

Spring Cloud构建微服务架构:消息驱动的微服务(核心概念)【Dalston版】
source link: http://blog.didispace.com/spring-cloud-starter-dalston-7-2/?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Spring Cloud构建微服务架构:消息驱动的微服务(核心概念)【Dalston版】
通过《Spring Cloud构建微服务架构:消息驱动的微服务(入门)》一文,相信大家对Spring Cloud Stream的工作模式已经有了一些基础概念,比如:输入、输出通道的绑定,通道消息事件的监听等。下面在本文中,我们将详细介绍一下Spring Cloud Stream中是如何通过定义一些基础概念来对各种不同的消息中间件做抽象的。
下图是官方文档中对于Spring Cloud Stream应用模型的结构图。从中我们可以看到,Spring Cloud Stream构建的应用程序与消息中间件之间是通过绑定器Binder相关联的,绑定器对于应用程序而言起到了隔离作用,它使得不同消息中间件的实现细节对应用程序来说是透明的。所以对于每一个Spring Cloud Stream的应用程序来说,它不需要知晓消息中间件的通信细节,它只需要知道Binder对应用程序提供的概念去实现即可,而这个概念就是在快速入门中我们提到的消息通道:Channel。如下图案例,在应用程序和Binder之间定义了两条输入通道和三条输出通道来传递消息,而绑定器则是作为这些通道和消息中间件之间的桥梁进行通信。
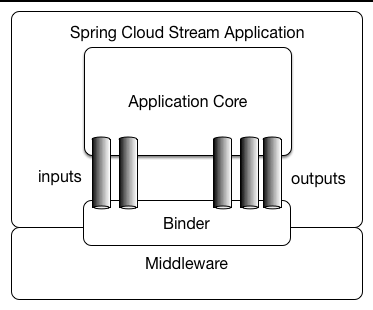
Binder绑定器是Spring Cloud Stream中一个非常重要的概念。在没有绑定器这个概念的情况下,我们的Spring Boot应用要直接与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现细节上会有较大的差异性,这使得我们实现的消息交互逻辑就会非常笨重,因为对具体的中间件实现细节有太重的依赖,当中间件有较大的变动升级、或是更换中间件的时候,我们就需要付出非常大的代价来实施。
通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离。通过向应用程序暴露统一的Channel通道,使得应用程序不需要再考虑各种不同的消息中间件实现。当我们需要升级消息中间件,或是更换其他消息中间件产品时,我们要做的就是更换它们对应的Binder绑定器而不需要修改任何Spring Boot的应用逻辑。这一点在上一章实现消息总线时,从RabbitMQ切换到Kafka的过程中,已经能够让我们体验到这一好处。
目前版本的Spring Cloud Stream为主流的消息中间件产品RabbitMQ和Kafka提供了默认的Binder实现,在快速入门的例子中,我们就使用了RabbitMQ的Binder。另外,Spring Cloud Stream还实现了一个专门用于测试的TestSupportBinder,开发者可以直接使用它来对通道的接收内容进行可靠的测试断言。如果要使用除了RabbitMQ和Kafka以外的消息中间件的话,我们也可以通过使用它所提供的扩展API来实现其他中间件的Binder。
仔细的读者可能已经发现,我们在快速入门示例中,并没有使用application.properties或是application.yml来做任何属性设置。那是因为它也秉承了Spring Boot的设计理念,提供了对RabbitMQ默认的自动化配置。当然,我们也可以通过Spring Boot应用支持的任何方式来修改这些配置,比如:通过应用程序参数、环境变量、application.properties或是application.yml配置文件等。比如,下面就是通过配置文件来对RabbitMQ的连接信息以及input通道的主题进行配置的示例:
spring.cloud.stream.bindings.input.destination=raw-sensor-data
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=springcloud
spring.rabbitmq.password=123456
发布-订阅模式
在Spring Cloud Stream中的消息通信方式遵循了发布-订阅模式,当一条消息被投递到消息中间件之后,它会通过共享的Topic主题进行广播,消息消费者在订阅的主题中收到它并触发自身的业务逻辑处理。这里所提到的Topic主题是Spring Cloud Stream中的一个抽象概念,用来代表发布共享消息给消费者的地方。在不同的消息中间件中,Topic可能对应着不同的概念,比如:在RabbitMQ中的它对应了Exchange、而在Kakfa中则对应了Kafka中的Topic。
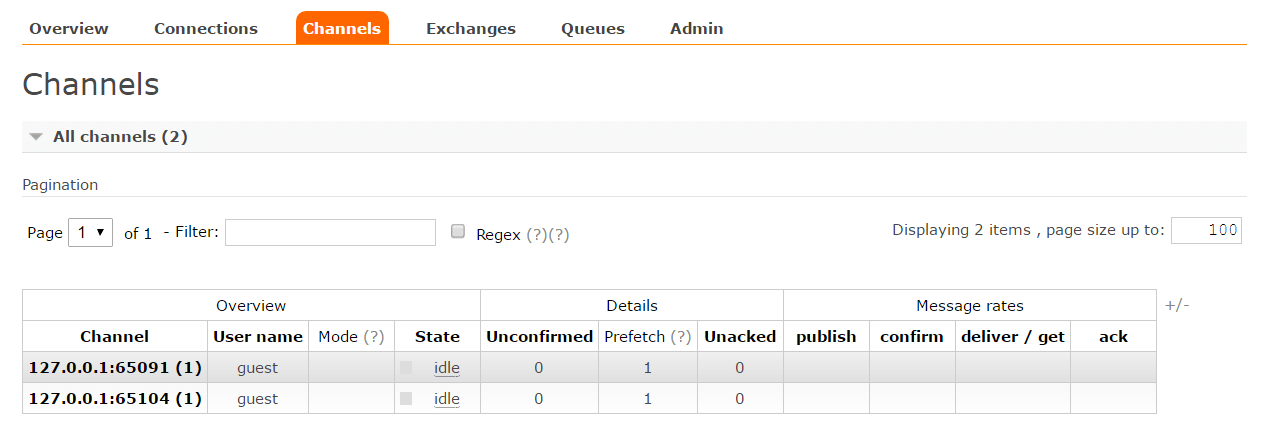
在快速入门的示例中,我们通过RabbitMQ的Channel进行发布消息给我们编写的应用程序消费,而实际上Spring Cloud Stream应用启动的时候,在RabbitMQ的Exchange中也创建了一个名为input的Exchange交换器,由于Binder的隔离作用,应用程序并无法感知它的存在,应用程序只知道自己指向Binder的输入或是输出通道。为了直观的感受发布-订阅模式中,消息是如何被分发到多个订阅者的,我们可以使用快速入门的例子,通过命令行的方式启动两个不同端口的进程。此时,我们在RabbitMQ控制页面的Channels标签页中看到如下图所示的两个消息通道,它们分别绑定了启动的两个应用程序。
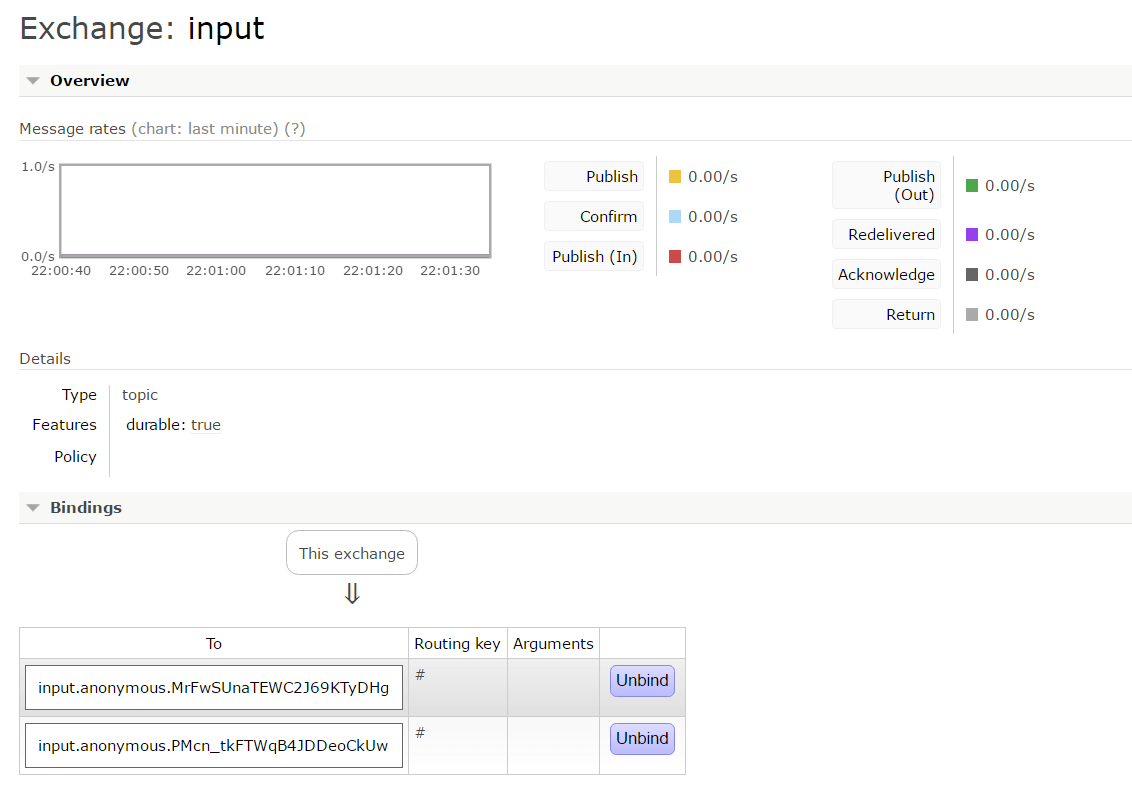
而在Exchanges标签页中,我们还能找到名为input的交换器,点击进入可以看到如下图所示的详情页面,其中在Bindings中的内容就是两个应用程序绑定通道中的消息队列,我们可以通过Exchange页面的Publish Message来发布消息,此时可以发现两个启动的应用程序都输出了消息内容。
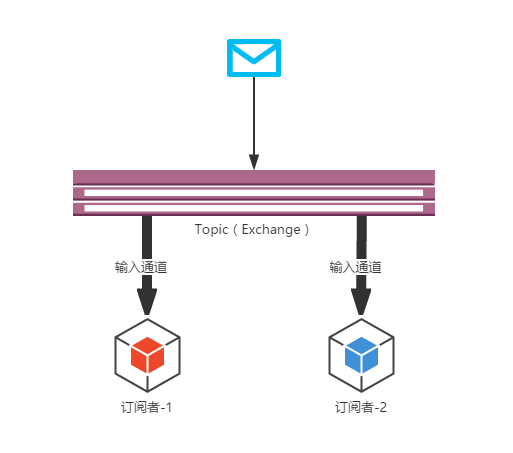
下图总结了我们上面所做尝试的基础结构,我们启动的两个应用程序分别是“订阅者-1”和“订阅者-2”,他们都建立了一条输入通道绑定到同一个Topic(RabbitMQ的Exchange)上。当该Topic中有消息发布进来后,连接到该Topic上的所有订阅者可以收到该消息并根据自身的需求进行消费操作。
相对于点对点队列实现的消息通信来说,Spring Cloud Stream采用的发布-订阅模式可以有效的降低消息生产者与消费者之间的耦合,当我们需要对同一类消息增加一种处理方式时,只需要增加一个应用程序并将输入通道绑定到既有的Topic中就可以实现功能的扩展,而不需要改变原来已经实现的任何内容。
虽然Spring Cloud Stream通过发布-订阅模式将消息生产者与消费者做了很好的解耦,基于相同主题的消费者可以轻松的进行扩展,但是这些扩展都是针对不同的应用实例而言的,在现实的微服务架构中,我们每一个微服务应用为了实现高可用和负载均衡,实际上都会部署多个实例。很多情况下,消息生产者发送消息给某个具体微服务时,只希望被消费一次,按照上面我们启动两个应用的例子,虽然它们同属一个应用,但是这个消息出现了被重复消费两次的情况。为了解决这个问题,在Spring Cloud Stream中提供了消费组的概念。
如果在同一个主题上的应用需要启动多个实例的时候,我们可以通过spring.cloud.stream.bindings.input.group属性为应用指定一个组名,这样这个应用的多个实例在接收到消息的时候,只会有一个成员真正的收到消息并进行处理。如下图所示,我们为Service-A和Service-B分别启动了两个实例,并且根据服务名进行了分组,这样当消息进入主题之后,Group-A和Group-B都会收到消息的副本,但是在两个组中都只会有一个实例对其进行消费。
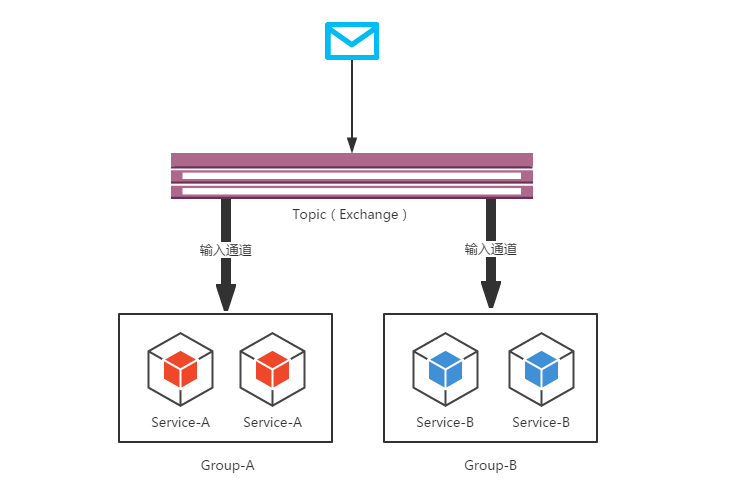
默认情况下,当我们没有为应用指定消费组的时候,Spring Cloud Stream会为其分配一个独立的匿名消费组。所以,如果同一主题下所有的应用都没有指定消费组的时候,当有消息被发布之后,所有的应用都会对其进行消费,因为它们各自都属于一个独立的组中。大部分情况下,我们在创建Spring Cloud Stream应用的时候,建议最好为其指定一个消费组,以防止对消息的重复处理,除非该行为需要这样做(比如:刷新所有实例的配置等)。
通过引入消费组的概念,我们已经能够在多实例的情况下,保障每个消息只被组内一个实例进行消费。通过上面对消费组参数设置后的实验,我们可以观察到,消费组并无法控制消息具体被哪个实例消费。也就是说,对于同一条消息,它多次到达之后可能是由不同的实例进行消费的。但是对于一些业务场景,就需要对于一些具有相同特征的消息每次都可以被同一个消费实例处理,比如:一些用于监控服务,为了统计某段时间内消息生产者发送的报告内容,监控服务需要在自身内容聚合这些数据,那么消息生产者可以为消息增加一个固有的特征ID来进行分区,使得拥有这些ID的消息每次都能被发送到一个特定的实例上实现累计统计的效果,否则这些数据就会分散到各个不同的节点导致监控结果不一致的情况。而分区概念的引入就是为了解决这样的问题:当生产者将消息数据发送给多个消费者实例时,保证拥有共同特征的消息数据始终是由同一个消费者实例接收和处理。
Spring Cloud Stream为分区提供了通用的抽象实现,用来在消息中间件的上层实现分区处理,所以它对于消息中间件自身是否实现了消息分区并不关心,这使得Spring Cloud Stream为不具备分区功能的消息中间件也增加了分区功能扩展。
以下专题教程也许您会有兴趣
本文内容部分节选自我的《Spring Cloud微服务实战》,但对依赖的Spring Boot和Spring Cloud版本做了升级。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK