

Benchmarking relational data in BonsaiDb
source link: https://bonsaidb.io/blog/commerce-benchmark/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Benchmarking relational data in BonsaiDb
Written by Ecton. Published 2022-01-18.
If you aren't familiar with BonsaiDb, check out our What is BonsaiDb? page.
While we're working towards our first alpha, I've been trying to anticipate questions potential users might have when looking at BonsaiDb for the first time. Although we are keeping the alpha label, we are hoping to find some adventurous users who are excited at our vision of a database designed for and written in Rust.
One obvious question that almost everyone will ask at some point when hearing about a new database: how does it perform?
BonsaiDb is a unique database. It is best described as a NoSQL database, but traditionally NoSQL databases tend to favor eventual consistency and speed over ACID compliance. When starting this project, I specifically wanted to have all the guarantees PostgreSQL makes, but easier to use and deploy.
Until this past week, I knew from previous benchmarks that Nebari (our underlying storage layer) was pretty fast, but I had no real indicator of how BonsaiDb would perform relative to PostgreSQL.
Designing a Benchmark Suite
I had three different parameters I wanted to measure:
- Dataset size
- The amount of concurrent workers
- Read-heavy vs Write-heavy workloads
I decided to create a benchmark suite inspired by the needs of an ecommerce website. The basic idea is to generate an initial data set, a list of plans for workers to execute, and test the dataset and plans using different quantities of workers. The operations being benchmarked are:
- Lookup product by id
- Find product by name (exact match)
- Create shopping cart
- Add product to cart
- Checkout
- Review a product
A single plan is generated by using probabilities to adjust how many plans succeed in each step of the shopping process. Some plans will search for products and never add them to a cart; Others will not only purchase the product, but also write a review. By adjusting the probabilities of each action occurring, we create a funnel that allows us to adjust the ratio of reads and writes.
I've written some more notes on the implementation of the benchmark itself, such as how aggregation of ratings is handled, in the benchmark's README.
BonsaiDb is faster than I had hoped!
These graphs show the accumulated execution time of each operation:
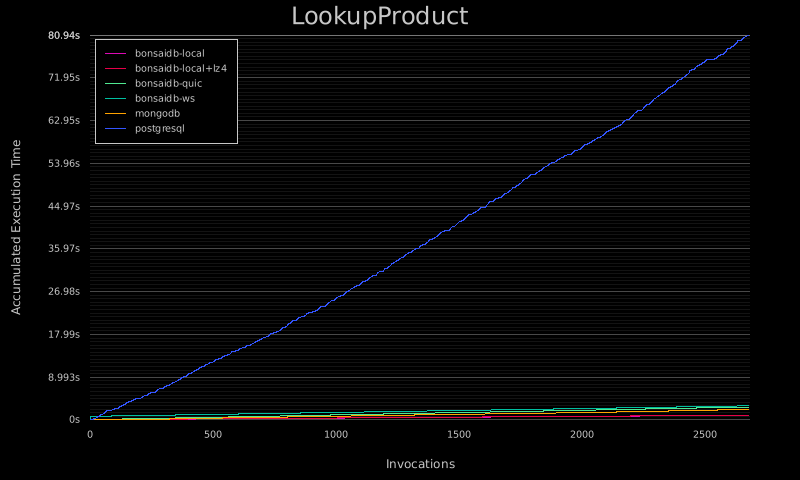
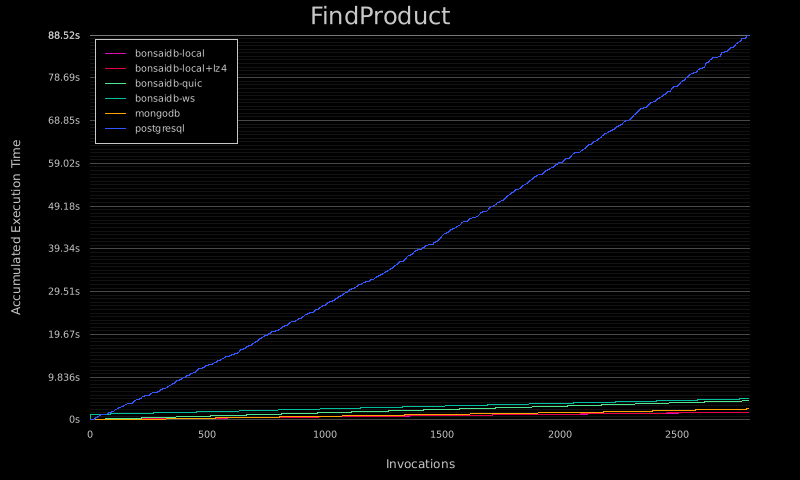
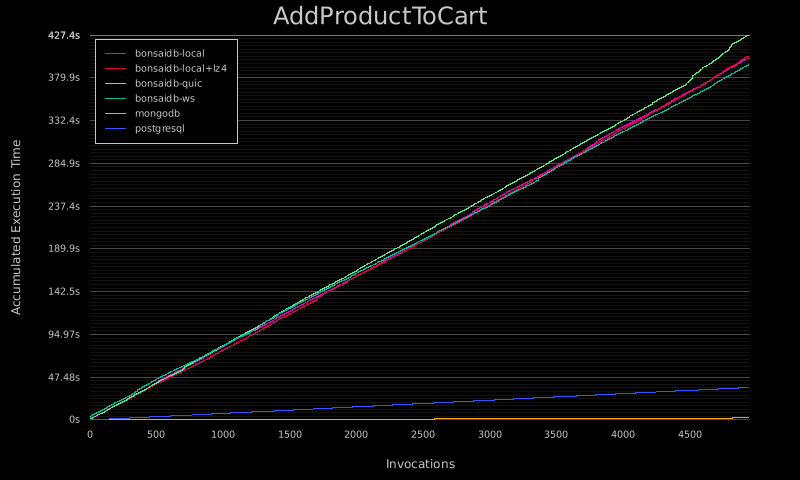
This set of graphs is from the "large, write-heavy, 2 workers per core" benchmark, run on a Scaleway GP1-XS instance running Ubuntu 20.04 with 4 CPU cores, 16GB of RAM, and local NVME storage. The entire suite's results can be viewed here as well.
As I started seeing these results, I was simply blown away. I've tried to be as fair as possible in writing this benchmark suite. Over time I plan on adding additional database backends for comparison, as well as additional operations as BonsaiDb gains more features.
One major difference between PostgreSQL and BonsaiDb is the lack of SQL. With BonsaiDb, the query language is Rust itself. This is why I often refer to BonsaiDb as a programmable database. The interface for accessing your data is how you design it. For example, here's the implementation of find product:
let product = Product::load(&operation.name, &self.database)
.await
.unwrap() // Result
.unwrap(); // Option<CollectionDocument<Product>>
let rating = self
.database
.view::<ProductReviewsByProduct>()
.with_key(product.id as u32)
.with_access_policy(AccessPolicy::NoUpdate)
.reduce()
.await
.unwrap(); // Returns a f32
Trying out BonsaiDb
BonsaiDb is currently labeled experimental. We are working to stabilize custodian-password, which has involved updating many existing crates to improve the OPAQUE-KE ecosystem in Rust. After that is done, we are going to label BonsaiDb as alpha. It hasn't been used by many people yet, so we expect that there will be bugs and some of those bugs might even cause loss of data. That being said, we've been using it ourselves with KhonsuLabs.com since early November 2021 with no issues, in addition to a couple other small test projects.
We encourage most users to wait another week or two until we have the alpha on Crates.io, but for those looking to play with something new, we'd love any feedback from early users. We've already made countless improvements to the API, documentation, user's guide and examples as a result of questions from early adopters.
If you're interested in BonsaiDb but want to wait until we've released a stable version, we invite you to subscribe to this site's feed or watch the repository's releases section.
We are looking forward to seeing what types of applications BonsaiDb will power someday!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK