

React key究竟有什么作用?深入源码不背概念,五个问题刷新你对于key的认知 - 听风是...
source link: https://www.cnblogs.com/echolun/p/16440172.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
学或不学,知识都在那里,只增不减。
React key究竟有什么作用?深入源码不背概念,五个问题刷新你对于key的认知

我在【react】什么是fiber?fiber解决了什么问题?从源码角度深入了解fiber运行机制与diff执行一文中介绍了react对于fiber处理的协调与提交两个阶段,而在介绍协调时又顺带解释了另一个较为重要的概念diff。那既然提到了diff我们还会顺带问一问diff中另一个有趣的概念key,那么现在我来问大家,你是如何理解key的,key又有什么作用呢?请大家思考一会如何回答。
我想,超过一大半的人会说,key在diff时能起到标记的作用,比如往一个数组前面添加一个元素,react通过key能清晰知道它只用新增一个节点,而另外两个节点可以直接复用,从而极大优化性能。
正如官网在介绍key时的例子所言:
当子元素拥有 key 时,React 使用 key 来匹配原有树上的子元素以及最新树上的子元素。以下例子在新增 key 之后使得之前的低效转换变得高效。
<!-- 更新前 -->
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<!-- 更新后 -->
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
现在 React 知道只有带着 '2014' key 的元素是新元素,带着 '2015' 以及 '2016' key 的元素仅仅移动了。
那么这个回答有问题吗?官方都这么说了,那大概是没问题的;但如果我是面试官,我会基于这个回答再抛出如下几个问题:
-
为什么
list渲染时我们不提供key react就会给出警告,而普通dom结构不提供key却不会如此?说说你的理解。 -
react中的key真的有这么聪明吗?在列表渲染时通过key react就能知道哪些是新增的哪些是可以直接复用(仅仅是移动了)? -
我们知道
react的diff是逐层比较的,假设现在有一个数组为:const list = [ {key:2015,value:1}, {key:2016,value:2}, ]我们在更新后
list为:const list = [ {key:2014,value:0}, {key:2015,value:1}, {key:2016,value:2}, ]按照逐层比较的概念,它应该是这样:

那岂不是每一次比较都会认为
key不同?每一层对比后都得重新渲染?那所谓的优化又是怎么做的呢? -
按照
diff逐层对比的逻辑,如果新旧节点的key相等,则证明这个旧节点还可以复用。而我们不提供key时,key将默认为null;既然你又是逐层对比,而此时null === null也为true,也能够复用,那为什么还要提供独一无二的key? -
为什么不推荐使用
index作为key,原因是什么?
通过这五个问题,其实你能发现react官方基于key的解释其实是特别宏观的角度,如果你稍微了解过源码,你甚至会发现官方这个结论还有点经不住推敲,那么就让我们带着这几个问题投身于react源码中,通过这几个问题来重新理解react中的key。
注意,本文的源码分析均基于react 17.0.2版本,那么本文开始。
贰 ❀ 深入理解react中的key
如果你有留意react官方文档,key的解释是在介绍list结构时所强调的概念,这也证明了key对于非list结构并不重要(一般我们直接不加key),这也说明在源码层diff一定会对于是否是list做逻辑区分,简单点来说,针对非list的源码逻辑处理,你加不加key一点也不重要。
老实说,上文我抛出的五个问题的结论其实是彼此关联和依赖的,所以在解释这几个问题之前,我先给出二个比较核心的结论(后面会从源码层解释这个结论):
react对于非list结构的的新旧节点对比确实是逐层对比,但对于list结构且假设添加了独一无二key时并不一定如此。diff对比是先对比key,若key不同直接重新创建节点,若key相同则再对比type(标签类型),如果type不同同样重新创建;因此只有key type都相同时,react才会基于旧节点结合新props生成新节点。
先记住这两个结论,下文我会连着结论以及上文的问题依次给出解释。
贰 ❀ 壹 为什么非list 结构不提供key不会有警告?
站在react设计角度,结合我对于源码的理解,我来说说我的看法。
我们都知道list的节点始终是动态生成的,每次数据的变更都会导致list需要map生成一份新的列表(宏观角度确实是重新遍历生成),站在react的角度,它需要考虑list数据规模大小是否会造成性能问题,所以在diff源码层才有了当key与type都相同时,react会利用旧fiber节点的数据clone一个新的fiber节点,而不是重新创建一个全新的fiber节点。
// 当diff判断新旧节点的key与type都相同时,会使用旧fiber节点以及新的props来clone生成一个全新的fiber
function useFiber(fiber, pendingProps) {
var clone = createWorkInProgress(fiber, pendingProps);
clone.index = 0;
clone.sibling = null;
return clone;
}
而对于list结构,在某些情况下react会使用key来缓存旧fiber节点便于后续对比,缓存的逻辑如下:
function mapRemainingChildren(returnFiber, currentFirstChild) {
// 创建一个map
var existingChildren = new Map();
// 这个是旧fiber节点
var existingChild = currentFirstChild;
// 只要旧fiber节点不会空,就一直遍历
while (existingChild !== null) {
if (existingChild.key !== null) {
// 如果fiber节点的key不会null,那就通过key==>fiber的形式存起来
existingChildren.set(existingChild.key, existingChild);
} else {
// 假设为null,那就用index==>fiber形式存起来
existingChildren.set(existingChild.index, existingChild);
}
// 将existingChild赋予成当前fiber的兄弟节点,然后继续while
existingChild = existingChild.sibling;
}
// 返回缓存后的map
return existingChildren;
}

但需要注意的是,并不是只要是list结构 react就会利用key缓存旧节点。经测试,只有当key独一无二,且key不相同时才会触发缓存逻辑,比如如下情况:
<!-- 更新前 -->
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<!-- 更新后 -->
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
第一次对比时,由于2014 !== 2015,react就会想,你小子是不是在数组前或者数组中间插入了新元素了,为了避免逐层对比导致接下来的每个节点都要重新创建,此时会跳出之前的diff逻辑来到mapRemainingChildren方法,然后把旧节点存在map中,之后再借用map + key来达到旧节点的对比与复用。
而如下例子是在数组之后插入了一个元素,这就导致2015 === 2015,所以react并不会走到缓存逻辑,毕竟你key对比就已经相同了,之后判断type都是li,说明新旧节点可能就只有props不同,那就直接复用更新就好了,没必要去缓存:
<!-- 更新前 -->
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<!-- 更新后 -->
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
<li key="2016">Connecticut</li>
</ul>
所以来到非list情况,dom结构基本上是稳定的,你很难遇到dom插入新节点的场景,更多变化的是模板语法中的变量或者其它样式,所以react也根本没必要利用key去存储这些不怎么变化的节点。
而且站在性能优化的角度,第一大忌就是提前的过度优化。你想想,是list有key还能用key,那些非list不提供key你拿null来存吗?都是null的情况下react怎么知道谁是谁,难道强硬规定所有dom都需要提供key?而且即便强制开发者都提供key存所有fiber节点,你还需要考虑map对于内存占用以及是否会造成内存泄漏的问题,所以想想就知道这样的设计非常不合理。
一句话总结,对于非list结构很难出现dom经常变动的情况,逐层对比就已经满足新旧节点对比的需求;而对于list结构数据会经常变动,当头部或中部插入新数据时,逐层对比会因为对比错位而失效,所以需要key来缓存旧节点,从而借用map修正逐层对比。
贰 ❀ 贰 react的key真的有那么聪明吗?
针对官方所给的例子,假设数组前添加了一个元素,通过key react能知道只用新增一个,其它都只是移动了位置的结论,我更倾向于react需要考虑react初学者,且为了凸显key的作用,所以描述上显得key非常智能,但事实上并不是如此。
function reconcileSingleElement(returnFiber, currentFirstChild, element, lanes) {
// 获取新虚拟dom的key
var key = element.key;
// 旧有的div fiber节点
var child = currentFirstChild;
// 遍历当前节点的以及它的所有兄弟节点,注意下面的child = child.sibling,不为空就一直遍历对比
while (child !== null) {
// 对于非list这里都是null,也相等
if (child.key === key) {
switch (child.tag) {
default:
{
// 只有元素的type类型也相等时,才会走更新fiber的逻辑
if (child.elementType === element.type || (
isCompatibleFamilyForHotReloading(child, element) )) {
deleteRemainingChildren(returnFiber, child.sibling);
// 根据新的虚拟dom的props来更新旧有fiber节点
var _existing3 = useFiber(child, element.props);
// ....
}
break;
}
}
deleteRemainingChildren(returnFiber, child);
break;
} else {
// 如果key不相等,直接在父节点上把自己整个都删掉
deleteChild(returnFiber, child);
}
// 将兄弟节点赋予child,继续走while遍历
child = child.sibling;
}
}
react并不能根据key相同就能断定旧有节点只是移动了,最简单推翻这个结论的例子就是key相同但type不同,比如:
<!-- 更新前 -->
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<!-- 更新后 -->
<div>
<span key="2014">Connecticut</span>
<span key="2015">Duke</span>
<span key="2016">Villanova</span>
</div>
在前面的diff过程我们也说了,因为list对比某些情况还会借用key来缓存旧fiber节点,它起到一个标志作用,比较完key还是需要比较type是否相同,即便type相同我们还不能保证props是否相同,只要你能走到diff这一步,必定是key、type或者props某一个变了,就一定得更新fiber节点,这是毋庸置疑的,所以根本就不存在diff过程中直接完整复用旧节点的说法。
官方的对于旧节点只是移动了其实具有一定的误导性,源码层还是走了clone逻辑,只是相对重新创建代价更小。
贰 ❀ 叁 list 头部插入新元素的diff过程
针对第三个问题,前文也已经说过了,react对于list的diff不一定是逐层的,当你没提供key,或者key提供的是index,这会导致前后节点的key始终相等,从而继续判断type来决定是否更新复用旧fiber节点。
而当list对比且key不同时(数组头部或者中间插入元素时),react会先声明一个map然后以此利用key依次缓存旧fiber节点,之后再根据新的虚拟dom节点的顺序,通过key从这个map里获取旧fiber节点,如果能获取到,那就看看type是否相同,依次判断是否能用旧fiber节点进行更新;如果通过key从map获取不到,那说明这个节点就是一个全新的,直接重新创建。
说到底,key确实起到了标记的作用,但它的标记更多针对的是数组头部或者数组中间插入新数据的场景,只要key不同了,react就知晓不能继续逐层对比了,不然接下来肯定的key肯定会全部不同导致全部重新创建,因此才能根据key的独一无二建立旧fiber的map,并以此更新那些因插入导致原有对比顺序被打乱的旧节点。
接下来给大家展示下当数组头部插入新元素list对比的部分源码,大家可以结合上文在数组头部插入key=2014的例子来理解:
// 当子元素是数组时,会进入此方法进行diff
function reconcileChildrenArray(returnFiber, currentFirstChild, newChildren, lanes) {
// mapRemainingChildren的源码上面解释过了,定义map根据key依次缓存旧节点,注意,只有头部或者中部插入元素,才会触发这里的逻辑
var existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 遍历新的虚拟dom节点
for (; newIdx < newChildren.length; newIdx++) {
// 通过遍历新虚拟dom节点,依次更新旧map存储的节点,具体定义如下
var _newFiber2 = updateFromMap(existingChildren, returnFiber, newIdx, newChildren[newIdx], lanes);
// 删除部分不影响理解的逻辑
}
比如我们在数组前塞了一个key=2014的新节点,react在第一次对比是,发现2014! == 2015,外加上这块又是数组diff的逻辑,所以react会猜测你是不是在数组前面或者中间插入了元素,从而导致key不同,因此才会调用mapRemainingChildren提前把旧fiber存入map。
结合例子,那么此时的newChildren就是三个虚拟dom,然后依次遍历,与mapRemainingChildren返回的map节点做对比更新。紧接着我们来看updateFromMap的实现:
// updateFromMap具体实现
function updateFromMap(existingChildren, returnFiber, newIdx, newChild, lanes) {
// 如果新虚拟节点类型是数字或者字符串,走updateTextNode更新文本的逻辑
if (typeof newChild === 'string' || typeof newChild === 'number') {
var matchedFiber = existingChildren.get(newIdx) || null;
return updateTextNode(returnFiber, matchedFiber, '' + newChild, lanes);
}
// 如果新节点是对象类型
if (typeof newChild === 'object' && newChild !== null) {
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
{
// 利用key(可能是key也可能是index)从map中获取对应的旧fiber节点
var _matchedFiber = existingChildren.get(newChild.key === null ? newIdx : newChild.key) || null;
// 更新旧fiber节点
return updateElement(returnFiber, _matchedFiber, newChild, lanes);
}
}
}
return null;
}
这个方法做的事情也很简单,判断新节点的类型,是数字或者字符串,那就走文本更新的方法,反之就走更新对象的方法。而在对象更新中,我们看到了existingChildren.get()的逻辑,react通过key来获取旧的fiber节点,之后又通过updateElement来做进一步的更新:
function updateElement(returnFiber, current, element, lanes) {
// 判断旧fiber节点是否存在,存在就更新旧fiber节点,否则那就重新创建
if (current !== null) {
// 判断元素类型是否相同,比如前后都是li节点,证明dom类型没变,而
if (current.elementType === element.type || (
isCompatibleFamilyForHotReloading(current, element) )) {
// 根据新的props更新旧有的fiber节点
var existing = useFiber(current, element.props);
existing.ref = coerceRef(returnFiber, current, element);
existing.return = returnFiber;
return existing;
}
} // Insert
// 当旧fiber节点不存在时,既然对比不了,那就直接重新创建了
var created = createFiberFromElement(element, returnFiber.mode, lanes);
created.ref = coerceRef(returnFiber, current, element);
created.return = returnFiber;
return created;
}
在updateElement中我们看到了针对是否能从map中获取到旧节点的不同处理,比如key=2014在map很显然就找不到,这就导致了current是null,于是就走了下面的createFiberFromElement方法完全重新创建。
而当key是2015或者2016时,因为current就是之前的旧fiber节点,于是走了var existing = useFiber(current, element.props)旧节点更新逻辑,而不是重新创建。
贰 ❀ 肆 既然null===null,为什么还需要key?
其实说到这里,我想大家对于这个问题应该也有了一定的理解。对于非list结构而言,确实是否提供key并无重要,反正大家都是逐层对比;而对于list而言,当存在数组头部或中间插入元素时,假设大家提供index作为key或者不提供key,都会导致新旧节点的key全部相等。这就导致了已经错位的节点强行逐层对比,本应该新建的节点因为key相同而走了更新,本应该更新的节点因为key相同结果走了新建。
贰 ❀ 伍 为什么不推荐使用index做为key?
理由在第四个问题已经回答过了,而且核心问题是因为本应该新建的结果你只做了更新,这种情况甚至还能导致bug。官方在介绍key时也给了一个导致bug的例子,我们结合源码来深究为什么使用index导致了这个bug。
例子代码如下:
class Item extends React.Component {
render() {
return (
<div>
<div>
<input type="text" />
</div>
</div>
);
}
}
class Example extends React.Component {
constructor() {
super();
this.state = {
list: [
{ name: "听风是风", id: 1 },
{ name: "行星飞行", id: 2 },
],
};
}
addItem = () => {
const id = +new Date();
this.setState({
list: [{ name: "时间跳跃" + id + id, id }, ...this.state.list],
});
};
render() {
return (
<div className="example">
<button onClick={this.addItem}>clie me</button>
<div className="form">
<form>
<h3>
不好的做法 <code>key=index</code>
</h3>
{this.state.list.map((todo, index) => (
<Item {...todo} key={index} />
))}
</form>
<form>
<h3>
更好的做法 <code>key=id</code>
</h3>
{this.state.list.map((todo) => (
<Item {...todo} key={todo.id} />
))}
</form>
</div>
</div>
);
}
}

简单来说,我们分别使用index以及独一无二的id作为key,然后我们分别在两个form中的第一个input属于一个值,之后点击按钮,分别在数组前插入了一个新数据,然后区别就出现了,index的例子并没有按照预期完整重新创建一个input,这个1本应该属于第二个input。
那么为什么造成了这个bug呢?原因其实很简单,当使用了index作为key时,我们前文也说了,这个input就应该重新创建,结果你用index,0===0为true,type又相同,所以diff直接认为这是一次更新而不是重新创建。
在虚拟dom一文中,我们强调了虚拟dom为局部刷新提供了可能性,因为原生dom属性非常多,如果递归去对比就格外复杂了,但虚拟dom设计直接将我们需要对比的属性都聚焦在了props中,所以即便diff去更新props也只是更新虚拟dom的props,像上文中的input本身就是一个原生dom,它的vaule根本就不在diff比较的范畴内。
而前面也说了,因为index的缘故diff会认为你只是更新,在fiber节点中有一个stateNode字段保存了对应真实dom的属性,所以diff在clone节点时,直接将之前的stateNode赋值给了更新后的fiber节点,这就导致了这个1依旧停留在了第一个input上。
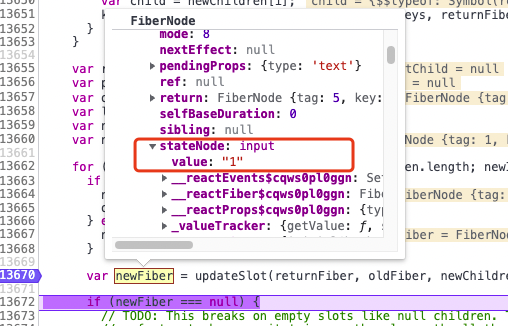
上图就是当第一个fiber更新完成之后,通过stateNode访问到input的value,这就是为啥导致这个bug的原因。
我们通过两张图来描述当数组前插入元素时,使用index或者不提供key默认null时,与使用独一无二key的diff差异:
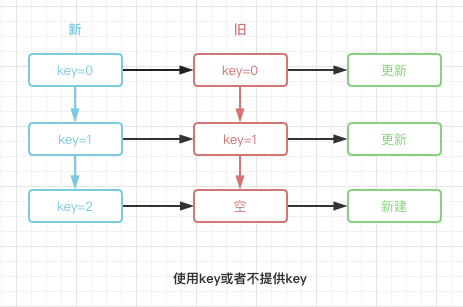
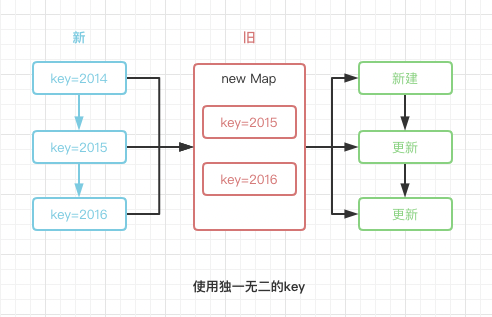
那么到这里,我们解释了文章开头的五个问题,也通过源码解开了key的神秘面纱。简单点来说,key并没有大家所想的那么聪明,但对于list的diff而言又极其重要,react的diff始终遵守逐层对比,也正因为key的存在,不管list如何改变顺序,只有key独一无二,react总是能正确的去更新或者新建它们,这才是key存在的核心意义。
那么到这里,关于key的介绍到此结束。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK