

RocketMQ开发者的个人空间
source link: https://my.oschina.net/apacherocketmq/blog/5271347
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

背景介绍
为何选择 RocketMQ
我们在几年前决定引入 MQ 时,市场上已经有不少成熟的解决方案,比如 RabbitMQ , ActiveMQ,NSQ,Kafka 等。考虑到稳定性、维护成本、公司技术栈等因素,我们选择了 RocketMQ :
纯 Java 开发,无依赖,使用简单,出现问题能 hold ;
经过阿里双十一考验,性能、稳定性可以保障;
功能实用,发送端:同步、异步、单边、延时发送;消费端:消息重置,重试队列,死信队列;
社区活跃,出问题能及时沟通解决。
使用情况
主要用于削峰、解耦、异步处理;
已在火车票、机票、酒店等核心业务广泛使用,扛住巨大的微信入口流量;
在支付、订单、出票、数据同步等核心流程广泛使用;
每天 1000+ 亿条消息周转。
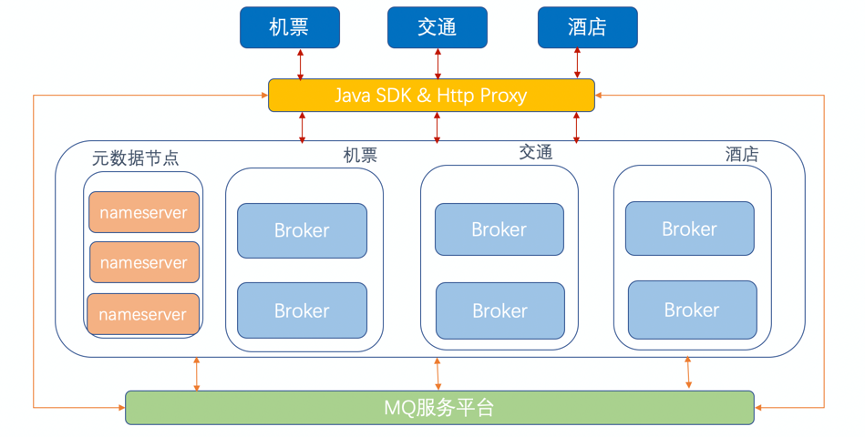
MQ 双中心改造
之前单机房出现过网络故障,对业务影响较大。为保障业务高可用,同城双中心改造提上了日程。
为何做双中心
单机房故障业务可用;
保证数据可靠:若所有数据都在一个机房,一旦机房故障,数据有丢失风险;
横向扩容:单机房容量有限,多机房可分担流量。
双中心方案
做双中心之前,对同城双中心方案作了些调研,主要有冷(热)备份、双活两种。(当时社区 Dledger 版本还没出现,Dledger 版本完全可做为双中心的一种可选方案。)
1)同城冷(热)备份 两个独立的 MQ 集群, 用户流量写到一个主集群,数据实时同步到备用集群, 社区有成熟的 RocketMQ Replicator 方案, 需要定期同步元数据,比如主题,消费组,消费进度等。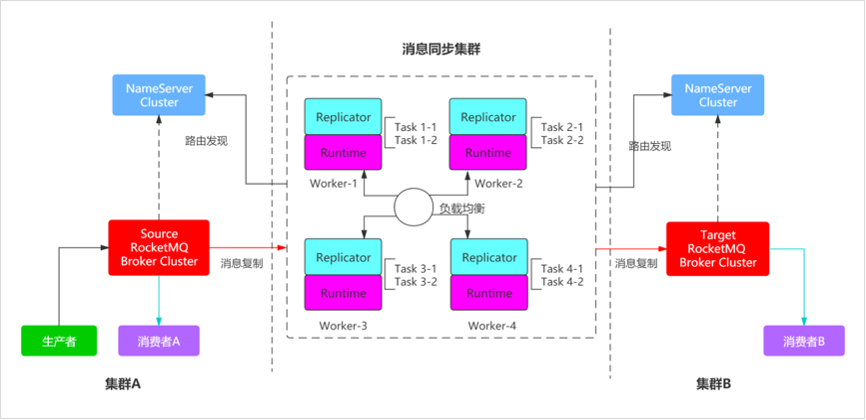

双中心诉求
- 就近原则:生产者在 A 机房,生产的消息存于 A 机房 broker ; 消费者在 A 机房,消费的消息来自 A 机房 broker 。
- 单机房故障:生产正常,消息不丢。
- broker 主节点故障:自动选主。
就近原则
简单说,就是确定两件事:
- 节点(客户端节点,服务端节点)如何判断自己在哪个 idc;
- 客户端节点如何判断服务端节点在哪个 idc。

ip 查询:通过公司内部组件查询 ip 所在机房信息;
broker 名称增加机房信息:在配置文件中,将机房信息添加到 broker 名称上;
协议层增加机房标识:服务端节点向元数据系统注册时,将自身的机房信息一起注册。
相对于前两者,实现起来略复杂,改动了协议层, 我们采用了第二种与第三种结合的方式。
就近生产
基于上述分析,就近生产思路很清晰,默认优先本机房就近生产; 若本机房的服务节点不可用,可以尝试扩机房生产,业务可以根据实际需要具体配置。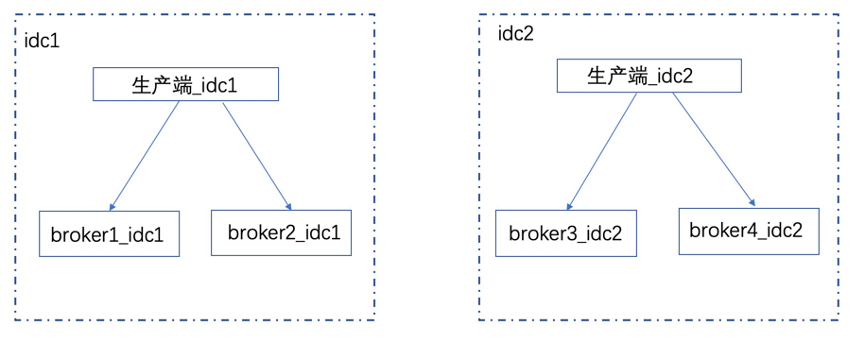
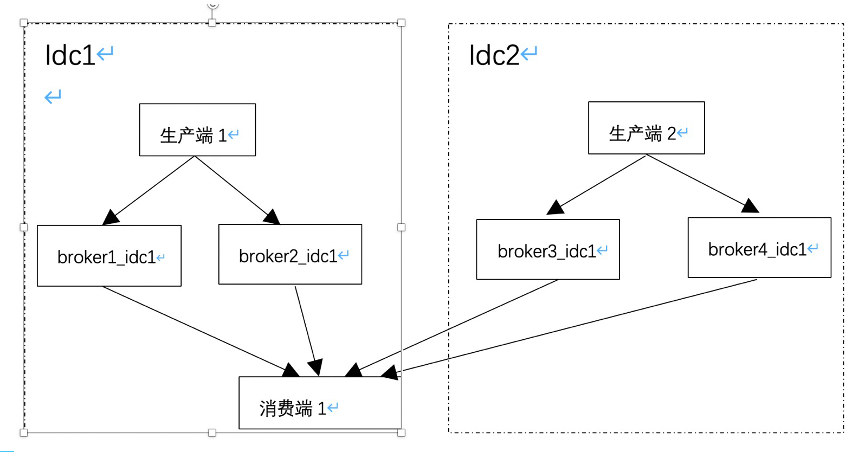
就近消费
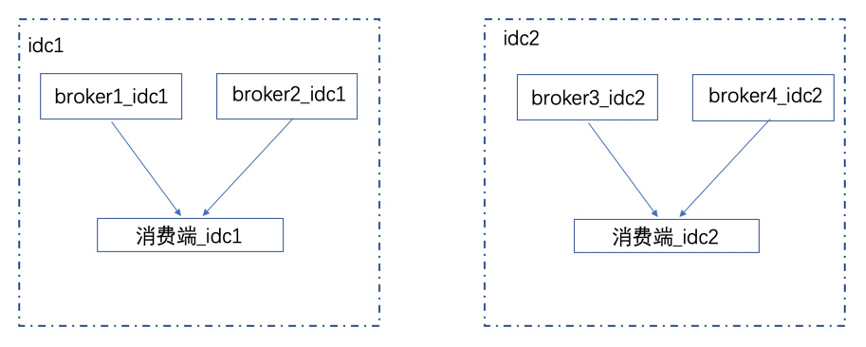
优先本机房消费,默认情况下又要保证所有消息能被消费。 队列分配算法采用按机房分配队列
每个机房消息平均分给此机房消费端;
此机房没消费端,平分给其他机房消费端。
消费场景主要是消费端单边部署与双边部署。 单边部署时,消费端默认会拉取每个机房的所有消息。Map<String, Set> mqs = classifyMQByIdc(mqAll);Map<String, Set> cids = classifyCidByIdc(cidAll);Set<> result = new HashSet<>;for(element in mqs){result.add(allocateMQAveragely(element, cids, cid)); //cid为当前客户端}
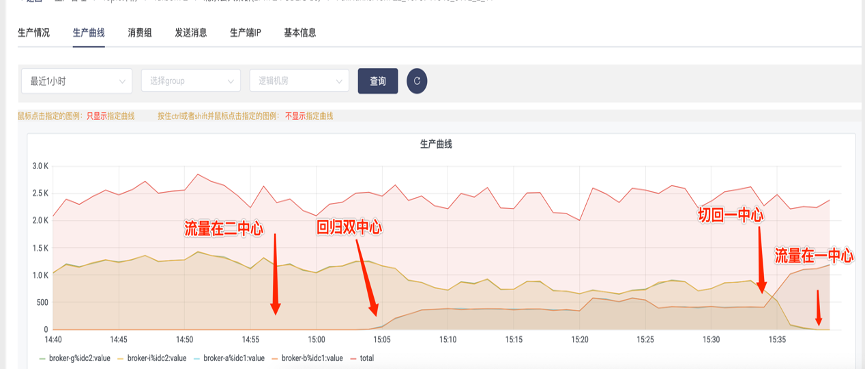
单机房故障
每组 broker 配置
单机房故障
消息生产跨机房;未消费消息在另一机房继续被消费。
故障切主
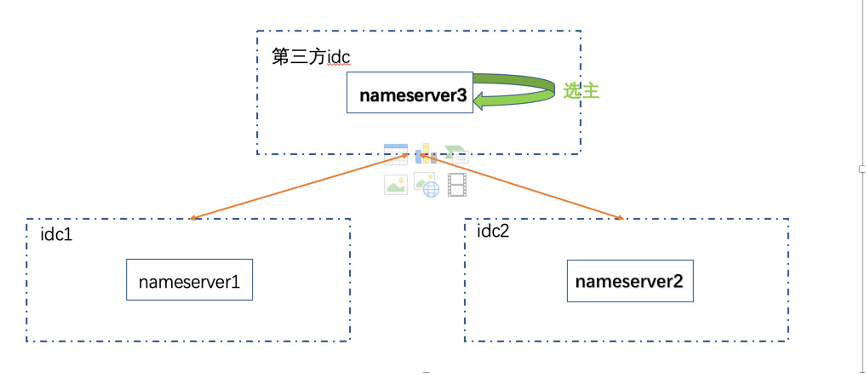
在某一组 broker 主节点出现故障时,为保障整个集群的可用性,需要在 slave 中选主并切换。要做到这一点,首先得有个broker 主故障的仲裁系统,即 nameserver(以下简称 ns )元数据系统(类似于 redis 中的哨兵)。 ns 元数据系统中的节点位于三个机房(有一个第三方的云机房,在云上部署 ns 节点,元数据量不大,延时可以接受),三个机房的 ns 节点通过 raft 协议选一个leader,broker 节点会将元数据同步给 leader, leader 在将元数据同步给 follower 。 客户端节点获取元数据时, 从 leader,follower 中均可读取数据。
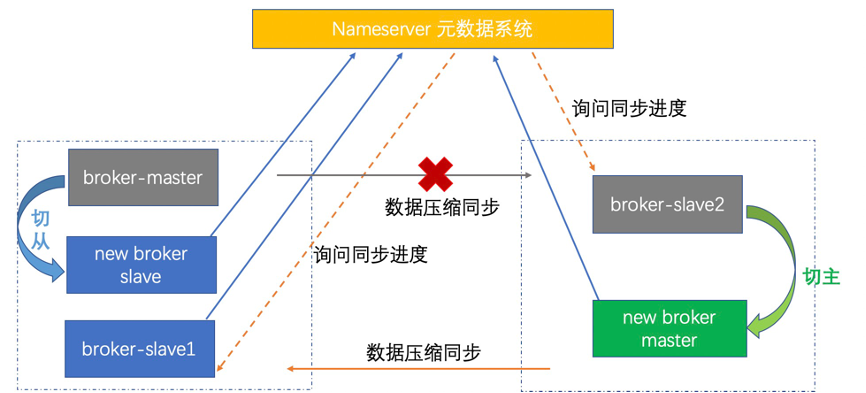
若 nameserver leader 监控到 broker 主节点异常, 并要求其他 follower 确认;半数 follower 认为 broker 节点异常,则 leader 通知在 broker 从节点中选主,同步进度大的从节点选为主;
新选举的 broker 主节点执行切换动作并注册到元数据系统;
生产端无法向旧 broker 主节点发送消息。
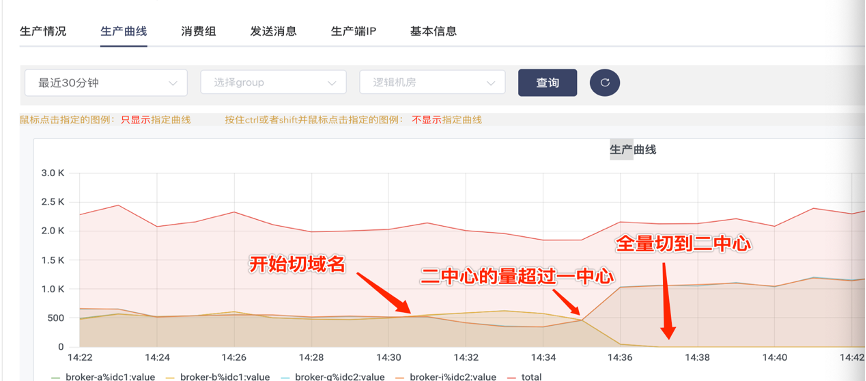
全局 Global 集群
一主二从,写过半消息即及写入成功
元数据系统 raft 选主
broker 主节点故障,自动选主
MQ 平台治理
即使系统高性能、高可用,倘若随便使用或使用不规范,也会带来各种各样的问题,增加了不必要的维护成本,因此必要的治理手段不可或缺。
目的
让系统更稳定
快速定位、止损
治理哪些方面
主题/消费组治理 生产环境 MQ 集群,我们关闭了自动创建主题与消费组,使用前需要先申请并记录主题与消费组的项目标识与使用人。一旦出现问题,我们能够立即找到主题与消费组的负责人,了解相关情况。若存在测试,灰度,生产等多套环境,可以一次申请多个集群同时生效的方式,避免逐个集群申请的麻烦。 为避免业务疏忽发送大量无用的消息,有必要在服务端对主题生产速度进行流控,避免这个主题挤占其他主题的处理资源。 对消息堆积敏感的消费组,使用方可设置消息堆积数量的阈值以及报警方式,超过这个阈值,立即通知使用方;亦可设置消息堆积时间的阈值,超过一段时间没被消费,立即通知使用方。
消费节点掉线
发送、消费耗时检测
消息链路追踪
过低或有隐患版本检测
集群健康巡检
集群性能巡检
集群高可用
部分后台操作展示
主题与消费组申请

新老消费端并存时,我们实现的队列分配算法不兼容,做到兼容即可;
主题、消费组数量多,注册耗时过长,内存 oom ,通过压缩缩短注册时间,社区已修复;
topic 长度判断不一致,导致重启丢消息,社区已修复;
centos 6.6 版本中,broker 进程假死,升级 os 版本即可。
MQ 未来展望
目前消息保留时间较短,不方便对问题排查以及数据预测,我们接下来将对历史消息进行归档以及基于此的数据预测。
历史数据归档
底层存储剥离,计算与存储分离
基于历史数据,完成更多数据预测
服务端升级到 Dledger ,确保消息的严格一致
了解更多 RocketMQ 信息,可加入社区交流群,下面是钉钉群,欢迎大家加群留言。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK