

数据仓库--数据分层(ETL、ODS、DW、APP、DIM)
source link: https://blog.csdn.net/pmdream/article/details/113601956
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
参考:
https://www.cnblogs.com/itboys/p/10592871.html 数据仓库--通用的数据仓库分层方法
数据仓库各层说明:
一、数据加载层:ETL(Extract-Transform-Load)
二、数据运营层:ODS(Operational Data Store)
三、数据仓库层:DW(Data Warehouse)
1. 数据明细层:DWD(Data Warehouse Detail)
2. 数据中间层:DWM(Data WareHouse Middle)
3. 数据服务层:DWS(Data WareHouse Service)
四、数据应用层:APP(Application)
五、维表层:DIM(Dimension)
分层好处:
清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
复杂问题简单化:将复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。当数据出现问题之后,不用修复所有的数据,只需要从有问题的步骤开始修复。
屏蔽原始数据的异常:不必改一次业务就需要重新接入数据。
我们将数据模型分为三层:数据运营层( ODS )、数据仓库层(DW)和数据应用层(APP):
ODS层存放的是接入的原始数据,DW层是存放我们要重点设计的数据仓库中间层数据,APP是面向业务定制的应用数据。
一、数据运营层:ODS(Operational Data Store)
“面向主题的”数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
一般来讲,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD层来做。
二、数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和DWS(Data WareHouse Servce)层。
1. 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性,后文会举例说明。
2. 数据中间层:DWM(Data WareHouse Middle)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
3. 数据服务层:DWS(Data WareHouse Servce)
又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS亦可。
三、数据应用层:APP(Application)
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
四、维表层(Dimension)
最后补充一个维表层,维表层主要包含两部分数据:
高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
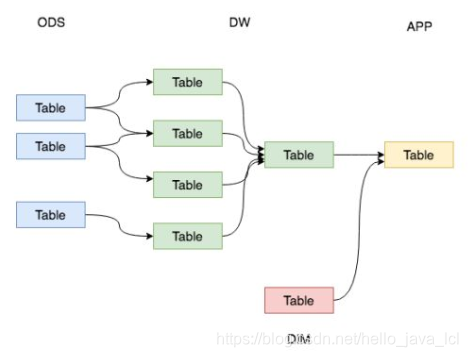
至此,我们讲完了数据分层设计中每一层的含义,这里做一个总结便于理解,如下图。

主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”。
各层示例应用说明:
如下图,可以认为是一个电商网站的数据体系设计。我们暂且只关注用户访问日志这一部分数据。

按业务分类汇总数据源,ODS层不同来源的日志文件汇总成一张表,保存到DWD层;
从DWD层中选取业务关注的核心维度来做聚合操作,比如只保留人、商品、设备和页面区域维度,以此类推生成很多个DWM的中间表;
从DWM层抽取数据,将一个人在整个网站中的行为数据放到一张表中,到DWS层,这就是我们的宽表了,可以快速满足大部分的通用型业务需求;
最后,在APP应用层,根据需求从DWS层的一张或者多张表取出数据拼接成一张应用表即可
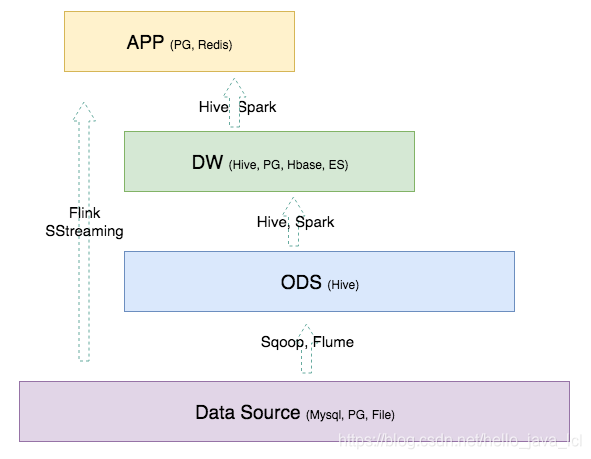
不同的层次中会用到什么计算引擎和存储系统:
数据层的存储一般如下:
Data Source:数据源一般是业务库和埋点,当然也会有第三方购买数据等多种数据来源方式。业务库的存储一般是Mysql 和 PostgreSql。
ODS 层:ODS 的数据量一般非常大,所以大多数公司会选择存在HDFS上,即Hive或者Hbase,Hive居多。
DW 层:一般和 ODS 的存储一致,但是为了满足更多的需求,也会有存放在 PG 和 ES 中的情况。
APP 层:应用层的数据,一般都要求比较快的响应速度,因此一般是放在 Mysql、PG、Redis中。
计算引擎的话,可以简单参考图中所列就行。目前大数据相关的技术更新迭代比较快,本节所列仅为简单参考。
从能力范围来讲,我们希望80%需求由20%的表来支持。直接点讲,就是大部分(80%以上)的需求,都用DWS的表来支持就行,DWS支持不了的,就用DWM和DWD的表来支持,这些都支持不了的极少一部分数据需要从原始日志中捞取。结合第一点来讲的话就是:80%的需求,我们都希望以对应用很友好的方式来支持,而不是直接暴露给应用方原始日志。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK