

如何通过任务调度实现百万规则报警
source link: https://my.oschina.net/u/3996014/blog/5322874
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者 | 黄晓萌
01 问题背景
报警是一个公司的日常需求,常见的形态除了满足运维过程中的基础设施监控报警(CPU/内存/磁盘等)之外,部分公司也会在应用指标(如 QPS、RT 等)及业务指标(如 GMV/日活 等)上有相应的报警需求。
在业务发展初期,基础设施较少,且应用形态单一,所以处理这一类需求往往会比较粗暴直接,但是随着业务的增长,尤其发展到日活百万甚至上亿级的时候,监控指标也会呈指数级上涨,在这种情况下对于报警体系就提出了巨大的挑战,如何解决这种体量下报警的有效性和时效性就成为了 IT 治理的重中之重。本篇文章,我们将从监控指标的体量出发,详解各个阶段报警体系中遇到的各个挑战。
02 一次常规的报警流程示意图
如下图所示,一次常规意义上的报警流程,主要会包含并发检查、齐全度检查、数据追补、阈值判断等核心环节。同时,为了保证报警的时效性,基本上整个流程会是一个秒级触发的形态,具体如下: 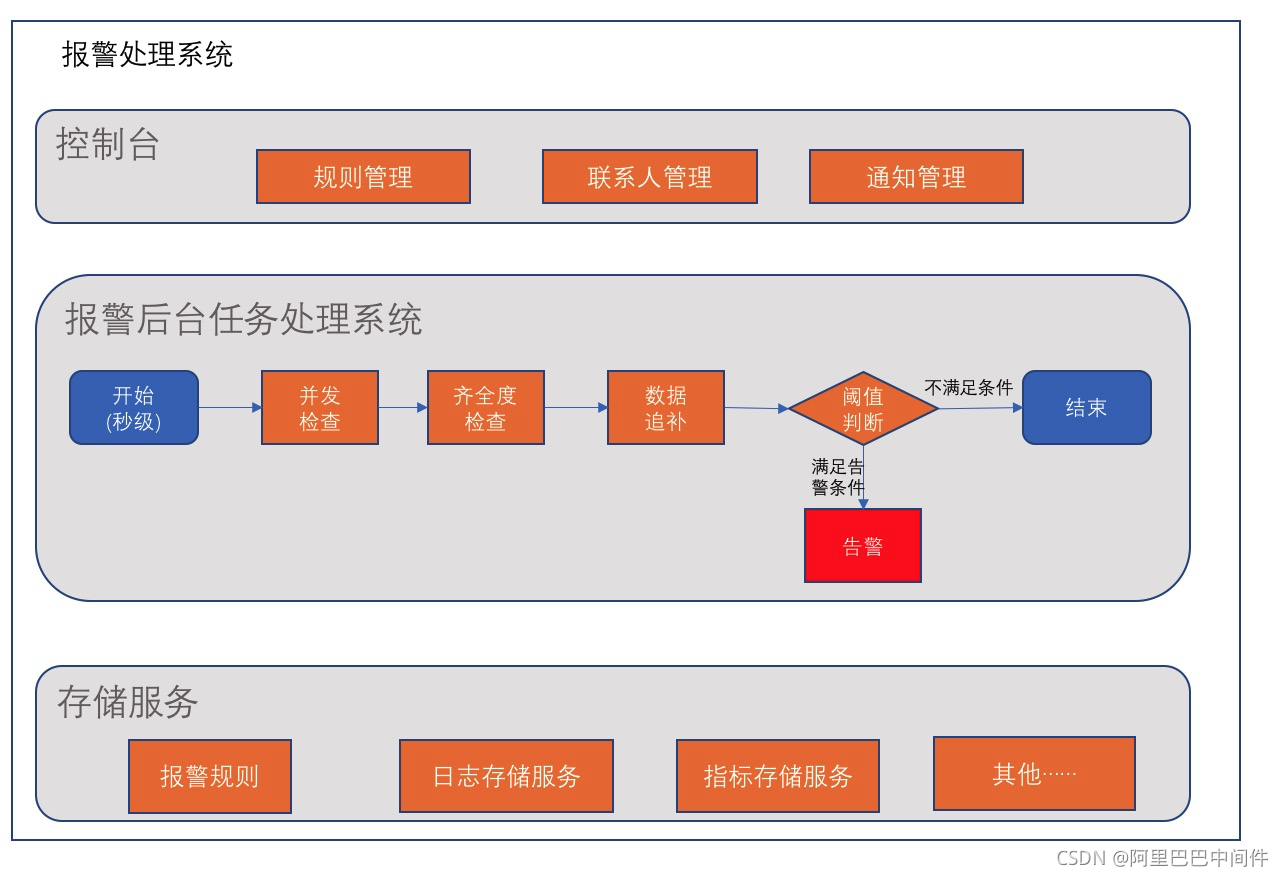
其中,报警后台任务处理系统是我们这次讨论的重点,几个核心流程的说明如下:
- 并发检查:检查当前告警规则是不是在其他进程或者节点中执行中,避免有些告警规则检查耗时过长,被重复执行了或被其他的任务节点抢占执行。
- 齐全度检查:获取当前告警规则对应的数据源的齐全度时间,即最新数据上报到什么时间了。因为数据源数据采集和上报一定会有延时的,如果数据不齐就进行检查,很容易漏报和误报。
- 数据查询:从监控数据中获取该规则的数据,一般会从收集上来的日志服务(如:ElasticSearch 服务等)或者基础监控指标存储服务(如:Zabbix、Prometheus 等)中获取。
- 数据追补:由某些报警任务设置的策略,没有数据点的情况下怎么处理。有补0,补满和不补三种。如在针对业务数据跌零报警的场景,我们会更倾向于补 0 ;但是针对 CPU 平均值超 80% 的场景,我们会倾向于不补。
- 阈值判断:根据获取的数据和报警条件,判断是否需要触发报警。
- 告警:将告警信息通过短信、钉钉、邮件等方式通知到配置的人,以便后续有人处理。
03 进程内调度方案
一开始的业务很少的时候,报警任务也趋于少数,这个时候一般的实现都会基于一个进程内的线程池执行相关的操作,架构图如下: 
把上图的“后台任务处理系统”放到一台机器上运行,能很快速的满足小规模的场景。但是等到业务量持续上涨的时候,一台机器就出现了资源瓶颈,这个时候一个下意识的反应就是扩容上面的任务处理系统,让不同的 Server 处理不同的报警规则。但是随着报警规则在不断增加,负载的持续上涨会引起 Server 也会重启或者突然挂掉。于是高可用、任务幂等执行、failover 等分布式问题又是面临的一个复杂的难题。
04 分布式调度解决方案
如果任务数达到万级别,寻求一个轻量的分布式的方案是我们的目标。分布式调度方案的基本思路都是通过单独的任务调度中心来调度任务,报警后台只管执行任务,即任务调度和任务执行隔离的思路,使得两层都能做很好的横向扩容来达到容量上涨的目的。业务实现上,每个报警规则会生成一个定时任务,这样可以保证每个报警规则负载均衡地执行。开源市场有挺多产品,比如:Quartz、xxl-job、elastic-job 等。以 quartz 为例,示意图如下: 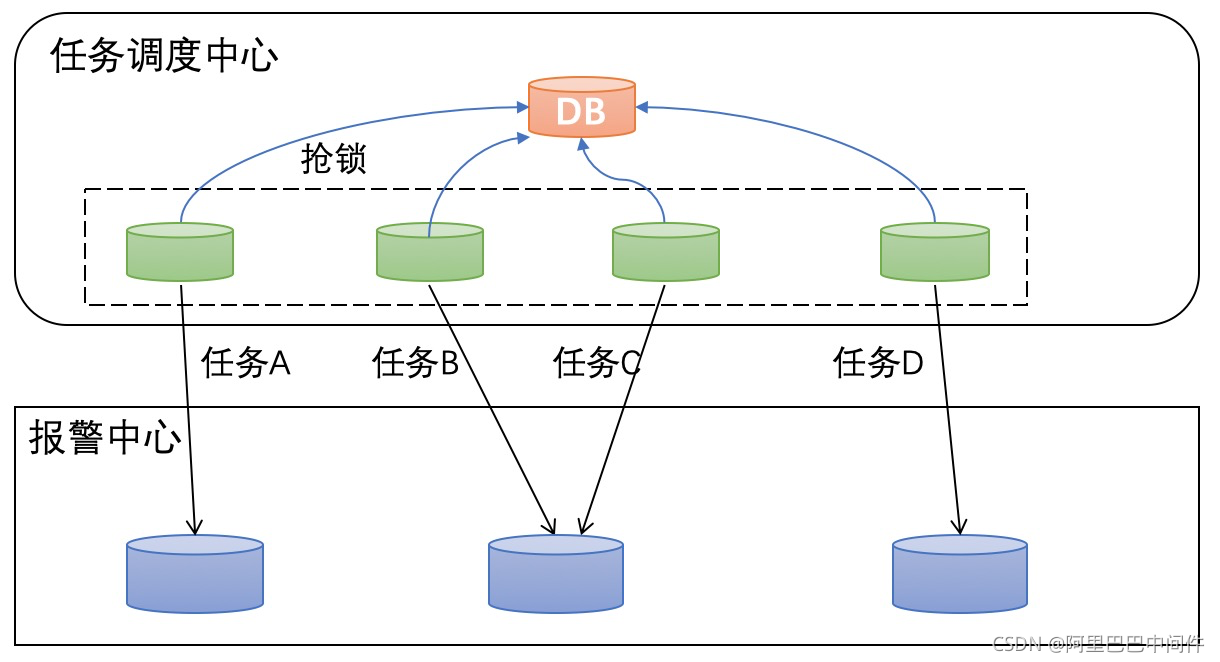
如上图所示,quartz 的每个 Server,会加载全量的所有任务,每次任务时间到了,所有 Server 会通过数据库抢锁,抢到锁的 Server 触发该任务给报警中心。
这个架构解决了任务的分布式调度、幂等执行的问题,并且执行层可以水平扩展,在任务量低的情况下可以稳定运行。
可是从上面的架构图可以看出,Quartz 的调度主要通过轮询 DB 和通过 DB 加锁的方式而实现,这个时候整个系统的吞吐基本上和 DB 的规格和性能息息相关。经测试,如果在任务量调度频率 1 分钟级别的触发达到1万,就会出现比较明显的调度延时。
05 基于 SchedulerX 2.0 的超大规模任务调度方案
1、SchedulerX 2.0 优势 SchedulerX 2.0 是阿里巴巴自研的一款商业化分布式任务调度平台,相对于开源任务调度系统,它有几大优势: • 支持海量任务 • 自研轻量级分布式跑批模型 • 可视化任务编排 • 商业化报警 • 可视化日志服务 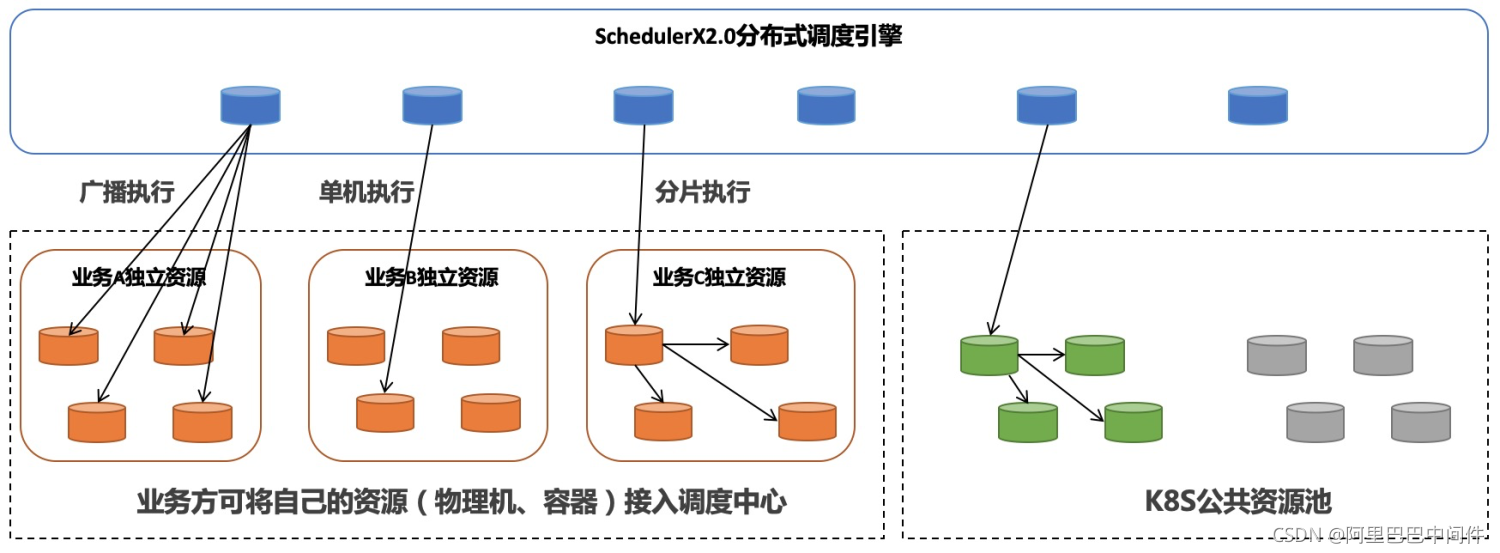
与常见方案相比,SchedulerX2.0 会将任务分布式到不同的 Server 调度,每次任务调度也不需要抢锁触发,和数据库无任何交互,没有性能瓶颈。
2、高可用能力 在分布系统中最常见的就是高可用问题,如果 SchedulerX 2.0 的某个 Server 挂了会怎么办? 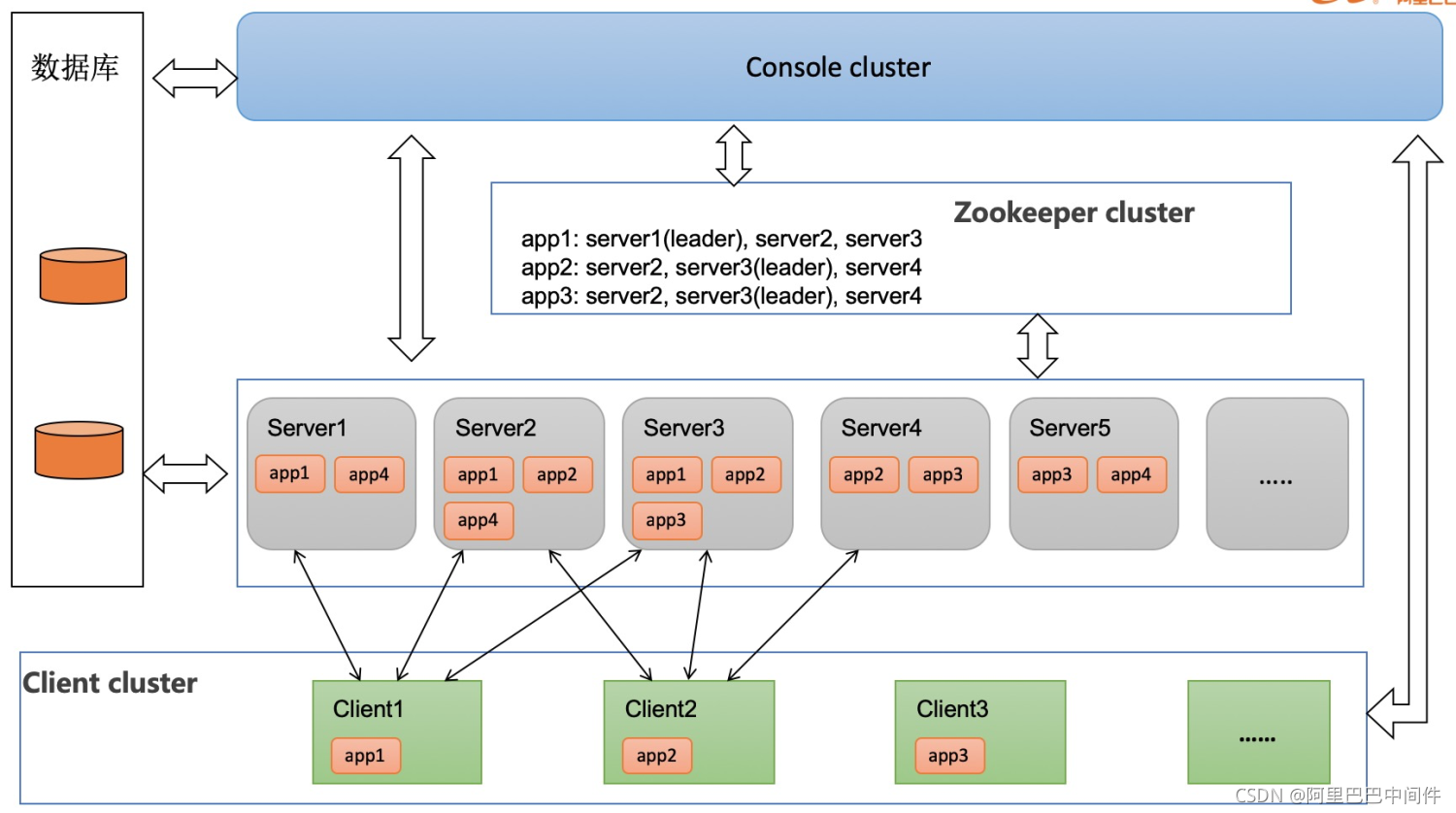
如上图所示,每个应用都会做三备份,通过 zk 抢锁,一主两备,如果某台 Server 挂了,会进行 failover,由其他 Server 接管调度任务。 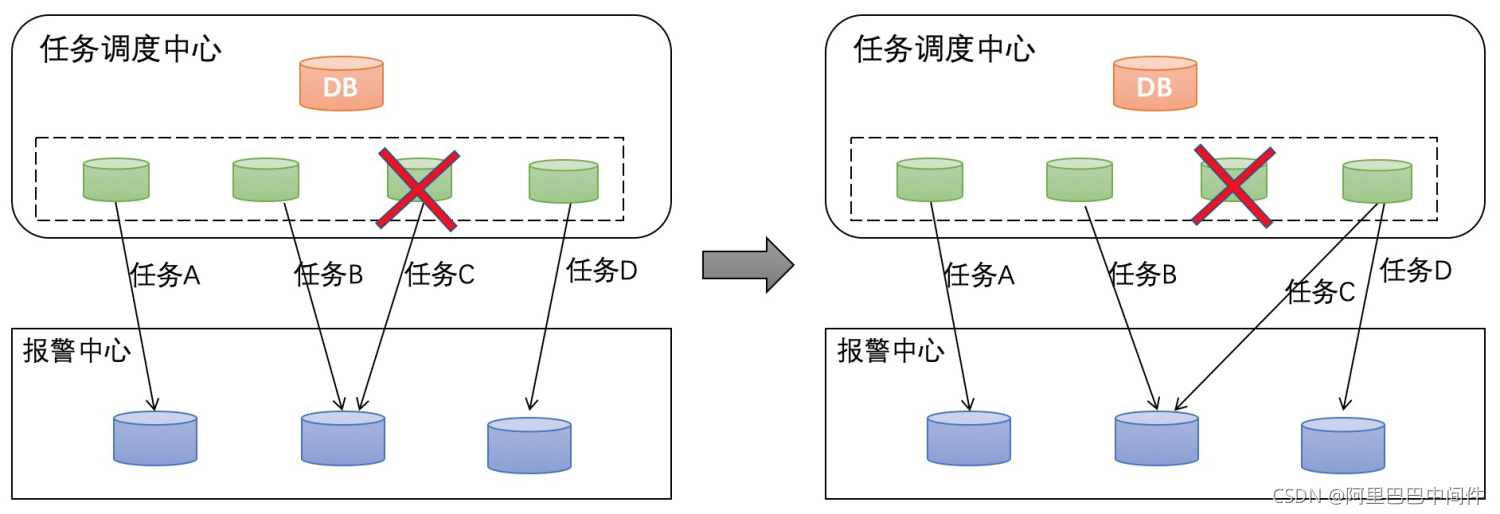
3、商业化报警 SchedulerX 2.0 当前支持钉钉、短信、邮件三种报警通道: 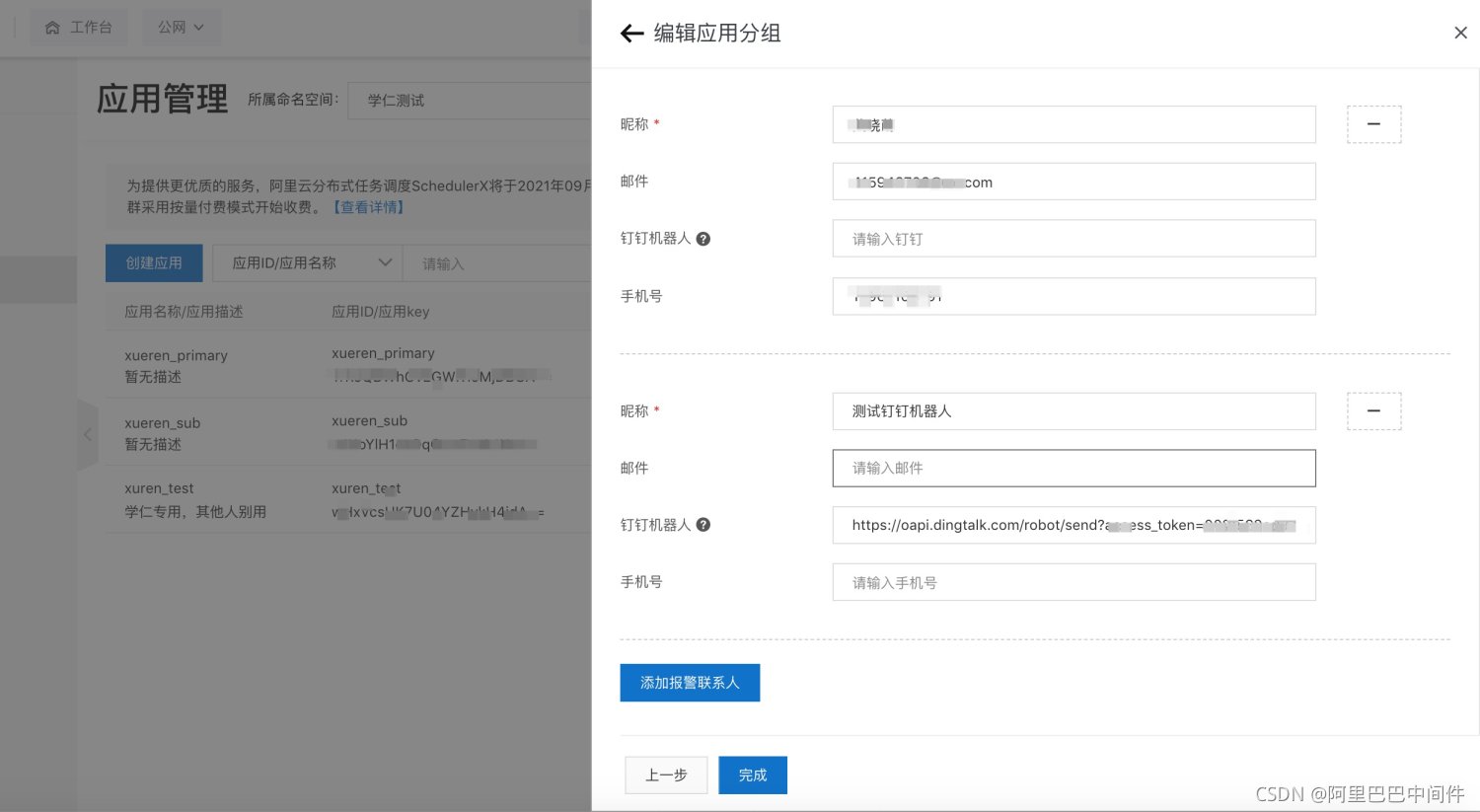
支持任务失败、超时、无可用机器报警: 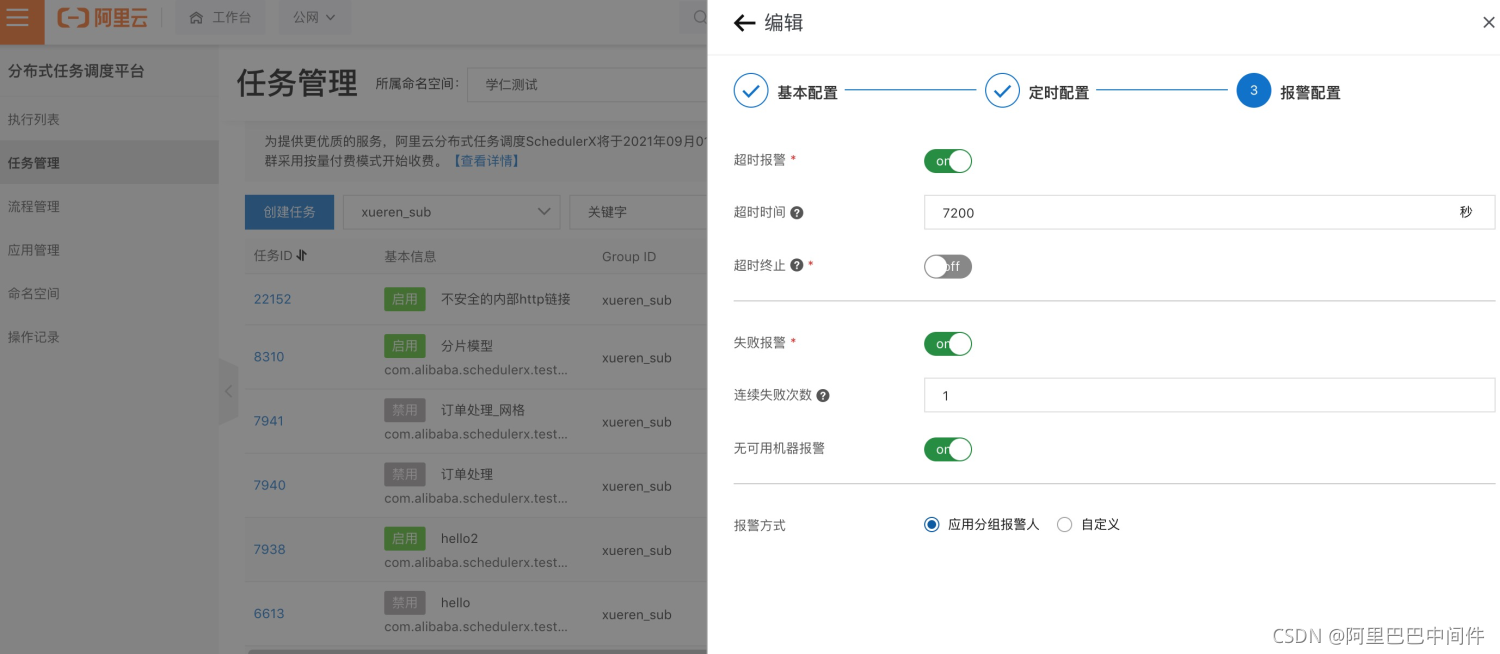
以钉钉告警为例,您可以实时收到报警: 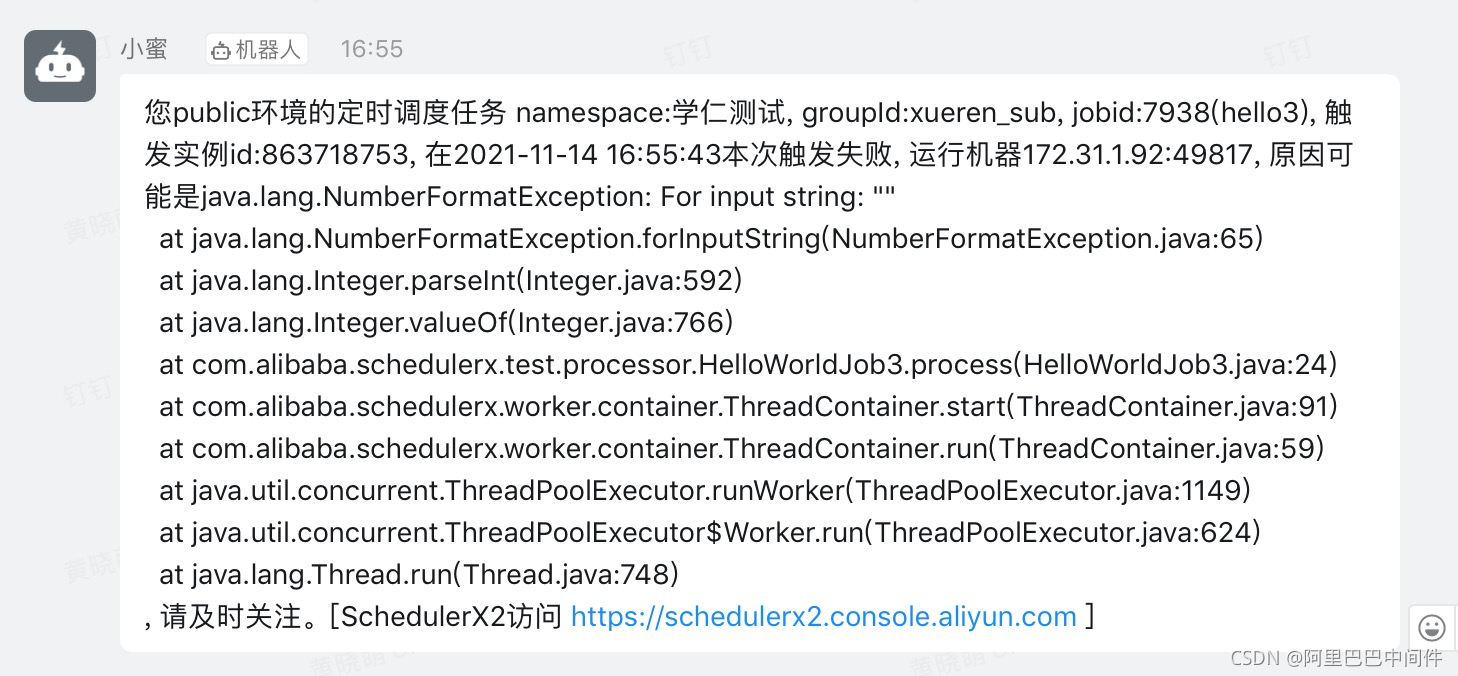
SchedulerX 2.0 在阿里巴巴集团内支撑了所有事业群的业务,经历了多次双十一的考验,当前在公有云已接入1000+家企业,在海量任务和高可用方面有充足的经验。显然,在超大规模任务调度领域,SchedulerX 2.0 已经是目前最优解决方案之一。
点击下方链接,了解更多分布式调度平台 SchedulerX 2.0 的特色及使用! https://www.aliyun.com/aliware/schedulerx
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK