

MSON,让JSON序列化更快
source link: https://tech.meituan.com/MSON.html?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
MSON,让JSON序列化更快
我们经常需要在主线程中读取一些配置文件或者缓存数据,最常用的结构化存储数据的方式就是将对象序列化为JSON字符串保存起来,这种方式特别简单而且可以和SharedPrefrence配合使用,因此应用广泛。但是目前用到的Gson在序列化JSON时很慢,在读取解析这些必要的配置文件时性能不佳,导致卡顿启动速度减慢等问题。
Gson的问题在哪里呢?笔者用AndroidStudio的profile工具分析了activity.onCreate方法的耗时情况。
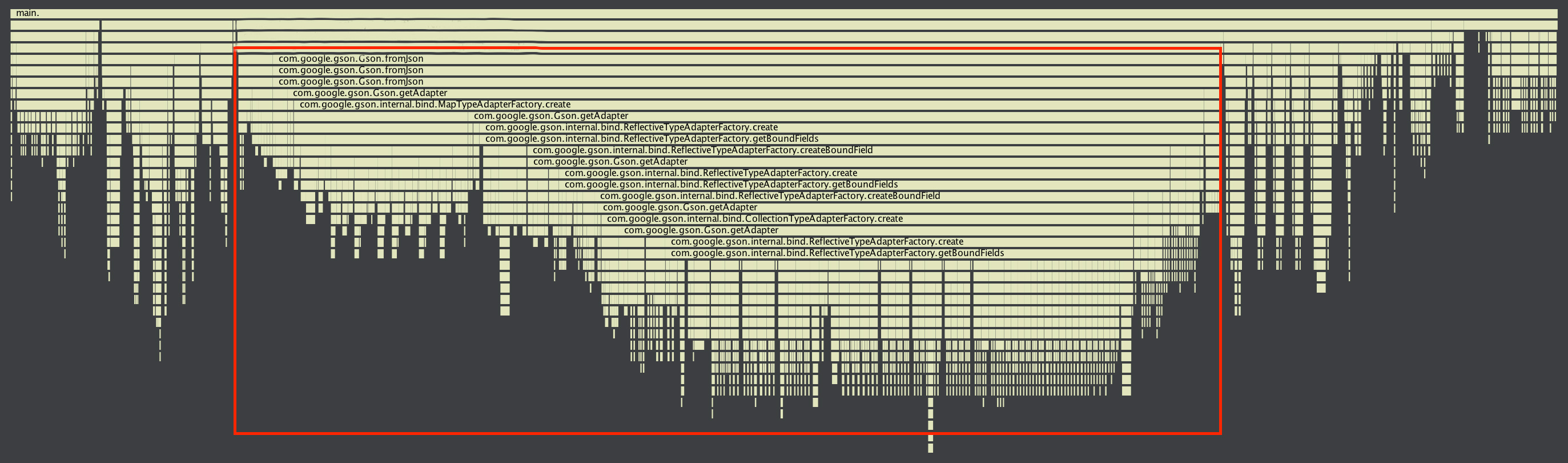
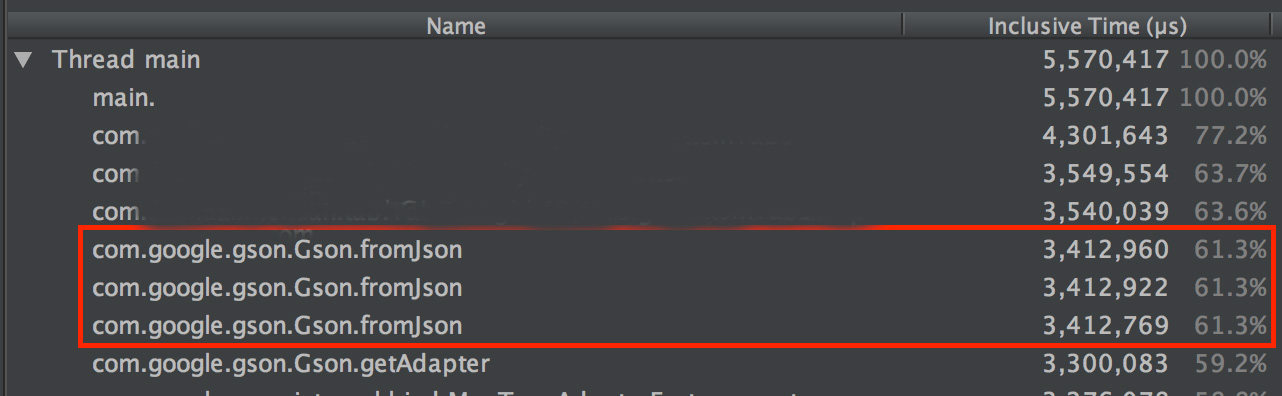
如图1所示,可以发现Gson序列化占用了大部分的执行时间,从图2可以更直观地看到Gson.fromJson占用了61%的执行时间。分析Gson的源码可以发现,它在序列化时大量使用了反射,每一个field,每一个get、set都需要用反射,由此带来了性能问题。
知道了性能的瓶颈之后,我们如何去修改呢?我能想到的方法就是尽量减少反射。
Android框架中由JSONObject来提供轻量级的JSON序列化工具,所以我选择用Android框架中的JSONObject来做序列化,然后手动复制到bean就可以去掉所有的反射。
我做了个简单的测试,分别用Gson和JSONObject的方式去序列化一个bean,看下各自速度如何。
使用JSONObject的实现方式如下:
public class Bean {
public String key;
public String title;
public String[] values;
public String defaultValue;
public static Bean fromJsonString(String json) {
try {
JSONObject jsonObject = new JSONObject(json);
Bean bean = new Bean();
bean.key = jsonObject.optString("key");
bean.title = jsonObject.optString("title");
JSONArray jsonArray = jsonObject.optJSONArray("values");
if (jsonArray != null && jsonArray.length() > 0) {
int len = jsonArray.length();
bean.values = new String[len];
for (int i=0; i<len; ++i) {
bean.values[i] = jsonArray.getString(i);
}
}
bean.defaultValue = jsonObject.optString("defaultValue");
return bean;
} catch (JSONException e) {
e.printStackTrace();
}
return null;
}
public static String toJsonString(Bean bean) {
if (bean == null) {
return null;
}
JSONObject jsonObject = new JSONObject();
try {
jsonObject.put("key", bean.key);
jsonObject.put("title", bean.title);
if (bean.values != null) {
JSONArray array = new JSONArray();
for (String str:bean.values) {
array.put(str);
}
jsonObject.put("values", array);
}
jsonObject.put("defaultValue", bean.defaultValue);
} catch (JSONException e) {
e.printStackTrace();
}
return jsonObject.toString();
}
}
测试代码:
private void test() {
String a = "{\"key\":\"123\", \"title\":\"asd\", \"values\":[\"a\", \"b\", \"c\", \"d\"], \"defaultValue\":\"a\"}";
Gson Gson = new Gson();
Bean testBean = Gson.fromJson(a, new TypeToken<Bean>(){}.getType());
long now = System.currentTimeMillis();
for (int i=0; i<1000; ++i) {
Gson.fromJson(a, new TypeToken<Bean>(){}.getType());
}
Log.d("time", "Gson parse use time="+(System.currentTimeMillis() - now));
now = System.currentTimeMillis();
for (int i=0; i<1000; ++i) {
Bean.fromJsonString(a);
}
Log.d("time", "jsonobject parse use time="+(System.currentTimeMillis() - now));
now = System.currentTimeMillis();
for (int i=0; i<1000; ++i) {
Gson.toJson(testBean);
}
Log.d("time", "Gson tojson use time="+(System.currentTimeMillis() - now));
now = System.currentTimeMillis();
for (int i=0; i<1000; ++i) {
Bean.toJsonString(testBean);
}
Log.d("time", "jsonobject tojson use time="+(System.currentTimeMillis() - now));
}
| 序列化方法 | Gson | JSONObject |
|---|---|---|
| 序列化耗时(ms) | 56 | 9 |
| 反序列化耗时(ms) | 97 | 7 |
执行1000次JSONObject,花费的时间是Gson的几十分之一。
虽然JSONObject能够解决我们的问题,但在项目中有大量的存量代码都使用了Gson序列化,一处处去修改既耗费时间又容易出错,也不方便增加减少字段。
那么有没有一种方式在使用时和Gson一样简单且性能又特别好呢?
我们调研了Java的AnnotationProcessor(注解处理器),它能够在编译前对源码做处理。我们可以通过使用AnnotationProcessor为带有特定注解的bean自动生成相应的序列化和反序列化实现,用户只需要调用这些方法来完成序列化工作。
我们继承“AbstractProcessor”,在处理方法中找到有JsonType注解的bean来处理,代码如下:
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(JsonType.class);
for (Element element : elements) {
if (element instanceof TypeElement) {
processTypeElement((TypeElement) element);
}
}
return false;
}
然后生成对应的序列化方法,关键代码如下:
JavaFileObject sourceFile = processingEnv.getFiler().createSourceFile(fullClassName);
ClassModel classModel = new ClassModel().setModifier("public final").setClassName(simpleClassName);
......
JavaFile javaFile = new JavaFile();
javaFile.setPackageModel(new PackageModel().setPackageName(packageName))
.setImportModel(new ImportModel()
.addImport(elementClassName)
.addImport("com.meituan.android.MSON.IJsonObject")
.addImport("com.meituan.android.MSON.IJsonArray")
.addImport("com.meituan.android.MSON.exceptions.JsonParseException")
.addImports(extension.getImportList())
).setClassModel(classModel);
List<? extends Element> enclosedElements = element.getEnclosedElements();
for (Element e : enclosedElements) {
if (e.getKind() == ElementKind.FIELD) {
processFieldElement(e, extension, toJsonMethodBlock, fromJsonMethodBlock);
}
}
try (Writer writer = sourceFile.openWriter()) {
writer.write(javaFile.toSourceString());
writer.flush();
writer.close();
}
为了今后接入别的字符串和JSONObject的转换工具,我们封装了IJSONObject和IJsonArray,这样可以接入更高效的JSON解析和格式化工具。
继续深入测试发现,当JSON数据量比较大时用JSONObject处理会比较慢,究其原因是JSONObject会一次性将字符串读进来解析成一个map,这样会有比较大的内存浪费和频繁内存创建。经过调研Gson内部的实现细节,发现Gson底层有流式的解析器而且可以按需解析,可以做到匹配上的字段才去解析。根据这个发现我们将我们IJSONObject和IJsonArray换成了Gson底层的流解析来进一步优化我们的速度。
代码如下:
Friend object = new Friend();
reader.beginObject();
while (reader.hasNext()) {
String field = reader.nextName();
if ("id".equals(field)) {
object.id = reader.nextInt();
} else if ("name".equals(field)) {
if (reader.peek() == JsonToken.NULL) {
reader.nextNull();
object.name = null;
} else {
object.name = reader.nextString();
}
} else {
reader.skipValue();
}
}
reader.endObject();
代码中可以看到,Gson流解析过程中我们对于不认识的字段直接调用skipValue来节省不必要的时间浪费,而且是一个token接一个token读文本流这样内存中不会存一个大的JSON字符串。
兼容性主要体现在能支持的数据类型上,目前MSON支持了基础数据类型,包装类型、枚举、数组、List、Set、Map、SparseArray以及各种嵌套类型(比如:Map<String, Map<String, List<String[]>>>)。
性能及兼容性对比
我们使用一个比较复杂的bean(包含了各种数据类型、嵌套类型)分别测试了Gson、fastjson和MSON的兼容性和性能。
测试用例如下:
@JsonType
public class Bean {
public Day day;
public List<Day> days;
public Day[] days1;
@JsonField("filed_a")
public byte a;
public char b;
public short c;
public int d;
public long e;
public float f;
public double g;
public boolean h;
@JsonField("filed_a1")
public byte[] a1;
public char[] b1;
public short[] c1;
public int[] d1;
public long[] e1;
public float[] f1;
public double[] g1;
public boolean[] h1;
public Byte a2;
public Character b2;
public Short c2;
public Integer d2;
public Long e2;
public Float f2;
public Double g2;
public Boolean h2;
@JsonField("name")
public String i2;
public Byte[] a3;
public Character[] b3;
public Short[] c3;
public Integer[] d3;
public Long[] e3;
public Float[] f3;
public Double[] g3;
public Boolean[] h3;
public String[] i3;
@JsonIgnore
public String i4;
public transient String i5;
public static String i6;
public List<String> k;
public List<Integer> k1;
public Collection<Integer> k2;
public ArrayList<Integer> k3;
public Set<Integer> k4;
public HashSet<Integer> k5;
// fastjson 序列化会崩溃所以忽略掉了,下同
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public List<int[]> k6;
public List<String[]> k7;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public List<List<Integer>> k8;
@JsonIgnore
public List<Map<String, Integer>> k9;
@JsonIgnore
public Map<String, String> l;
public Map<String, List<Integer>> l1;
public Map<Long, List<Integer>> l2;
public Map<Map<String, String>, String> l3;
public Map<String, Map<String, List<String>>> l4;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public SparseArray<SimpleBean2> m1;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public SparseIntArray m2;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public SparseLongArray m3;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public SparseBooleanArray m4;
public SimpleBean2 bean;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public SimpleBean2[] bean1;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public List<SimpleBean2> bean2;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public Set<SimpleBean2> bean3;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public List<SimpleBean2[]> bean4;
@com.alibaba.fastjson.annotation.JSONField(serialize = false, deserialize = false)
public Map<String, SimpleBean2> bean5;
}
测试发现:
- Gson的兼容性最好,能兼容几乎所有的类型,MSON其次,fastjson对嵌套类型支持比较弱。
- 性能方面MSON最好,Gson和fastjson相当。
测试结果如下:
| 序列化方法 | MSON | Gson | fastjson |
|---|---|---|---|
| 序列化耗时(ms) | 20 | 47 | 55 |
| 反序列化耗时(ms) | 1 | 20 | 43 |
MSON本身方法数很少只有60个,在使用时会对每一个标注了JsonType的Bean生成2个方法,分别是:
public String toJson(Bean bean) {...} // 1
public Bean fromJson(String data) {...} // 2
另外MSON不需要对任何类做keep处理。
MSON使用方法
下面介绍MSON的使用方法,流程特别简单:
1. 在Bean上加注解
@JsonType
public class Bean {
public String name;
public int age;
@JsonField("_desc")
public String description; //使用JsonField 标注字段在json中的key
public transient boolean state; //使用transient 不会被序列化
@JsonIgnore
public int state2; //使用JsonIgnore注解 不会被序列化
}
2. 在需要序列化的地方
MSON.fromJson(json, clazz); // 反序列化
MSON.toJson(bean); // 序列化
本文介绍了一种高性能的JSON序列化工具MSON,以及它的产生原因和实现原理。目前我们已经有好多性能要求比较高的地方在使用,可以大幅的降低JSON的序列化时间。
美团平台客户端技术团队长期招聘技术专家,有兴趣的同学可以发送简历到:fangjintao#meituan.com。
详情请点击:详细JD
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK