

How we deploy to production over 100 times a day
source link: https://monzo.com/blog/2022/05/16/how-we-deploy-to-production-over-100-times-a-day
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
How we deploy to production over 100 times a day
Read the articleOur success relies on us rapidly shipping new features to customers. This tight feedback loop helps us quickly validate our ideas. We can double down on the ideas that are working, and fail fast if we need to.
To achieve this rapid release cadence, we’ve optimised our engineering culture, tooling, and architecture to make the path from idea to production as frictionless as possible, all without sacrificing safety. We believe our approach gets us the best of both worlds: less friction encourages smaller changes, and smaller changes are less risky.
Slow and risky - the worst of both worlds!
Successful startups move quickly. It’s how they can compete with companies who have 1000x the resources. But as companies grow they get slow.
The cost of failure increases, so arduous change management processes are introduced.
More engineers are working on the same system and get in the way of each other.
Lots of new engineers are onboarded, so the effort expended in understanding the system increases.
Not only does this slow things down, it makes releases riskier too. All this red tape means engineers start to batch up changes into “big bang” releases that are more risky and much harder to roll back if they go wrong. This insight is not new. It's one of the core principles behind the DevOps movement (check out the Accelerate book for more).
At Monzo, we tackle this problem in the other direction: optimise the developer workflow for rapid delivery, and this leads to a reduction in risk too.
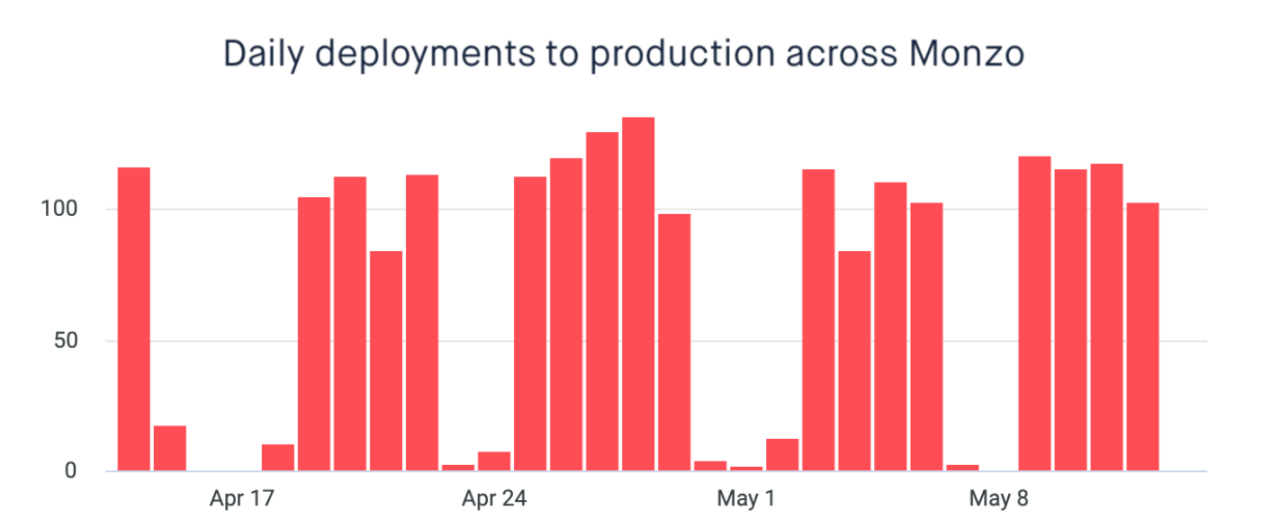
Our data backs this up. In the past year we have scaled up the number of people in our engineering discipline from 148 to 232. A 60% increase. As expected, the total number of deployments has gone up, but we are more satisfied to see an increase in the average number of deployments per engineer.
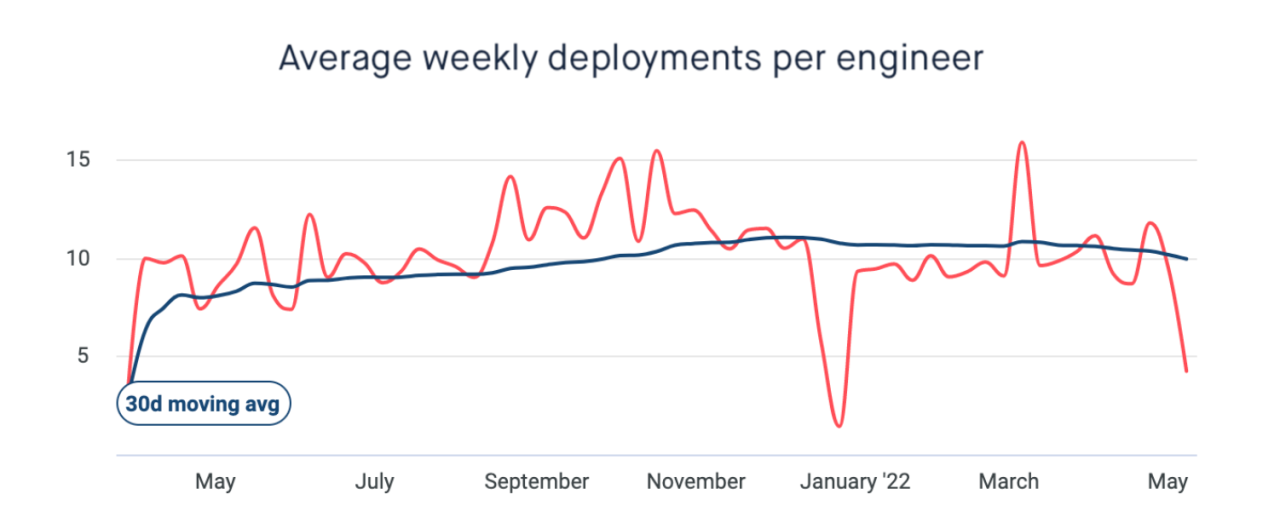
This is all while seeing a significant reduction in incidents, and the average number of rollbacks per deployment has remained relatively constant.
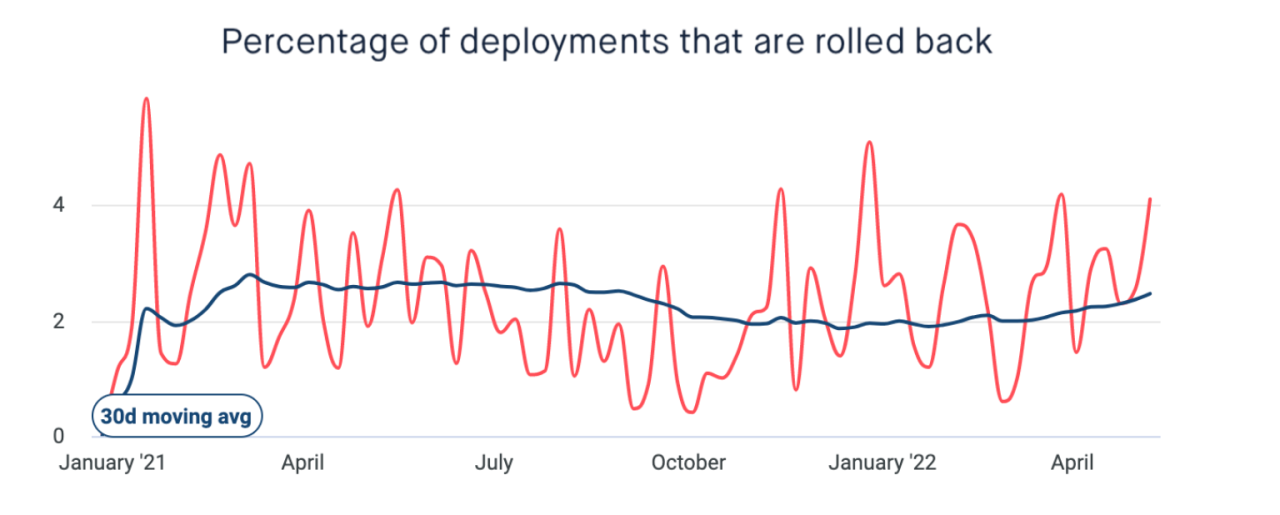
It’s worth pointing out that these metrics are just proxies. The number of deployments does not necessarily correspond directly to customer value. And the number of rollbacks does not necessarily correspond to negative customer impact. You should be very cautious at setting targets on these metrics because it could lead to perverse incentives. For example you might end up with lots of pointlessly small deployments with trivial customer value. When a measure becomes a target, it ceases to be a good measure (Goodhart’s law).
Small revertable changes
Fundamentally our aim is to deploy small changes. A small change is quicker to implement, and quicker to validate. Fewer things changing at once implies a smaller blast radius if things go wrong, and smaller changes are typically easier to revert.
Any friction in the workflow from idea to production will encourage engineers to batch up changes. Need sign-off from 2 senior engineers to deploy a change? Batch up changes! Need to manually deploy through 4 pre-prod environments? Batch up changes! Need to wait until another engineer has finished testing their changes? Batch up changes!
Our engineering culture
For a bank, our change management process is surprisingly light on human touch points: one review from an engineer on the owning team, and you can merge and deploy to production. But it’s worth highlighting that this is the minimum.
What we do instead is invest heavily in out-of-the-box guardrails, monitoring, and auditing to make mistakes less likely, and quicker to recover from when they inevitably do happen. For example:
Our deployment pipeline blocks invalid operations, like deploying a version to production that has not been deployed to staging.
Our deployment pipeline records events of what happened, and when. So we can easily find out why things went wrong and stop it happening again.
Our request middleware emits many metrics by default, which can be viewed in a pre-built Grafana dashboard. We have generic alerts configured for these metrics.
Our deployment CLI warns engineers if there are unapplied database migrations or undeployed commits from a different branch.
But there’s lots more to be done! For example our Backend Platform team is currently in the process of shipping automated rollback based on the same metrics used for our generic alerts.
An essential component of this decentralised approach to change management is transparency. If engineers further down the org structure are making decisions around risk, they need to have the context around the risk tolerance of the wider business. To do this we share the business’ risk appetite for incidents, and track our performance against specific targets. We associate “tiers” with each service (how critical they are) and warn when PRs make changes to critical ones. This helps engineers get a sense of the relative risk of a change.
Here’s an example of an automated Github comment that is made when a service on the “hot path” is modified
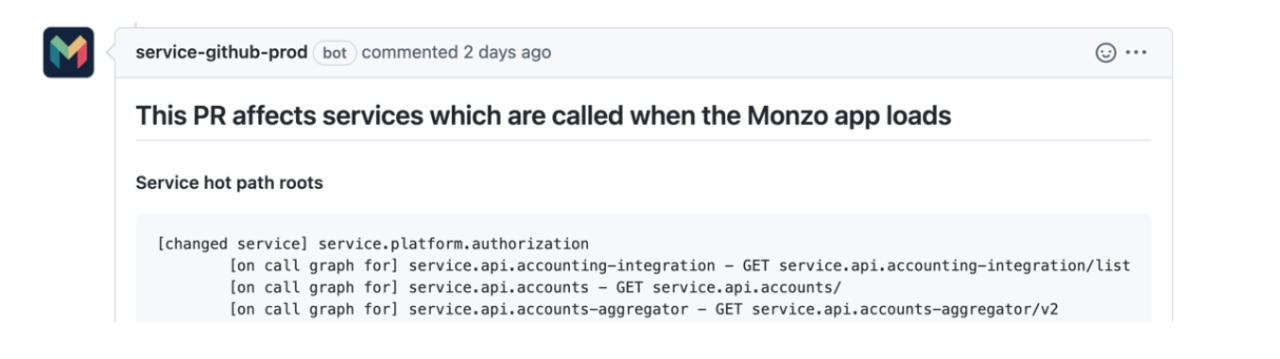
Not only do engineers need to feel confident about the changes they are making - they also need to know they won’t be blamed if things do go wrong. One of our company wide values is “be hard on problems, not on people”. Blaming people is a cop out. It doesn’t help them or the business improve. Instead we identify gaps in our process/guardrails/checks that could be tightened.
Tooling and architecture
The engineering culture we want to encourage is supported by our tooling. Our culture also shapes the design of tooling, so it’s a virtual cycle. Here are some of the principles we use when designing our tools.
We want engineers to enjoy interacting with our deployment tooling. It should be delightful to use. We bias towards a simple and opinionated user experience, over configurability. This means that while we use some complex systems behind the scenes (e.g. Kubernetes), engineers rarely need to interact with them directly. This does mean we have to build and maintain more, but we think the trade off is worth it.
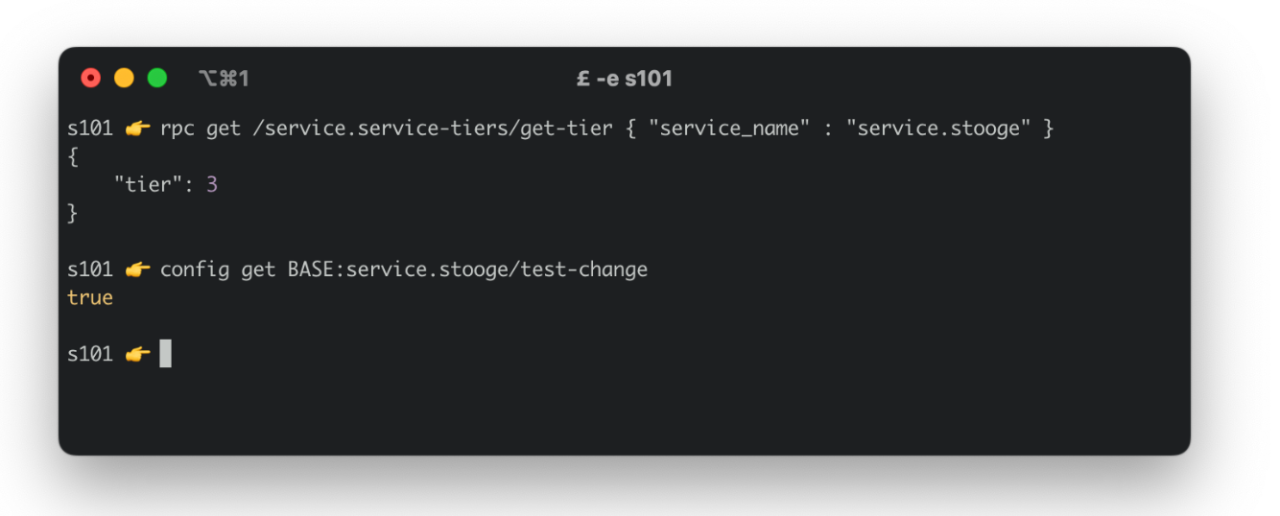
Here’s an example of a developer using our CLI to make an RPC to the service.service-tiers service, and fetching the config for service.stooge
The workflow is consistent and familiar. We put a large emphasis on technological consistency. We broadly use the same limited set of technologies for each service (programming languages (Go), libraries/frameworks, databases, deployment tooling, etc). This reduces the friction when engineers move between services, and it also means documentation, guardrails and checks can be reused.
We continue to invest in automating our deployment process. Deployments to staging and production are currently triggered with a single CLI command. We have a continuous delivery pipeline for our infrastructure changes, and would like to invest in something similar for service deployments. An unintended side effect of reducing friction from the deployment process is we see too many changes being deployed to staging for testing. This increases the number of manual steps engineers take in order to test out changes. This is something to watch out for! We’re actively working on improving our local development workflow to combat this.
Lastly we want to minimise contention. As we hire more engineers there is an increased chance that a release from one engineer might block changes from another engineer. We’ve chosen to tackle this at the architectural level. We’ve adopted a microservices architecture. We run over 2000 services and counting! There are certainly challenges to this (that’s for another post!), but a big advantage is the small unit of deployment. Each service can be deployed entirely independently. The chance of multiple engineers working on the same service is low, so the chance of contention is low.
Focus on the principles
Focussing on these principles has helped us to maintain a quick release cadence during a period of growth. And we think we can make the process even more efficient. There is still a lot to do!
The things you need to build will likely be quite different in your context. Even for us, the supporting tools and guardrails will change as we grow and our risk appetite changes, but the principles remain timeless.
If you want to help us deploy 200 times a day, please apply! We're always on the look out for Backend Engineers and Engineering Managers to join us!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK