

Pytorch实现波阻抗反演 - GeoFXR
source link: https://www.cnblogs.com/GeophysicsWorker/p/16399257.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Pytorch实现波阻抗反演
地震波阻抗反演是在勘探与开发期间进行储层预测的一项关键技术。地震波阻抗反演可消除子波影响,仅留下反射系数,再通过反射系数计算出能表征地层物性变化的物理参数。常用的有道积分、广义线性反演、稀疏脉冲反演、模拟退火反演等技术。

随着勘探与开发的深入,研究的地质目标已经从大套厚层砂体转向薄层砂体,而利用常规波阻抗反演方法刻画薄层砂体不仅要消耗大量人力、物力,且反演得到的波阻抗精度也难以满足实际需求。近年来,深度学习在地震反演和解释等地震领域显现出了巨大的潜力,其中,卷积神经网络(Convolution Neural Networks,CNN)是解决地震反演的一大有力工具。本文将介绍如何搭建CNN网络进行波阻抗反演。
2 Python环境配置
我们将使用Python语言以及Pytorch深度学习框架完成实验,因此首先需要配置Python环境。
(1)安装Anaconda
下载地址Anaconda | The World's Most Popular Data Science Platform
Anaconda是一个开源的Python和R语言的发行版本,用于计算科学(数据科学、机器学习、大数据处理和预测分析),致力于简化软件包管理系统和部署。
安装过程“下一步、下一步”,在这一步时,勾选添加Anaconda到环境变量(注意:在环境变量中有QT、R语言等时,须在“编辑环境变量”中手动将Anaconda路径下移,防止变量、路径被覆盖)
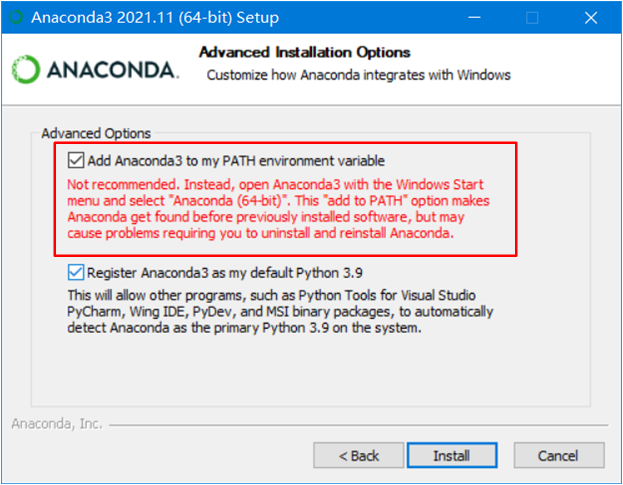
(tips:Python和Anaconda都有蟒蛇的意思)
选择Anaconda主要有几个原因:
- Anaconda的包使用软件包管理系统Conda进行管理,提供了conda install xxx命令,与pip install xxx功能相同。当pip安装库出现一些未知错误时,Conda可以作为补充,省去非必要的报错纠结;
- Anaconda整合了本机中的Python环境与Python包路径,并且提供虚拟环境管理,使得不同Python版本(Python2.x,Python3.x)、CPU/GPU版第三方库可以并列共存。避免了在今后使用中出现版本、路径、环境混乱的问题;
- 下载安装Anaconda可以一键获取新手套装,无需从Python官网从零开始。
随Anaconda一同下载的有
-
Anaconda Navigator:是包含在Anaconda中的图形用户界面,用户可以通过Anaconda Navigator启动应用,在不使用命令行的情况下管理软件包、创建虚拟环境和管理路径。
-
Jupyter Notebook:是一个基于Web的交互式计算环境,用于创建Jupyter Notebook文档。这类文档是一个JSON文档,包含一个有序的输入/输出单元格列表,这些单元格可以包含代码、文本(使用Markdown语言)、数学、图表和富媒体 (Rich media),通常以“.ipynb”结尾扩展。Jupyter Notebook的最大的优点就是可以“做一步看一步”,对于初学和开荒Python项目时,可以更简单、高效地编程。
-
Spyder,是一个开源、免费的Python集成开发环境(IDE)。其最大优点是模仿MATLAB的“工作空间”的功能,便于观察变量的值、维度、类型等信息。
-
Anaconda Prompt:等同Window PowerShell和cmd。
(2)安装Pycharm
下载地址Download PyCharm: Python IDE for Professional Developers by JetBrains
由捷克JetBrains公司专为Python打造,PyCharm具备一般IDE的功能,比如,调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制等等。PyCharm是商业软件,与Visual Stidio类似,有收费的专业版(Professional)和免费的社区版(Community),社区版能够满足一般编程需要,专业版集成了Jupyter Notebook并且支持远程开发。
下载Community版后,安装过程除了调整路径外,没有需要操作的地方,非必须的可选项都不打勾,然后“下一步下一步”。
安装完成后来到新建工程,以及配置Python环境的环节:
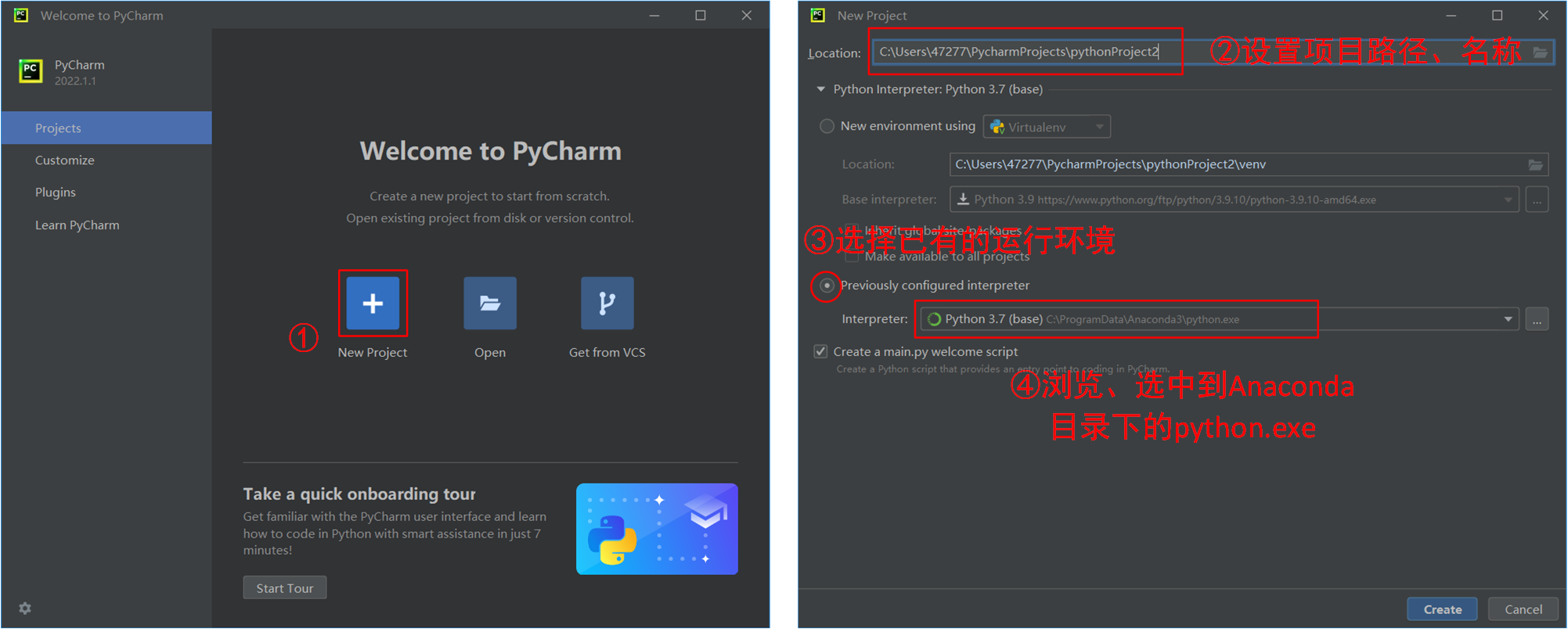
第一次创建工程、加载环境需要等上几分钟,读条完成后,这个工程的Python环境及编辑器就配置完成了。
3 Pytorch实战
首先我们需要在本地安装Pytorch,打开Anaconda Prompt或Window PowerShell或cmd,安装指令为
pip install torch torchvision torchaudio
或者
conda install pytorch torchvision torchaudio cpuonly -c pytorch
即可安装CPU版Pytorch(GPU版的安装稍复杂,此处不作详细介绍),随后开始本次项目的实战部分。
(1)数据准备
Step 1 导入数据
导入的数据包括地震记录,此处的数据已经被整理存储为.mat格式,通过scipy.io库将其读入。地震道与波阻抗数据都是文件中的键值对,从原始数据中抽取出部分作为实验数据集。
dataframe = sio.loadmat('Train_DataSyn_Ricker30.mat')
#从文件中分别提取提取地震道与波阻抗数据
Seismic_data = dataframe['Seismic'] #地震道
Impedance_data = dataframe['Imp']/1e6 #波阻抗
#随机抽取部分道,作为训练集
howMany = 2020
np.random.seed(9) #随机种子,便于复现
indxRand = [randint(0,dataframe['Seismic'].shape[1]-1) for p in range(0,howMany)] #随机索引
#地震道
Seismic_data = Seismic_data.transpose() #转置
Seismic_data = Seismic_data[indxRand,:] #通过索引抽取
#波阻抗
Impedance_data = Impedance_data.transpose()
Impedance_data = Impedance_data[indxRand,:]
数据展示如下:
我们的目标即是通过建立CNN模型挖掘规律,建立地震振幅属性⟹⟹波阻抗的映射,在未知波阻抗的地方可用地震记录进行预测,实现波阻抗反演。
Step 2 分割数据集
通常一个机器学习项目会需要我们对数据集进行分割,划分为训练集(建模)、验证集(调整超参数与初步评估)和测试集(评估模型)。
#其中验证集500个,测试集1000个,剩余(520)为训练集
howManyToValidate = 500
howManyToTest = 1000
#对输入Seismic与标签Imp进行相同的索引与处理
#用numpy索引切片的方式进行划分
valX = (Seismic_data[:howManyToValidate,:])
testX = (Seismic_data[howManyToValidate:howManyToValidate+howManyToTest,:])
trainX = (Seismic_data[howManyToValidate+howManyToTest:,:])
valImp = (Impedance_data[:howManyToValidate,:])
testImp = (Impedance_data[howManyToValidate:howManyToValidate+howManyToTest,:])
trainImp = (Impedance_data[howManyToValidate+howManyToTest:,:])
#转为torch中的Tensor格式
#此时数据为(道数,采样点数)的二维数组,按照torch的输入格式整理为(道数,数据高度,数据长度),便于后续输入道CNN网络中
valX = torch.FloatTensor(np.reshape(valX, (valX.shape[0], 1, valX.shape[1])))
testX = torch.FloatTensor(np.reshape(testX, (testX.shape[0], 1, testX.shape[1])))
trainX = torch.FloatTensor(np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1])))
valImp = torch.FloatTensor(np.reshape(valImp, (valImp.shape[0], 1, valImp.shape[1])))
testImp = torch.FloatTensor(np.reshape(testImp, (testImp.shape[0], 1, testImp.shape[1])))
trainImp = torch.FloatTensor(np.reshape(trainImp, (trainImp.shape[0], 1, trainImp.shape[1])))
(2) 建模
Step 1 建立网络
采用一维卷积神经网络(1D CNN)进行波阻抗的生成与预测,具体步骤与结构如下图。
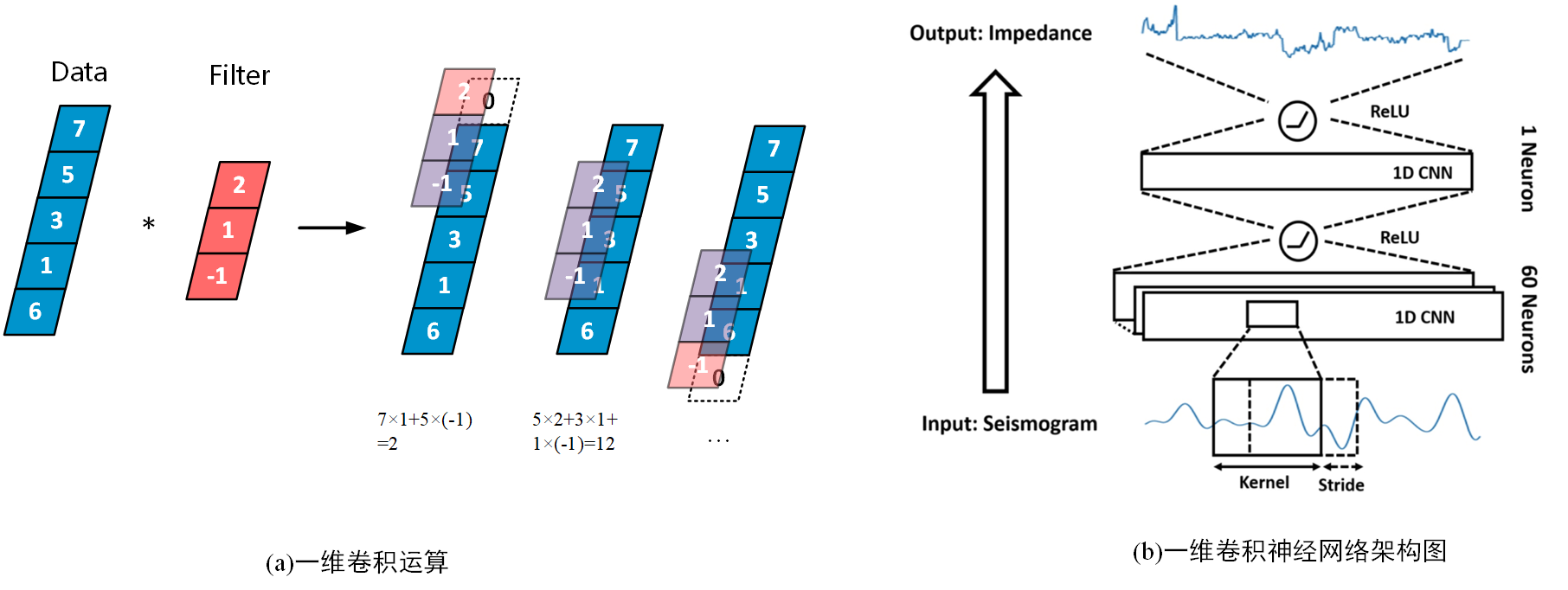
创建神经网络通常也就是创建一个继承自torch.nn.Module的类,而将网络层及其连接定义在类中的方法中
noOfNeurons = 60 #定义卷积核个数
dilation = 1
kernel_size = 300 #卷积核尺寸
stride = 1 #卷积核滑动步长
padding = int(((dilation*(kernel_size-1)-1)/stride-1)/2) #0填充个数
class CNN(nn.Module):
def __init__(self): #构造函数
super(CNN, self).__init__() #前面三行为固定格式
self.layer1 = nn.Sequential( #nn.Sequential为一个顺序的容器
#Conv1d的前两个参数分别表示输入通道数与输出通道数,又有卷积核个数=卷积层输出通道数
nn.Conv1d(1, noOfNeurons, kernel_size=kernel_size, stride=1, padding = padding+1),#卷积层
nn.ReLU()) #ReLu激活函数
self.layer2 = nn.Sequential(
nn.Conv1d(noOfNeurons, 1, kernel_size=kernel_size, stride=1, padding = padding+2),
nn.ReLU())
def forward(self, x): #在forward中将网络像搭积木一样连接起来
out = self.layer1(x)
out = self.layer2(out)
return out
cnn = CNN() #实例对象
注:①在PyTorch中,可以把神经网络类中forward函数看作一个专用函数,它专门用于编写前向传播的计算方法,并且已经写在了nn.Module的“出厂设置”中,在传入数据时便会开始执行,如上例中,使用cnn(x)本质上等于cnn.forward(x),显式使用后者反而报错。
②关于激活函数
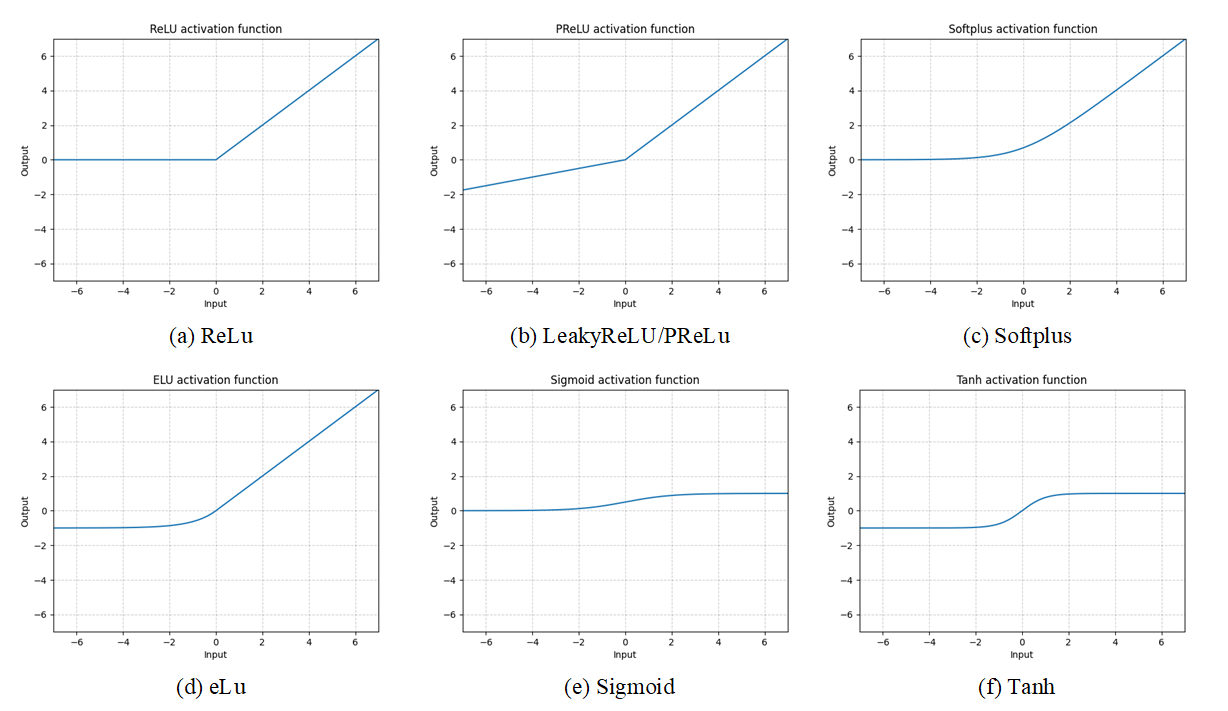
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,能够完成极其复杂的分类或回归任务。若没有激活函数,则每层就相当于矩阵乘法。
Sigmoid——nn.Sigmoid()
Sigmoid(x)=σ(x)=11+exp(−x)Sigmoid(x)=σ(x)=11+exp(−x)
优点:
能够将函数压缩至区间[0,1]之间,保证数据稳定,波动幅度小
缺点:
- 函数在两端的饱和区梯度趋近于0,当反向传播时容易出现梯度消失或梯度爆炸
- 输出不是0均值(zero-centered),导致收敛缓慢
- 运算量较大
如果我们在多个层中堆叠sigmoid,则系统学习效率可能低下,并且需要仔细初始化。因此,对于深度神经网络,首选ReLU函数。
ReLU(Rectified Linear Unit,修正线性单元)——nn.ReLU()
ReLU(x)=(x)+=max(0,x)ReLU(x)=(x)+=max(0,x)
优点:
- 梯度不饱和,收敛速度快
- 减轻反向传播时梯度弥散的问题
- 无需进行指数运算,运算速度快、复杂度低
缺点:
- 输出不是0均值(zero-centered)
- 对参数初始化和学习率非常敏感,容易出现神经元死亡。
常用的激活函数还有许多:
Step 2 定义训练参数
#定义与训练有关的超参数
num_epochs = 500 #迭代轮数
batch_size = 1 #批次大小
learning_rate = 0.001 #学习率
batch_size_tot = trainX.shape[0]
no_of_batches = int((batch_size_tot - batch_size_tot%batch_size)/batch_size) #总批数
loss_fn = nn.MSELoss() #损失函数,此处为一个回归任务,采用均方根误差作为损失值
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate) #优化器选择为Adam
注:①pytorch中的nn模块提供了很多可以直接使用的loss函数,常用的有:
| 损失函数 | 名称 | 适用场景 |
|---|---|---|
| torch.nn.MSELoss() | 均方误差损失 | 回归 |
| torch.nn.L1Loss() | 平均绝对值误差损失 | 回归 |
| torch.nn.CrossEntropyLoss() | 交叉熵损失 | 多分类 |
| torch.nn.BCELoss() | 二分类交叉熵损失 | 二分类 |
| torch.nn.MultiLabelMarginLoss() | 多标签分类的损失 | 多标签分类 |
②使用Loss函数会对每个样本计算其损失,然后开始梯度下降去降低损失w+=−αdxw+=−αdx,最基础的是一次优化输入一个样本的随机梯度下降(Stochastic gradient descent,SGD),或是一个小批次(Mini-batch)。除此之外还有很多种不同的优化器,torch.optim是一个实现了各种优化算法的库。它们采取不同的策略更新梯度,比初始的梯度下降更加高效:
| 函数 | 描述 | 公式 |
|---|---|---|
| torch.optim.SGD | SGD算法 | w=w−ηn∑ni=1∇Ji(w)w=w−ηn∑i=1n∇Ji(w) |
| torch.optim.SGD (Momentum=0.9...) |
Momentum算法 | m=b1∗m−αdxm=b1∗m−αdx w=w+mw=w+m |
| torch.optim.AdaGrad | AdaGrad算法 | v=v+dx2v=v+dx2 w=w−α∗dxv√w=w−α∗dxv |
| torch.optim.RMSProp | RMSprop算法 (Root Mean Square Prop) |
Momentum+AdaGrad v=b1∗v+(1−b1)∗dx2v=b1∗v+(1−b1)∗dx2 w=w−α∗dxv√w=w−α∗dxv |
| torch.optim.Adam | Adam算法 (Adaptive momentum) |
m=b1∗m+(1−b1)∗dxm=b1∗m+(1−b1)∗dx v=b2∗v+(1−b2)∗dx2v=b2∗v+(1−b2)∗dx2 w=w−α∗mv√w=w−α∗mv |
Step3 训练
for epoch in range(num_epochs): #开始迭代
for i in range(no_of_batches):
#地震道数据
#通过手动索引的方式建立batch
#使用Variable对Tensor进行封装,便于改变Tensor的.data、.grad、.grad_fn属性
traces = Variable(trainX[i*batch_size:(i+1)*batch_size,:,:])
imp_label = Variable(trainImp[i*batch_size:(i+1)*batch_size,:,:])
'''以下5行代码为固定格式,几乎所有pytorch网络都是同样的'''
outputs = cnn(traces) #将训练数据输入道cnn模型中,前向传播
loss = loss_fn(outputs, imp_label) #计算损失
optimizer.zero_grad() #每一批次计算完成后梯度清零
loss.backward() #反向传播
optimizer.step() #梯度更新
#然后在每一批次训练完成后,用交叉验证集检验
traces_val = Variable(valX)
outputs_val = cnn(traces_val)
imp_val = Variable(valImp)
loss_val = loss_fn(outputs_val, imp_val)
#打印
print ('Epoch [%d/%d], Iter [%d], Train Loss: %.6f, Validation Loss: %.6f'
%(epoch+1, num_epochs, i+1, loss.data.cpu().numpy(), loss_val.data.cpu().numpy()))
输出如下:
Epoch [1/500], Iter [1400], Train Loss: 0.357334, Train Loss: 0.099698, Validation Loss: 0.489520, Validation Loss: 0.121744
Epoch [2/500], Iter [1400], Train Loss: 0.279390, Train Loss: 0.088157, Validation Loss: 0.453510, Validation Loss: 0.117180
Epoch [3/500], Iter [1400], Train Loss: 0.249917, Train Loss: 0.083377, Validation Loss: 0.435483, Validation Loss: 0.114828
Epoch [4/500], Iter [1400], Train Loss: 0.277595, Train Loss: 0.087873, Validation Loss: 0.431772, Validation Loss: 0.114337
...
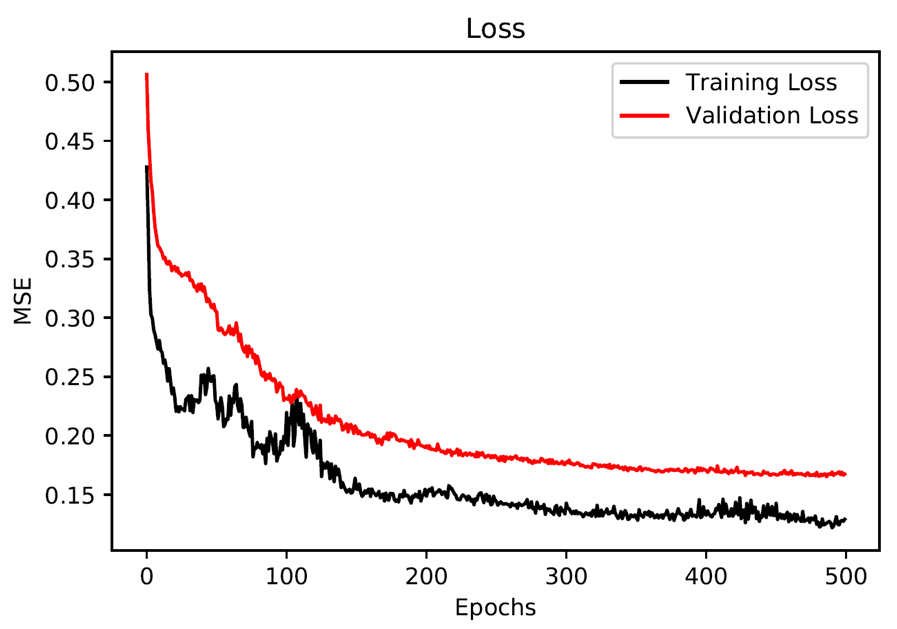
模型的损失值曲线图如下:
(3)预测
Step 1 预测测试集
通常测试集也是有标签的,我们能够直观地对比模型的预测效果与精度。
#抽取出待测的地震道
sampleNumber = 25
TestingSetSeismicTrace = Variable(testX[sampleNumber:sampleNumber+1,:,:]) #输入数据
CNN_ImpedancePrediction = cnn(TestingSetSeismicTrace) #预测结果
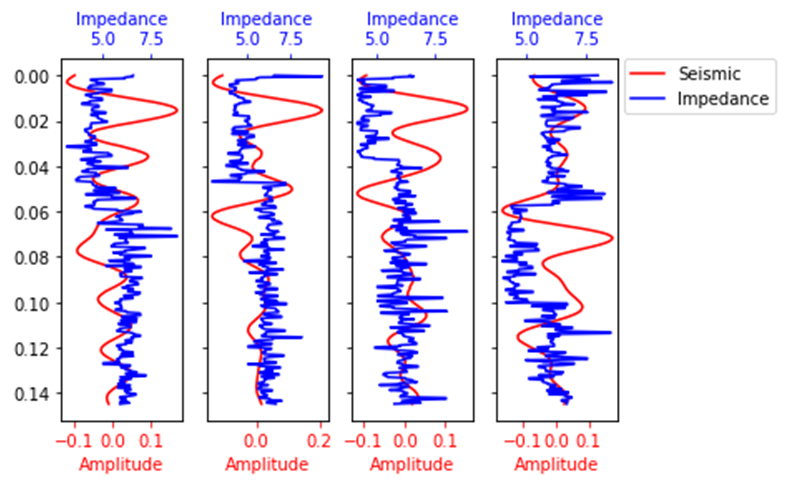
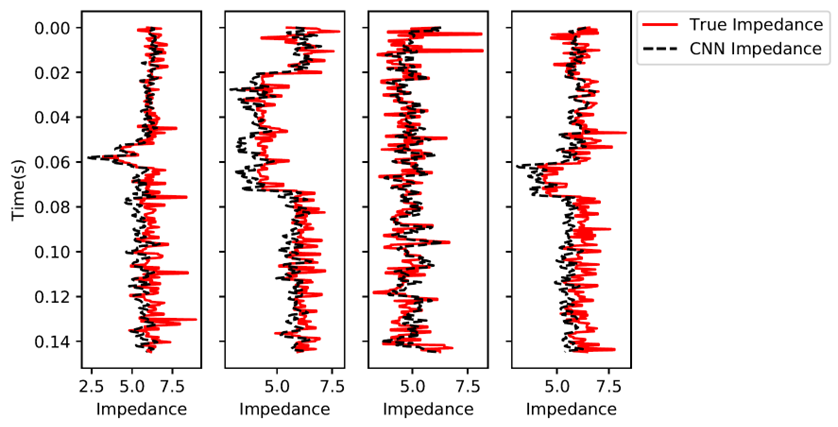
图中展示了4道的真实波阻抗与CNN预测波阻抗:
Step 2 保存&加载模型
训练一次模型往往需要花费很长时间,将模型保存下来,在需要的时候载入,避免关闭程序后再重新训练。
#保存模型
with open('cnn.pkl', 'wb') as pickle_file:
torch.save(cnn.state_dict(), pickle_file)
#加载模型
#加载时需要先实例化对象
cnn_new = CNN()
with open('cnn.pkl', 'rb') as pickle_file:
cnn_new.load_state_dict(torch.load(pickle_file))
Step 3 应用
应用时往往没有标签(波阻抗),需要模型由已知数据预测未知。
dataframe = sio.loadmat('HardTest_DataSyn_Ricker30.mat')
TestingSeismic = dataframe['wz_with_multiples']
TestingSeismic = TestingSeismic.transpose()[:, 0:333]
TestingImpedance = dataframe['IpTimeVec']/1e6
TestingImpedance = TestingImpedance.transpose()[:, 0:333]
print(TestingImpedance.shape[1])
sampleNumber = 25
#抽取应用数据的地震道
AppSeismicTrace = AppSeismic[sampleNumber,:]
#Numpy.array-->Tensor-->Variable
AppSeismicTraceTorch = torch.FloatTensor(np.reshape(AppSeismicTrace, (1,1, AppSeismicTrace.shape[0]))) #输入尺寸与训练集保持一致,第一个1表示应用当前单个样本
AppSeismicTraceTorch = Variable(AppSeismicTraceTorch) #封装成Variable
#用加载的cnn_new模型去预测
CNN_ImpedancePrediction = cnn_new(AppSeismicTraceTorch)
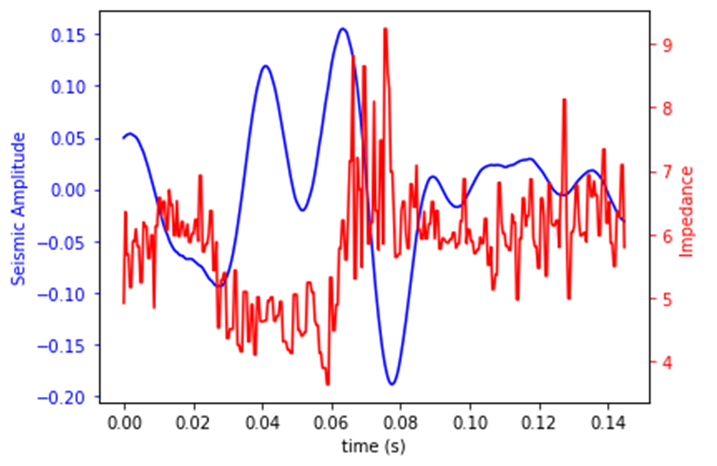
于是,我们便完成了,通过建立神经网络模型,从地震记录反演波阻抗的整个过程。
import torch.nn as nn
import torch.autograd
from torch.autograd import Variable
import scipy.io as sio
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import numpy as np
from random import randint
#******************导入数据*********************
dataframe = sio.loadmat('Train_DataSyn_Ricker30.mat')
#从文件中分别提取提取地震道与波阻抗数据
Seismic_data = dataframe['Seismic'] #地震道
Impedance_data = dataframe['Impedance']/1e6 #波阻抗
#随机抽取部分道,作为训练集
howMany = 2020
np.random.seed(9) #随机种子,便于复现
indxRand = [randint(0,dataframe['Seismic'].shape[1]-1) for p in range(0,howMany)] #随机索引
#地震道
Seismic_data = Seismic_data.transpose() #转置
Seismic_data = Seismic_data[indxRand,:] #通过索引抽取
#波阻抗
Impedance_data = Impedance_data.transpose()
Impedance_data = Impedance_data[indxRand,:]
dt = 4.3875e-4
time = np.linspace(0,(Seismic_data.shape[1]-1)*dt,Seismic_data.shape[1])
#*********************分割数据集****************************
#其中验证集500个,测试集1000个,剩余(520)为训练集
howManyToValidate = 500
howManyToTest = 1000
#对输入Seismic与标签Imp进行相同的索引与处理
#用numpy索引切片的方式进行划分
valX = (Seismic_data[:howManyToValidate,:])
testX = (Seismic_data[howManyToValidate:howManyToValidate+howManyToTest,:])
trainX = (Seismic_data[howManyToValidate+howManyToTest:,:])
valImp = (Impedance_data[:howManyToValidate,:])
testImp = (Impedance_data[howManyToValidate:howManyToValidate+howManyToTest,:])
trainImp = (Impedance_data[howManyToValidate+howManyToTest:,:])
#转为torch中的Tensor格式
#此时数据为(道数,采样点数)的二维数组,按照torch的输入格式整理为(道数,数据高度,数据长度),便于后续输入道CNN网络中
valX = torch.FloatTensor(np.reshape(valX, (valX.shape[0], 1, valX.shape[1])))
testX = torch.FloatTensor(np.reshape(testX, (testX.shape[0], 1, testX.shape[1])))
trainX = torch.FloatTensor(np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1])))
valImp = torch.FloatTensor(np.reshape(valImp, (valImp.shape[0], 1, valImp.shape[1])))
testImp = torch.FloatTensor(np.reshape(testImp, (testImp.shape[0], 1, testImp.shape[1])))
trainImp = torch.FloatTensor(np.reshape(trainImp, (trainImp.shape[0], 1, trainImp.shape[1])))
#********************建模*********************
noOfNeurons = 60 #定义卷积核个数
dilation = 1
kernel_size = 300 #卷积核尺寸
stride = 1 #卷积核滑动步长
padding = int(((dilation*(kernel_size-1)-1)/stride-1)/2) #0填充个数
class CNN(nn.Module):
def __init__(self): #构造函数
super(CNN, self).__init__() #前面三行为固定格式
self.layer1 = nn.Sequential( #nn.Sequential为一个顺序的容器
#Conv1d的前两个参数分别表示输入通道数与输出通道数,又有卷积核个数=卷积层输出通道数
nn.Conv1d(1, noOfNeurons, kernel_size=kernel_size, stride=1, padding = padding+1),#卷积层
nn.ReLU()) #ReLu激活函数
self.layer2 = nn.Sequential(
nn.Conv1d(noOfNeurons, 1, kernel_size=kernel_size, stride=1, padding = padding+2),
nn.ReLU())
def forward(self, x): #在forward中将网络像搭积木一样连接起来
out = self.layer1(x)
out = self.layer2(out)
return out
cnn = CNN() #实例对象
#*************************训练************************
#定义与训练有关的超参数
num_epochs = 500 #迭代轮数
batch_size = 1 #批次大小
learning_rate = 0.001 #学习率
batch_size_tot = trainX.shape[0]
no_of_batches = int((batch_size_tot - batch_size_tot%batch_size)/batch_size) #总批数
loss_fn = nn.MSELoss() #损失函数,此处为一个回归任务,采用均方根误差作为损失值
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate) #优化器选择为Adam
for epoch in range(num_epochs): #开始迭代
for ii in range(no_of_batches):
#地震道数据
#通过手动索引的方式建立batch
#使用Variable对Tensor进行封装,便于改变Tensor的.data、.grad、.grad_fn属性
traces = Variable(trainX[ii*batch_size:(ii+1)*batch_size,:,:])
imp_label = Variable(trainImp[ii*batch_size:(ii+1)*batch_size,:,:])
'''以下5行代码为固定格式,几乎所有pytorch网络都是同样的'''
outputs = cnn(traces) #将训练数据输入道cnn模型中,前向传播
loss = loss_fn(outputs, imp_label) #计算损失
optimizer.zero_grad() #每一批次计算完成后梯度清零
loss.backward() #反向传播
optimizer.step() #梯度更新
#然后在每一批次训练完成后,用交叉验证集检验
traces_val = Variable(valX)
outputs_val = cnn(traces_val)
imp_val = Variable(valImp)
loss_val = loss_fn(outputs_val, imp_val)
#打印
print ('Epoch [%d/%d], Iter [%d], Train Loss: %.6f, Validation Loss: %.6f'
%(epoch+1, num_epochs, ii+1, loss.data.cpu().numpy(), loss_val.data.cpu().numpy()))
#**********************测试集可视化对比**************************
#取出4道
sampleNumbers = np.array([21,50,162,206])
fig, axs = plt.subplots(1, 4, sharey=True)
axs[0].invert_yaxis()
fig.suptitle('Samples of Testing Data Predictions')
for i in range(4):
sampleNumber = sampleNumbers[i];
TestingSetSeismicTrace = Variable(testX[sampleNumber:sampleNumber+1,:,:])
CNN_ImpedancePrediction = cnn(TestingSetSeismicTrace)
#Numpy数据作图用
TestingSetSeismicTrace = testX[sampleNumber,:].numpy().flatten()
TestingSetImpedanceTrace = testImp[sampleNumber,:].numpy().flatten()
CNN_ImpedancePrediction = CNN_ImpedancePrediction.data.cpu().numpy().flatten()
line1, = axs[i].plot(TestingSetImpedanceTrace, time, 'r-')
axs[i].set_xlabel('Impedance')
if i==0:
axs[i].set_ylabel('Time(s)')
line2, = axs[i].plot(CNN_ImpedancePrediction, time, 'k--')
lgd = plt.legend((line1, line2), ('True Impedance', 'CNN Impedance'), bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
#********************模型保存&加载*********************
#保存模型
with open('cnn.pkl', 'wb') as pickle_file:
torch.save(cnn.state_dict(), pickle_file)
#加载模型
#加载时需要先实例化对象
cnn_new = CNN()
with open('cnn.pkl', 'rb') as pickle_file:
cnn_new.load_state_dict(torch.load(pickle_file))
#**********************应用************************
Appdataframe = sio.loadmat('HardTest_DataSyn_Ricker30.mat')
AppSeismic = Appdataframe['Seismic']
AppSeismic = AppSeismic.transpose()
sampleNumber = 25
#抽取应用数据的地震道
AppSeismicTrace = AppSeismic[sampleNumber,:]
#Numpy.array-->Tensor-->Variable
AppSeismicTraceTorch = torch.FloatTensor(np.reshape(AppSeismicTrace, (1,1, AppSeismicTrace.shape[0]))) #输入尺寸与训练集保持一致,第一个1表示应用当前单个样本
AppSeismicTraceTorch = Variable(AppSeismicTraceTorch) #封装成Variable
#用加载的cnn_new模型去预测
CNN_ImpedancePrediction = cnn_new(AppSeismicTraceTorch)
#作图
fig, ax1 = plt.subplots()
ax1.plot(time, AppSeismicTrace, 'b-')
ax1.set_xlabel('time (s)')
ax1.set_ylabel('Seismic Amplitude', color='b')
ax1.tick_params('y', colors='b')
ax2 = ax1.twinx()
ax2.plot(time, CNN_ImpedancePrediction.detach().numpy().flatten(), 'r-')
ax2.set_ylabel('Impedance', color='r')
ax2.tick_params('y', colors='r')
fig.tight_layout()
plt.show()
引用文献
[1] Vishal Das;Ahinoam Pollack;Uri Wollner;Tapan Mukerji.Convolutional neural network for seismic impedance inversion[J].Geophysics,2019,Vol.84(6): R869-R880
[2]王治强. 稀疏脉冲反褶积及其波阻抗反演研究[D].中国石油大学(北京),2018.DOI:10.27643/d.cnki.gsybu.2018.001091.
[3] Activation and loss functions (part 1) · Deep Learning (atcold.github.io)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK