的事情。
- 缺点,预处理步骤在通过训练数据集的每次迭代中会重复,计算的预处理的步骤越复杂,浪费的时间就越多。另一个缺点是,必须在与ML模型相同的框架中实现预处理代码。例如,如果模型是使用Pytorch编写的,那么预处理也必须使用Pytorch完成。如果预处理代码使用自定义库,会变得非常麻烦。
- 使用转换函数,将预处理步骤封装成函数,并将该函数一次性的应用于原始数据。然后对预处理后的数据进行模型训练,,这样预处理只进行了一次,可以提高效率。但是必须确保预测代码中也需要调用相同函数。像Tensorflow Extended (TFX)这样的框架提供了转换功能来简化相关操作。一些基于sql的ML框架,比如BigQuery ML,也支持TRANSFORM子句。
- 使用特征存储。
- 预测时需要动态特征,这种动态特征必须在服务器上计算,这时特性库就发挥了作用。例如动态定价模型的特征之一可能是过去一小时内网站上商品列表的访问数量。请求酒店价格的客户是无法实获取这个特征的,这些信息是在服务器上通过点击流数据的流管道进行实时计算的,所以特征库可以保存实时的计算结果并且提供对外的访问。PS:没看懂,大概是训练时刻t1 “过去一小时内网站上商品列表” 和 推理时刻t2 “过去一小时内网站上商品列表” 不一样,所以要把t1 时刻 “过去一小时内网站上商品列表” 保存下来给推理用
- 防止不必要的数据拷贝。例如有一个计算开销很大的特性,并且在多个ML模型中使用。与使用转换函数并将转换后的特性存储在多个ML训练数据集中相比,将它存储在一个集中的存储库中是更加高效的选择。
AI工程化落地的数据和特征的挑战
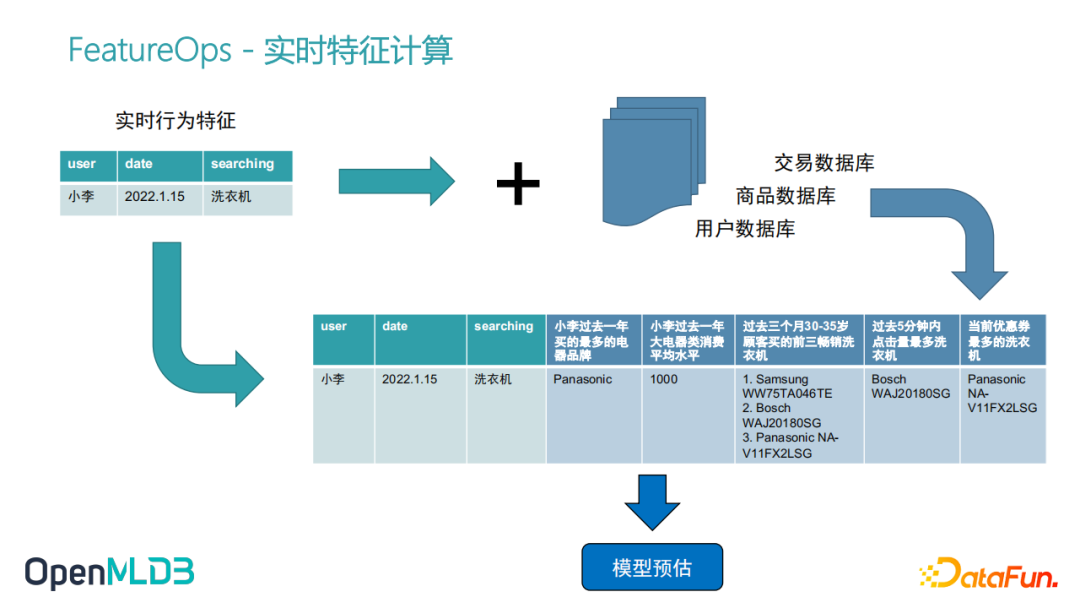
全栈 FeatureOps:开源机器学习数据库 OpenMLDB举一个性化搜索的例子,比如小李同学,在某个时间点想买洗衣机,去搜索洗衣机,触发了搜索行为以后,后面整个特征计算会做什么?首先进来的实时行为特征,只是这三个原始的特征,就是User ID,date以及他在搜索东西。如果我们只是拿这三个特征去做模型训练和推理,它是达不到一个非常好的模型精度的。此时需要做一个特征工程,所谓的特征工程就是我们从数据库里去进一步的去拉取一些历史数据,比方说我们从交易数据库、商品数据库、用户数据库去拉取一些历史数据,然后组合、计算,得到一些更完整的更有意义的特征。
推荐模型本质上是一个函数,输入输出都是数字或数值型的向量。离线训练 要根据用户的原始特征(有的地方称为物料) 构建训练样本,在线服务要根据用户的uid/itemId 找到原始特征,并根据原始特征转换为训练特征(也叫实时特征),再调用预测服务得到预测值。这个过程中
- 因为数据量大,物料转特征要用到spark,而算法人员一般不会使用spark。且特征转换 多样,每个模型都不同
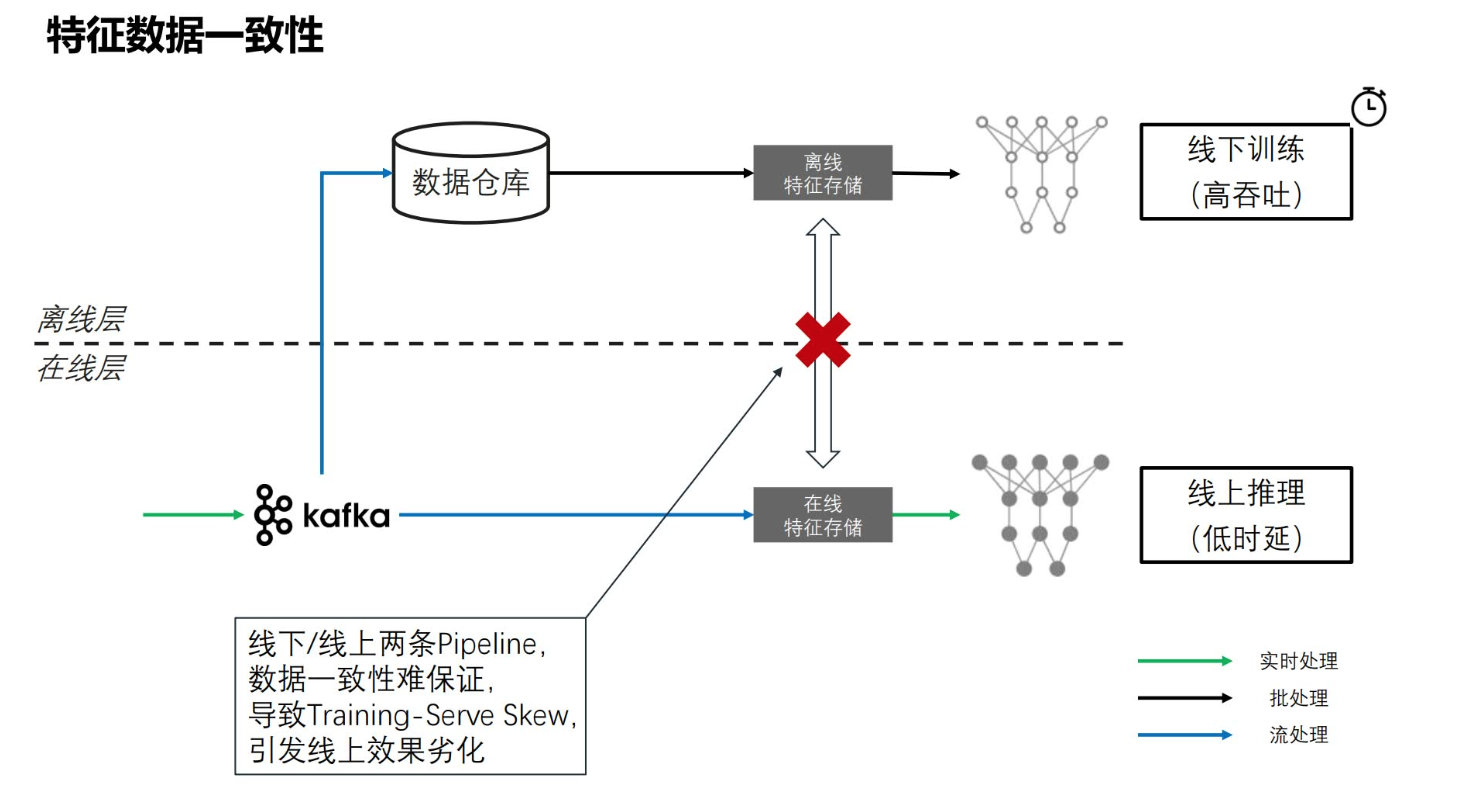
- 离线/在线一致性校验 千亿级模型在离线一致性保障方案详解 未细读
- 数据科学家他关注的点是模型的准确度、精确度、质量,但他不太关心模型上线后latency, QPS等等。大部分科学数据科学家做这个过程当中,用的是Python,RSQL这种偏向批处理比较易用的框架,这种面向批处理的这种框架,不能直接上线。所以一般会有一个工程化团队,把科学家做的特征工程的脚本和模型训练的建模方法,翻译成线上的一套东西,因为他们非常关注latency、QPS,他们会用一些高性能数据库,甚至去用c++自己搭建一套特征抽取的服务,打通后面预估服务这条线。因为线上线下是两套系统,由两个团队开发,所以一致性校验是不可避免的。
- 有的特征可能在训练过程中t1时刻被转为a(对应模型参数版本v1),但经过一段时间t2时刻(随着样本量的变化)会被转换为b,此时拿着t1 时刻的模型参数去预测t2 就会不准。AI算法模型中的特征穿越问题:原理篇
- 特征服务/feature serving: 在线服务可能qps 非常高,一般要用到特征缓存
- 缓存原始特征/物料,公司有很多个部门,也就是会有很多个物料服务,此时会有一个物料缓存网关。物料缓存网关的核心功能则为缓存和路由,其根据特征名称路由到不同的物料服务来计算。
- 缓存训练特征。预测时实时 将物料转换为训练特征,实时计算就意味着RT增加,特征越多,RT的压力越来越大。降低RT的常见思路为用空间换时间,类似年龄性别等人口属性和用户的长期兴趣是固定的,没有必要每次都计算,可以将某些类型的特征提前计算好并存储到缓存中,线上请求直接拉取对应的特征即可。要区分不同物料的计算频率,我们将物料区分为下面几种更新周期:天级别、分钟级别、实时级别。实时级别的特征还是需要每次请求都实时计算的。此时,物料缓存网关 实际是 物料and特征缓存网关。
- 实时推荐对上述处理过程的挑战
网易新闻推荐工程优化 - 特征平台篇业内常见的特征平台的核心设计往往为数据表,比如设计用户表和文章表。离线训练时将日志信息、用户表、文章表做join处理以生成样本;在线服务时则有专门的服务加速从数据表中获取内容的过程。
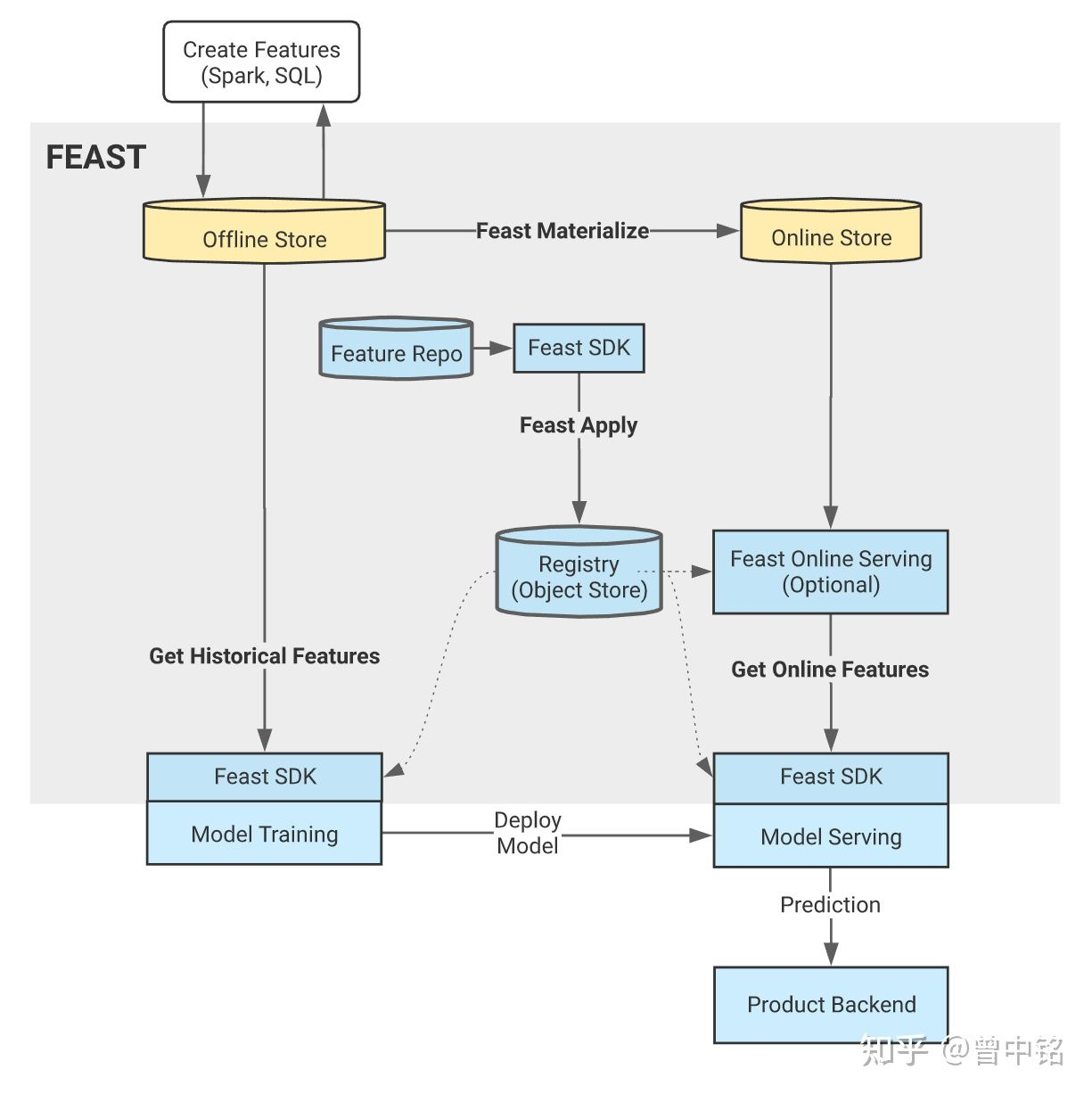
特征平台(Feature Store):序论 业界已经有 Feast/Tecton/Databricks Feature Store/LinkedIn Feathr 等
- Feature Registry:一般数据库即可,以承载特征元数据,比如 name、entities、schema、source
- 特征计算/ Feature Pipeline。从各类原始数据,例如日志、记录、表,经过关联、统计、转化、聚集等操作得到的一系列值。这些Pipeline通常是Spark、Flink、Hive、SQL作业,并且批处理作业还需要一个编排系统(例如Apache Airflow)进行管理。PS: 以下工程通过python 等描述后,交给spark 执行
- 对于需要从原始数据计算得到的特征,Feathr称之为Anchored Feature,即该Feature是Anchor(锚定)在某个数据源上的。其Feature定义过程如下:
- 声明特征数据源,比如使用HDFS上的文件作为数据源
- 声明Feature对象,该对象记录了name、feature_type(数据类型)、transform(特征计算逻辑)等信息
- 声明FeatureAnchor对象
- 对于基于其他特征计算得到的特征,Feathr称之为Derived Feature(衍生特征)。其定义过程与AnchorFeature类似,只是将Source换成input_features。
- 对于需要从原始数据计算得到的特征,Feathr称之为Anchored Feature,即该Feature是Anchor(锚定)在某个数据源上的。其Feature定义过程如下:
- Offline Store:同时支持SQL数据库/数据仓库和数据湖,包含了特征的所有版本,Feast中是一个时序表,包含timestamp/entity/feature 等
- Online Store:比如Redis,用于存储特征的最新版本,服务于模型推理时的特征在线消费场景
- SDK:比如基于Python开发的SDK,供用户使用
工作流程大概如下
- 特征元数据
- 特征计算,使用python或dsl 描述特征计算逻辑,交给spark 等处理,处理完成后存储到 Offline Store 中,并同步一份给 Online Store
- 模型训练,训练时从 Offline Store 中拼接 训练样本
- 推理时,业务方根据SDK 从 Online Store 中拿到某个用户的特征数据,调用serving 服务拿到预估值。
vivo推荐中台升级路:机器成本节约75%,迭代周期低至分钟级
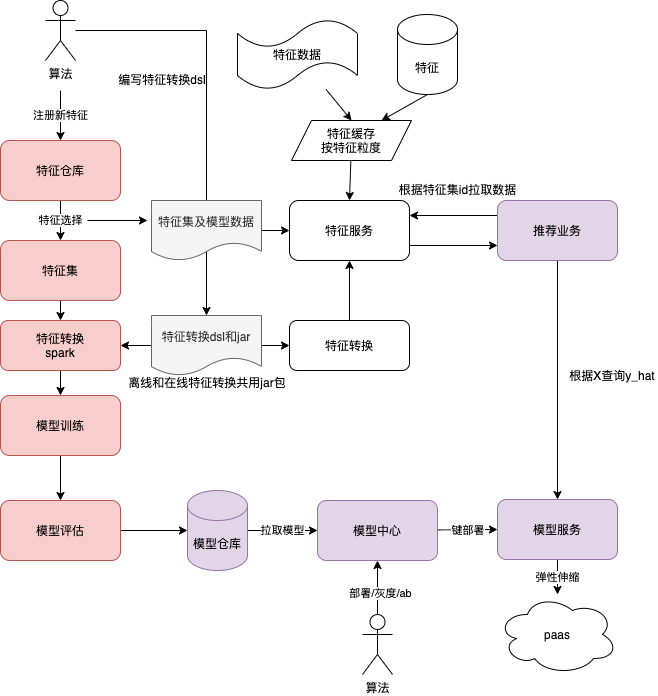
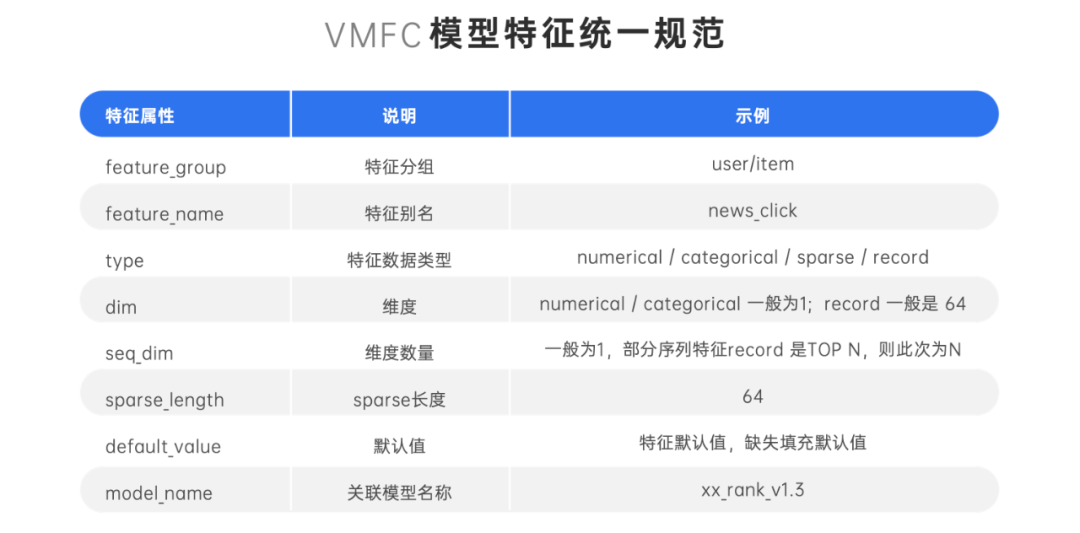
- 为了打通离线训练与在线推理的特征解析,我们对多个业务进行抽象设计,制定了 vivo 模型特征统一配置规范,VMFC(vivo Model Feature Configration)。
- 算法工程师在样本生产时,先在特征仓库勾选形成样本需要的特征集,在创建离线模型训练任务的时候,选择该模型训练与该特征集匹配。最终模型训练完成之后,在模型中心对其一键部署为在线推理服务。
- 在线推理服务对外提供统一接口,业务方使用时只需要指定对应的业务与模型代码,配置化推理服务找到该模型的 VMFC,便可以自动查询需要的特征,拼接为模型入参,返回预测结果。
在 vivo 传统的推荐系统架构中,特征的获取、特征的处理、特征的拼接以及推理预测是耦合在推荐工程的代码中的,每次算法实验的迭代,每增加一个特征,甚至是增加一个用于回传的特征,都需要在离线训练和推荐工程端硬编码新增的特征名称。然后把特征处理函数“搬运”过来,显然存在以下难以解决的痛点:
- 架构耦合对单机压力愈来愈大:特征获取与模型预测耦合,推荐系统服务器单机运行压力大;
- 硬编码迭代效率慢成为工程落地的瓶颈:特征获取与特征处理的逻辑不够灵活,无法应对算法实验的快速迭代需求,成为推荐系统流水线的瓶颈环节;
- 特征数据不一致:频繁的多分支多版本算法实验,多人协作带来较大沟通成本;训练的特征集、特征处理函数可能与线上推理预测的不一致,进而导致特征数据不一致;
- 特征复用困难:各个业务场景的特征都依赖于数据流算法工程师的经验,对多个团队类似的业务场景,特征的数据和经验不共享,导致增加了特征重复处理、存储等问题。数据孤岛效应明显,成本也很难缩减。
基于上述痛点,为了从根源解决算法迭代效率的问题,创造性的提出了特征仓库,特征集和通用特征服务的三大概念。
- 特征仓库,是通过特征工程把 Raw 数据抽取转化为一个特征,在特征平台注册为一个新特征元数据信息(Metadata),描述了这个特征存储的方式,数据类型,长度,默认值等,并且可以对该特征设置多项目共享,达到特征复用的目的。字节跳动基于 Iceberg 的海量特征存储实践
- 特征集,是一个虚拟灵活的特征集合概念,按照模型迭代的需求,可以自由从特征仓库上勾选需要的特征元数据,类似购物车的概念,按需动态勾选一个匹配当前模型训练的特征集。如果一个特征已经在平台上注册过,其他业务和场景需要复用,相应的算法工程师只需要申请共享,通过合规审批之后,就可以通过勾选特征集,用于自己的模型训练和在线推理。
- 特征服务,把特征获取这个关键步骤直接服务化,与特征管理平台联动的一个可配置化特征服务。在线获取特征的时候,调用通用特征服务的接口,传入特征集的唯一 ID,特征服务根据特征集元数据动态灵活获取需要的特征,一次返回给在线推理工程,通过特征拼接进入 Tensorflow 模型进行 CTR 实时预测。给出推荐结果。

对训练样本需要的特征进行汇总分析,并对依赖的原始数据进行梳理,整理出由原始数据到特征样本之间所有的变换、组合关系,我们称之为特征算子。抽象算子之后,我们将进行特征描述和组合。我们选择json作为配置描述语言。
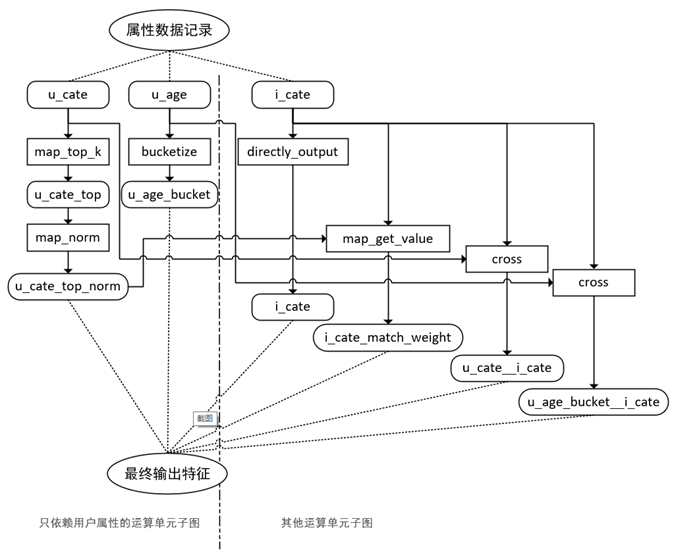
根据特征算子的输入、输出依赖关系将特征算子列表转成特征算子依赖关系图,该图为一个有向无环图。运行时,只需要根据图结点的依赖关系进行遍历计算,即可得到最终的特征数据。
如果算法人员懂spark,可以把原始特征数据读取为dataframe,然后一路转换dataframe,最终转成训练集。但实际上机器学习平台为了支持特征处理 + 训练的可编排,一般会为一次数据转换启动一个spark任务,任务之间通过hdfs流转数据,hdfs ==> dataframe ==> hdfs落盘 ==> dataframe ==> hdfs落盘 ==> tfdataset ==> tf训练任务。为啥不写到一个spark任务呢?因为算法写不了这个spark 任务,又要支持他灵活编排。spark 任务之间通过hdfs 流转数据,有点又回到了mapreduce的感觉,如果能做到 两个spark 任务之间的数据流转在内存里、或者说 根据dag的 特征处理部分 翻译出来一个完整的saprk 任务,是不是会大大加快特征处理这块的速度?
模型仓库与模型服务
- 模型仓库,主要是对离线训练完成的模型进行统一管理,并且提供离线模型的一键部署能力。算法同事在完成模型训练之后,只需要确定该离线模型符合预期并加入模型仓库。
- 模型服务,“模型即服务”(Model as a Service), 基于 VMFC 的离线训练得到模型,在模型仓库一键部署成为在线服务,即可对外提供标准的在线预测接口。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK