
5

2018.01 Dice (EA) 工作室游戏开发技术概览
source link: https://gulu-dev.com/post/2018-01-25-ea-dice-tech-overview/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
- 2022-05-01 补记
- 这是我在 2018 年离开西山居前不久做的一次技术分享,原文副标题是 “Dice 如何改造引擎适应现代技术发展”。
- 这次整理的过程里重新看了一遍,还有不少新的收获和启发。
这份材料的内容还是非常扎实的,一共有75页。
Intro
- 对 Dice 到目前为止已公开的 55 份技术资料做了筛选和提炼,形成一份相对完整的信息体系,提取重点并在讨论会上做快速的讲解。
- 了解一线游戏工作室的技术关注热点,趋势判断,及若干实践中的分析,判断和取舍
- 了解如何在成熟的技术体系中保持系统的低熵,持续吸纳和消化新的技术并改善架构
- 在使用成熟工具链生产内容时,如何降低持续引入的新技术对已制作资源和已建立流程的冲击
- 如何在通用化 (复用技术组件,工具,内容和资源) 和独特性 (避免画面和 Gameplay 的同质化) 之间避免失衡
- Massive Procedural Content Generation (大体量的过程化的内容生成技术)
- Game Engine Mobilizing (游戏引擎的移动化)
本次分享的大纲,主要是三个部分:移动化,围绕数据的改造和 FrameGraph。

Topics
这是当时从55分材料当中提取出的最有价值的10篇。
- (2007) Frostbite: 渲染架构 (过程化纹理和着色)
- (2008) Battlefield: 基于节点的着色框架,命令缓冲并行化,软光栅裁剪实现
- (2009) Frostbite: 引擎并行化,CPU/GPU Jobs
- (2011) Battlefield 3: 粒子光影和间接光,完整绘制流程,图形选项和性能工具
- (2013) Frostbite: 资源流水线扩展:存储和数据库,构建模型,网络缓存
- (2015) Battlefield 4: 渲染流水线的挑战和改造 - 降低复杂度,预计算,利用屏幕空间
- (2016) Frostbite 3: 族裁剪 (Cluster Culling),朝向裁剪 (Orientation Culling),微裁剪 (Primitive Culling) 深度裁剪 (Depth Culling) 打包绘制 (Draw Compaction)
- (2017) Frostbite 架构对比 (2007 vs 2017) FrameGraph 实现,临时资源 (Transient Resource) 管理,帧流程的图形化 (可搜索 PDF) 异步模型,内存布局复用
- 代码技术:局部栈分配,面向数据设计,二进制膨胀
- 移动平台技术: GL/Metal 对比分析,光照系统改造,基于局部存储的优化 (tile memory)
一些分享前的准备脚本
什么是“围绕数据设计”?
- Data-Oriented Design
- 把关注点从“对象和交互”转移到“数据和读写”。
- 现代体系的内存访问敏感性强,提供紧凑的数据,理解和配合 Cache 的行为越来越重要。
- 当把行为线程化时,对数据读写的明确约定能够极大地简化逻辑,避免不必要的锁。
- 良好的面向对象设计,会把逻辑和数据耦合在一起,而线程同步往往只关心数据本身。耦合带来维护负担。(POD-struct 的同步几乎总是比对象同步要简明)
面向对象的例子 (数据不紧凑,难以优化)
- 80 个时钟周期的运算实际消耗了 7680 个周期
- 98.96% 的时间花费在实际运算逻辑之外,惊人的浪费
- 反过来从输出出发,仅仅提供运算所需的最少量的输入数据
- 紧凑的数据,更有利于批量处理
- 消耗在内存寻址上的时间降低到原来的 25% (1900 ~ 7600)
内存布局的对比 (OOD vs DOD)
核心关注点是内存的利用效率
- 优先针对数据优化,而不是代码
- 绝大部分代码的性能实际上取决于内存访问 (bound by memory access)
- 用于运算的数据集 (native data) 可以跟源数据集 (source data) 分离
- (就好像 native code 和 source code 那样)
- 可以理解为,为了更高效的访问,我们把数据“编译”为更紧凑的组织形式
三个例子:
- 场景中的逻辑对象 (如触发器 Trigger)
- 原始数据由场景树和链表加载并持有
- 但生成紧凑数组用于专项处理
- 裁剪系统 (所有对象的包围数据本来是各自持有并维护)
- 从层次化数据结构中,提取包围信息并填充到线性数组
- 忽略父子关系,一次性迭代并处理所有对象
- 比原有系统快 3 倍 (3x),代码大幅简化 (code size 1/5)
- 更容易并行化
- <简略介绍> Culling The Battlefield
- Path-finding
- <简略介绍> AStepTowardsDataOrientation
高级内存话题 (域内的栈上分配)
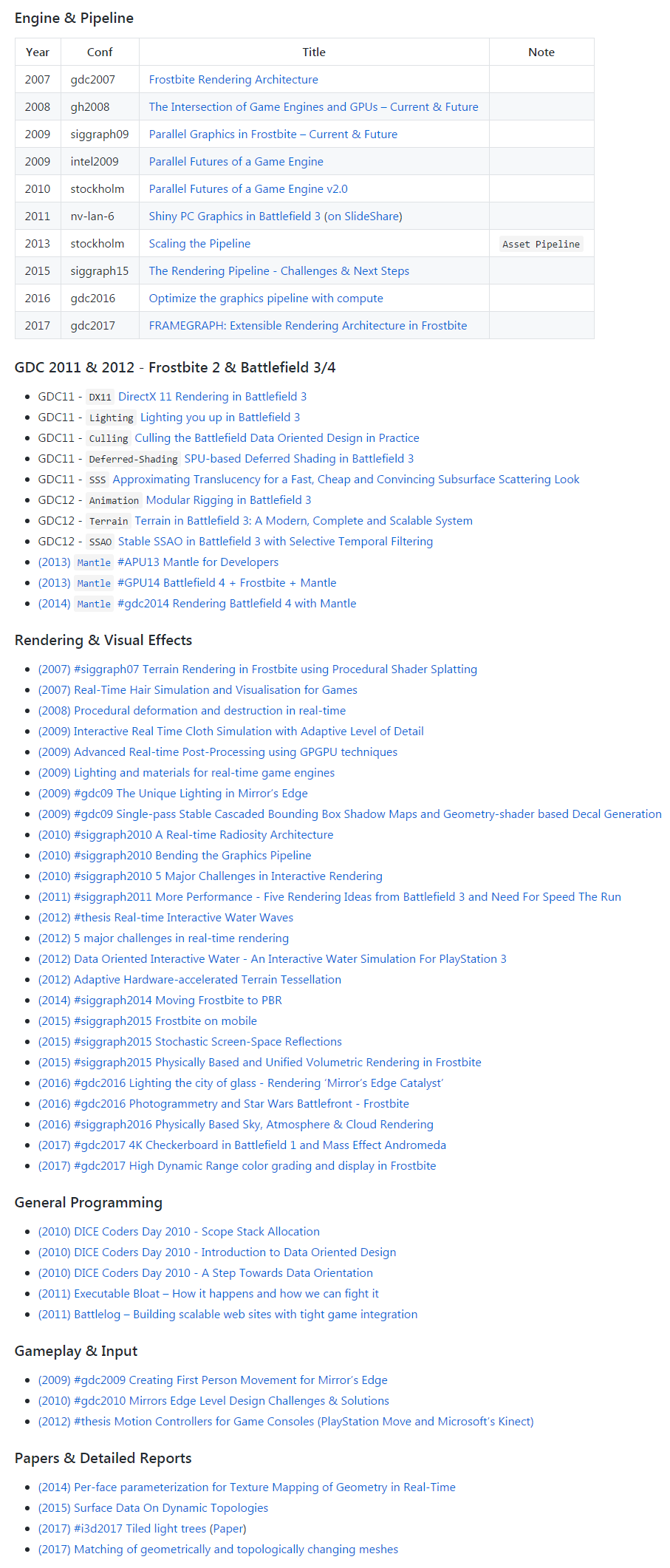
本次分享所参考的 55 份材料来源在这里:
dev-awesomenesses/awesome-frostbite-engine.md
由于年久失修,其中绝大部分链接现在已不可用,DICE 也已经不再开放他的技术文档公开访问了。
(全文完)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK