

[译]用 Go 语言编写一个微服务博客 — 第五部分 — 在 Docker Swarm 上进行部署
source link: https://www.sulinehk.com/post/write-a-microservice-blog-in-golang-part5/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
原文链接:Go microservices, part 5 - deploying on Docker Swarm
在第 5 部分中,我们将启动 accountservice,在本地部署的 Docker Swarm 集群上运行,并讨论容器编排的核心概念。
这篇博客文章涉及以下内容:
- Docker Swarm 和容器编排
- 使用 Docker 容器化我们的 accountservice
- 搭建本地 Docker Swarm 集群
- 将 accountservice 部署为 Swarm 服务
- 运行基准测试并收集指标
![]()
什么是容器编排?
在开始实践之前,可能需要快速介绍一下容器编排的概念。
随着应用程序变得越来越复杂,并且必须处理越来越高的负载,我们必须接受这样一个事实,即:我们需要管理分布运行在多个物理或虚拟硬件上的数百个服务实例。
而容器编排允许我们将所有硬件视为单个逻辑实体。
来自 thenewstack.io 的有关容器编排的这篇文章将其总结为:抽象了主机基础结构,编排工具使得用户可以将整个集群视为单个部署目标。
我可以试着总结,容器编排工具,如:Kubernetes 或 Docker Swarm 允许我们部署软件组件作为服务,在基础设施上的一个或多个节点上运行。
对于 Docker,Swarm 模式用于管理被称为 swarm 的 Docker 集群。
Kubernetes 的关键概念命名和层次结构略有不同,但是总体上和 Docker Swarm 相同。
容器编排工具不仅为我们处理了服务的生命周期,还为诸如服务发现、负载平衡、内部寻址和日志记录之类的工作提供了工具。
Docker Swarm 核心概念
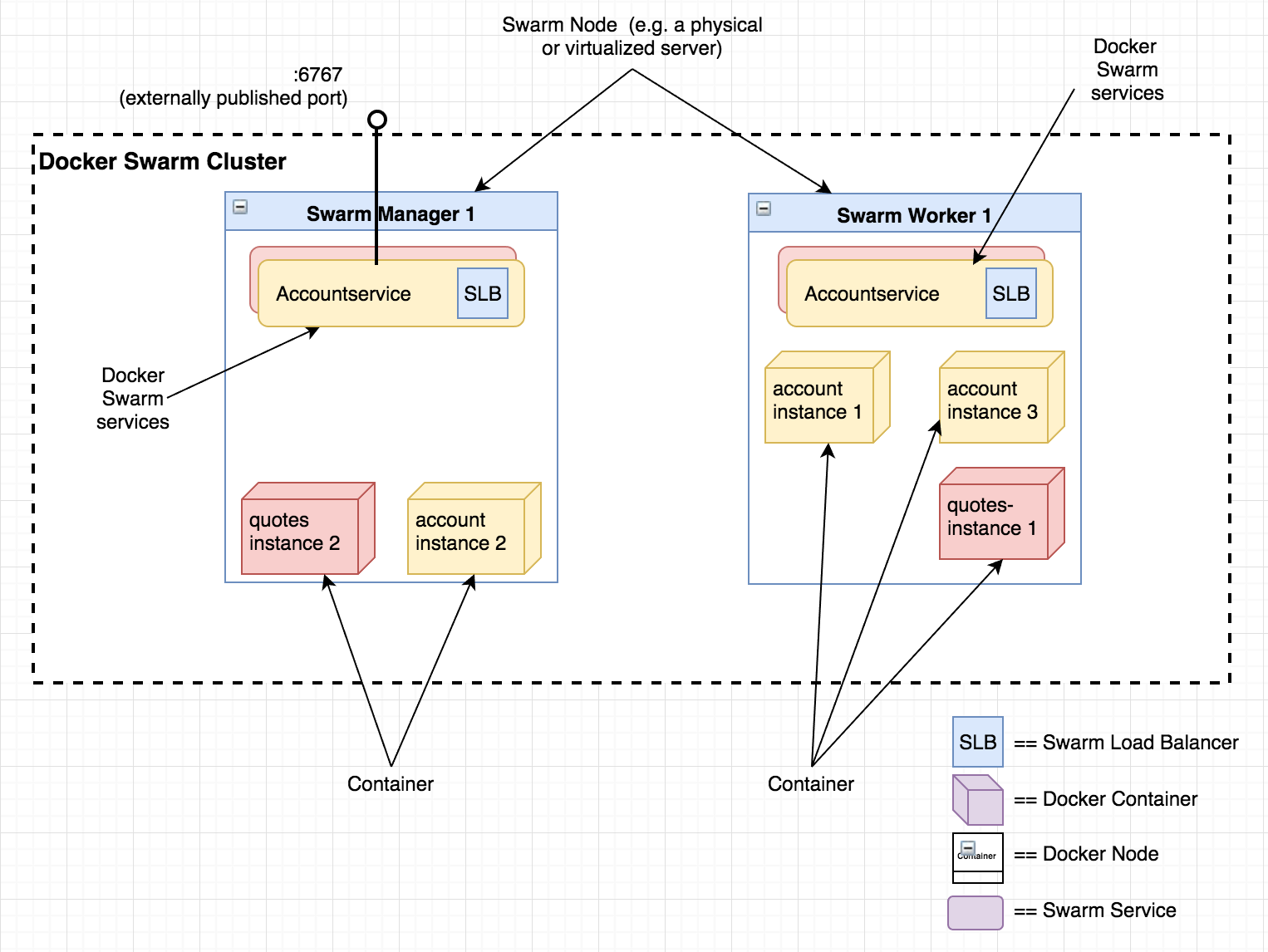
在 Docker Swarm 中,有三个概念需要介绍:节点、服务和任务。
一个节点是一个在 swarm 里面的 Docker 引擎的实例。
从技术上讲,可以将其视为具有自己的 CPU 资源、内存和网络接口的主机。
节点可以是管理者节点或工作者节点。
服务是对工作者节点上要执行的操作,由容器镜像和您指示容器执行的命令合集来定义。
服务可以被复制或包括,详情请参阅该文档。
服务可以被看作是一种抽象,它使任意数量的容器形成一个逻辑服务,可以通过其名称在整个集群中(或集群外部)来访问它,而不必了解有关内部环境网络拓扑的任何信息。
尽一切可能将任务视为 Docker 容器。
Docker 文档将任务定义为某种*承载 Docker 容器和在容器内运行的命令*。
管理者节点将启动给定容器镜像的任务分配给工作者节点。
下图展示了微服务格局的可能(简化)的部署图例,其中,两个节点总共运行抽象于两个服务(accountservice, quotes-service)的五个容器实例。
尽管本部分不会更改之前系列中的任何 Go 代码,但我们将添加一些新文件以在 Docker 上运行。
可以从 git 中检出对应的分支,以获取已完成的代码。
git checkout P5容器化我们的 accountservice
Docker 安装
为了使这部分工作,您需要在开发机器上安装 Docker。
建议您针对操作系统遵循本指南。
就我而言,在为该博客系列部署代码时,我就已经使用 Docker Toolbox 和 Virtualbox 了,但是您也可以使用 Docker for Mac/Windows 或在 Linux 上运行原生的 Docker。
创建一个 Dockerfile
一个 Dockerfile 是 Docker 构建镜像时您希望在其中包含什么的配方。
让我们从在 /accountservice 文件夹中创建一个名为 Dockerfile 的文件来开始:
FROM iron/base
EXPOSE 6767
ADD accountservice-linux-amd64 /
ENTRYPOINT ["./accountservice-linux-amd64"]标识说明:
- FROM:定义基础镜像,即我们将从其开始,再构建自己的镜像。iron/base 是一个非常紧凑的镜像,非常适合运行 Go 应用程序
- EXPOSE:定义我们要在内部 Docker 网络上暴露的端口号,使其可以访问
- ADD:将文件 accountservice-linux-amd64 添加到容器文件系统的根目录(/)
- ENTRYPOINT:定义当 Docker 启动此镜像的容器时要运行的可执行文件
为别的 CPU 架构/操作系统构建
如您所见,我们添加的文件名称中带有 *linux-amd64*。
尽管我们可以任意命名 Go 可执行文件,但我喜欢使用将操作系统和目标 CPU 平台放在可执行文件名称中的约定。
我是在运行 OS X 的 Mac 上编写此博客系列的。
因此,如果我在 /goblog/accountservice 文件夹中从命令行构建 accountservice 的 go 可执行文件:
> go build这将在同一文件夹中创建一个名为 accountservice 的可执行文件。
该可执行文件的问题在于,它无法在我们的 Docker 容器(基于 Linux 的底层操作系统)中运行。
因此,在构建之前,我们需要设置一些环境变量,以便 go 编译器和链接器知道我们正在为其它操作系统、CPU 体系结构构建,在该示例中为 Linux。
再次进入 /goblog/accountservice 目录:
> export GOOS=linux
> go build -o accountservice-linux-amd64
> export GOOS=darwin这将生成一个使用 -o 参数命名的可执行二进制文件。
我通常会编写自己的 shell 脚本,该脚本会将该过程自动化。
由于 OS X 和基于 Linux 的容器都在 AMD64 CPU 架构上运行,因此我们不需要设置(和重置)GOARCH 环境变量。
但是,如果要为 32 位 OS 或 ARM 处理器构建,则需要在构建之前适当设置 GOARCH。
创建一个 Docker 镜像
现在是时候构建我们的第一个包含可执行文件的 Docker 镜像了。
进入 /accountservice 目录的父目录,它应该是 *$GOPATH/src/github.com/callistaenterprise/goblog*。
在构建 Docker 容器镜像时,我们通常使用 [prefix]/[name] 命名约定的标签。
我通常使用 github 用户名作为前缀,例如:*eriklupander/myservicename*。
在本博客系列中,我将使用 someprefix。
在项目文件夹(/goblog)执行以下命令,来构建基于上述 Dockerfile 的 Docker 镜像:
> docker build -t someprefix/accountservice accountservice/
Sending build context to Docker daemon 13.17 MB
Step 1/4 : FROM iron/base
---> b65946736b2c
Step 2/4 : EXPOSE 6767
---> Using cache
---> f1147fd9abcf
Step 3/4 : ADD accountservice-linux-amd64 /
---> 0841289965c6
Removing intermediate container db3176c5e1e1
Step 4/4 : ENTRYPOINT ./accountservice-linux-amd64
---> Running in f99a911fd551
---> e5700191acf2
Removing intermediate container f99a911fd551
Successfully built e5700191acf2很好!我们本地的 Docker 镜像存储库现在包含一个名为 someprefix/accountservice 的镜像。
如果我们要在多个节点上运行,或者要分享我们的新镜像,则可以使用 docker push 使该镜像可用于除开当前活动的 Docker Engine,其它任何能够 pull 的主机。
现在,我们可以通过命令行直接运行此镜像:
> docker run --rm someprefix/accountservice
Starting accountservice
Seeded 100 fake accounts...
2017/02/05 11:52:01 Starting HTTP service at 6767但是,请注意,此容器不再在您的宿主机 OS 的 localhost 上运行。
现在它存在于自己的网络环境中,实际上我们不能直接从宿主机操作系统中调用它。
当然,有多种方法可以解决此问题,但是我们现在先不管它,而是在本地设置 Docker Swarm 并在那里部署我们的 accountservice。
使用 Ctrl+C 停止刚才启动的容器。
设置一个单节点 Docker Swarm 集群
本博客系列的目标之一是:在容器编排器中运行微服务。
对于大许多人来说,这通常意味着使用 Kubernetes、Docker Swarm 或其它编排器,例如:Apache Mesos 和 Apcera,但是本博客系列将仅专注于 Docker 1.13 的 Docker Swarm。
在开发机上设置 Docker Swarm 集群时涉及的步骤可能会有所不同,具体取决于您自己的操作系统。
还有基于我的同事 Magnus 的发现,使用 Docker Toolbox、Oracle Virtualbox 和 docker-machine。
创建一个 Swarm 管理器
一个 Docker Swarm 集群至少包含一个 Swarm Manager 和零到多个的 Swarm Worker。
为了简单起见,我的示例将仅使用单个 Swarm Manager,至少现在是这样。
重要的是,在本节之后,您需要有一个正常工作的 Swarm Manager。
此处的示例使用 docker-machine,并使在 Virtualbox 上运行的虚拟 linux 计算机作为我的 Swarm Manager。
在我的示例中,我把它称为 *swarm-manager-1*。您也可以浏览有关如何创建 Swarm 的官方文档。
以下命令初始化 docker-machine 宿主机的标识为 *swarm-manager-1*,并设置 swarm 的节点和 IP 地址。
> docker $(docker-machine config swarm-manager-1) swarm init --advertise-addr $(docker-machine ip swarm-manager-1)如果要创建一个多节点 swarm 集群,请保存好上面命令返回的 *join-token*,因为稍后在向集群中添加其它节点时将需要它。
创建覆盖网络
Docker 覆盖网络是我们在向 Swarm 添加诸如 accountservice 之类的服务时使用的一种机制。
这样它就可以访问在同一 Swarm 集群中运行的其它容器,而无需了解任何有关实际集群拓扑的信息。
让我们创建一个这样的网络:
docker network create --driver overlay my_networkmy_network 是我们为该网络指定的名称。
部署 accountservice
还差一点!现在,是时候将我们的 accountservice 部署为 Docker Swarm 服务了。
这个 docker service create 命令有很多参数,但用到的很少。
以下是我们部署 accountservice 的命令:
> docker service create --name=accountservice --replicas=1 --network=my_network -p=6767:6767 someprefix/accountservice
ntg3zsgb3f7ah4l90sfh43kud以下是参数的简要说明:
–name:为我们的服务分配一个逻辑名称。这也是其它服务在集群中寻找我们的服务时将使用的名称。因此,如果您有另一个要调用 accountservice 的服务,像这样执行 GET http://accountservice:6767/accounts/10000 就行了。
–replicas:我们想要的服务实例数量。如果我们有一个多节点 Docker Swarm 集群,那么 swarm 引擎将自动在各个节点之间分配实例。
–network:在这里,我们告诉 accountservice 将其自身附加到刚刚创建的覆盖网络。
-p:映射[内部端口]:[外部端口]。在这里,我们使用了 6767:6767,但是如果我们使用 6767:80 创建了它,那么在外部调用时,我们将从端口 80 访问该服务。请注意,这是使我们的服务可从集群外部访问的机制。通常,您不应该将服务直接向外界公开。取而代之的是,您将使用具有路由规则和安全设置的边缘服务器(例如:反向代理),因此外部使用者只能以您想要的方式访问您的服务。
someprefix/accountservice:在这里,我们指定想要容器运行的镜像。在我们的例子中,这是我们在创建容器时指定的标签。注意,如果要运行多节点集群,则必须将镜像推送到 Docker 存储库,例如:public 和 free Docker Hub 服务。如果您希望镜像保持私有,则还可以设置私有 Docker 存储库或使用付费服务。
现在,运行此命令以查看我们的服务是否成功启动。
> docker service ls
ID NAME REPLICAS IMAGE
ntg3zsgb3f7a accountservice 1/1 someprefix/accountservice很好!现在,我们可以使用 curl 或浏览器来使用我们的 API 了。
我们唯一需要知道的是 Swarm 的公开 IP。
即使我们在具有许多节点的集群上,运行我们服务的一个实例,覆盖网络和 Docker Swarm 也允许我们根据其端口向任何集群主机请求服务。这也意味着两个服务不能在暴露同一端口。
他们很可能在内部具有相同的端口,但对外部的 Swarm 来说,都算一个。
还记得我们之前保存的环境变量 ManagerIP 吗?
> echo $ManagerIP
192.168.99.100如果前面关闭了终端,则可以重新导出它:
> export ManagerIP=`docker-machine ip swarm-manager-0`让我们使用 curl 来访问一下:
> curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0"}正常运行!
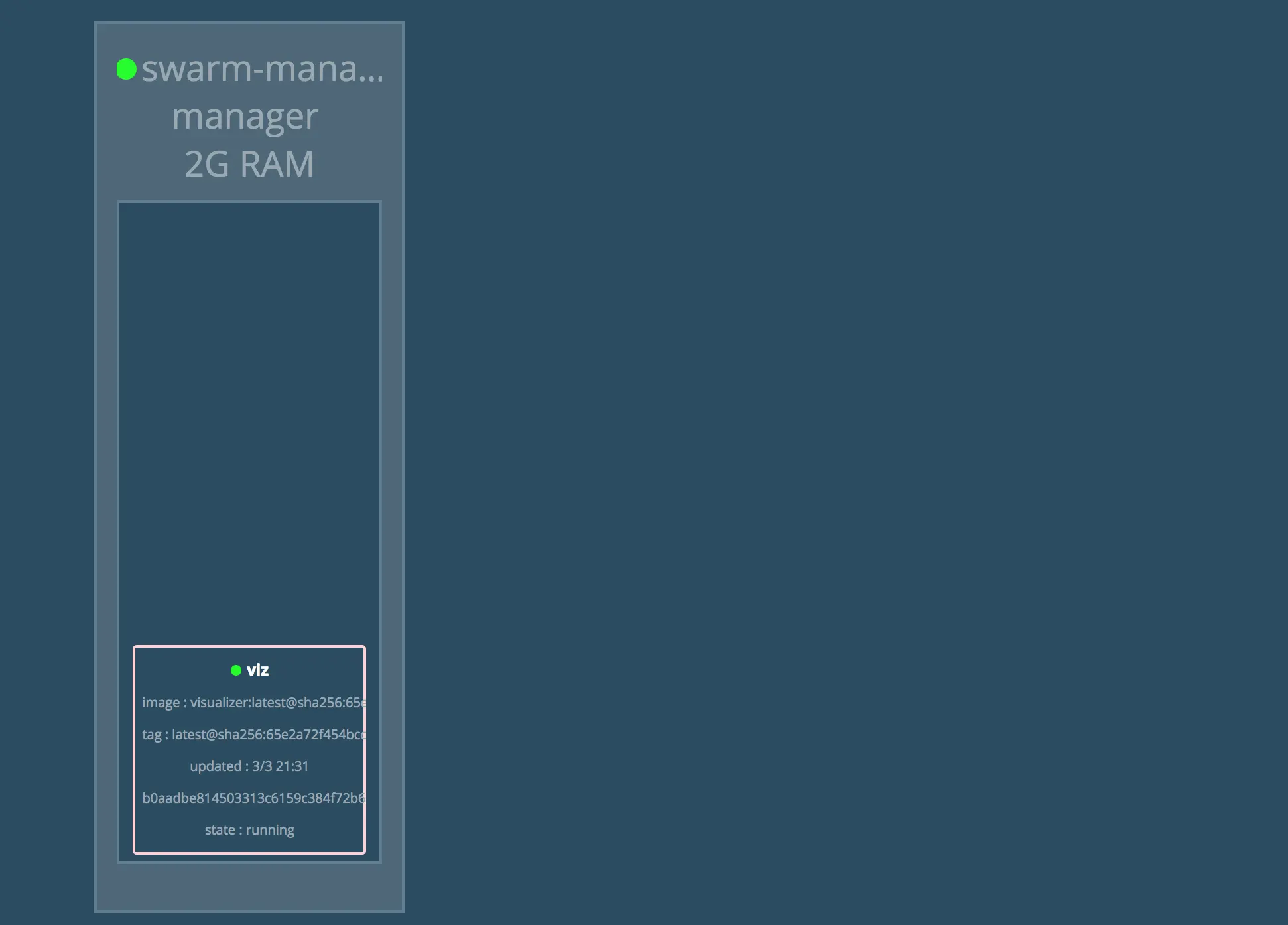
部署可视化工具
使用 Docker 命令行 API 检查 Swarm 的状态(例如:*docker service ls*)是完全可行的。
使用可视化工具可能看起来更有趣。这种可视化工具是 Docker Swarm Visualizer 的标记,我们可以将其部署为 Docker Swarm 服务。
这为我们提供了一种查看集群拓扑的替代机制。
它也可以仅用于确保我们可以访问集群中某个端口上公开的服务。
从预建的容器镜像安装可视化工具只需要运行一行:
docker service create \
--name=viz \
--publish=8080:8000/tcp \
--constraint=node.role==manager \
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
manomarks/visualizer这将创建一个我们可以在端口 8000 上访问的服务。
在您的浏览器中访问:http://$ManagerIP:8000:
奖励内容!
我使用 Go、Docker Remote API 和 D3.js 制作了一个名为 dvizz 的 Swarm 可视化工具。
如果喜欢的话,可以直接从预建的镜像安装它:
docker service create \
--constraint node.role==manager \
--replicas 1 --name dvizz -p 6969:6969 \
--mount type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock \
--network my_network \
eriklupander/dvizz在您的浏览器中访问:http://$ManagerIP:6969:
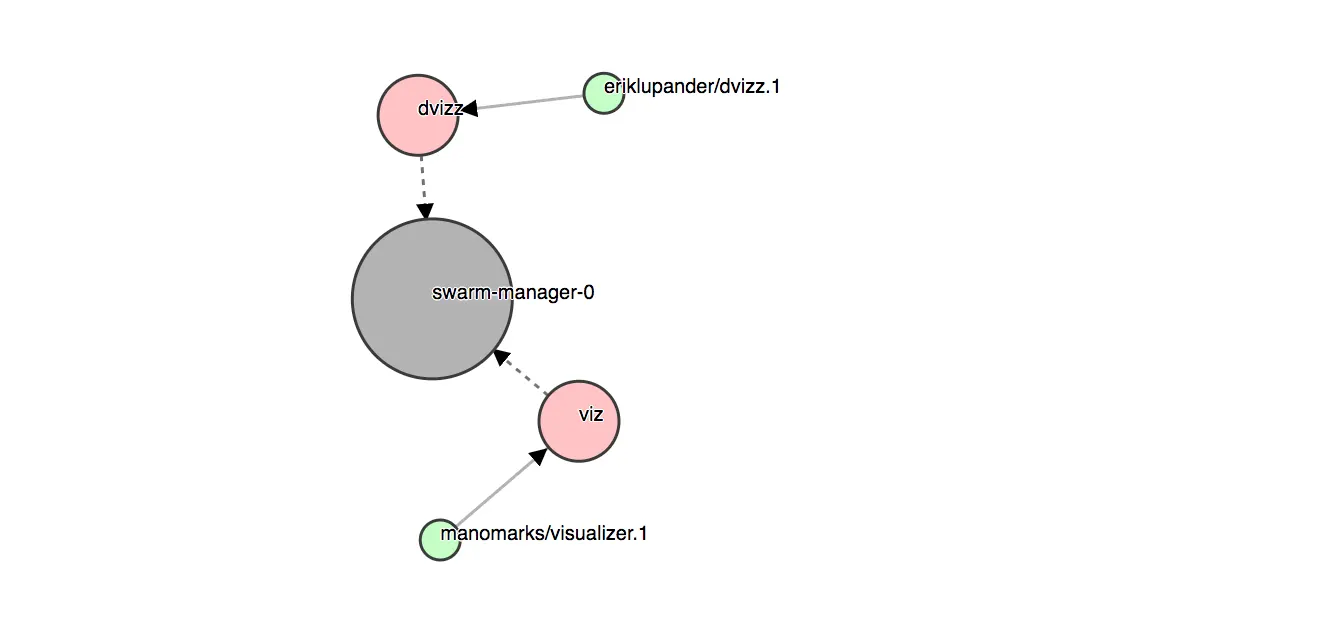
现在它还有一点 bug,所以不要用于正式环境,但在向上或向下扩展服务时,看着该图变化是一件很有趣的事情,我们将在博客系列的第 7 部分中做这件事。
如果您想让它变得更酷、更有用和更少 bug,请随意对 dvizz 发起 pull request!
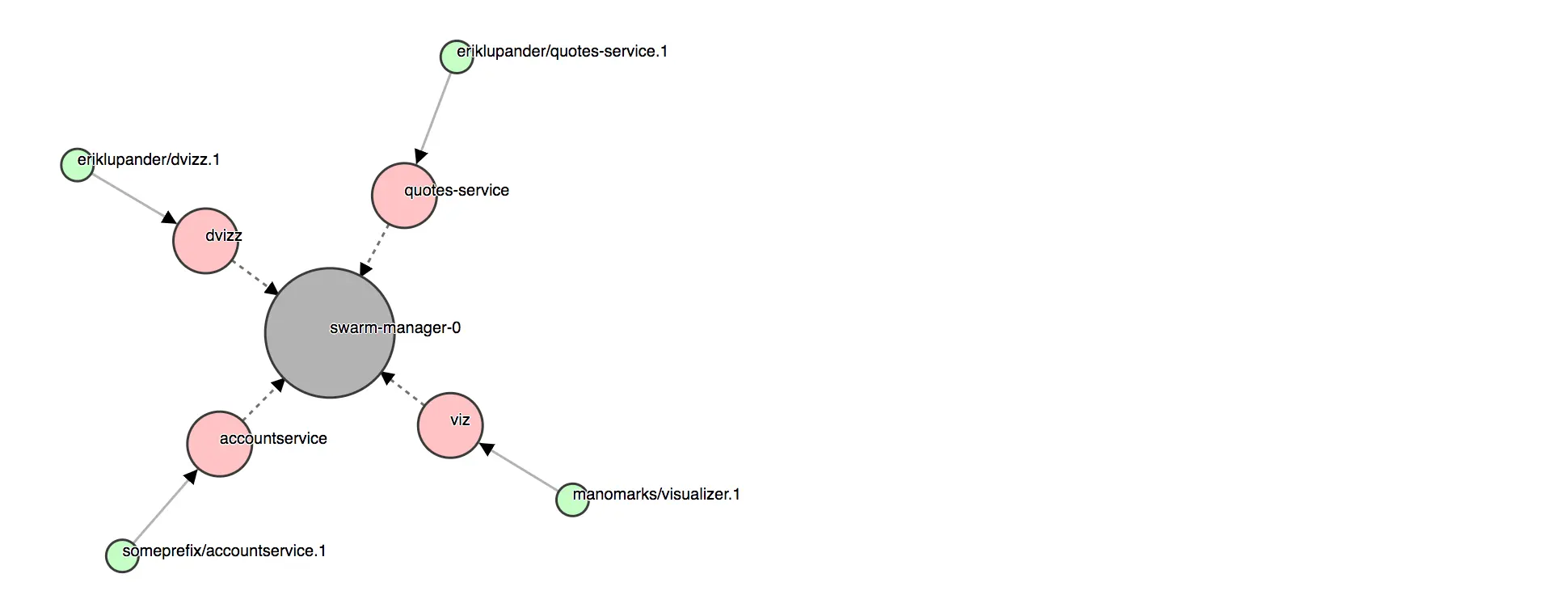
添加 quotes-service
只有一种服务的微服务不是很常见。
让我们补救一下:直接从容器镜像中部署先前提到的基于 Spring Boot 的 quotes-service,我将其推送到了被标记为 eriklupander/quotes-service 的 Docker Hub:
> docker service create --name=quotes-service --replicas=1 --network=my_network eriklupander/quotes-service如果您使用 docker ps 列出正在运行的 Docker 容器,我们应该看到它已启动(或正在启动):
> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
98867f3514a1 eriklupander/quotes-service "java -Djava.security" 12 seconds ago Up 10 seconds (health: starting) 8080/tcp 注意,我们不会为此服务暴露端口,这意味着它将无法从 Swarm 集群外部访问,而只能在内部的 8080 端口访问
。我们将在第 7 部分中研究服务发现和负载平衡时集成该服务。
如果您在 Swarm 中添加了 dvizz,则由于我们已经添加了 quotes-service 和 accountservice,它应该显示类似这样的内容。
copyall.sh 脚本
为了使我们的工作更轻松一些,我们可以添加一个 shell 脚本来做自动化重建和重新部署的工作。
在 /goblog 的根目录中,创建一个名为 copyall.sh 的 shell 脚本:
#!/bin/bash
export GOOS=linux
export CGO_ENABLED=0
cd accountservice;go get;go build -o accountservice-linux-amd64;echo built `pwd`;cd ..
export GOOS=darwin
docker build -t someprefix/accountservice accountservice/
docker service rm accountservice
docker service create --name=accountservice --replicas=1 --network=my_network -p=6767:6767 someprefix/accountservice该脚本设置了环境变量,因此,我们可以正确地为 Linux/AMD64 构建静态链接的二进制文件。
然后再运行一些 Docker 命令来构建镜像并将其部署为 Docker Swarm 服务。
Go 的构建脚本是这个博客系列中不会涉及的主题。
就个人而言,我喜欢 shell 脚本的简洁,但我偶尔也会使用 gradle 插件,而且我知道古老的 make 也很受欢迎。
运行时表现和性能
从现在开始,当服务在 Docker Swarm 中运行时,所有基准测试和 CPU/memory 指标都将在该服务上进行。
这意味着以前博客文章的结果与我们从现在开始所获得的结果不再具有可比性。
我们将使用与以前相同的 Gatling 测试,同时使用 docker stats 收集 CPU 使用率和内存使用情况。
如果您想自己运行负载测试,则第 2 部分中提到的要求仍然适用。
只需注意,您需要将 -baseUrl= 参数更改为 Swarm Manager 节点的 IP,例如:
> mvn gatling:execute -Dusers=1000 -Dduration=30 -DbaseUrl=http://$ManagerIP:6767启动后的内存使用情况
> docker stats $(docker ps | awk '{if(NR>1) print $NF}')
CONTAINER CPU % MEM USAGE / LIMIT
accountservice.1.k8vyt3dulvng9l6y4mj14ncw9 0.00% 5.621 MiB / 1.955 GiB
quotes-service.1.h07fde0ejxru4pqwwgms9qt00 0.06% 293.9 MiB / 1.955 GiB启动后,包含一个空的 Linux 发行版和我们正在运行的 accountservice 的容器使用了我分配给 Docker Swarm 节点的 2GB 内存中的约 5.6 mb。
基于 Java 的 quotes-service 约为 300 mb,尽管可以通过调整 JVM 来一定程度地减少。
负载测试期间的 CPU 和内存使用情况
CONTAINER CPU % MEM USAGE / LIMIT
accountservice.1.k8vyt3dulvng9l6y4mj14ncw9 25.50% 35.15 MiB / 1.955 GiBB在 Virtualbox 实例,而不是原生 OS X 上运行的 Swarm 中,以 1K req/s 运行时,我们看到的数字与早期的数字非常一致。
预期内存使用量会稍高一些,毕竟,容器本身也需要一些内存。
CPU 使用率也大致相似。

现在的平均等待时间为 4 ms。
性能直接从亚毫秒增加到毫秒的确切原因可能有几个,我猜测当在原生 OS 上运行 Gatling 测试时,请求通过桥接网络在虚拟实例上运行的 Swarm 时得到了优化。
不过,能够以 4ms 的平均延迟运行 1K req/s 仍然非常好,包括从 BoltDB 中读取、序列化为 JSON 和通过 HTTP 提供服务。
为了防止在以后的博客文章中添加链路追踪、日志记录、熔断或其他功能,而需要大量缩小 req/s,现在先记录下 200 req/s 时的情况。
如下所示:

下面总结博客系列的第 5 部分:我们学习了如何在本地启动 Docker Swarm 环境(具有一个节点)以及如何将 accountservice 微服务打包和部署为 Docker Swarm 服务。
在第 6 部分中,我们将为我们的微服务添加一个 Healthcheck。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK