

How to Handle Stacked Pull Requests on GitHub
source link: https://pspdfkit.com/blog/2021/how-to-handle-stacked-pull-requests-on-github/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
If you develop software, there’s a good chance you use a platform like GitHub to collaborate and work together on code with your team. The basic unit of reviewable code in GitHub is the pull request, but the implementation of a feature may require several pull requests. This blog post will give you the necessary git and GitHub concepts to understand how to work with dependent (stacked) pull requests.
What Are Stacked Pull Requests?
GitHub is designed in a way that all reviewable code must be part of a git branch. The typical workflow when you want some changes to be reviewed is that you:
-
First, create a local git branch.
-
Next, push the branch to the remote repository you share with your colleagues.
-
Then, create a pull request — a process in which you need to select your new branch and a base branch (where you want your changes merged), which is typically (but not always, as you’ll see) the main development branch.
But what happens when you need to create several pull requests to complete the implementation of a given feature? In this case, you’d create, say, three pull requests: A, B, and C. Pull request A will merge into the main development branch; pull request B will build on top of A and merge into A; pull request C will build on top of B and merge into B.
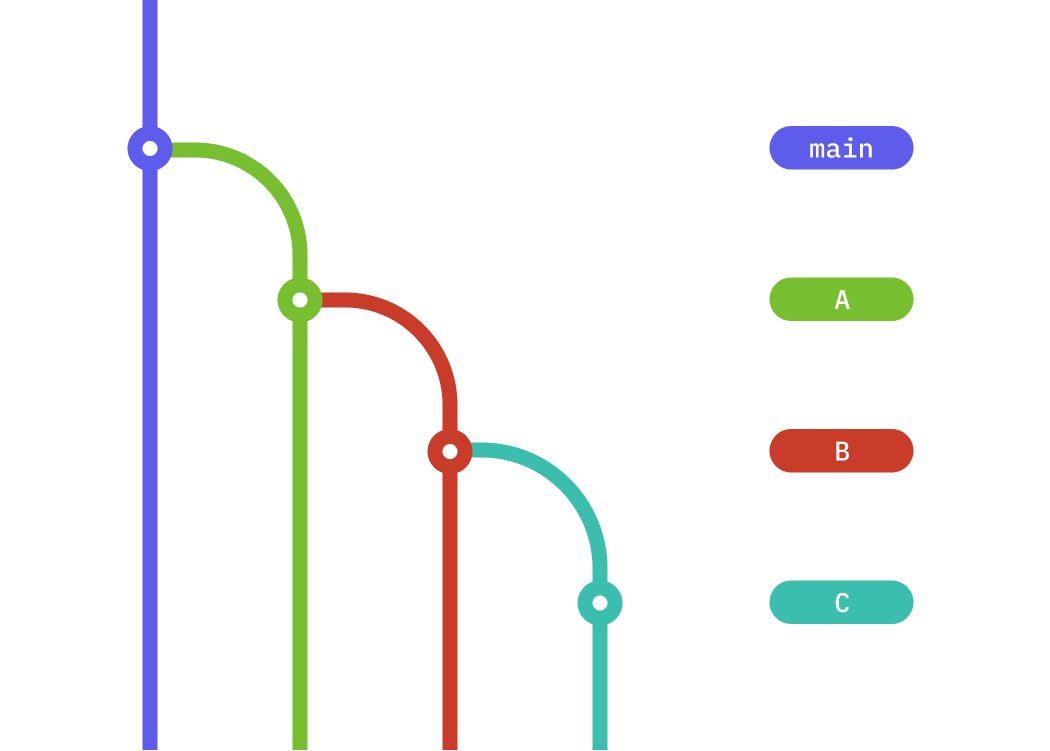
This situation is what’s usually called a stack of pull requests. The diagram above represents the scenario visually.
How Does GitHub Compute the Contents of a Pull Request?
As mentioned earlier, when you create a pull request, you need to specify two parameters: the branch with the work you want to integrate, and the branch you want the work to be integrated into (the base branch). With that information, GitHub is able to check if the work is actually mergeable (that is, if there are no conflicting changes in both lines of work), and if so, produce a diff of the changes that can be reviewed by a person.
In a pull request, GitHub calculates the diff between the branch and the base branch using the triple-dot notation of the git diff command. This notation lets you view the changes in a branch, starting at the common ancestor of both branches. For example, if you open a pull request for a branch named my-awesome-feature against main, GitHub will internally perform the following diff:
git diff main...my-awesome-feature
The output of this command will show the contents of my-awesome-feature, starting at the common ancestor between main and my-awesome-feature.
What Is the Common Ancestor of Two Branches?
You may ask what the common ancestor of two git branches is. In general, there may be more than one, but in many cases, you’ll only be interested in the closest one. This is also known as the merge base; this is a concept from graph theory that applies to git as well.
For example, consider the following topology of the main and my-awesome-branch branches.
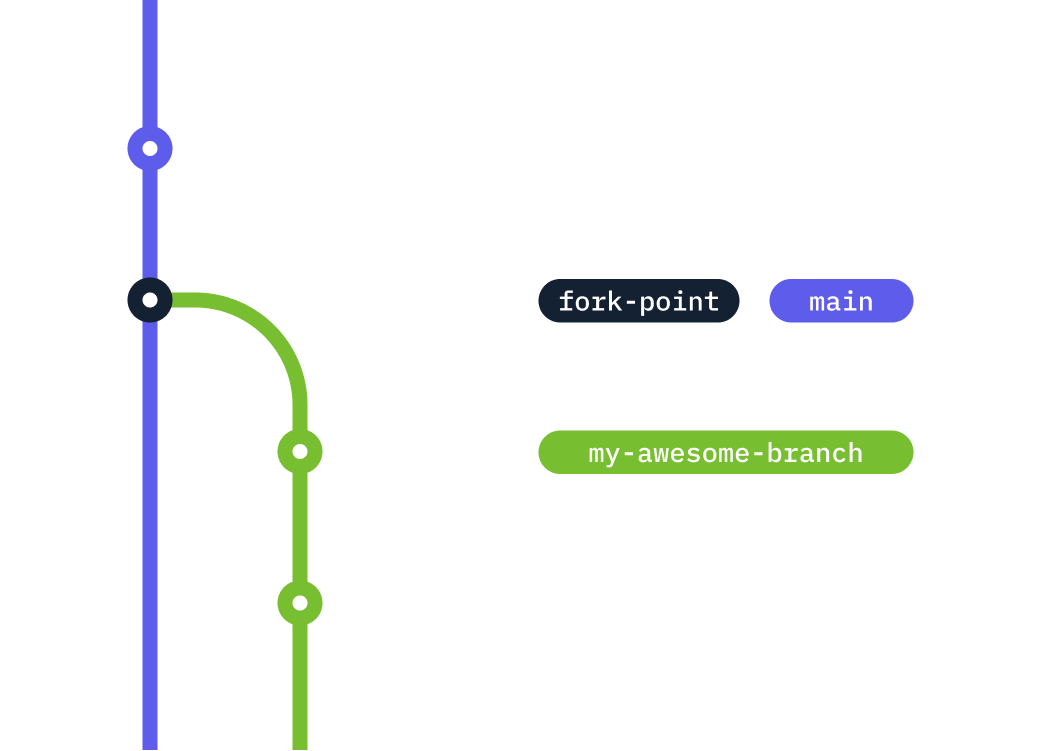
The merge base between main and my-awesome-branch is the commit fork-point. This is the commit my-awesome-branch was branched from.
A Common Stacked Pull Request Workflow on GitHub
Now that you know how GitHub prepares a pull request’s page to review code, it’s time to see how a workflow with several stacked pull requests may work.
Suppose you have the following set of stacked branches, which is the same example you saw in the What Are Stacked Pull Requests? section.
The corresponding pull requests would be A, whose base branch is main; B, whose base branch is A; and C, whose base branch is B. In this initial configuration, everything works fine, each pull request is mergeable, and reviewers will only see the changes introduced by the corresponding pull request. Everyone is happy.
Complexity starts as soon as the branches evolve — for example, because new commits are added (such as in response to review comments), or because some of the pull requests are merged (or squash merged into a single commit). The next sections will analyze the different situations in more detail.
When Some Commits Are Added to Pull Request A
Below, you’ll see a graphical description of the scenario after you commit three changes to A.
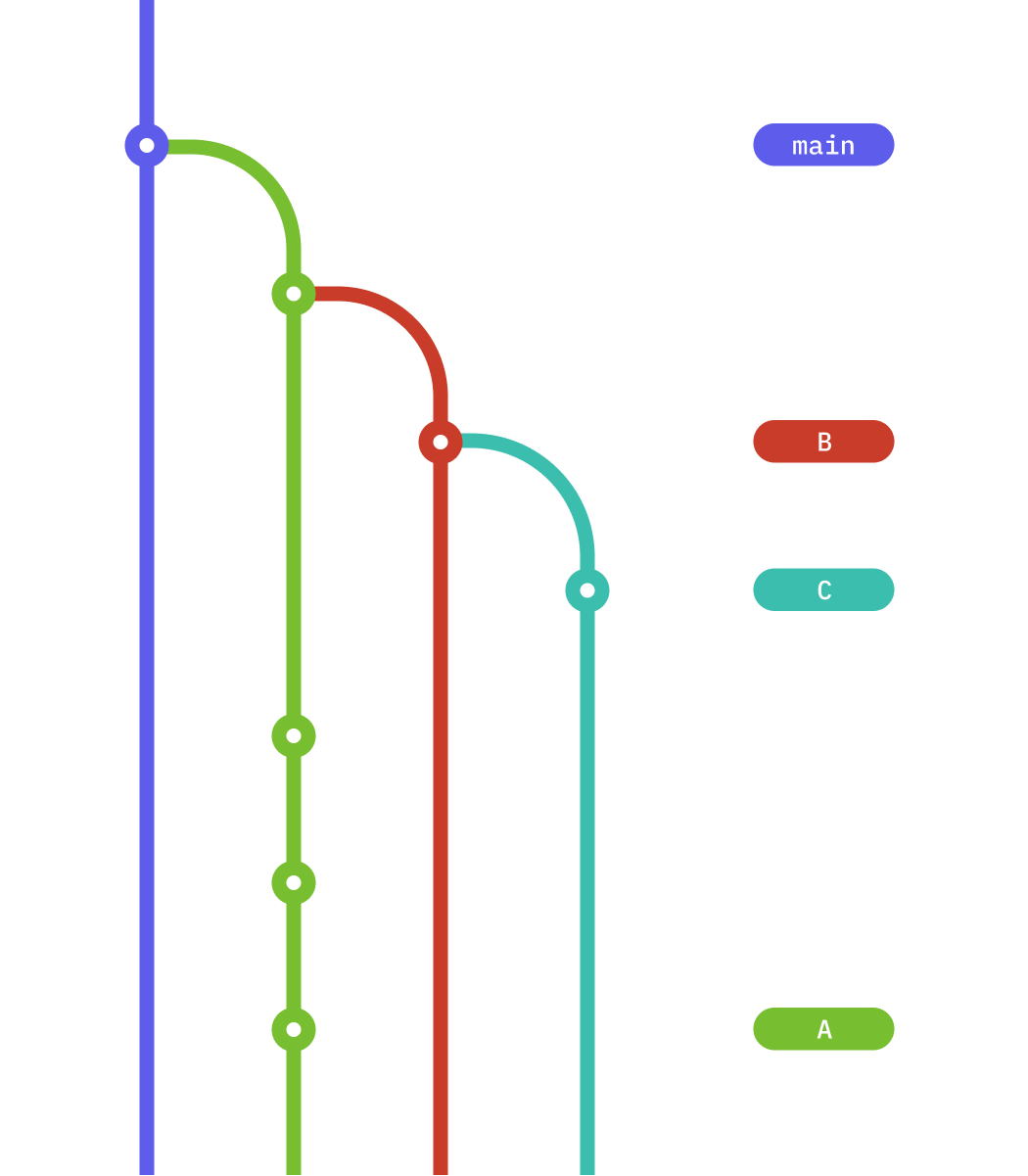
If you add commits to pull request A, those changes may conflict with the changes in pull request B. If that happens, you won’t be able to merge pull request B cleanly into A (or into main, when A is merged into main).
There are many possible solutions to this problem. For example, a popular one would be to perform a git operation known as git rebase so that the B branch appears to have branched from the top of branch A. (You’ll need to fix conflicts manually so that the branch is mergeable again.)
Typically, git rebase is run as follows:
git rebase <upstream>
In this sample scenario, if you’re in branch B, you could write the following:
git rebase A
In that case, git rebase will do the following:
-
Calculate the commits in
Bthat aren’t inAand save them in memory, temporarily. -
Check out the
Abranch. -
Reapply the saved commits on top of
A(after you resolve the merge conflicts).
You can understand the git rebase command as a “cut and paste” command, where the commits in the B branch are “cut” and then “pasted” on top of the A branch. This analogy isn’t totally correct, though: The pasted commits aren’t the same as the ones you cut; they’re different ones but with identical changes. And if you resolved conflicts along the way, the contents won’t be the same. I know, it’s confusing!
When Pull Request A Is Merged and Closed
If you finish addressing feedback on pull request A and you merge and close it, the following things would happen to the dependent pull requests, B and C:
-
As soon as you merge and delete the
Abranch, the base branch of theBpull request — which wasAoriginally — will switch tomain. -
GitHub will update the diff view of pull request
Bby issuing the command explained in the How Does GitHub Compute the Contents of a Pull Request? section:
git diff main...B
Remember that this command shows the contents of B, starting at the common ancestor between main and B. In other words, this is equivalent to git diff $(git merge-base main B) B. The problem is that the common ancestor of both branches is the commit where the A branch started diverging from main.
Two things may happen: In the best case, you’ll see a huge diff that contains the changes from A (already merged), and in the worst case, the pull request won’t be mergeable.
The solution to this apparent mess is to keep the calm and think about what the GitHub web interface expects. The base branch of the B pull request is now main, so you’d like to make B as if it branched from main. git-rebase to the rescue again!
From branch B, issue this command:
git rebase main
In this case, the commits from B that aren’t already on main will be reapplied. This seems easy, but in practice, the way git rebase checks if a commit is already in the destination branch may introduce duplicated commits. The following section explains the problem in more detail.
Rebasing Branches in a Stacked Pull Request May Cause Duplicated Commits
How does git rebase know if a commit is already on main? It compares the contents of the commit, so even if both commits have different hashes but the same contents, git rebase will skip it. However, if you fixed conflicts, the contents of both commits won’t be exactly the same, so git rebase will create duplicated commits that will cause further conflicts if you need to rebase the branches again.
One solution to avoid this messy situation is to pass an option to the git rebase command to actually “transplant” one branch onto another, giving more flexibility about which commits you want to rebase: git rebase --onto is the option to do that.
Using git rebase –onto as a More Flexible Way to Rebase
The syntax of git rebase with the --onto option is the following:
git rebase --onto <newbase> <upstream>
In the example of the main and B branches, if the current branch is B, the command would be:
git rebase --onto main A
This will only “transplant” the commits between A and B (that is, the output of the git log A..B command).
Once you’ve rebased the subset A..B onto main, you can git push --force-with-lease your changes. The pull request’s webpage should only contain the changes in B that aren’t in main, and the pull request should be mergeable again.
You’ll need to follow the same process for the other dependent branches, such as C in the example above.
Conclusion
Good code review practices encourage sending small chunks of code to review. For efficiency, developers working on a non-trivial feature build a pipeline of dependent changes, where some parts of the code are being reviewed and addressed while other parts are being developed further. If you use GitHub as your code review platform, this means implementing a workflow commonly known as stacked pull requests.
As of now, working with stacked pull requests on GitHub isn’t as easy as it could be, and it requires some knowledge about how git works. We hope this article helped shed some light on the git concepts you need to master to feel confident dealing with stacked pull requests and to develop your own automation to make the process simpler.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK