

diziet | Recent Entries
source link: https://diziet.dreamwidth.org/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Summary
I have just tagged nailing-cargo/1.0.0.
nailing-cargo
is a wrapper around the Rust build tool cargo. nailing-cargo can:
Work around cargo's problem with totally unpublished local crates (by temporally massaging your
Cargo.toml)Make it easier to work in Rust without giving the Rust environment (and every author of every one of your dependencies!) control of your main account. (Privsep, with linkfarming where needed.)
- Tweak a few defaults.
Background and history
It's not really possible to make a nontrivial Rust project without
using cargo.
But the build process automatically downloads and executes code from
crates.io, which is a minimally-curated repository.
I didn't want to expose my main account to that.
And, at the time, I was working on a project which for which I was also writing a library as a dependency, and I found that cargo couldn't cope with this unless I were to commit (to my git repository) the path (on my local laptop) of my dependency.
I filed some bugs, including about the unpublished crate problem. But also, I was stubborn enough to try to find a workaround that didn't involve committing junk to my git history. The result was a short but horrific shell script.
I wrote about this at the time (March 2019).
Over the last few years the difficulties I have with cargo have remained un-resolved. I found my interactions with upstream rather discouraging. It didn't seem like I would get anywhere by trying to help improve cargo to better support my needs.
So instead I have gradually improved nailing-cargo. It is now a Perl script. It is rather less horrific, and has proper documentation (sorry, JS needed because GitLab).
Why Perl ?
Rust would have been my language of choice. But I wanted to avoid a chicken-and-egg situation. When you're doing privsep, nailing-cargo has to run in your more privileged environment. I wanted something easy to get going with.
nailing-cargo has to contain a TOML parser; and I found a small one,
TOML-Tiny, which was good enough as a starting point, and small enough
I could bundle it as a git subtree. Perl is nicely fast to start up
(nailing-cargo --- true runs in about 170ms on my
laptop), and it is easy to write a Perl script that will work on
pretty much any Perl installation.
Still unsolved: embedding cargo in another build system
A number of my projects contain a mixture of Rust code with other languages. Unfortunately, nailing-cargo doesn't help with the problems which arise trying to integrate cargo into another build system.
I generally resort to find runes for finding Rust source
files that might influence cargo, and stamp files for seeing if I have
run it recently enough; and I simply live with the fact that cargo
sometimes builds more stuff than I needed it to.
Future
There are a number of ways nailing-cargo could be improved.
Notably, the need to overwrite your actual Cargo.toml is
very annoying, even if nailing-cargo puts it back afterwards.
A big problem with this is that it means that
nailing-cargo has to take a lock, while your cargo rune runs.
This effectively prevents using nailing-cargo with long-running
processes. Notably, editor integrations like rls and racer.
I could perhaps solve this with more linkfarm-juggling, but that
wouldn't help in-tree builds and it's hard to keep things up to date.
I am considering using
LD_PRELOAD trickery or maybe bwrap(1) to "implement"
the alternative Cargo.toml feature which was
rejected by cargo upstream in 2019
(and
again in April
when someone else asked).
Currently there is no support for using sudo for
out-of-tree privsep. This should be easy to add but it needs someone
who uses sudo to want it (and to test it!)
The documentation has some other
dicusssion of limitations, some of
which aren't too hard to improve.
Patches welcome!
I have just disconnected from irc.freenode.net for the last time. You should do the same. The awful new de facto operators are using user numbers as a public justification for their behaviour. Specifically, I recommend that you:
- Move your own channels to to Libera or OFTC
- If you have previously been known to be generally around on Freenode, connect to Libera (the continuity network set up by the Freenode staff), and register your usual nick(s) there.
- Disconnect from freenode so that you don't count as one of their users.
Note that mentioning libera in the channel topic of your old channels on freenode is likely to get your channel forcibly taken over by the new de facto operators of freenode. They won't tolerate you officially directing people to the competition.
I did an investigation and writeup of this situation for the Xen Project. It's a little out of date - it doesn't have the latest horrible behaviours from the new regime - but I think it is worth pasting it here:
Message-ID: <[email protected]> From: Ian Jackson <[email protected]> To: [email protected] CC: [email protected] Subject: IRC networks Date: Wed, 19 May 2021 16:39:02 +0100 Summary: We have for many years used the Freenode IRC network for real-time chat about Xen. Unfortunately, Freenode is undergoing a crisis. There is a dispute between, on the one hand, Andrew Lee, and on the other hand, all (or almost all) Freenode volunteer staff. We must make a decision. I have read all the publicly available materials and asked around with my contacts. My conclusions: * We do not want to continue to use irc.freenode.*. * We might want to use libera.chat, but: * Our best option is probably to move to OFTC https://www.oftc.net/ Discussion: Firstly, my starting point. I have been on IRC since at least 1993. Currently my main public networks are OFTC and Freenode. I do not have any personal involvement with public IRC networks. Of the principals in the current Freenode dispute, I have only heard of one, who is a person I have experience of in a Debian context but have not worked closely with. George asked me informally to use my knowledge and contacts to shed light on the situation. I decided that, having done my research, I would report more formally and publicly here rather than just informally to George. Historical background: * Freenode has had drama before. In about 2001 OFTC split off from Freenode after an argument over governance. IIRC there was drama again in 2006. Significant proportion of the Free Software world, including Debian, now use OFTC. Debian switched in 2006. Facts that I'm (now) pretty sure of: * Freenode's actual servers run on donated services; that is, the hardware is owned by those donating the services, and the systems are managed by Freenode volunteers, known as "staff". * The freenode domain names are currently registered to a limited liability company owned by Andrew Lee (rasengan). * At least 10 Freenode staff have quit in protest, writing similar resignation letters protesting about Andrew Lee's actions [1]. It does not appear that any Andrew Lee has the public support of any Freenode staff. * Andrew Lee claims that he "owns" Freenode.[2] * A large number of channel owners for particular Free Software projects who previously used Freenode have said they will switch away from Freenode. Discussion and findings on Freenode: There is, as might be expected, some murk about who said what to whom when, what promises were made and/or broken, and so on. The matter was also complicated by the leaking earlier this week of draft(s) of (at least one of) the Freenode staffers' resignation letters. Andrew Lee has put forward a position statement [2]. A large part of the thrust of that statement is allegations that the current head of Freenode staff, tomaw, "forced out" the previous head, christel. This allegation is strongly disputed by by all those current (resigning) Freenode staff I have seen comment. In any case it does not seem to be particularly germane; in none of my reading did tomaw seem to be playing any kind of leading role. tomaw is not mentioned in the resignation letters. Some of the links led to me to logs of discussions on #freenode. I read some of these in particular[3]. MB I haven't been able to verify that these logs have not been tampered with. Having said that and taking the logs at face value, I found the rasengan writing there to be disingenuous and obtuse. Andrew Lee has been heavily involved in Bitcoin. Bitcoin is a hive of scum and villainy, a pyramid scheme, and an environmental disaster, all rolled into one. This does not make me think well of Lee. Additionally, it seems that Andrew Lee has been involved in previous governance drama involving a different IRC network, Snoonet. I have come to the very firm conclusion that we should have nothing to do with Andrew Lee, and avoid using services that he has some effective control over. Alternatives: The departing Freenode staff are setting up a replacement, "libera.chat". This is operational but still suffering from teething problems and of course has a significant load as it deals with an influx of users on a new setup. On the staff and trust question: As I say, I haven't heard of any of the Freenode staff, with one exception. Unfortunately the one exception does not inspire confidence in me[4] - although NB that is only one data point. On the other hand, Debian has had many many years of drama-free involvement with OFTC. OFTC has a formal governance arrangement and it is associated with Software in the Public Interest. I notice that the last few OFTC'[s annual officer elections have been run partly by Steve McIntyre. Steve is a friend of mine (and he is a former Debian Project Leader) and I take his involvement as a good sign. I recommend that we switch to using OFTC as soon as possible. Ian. References: Starting point for the resigning Freenode staff's side [1]: https://gist.github.com/joepie91/df80d8d36cd9d1bde46ba018af497409 Andrew Lee's side [2]: https://gist.github.com/realrasengan/88549ec34ee32d01629354e4075d2d48 [3] https://paste.sr.ht/~ircwright/7e751d2162e4eb27cba25f6f8893c1f38930f7c4 [4] I won't give the name since I don't want to be shitposting.
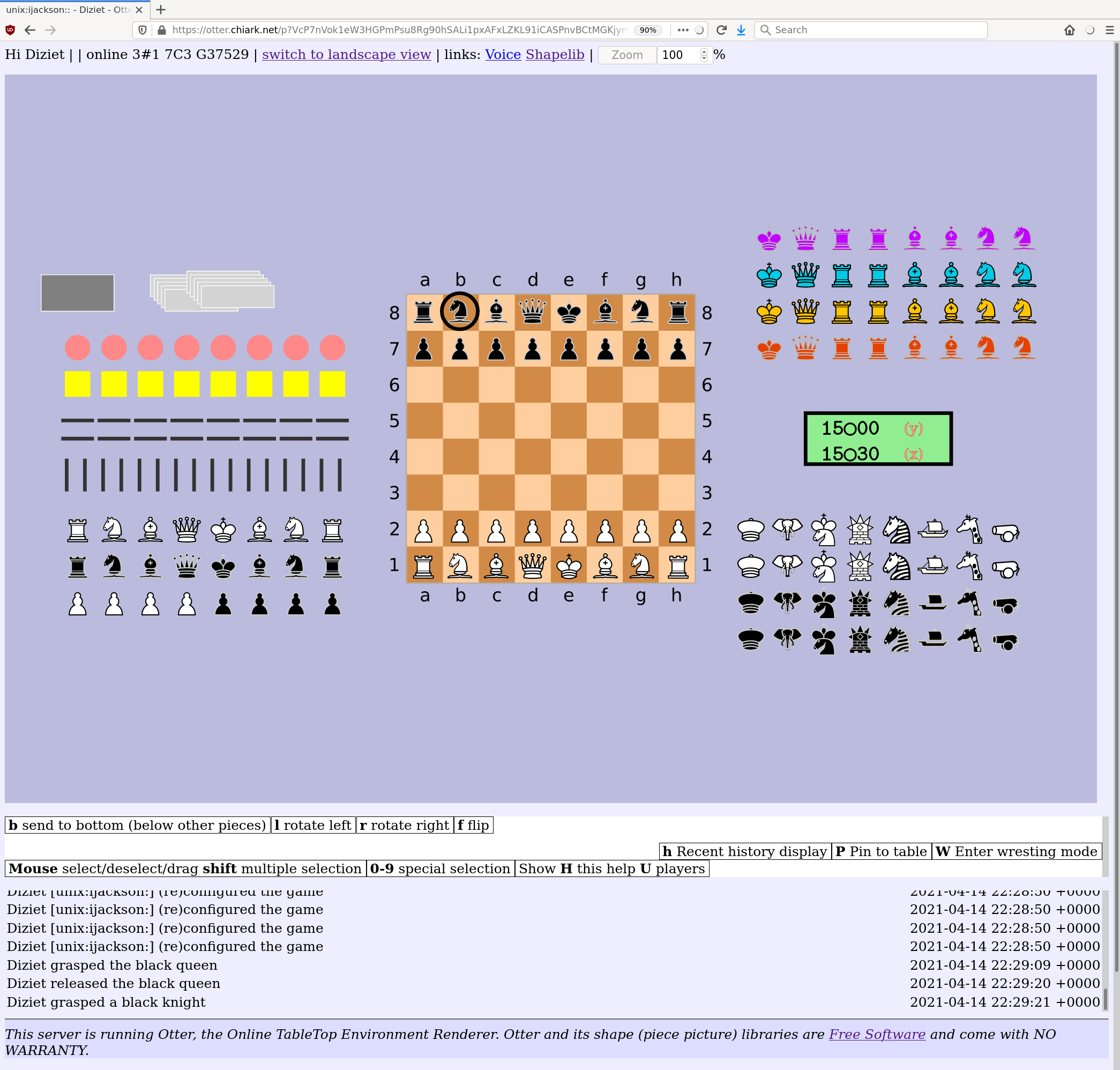
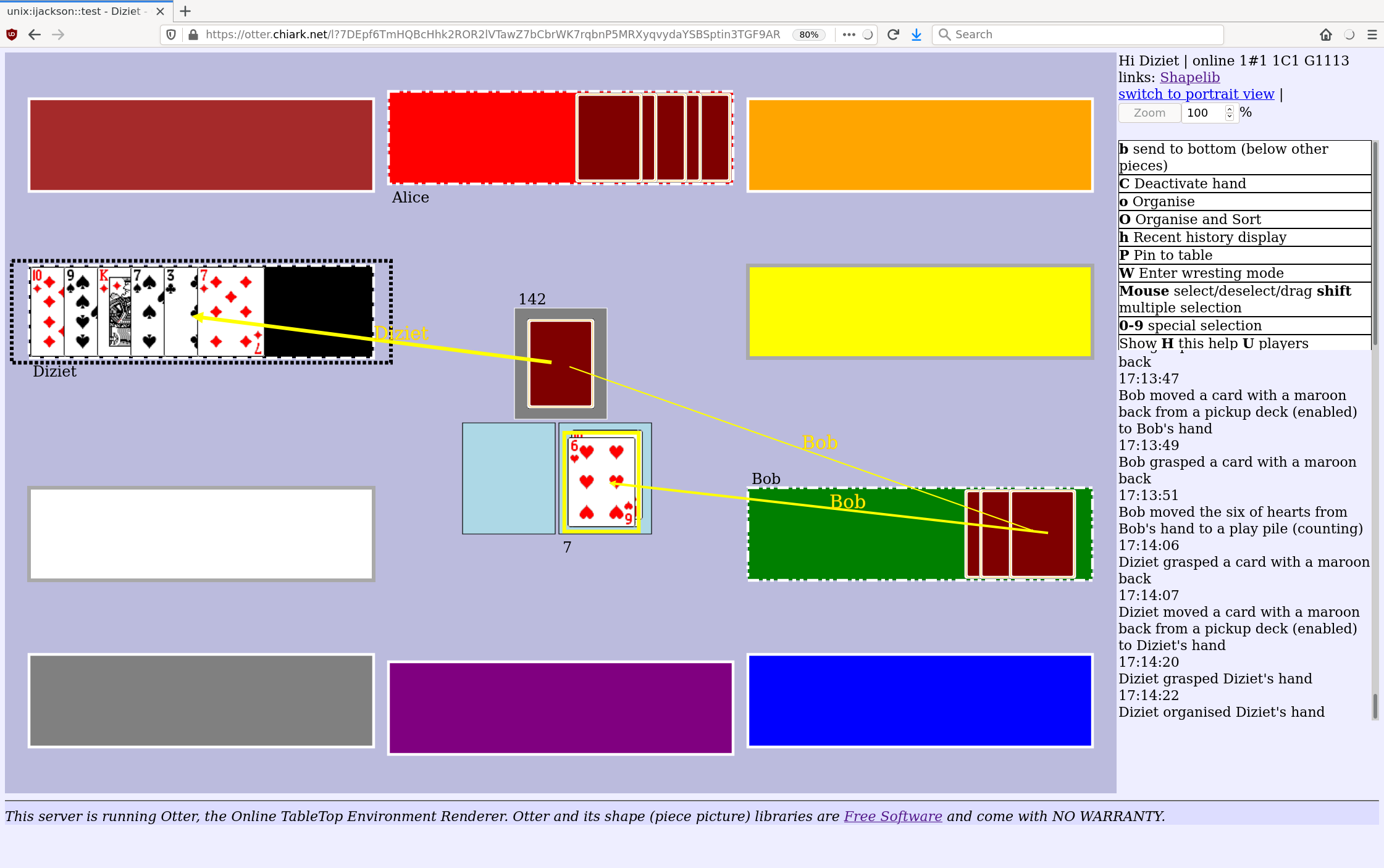
In April I wrote about releasing Otter, which has been one of my main personal projects during the pandemic.
Uploadable game materials
Otter comes with playing cards and a chess set, and some ancillary bits and bobs. Until now, if you wanted to play with something else, the only way was to read some rather frightening build instructions to add your pieces to Otter itself, or to dump a complicated structure of extra files into the server install.
Now that I have released Otter 0.6.0, you can upload a zipfile to the server. The format of the zipfile is even documented!
Otter development - I still love Rust
Working on Otter has been great fun, partly because it has involved learning lots of new stuff, and partly because it's mosty written in Rust. I love Rust; one of my favourite aspects is the way it's possible to design a program so that most of your mistakes become compile errors. This means you spend more time dealing with compiler errors and less time peering at a debugger trying to figure out why it has gone wrong.
Future plans - help wanted!
So far, Otter has been mostly a one-person project. I would love to have some help. There are two main areas where I think improvement is very important:
I want it to be much easier to set up an Otter server yourself, for you and your friends. Currently there are complete build instructions, but nowadays these things can be automated. Ideally it would be possible to set up an instance by button pushing and the payment of a modest sum to a cloud hosting provider.
- Right now, the only way to set up a game, manage the players in it, reset the gaming table, and so on, is using the otter command line tool. It's not so bad a tool, but having something pointy clicky would make the system much more accessible. But GUIs of this kind are a lot of work.
If you think you could help with these, and playing around with a game server sounds fun, do get in touch.
For now, next on my todo list is to provide a nicely cooked git-forge-style ssh transport facility, so that you don't need a shell account on the server but can run the otter command line client tool locally.
One of the things that I found most vexing about lockdown was that I was unable to play some of my favourite board games. There are online systems for many games, but not all. And online systems cannot support games like Mao where the players make up the rules as we go along.
I had an idea for how to solve this problem, and set about implementing it. The result is Otter (the Online Table Top Environment Renderer).
We have played a number of fun games of Penultima with it, and have recently branched out into Mao. The Otter is now ready to be released!
More about Otter
(cribbed shamelessly from the README)
Otter, the Online Table Top Environment Renderer, is an online game system.
But it is not like most online game systems. It does not know (nor does it need to know) the rules of the game you are playing. Instead, it lets you and your friends play with common tabletop/boardgame elements such as hands of cards, boards, and so on.
So it’s something like a “tabletop simulator” (but it does not have any 3D, or a physics engine, or anything like that).
This means that with Otter:
Supporting a new game, that Otter doesn’t know about yet, would usually not involve writing or modifying any computer programs.
If Otter already has the necessary game elements (cards, say) all you need to do is write a spec file saying what should be on the table at the start of the game. For example, most Whist variants that start with a standard pack of 52 cards are already playable.
You can play games where the rules change as the game goes along, or are made up by the players, or are too complicated to write as a computer program.
House rules are no problem, since the computer isn’t enforcing the rules - you and your friends are.
Everyone can interact with different items on the game table, at any time. (Otter doesn’t know about your game’s turn-taking, so doesn’t know whose turn it might be.)
Installation and usage
Otter is fully functional, but the installation and account management arrangements are rather unsophisticated and un-webby. And there is not currently any publicly available instance you can use to try it out.
Users on chiark will find an instance there.
Other people who who are interested in hosting games (of Penultima or Mao, or other games we might support) will have to find a Unix host or VM to install Otter on, and will probably want help from a Unix sysadmin.
Otter is distributed via git, and is available on Salsa, Debian's gitlab instance.
There is documentation online.
Future plans
I have a number of ideas for improvement, which go off in many different directions.
Quite high up on my priority list is making it possible for players to upload and share game materials (cards, boards, pieces, and so on), rather than just using the ones which are bundled with Otter itself (or dumping files ad-hoc on the server). This will make it much easier to play new games. One big reason I wrote Otter is that I wanted to liberate boardgame players from the need to implemet their game rules as computer code.
The game management and account management is currently done with a command line tool. It would be lovely to improve that, but making a fully-featured management web ui would be a lot of work.
Screenshots!
(Click for the full size images.)
This started at around 0500 UTC on Wednesday morning, according to my own RSS reader cron job. A friend found #43443 in the DW ticket tracker, where a user of a minority web browser found they were blocked.
Local tests demonstrated that Dreamwidth had applied blocking by the HTTP User-Agent header, and were rejecting all user-agents not specifically permitted. Today, this rule has been relaxed and unknown user-agents are permitted. But user-agents for general http client libraries are still blocked.
I'm aware of three unresolved tickets about this: #43444 #43445 #43447
We're told there by a volunteer member of Dreamwidth's support staff that this has been done deliberately for "blocking automated traffic". I'm sure the volunteer is just relaying what they've been told by whoever is struggling to deal with what I suppose is probably a spam problem. But it's still rather unsatisfactory.
I have suggested in my own ticket that a good solution might be to apply the new block only to posting and commenting (eg, maybe, by applying it only to HTTP POST requests). If the problem is indeed spam then that ought to be good enough, and would still let RSS readers work properly.
I'm told that this new blocking has been done by "implementing" (actually, configuring or enabling) "some AWS rules for blocking automated traffic". I don't know what facilities AWS provides. This kind of helplessness is of course precisely the kind of thing that the Free Software movement is against and precisely the kind of thing that proprietary services like AWS produce.
I don't know if this blog entry will appear on planet.debian.org and on other people's reader's and aggregators. I think it will at least be seen by other Dreamwidth users. I thought I would post here in the hope that other Dreamwidth users might be able to help get this fixed. At the very least other Dreamwidth blog owners need to know that many of their readers may not be seeing their posts at all.
If this problem is not fixed I will have to move my blog. One of the main points of having a blog is publishing it via RSS. RSS readers are of course based on general http client libraries and many if not most RSS readers have not bothered to customise their user-agent. Those are currently blocked.
Here is what I wrote in my commit message:
I published my first Free Software in 1989, under the GNU General
Public Licence. I remain committed to the ideal of software freedom,
for everyone.
When the CSAIL list incident blew up I was horrified to read the
stories of RMS's victims. We have collectively failed those people
and I am glad to see that many of us are working to make a better
community.
I have watched with horror as RMS has presided over, and condoned,
astonishingly horrible behaviour in many GNU Project discussion
venues.
The Free Software Foundation Board are doing real harm by reinstating
an abuser. I had hoped for and expected better from them.
RMS's vision and ideals of software freedom have been inspiring to me.
But his past behaviour and current attitudes mean he must not and can
not be in a leadership position in the Free Software community.
Comments are disabled. Edited 2021-03-23T21:44Z to fix a typo in the commit message.
Today we completed our gazebo, which we designed and built out of scaffolding:

Scaffolding is fairly expensive but building things out of it is enormous fun! You can see a complete sequence of the build process, including pictures of the "engineering maquette", at https://www.chiark.greenend.org.uk/~ijackson/2020/scaffold/
Post-lockdown maybe I will build a climbing wall or something out of it...
edited 2020-11-08 20:44Z to fix img url following hosting reorg
tl;dr: Do not configure Mailman to replace the mail domains in From: headers. Instead, try out my small new program which can make your Mailman transparent, so that DKIM signatures survive.
Background and narrative
NB: This explanation is going to be somewhat simplified. I am going to gloss over some details and make some slightly approximate statements.
DKIM is a new anti-spoofing mechanism for Internet email, intended to help fight spam. DKIM, paired with the DMARC policy system, has been remarkably successful at stemming the flood of joe-job spams. As usually deployed, DKIM works like this:
When a message is originally sent, the author's MUA sends it to the MTA for their From: domain for outward delivery. The From: domain mailserver calculates a cryptographic signature of the message, and puts the signature in the headers of the message.
Obviously not the whole message can be signed, since at the very least additional headers need to be added in transit, and sometimes headers need to be modified too. The signing MTA gets to decide what parts of the message are covered by the signature: they nominate the header fields that are covered by the signature, and specify how to handle the body.
A recipient MTA looks up the public key for the From: domain in the DNS, and checks the signature. If the signature doesn't match, depending on policy (originator's policy, in the DNS, and recipient's policy of course), typically the message will be treated as spam.
The originating site has a lot of control over what happens in practice. They get to publish a formal (DMARC) policy in the DNS which advises recipients what they should do with mails claiming to be from their site. As mentioned, they can say which headers are covered by the signature - including the ability to sign the absence of a particular headers - so they can control which headers downstreams can get away with adding or modifying. And they can set a normalisation policy, which controls how precisely the message must match the one that they sent.
Mailman
Mailman is, of course, the extremely popular mailing list manager. There are a lot of things to like about it. I choose to run it myself not just because it's popular but also because it provides a relatively competent web UI and a relatively competent email (un)subscription interfaces, decent bounce handling, and a pretty good set of moderation and posting access controls.
The Xen Project mailing lists also run on mailman. Recently we had some difficulties with messages sent by Citrix staff (including myself), to Xen mailing lists, being treated as spam. Recipient mail systems were saying the DKIM signatures were invalid.
This was in fact true. Citrix has chosen a fairly strict DKIM policy; in particular, they have chosen "simple" normalisation - meaning that signed message headers must precisely match in syntax as well as in a semantic sense. Examining the the failing-DKIM messages showed that this was definitely a factor.
Applying my Opinions about email
My Bayesian priors tend to suggest that a mail problem involving corporate email is the fault of the corporate email. However in this case that doesn't seem true to me.
My starting point is that I think mail systems should not not modify messages unnecessarily. None of the DKIM-breaking modifications made by Mailman seemed necessary to me. I have on previous occasions gone to corporate IT and requested quite firmly that things I felt were broken should be changed. But it seemed wrong to go to corporate IT and ask them to change their published DKIM/DMARC policy to accomodate a behaviour in Mailman which I didn't agree with myself. I felt that instead I shoud put (with my Xen Project hat on) my own house in order.
Getting Mailman not to modify messages
So, I needed our Mailman to stop modifying the headers. I needed it to not even reformat them. A brief look at the source code to Mailman showed that this was not going to be so easy. Mailman has a lot of features whose very purpose is to modify messages.
Personally, as I say, I don't much like these features. I think the subject line tags, CC list manipulations, and so on, are a nuisance and not really Proper. But they are definitely part of why Mailman has become so popular and I can definitely see why the Mailman authors have done things this way. But these features mean Mailman has to disassemble incoming messages, and then reassemble them again on output. It is very difficult to do that and still faithfully reassemble the original headers byte-for-byte in the case where nothing actually wanted to modify them. There are existing bug reports[1] [2] [3] [4]; I can see why they are still open.
Rejected approach: From:-mangling
This situation is hardly unique to the Xen lists. Many other have struggled with it. The best that seems to have been come up with so far is to turn on a new Mailman feature which rewrites the From: header of the messages that go through it, to contain the list's domain name instead of the originator's.
I think this is really pretty nasty. It breaks normal use of email, such as reply-to-author. It is having Mailman do additional mangling of the message in order to solve the problems caused by other undesirable manglings!
Solution!
As you can see, I asked myself: I want Mailman not modify messages at all; how can I get it to do that? Given the existing structure of Mailman - with a lot of message-modifying functionality - that would really mean adding a bypass mode. It would have to spot, presumably depending on config settings, that messages were not to be edited; and then, it would avoid disassembling and reassembling the message at at all, and bypass the message modification stages. The message would still have to be parsed of course - it's just that the copy send out ought to be pretty much the incoming message.
When I put it to myself like that I had a thought: couldn't I implement this outside Mailman? What if I took a copy of every incoming message, and then post-process Mailman's output to restore the original?
It turns out that this is quite easy and works rather well!
outflank-mailman
outflank-mailman is a 233-line script, plus documentation, installation instructions, etc.
It is designed to run from your MTA, on all messages going into, and coming from, Mailman. On input, it saves a copy of the message in a sqlite database, and leaves a note in a new Outflank-Mailman-Id header. On output, it does some checks, finds the original message, and then combines the original incoming message with carefully-selected headers from the version that Mailman decided should be sent.
This was deployed for the Xen Project lists on Tuesday morning and it seems to be working well so far.
If you administer Mailman lists, and fancy some new software to address this problem, please do try it out.
Matters arising - Mail filtering, DKIM
Overall I think DKIM is a helpful contribution to the fight against spam (unlike SPF, which is fundamentally misdirected and also broken). Spam is an extremely serious problem; most receiving mail servers experience more attempts to deliver spam than real mail, by orders of magnitude. But DKIM is not without downsides.
Inherent in the design of anything like DKIM is that arbitrary modification of messages by list servers is no longer possible. In principle it might be possible to design a system which tolerated modifications reasonable for mailing lists but it would be quite complicated and have to somehow not tolerate similar modifications in other contexts.
So DKIM means that lists can no longer add those unsubscribe footers to mailing list messages. The "new way" (RFC2369, July 1998), to do this is with the List-Unsubscribe header. Hopefully a good MUA will be able to deal with unsubscription semiautomatically, and I think by now an adequate MUA should at least display these headers by default.
Sender:
There are implications for recipient-side filtering too. The "traditional" correct way to spot mailing list mail was to look for Resent-To:, which can be added without breaking DKIM; the "new" (RFC2919, March 2001) correct way is List-Id:, likewise fine. But during the initial deployment of outflank-mailman I discovered that many subscribers were detecting that a message was list traffic by looking at the Sender: header. I'm told that some mail systems (apparently Microsoft's included) make it inconvenient to filter on List-Id.
Really, I think a mailing list ought not to be modifying Sender:. Given Sender:'s original definition and semantics, there might well be reasonable reasons for a mailing list posting to have different From: and and then the original Sender: ought not to be lost. And a mailing list's operation does not fit well into the original definition of Sender:. I suspect that list software likes to put in Sender mostly for historical reasons; notably, a long time ago it was not uncommon for broken mail systems to send bounces to the Sender: header rather than the envelope sender (SMTP MAIL FROM).
DKIM makes this more of a problem. Unfortunately the DKIM specifications are vague about what headers one should sign, but they pretty much definitely include Sender: if it is present, and some materials encourage signing the absence of Sender:. The latter is Exim's default configuration when DKIM-signing is enabled.
Franky there seems little excuse for systems to not readily support and encourage filtering on List-Id, 20 years later, but I don't want to make life hard for my users. For now we are running a compromise configuration: if there wasn't a Sender: in the original, take Mailman's added one. This will result in (i) misfiltering for some messages whose poster put in a Sender:, and (ii) DKIM failures for messages whose originating system signed the absence of a Sender:. I'm going to mine the db for some stats after it's been deployed for a week or so, to see which of these problems is worst and decide what to do about it.
Mail routing
For DKIM to work, messages being sent From: a particular mail domain must go through a system trusted by that domain, so they can be signed.
Most users tend to do this anyway: their mail provider gives them an IMAP server and an authenticated SMTP submission server, and they configure those details in their MUA. The MUA has a notion of "accounts" and according to the user's selection for an outgoing message, connects to the authenticated submission service (usually using TLS over the global internet).
Trad unix systems where messages are sent using the local sendmail or localhost SMTP submission (perhaps by automated systems, or perhaps by human users) are fine too. The smarthost can do the DKIM signing.
But this solution is awkward for a user of a trad MUA in what I'll call "alias account" setups: where a user has an address at a mail domain belonging to different people to the system on which they run their MUA (perhaps even several such aliases for different hats). Traditionally this worked by the mail domain forwarding incoming the mail, and the user simply self-declaring their identity at the alias domain. Without DKIM there is nothing stopping anyone self-declaring their own From: line.
If DKIM is to be enabled for such a user (preventing people forging mail as that user), the user will have to somehow arrange that their trad unix MUA's outbound mail stream goes via their mail alias provider. For a single-user sending unix system this can be done with tolerably complex configuration in an MTA like Exim. For shared systems this gets more awkward and might require some hairy shell scripting etc.
edited 2020-10-01 21:22 and 21:35 and -02 10:50 +0100 to fix typos and 21:28 to linkify "my small program" in the tl;drAny software system has underlying design principles, and any software project has process rules. But I seem to be seeing more often, a pathological pattern where abstract and shakily-grounded broad principles, and even contrived and sophistic objections, are used to block sensible changes.
Today I will go through an example in detail, before ending with a plea:
PostgreSQL query planner, WITH [MATERIALIZED]
optimisation fence
Background history
PostgreSQL has a sophisticated query planner which usually gets the right answer. For good reasons, the pgsql project has resisted providing lots of knobs to control query planning. But there are a few ways to influence the query planner, for when the programmer knows more than the planner.
One of these is the use of a WITH common table
expression. In pgsql versions prior to 12, the planner would
first make a plan for the WITH clause; and then, it would make
a plan for the second half, counting the WITH clause's likely
output as a given. So WITH acts as an "optimisation fence".
This was documented in the manual - not entirely clearly, but a careful reading of the docs reveals this behaviour:
The
WITHquery will generally be evaluated as written, without suppression of rows that the parent query might discard afterwards.
Users (authors of applications which use PostgreSQL) have been using this technique for a long time.
New behaviour in PostgreSQL 12
In PostgreSQL 12 upstream were able to make the query planner
more sophisticated. In particular, it is now often capable of
looking "into" the WITH common table expression. Much of the time
this will make things better and faster.
WITH was being used for its side-effect as an optimisation
fence, this change will break things: queries that ran very quickly
in earlier versions might now run very slowly. Helpfully,
pgsql 12 still has a way to specify an optimisation fence:
specifying WITH ... AS MATERIALIZED in the query.
So far so good.
Upgrade path for existing users of WITH fence
But what about the upgrade path for existing users of the WITH
fence behaviour?
Such users will have to update their queries to add AS MATERIALIZED.
This is a small change. Having to update a query like this
is part of routine software maintenance and not in itself
very objectionable. However, this change cannnot be made
in advance because pgsql versions prior to 12 will reject
the new syntax.
So the users are in a bit of a bind. The old query syntax can be unuseably slow with the new database and the new syntax is rejected by the old database. Upgrading both the database and the application, in lockstep, is a flag day upgrade, which every good sysadmin will want to avoid.
A solution to this problem
Colin Watson proposed a very simple solution: make the earlier PostgreSQL versions accept the new MATERIALIZED syntax. This is correct since the new syntax specifies precisely the actual behaviour of the old databases. It has no deleterious effect on any users of older pgsql versions. It makes it possible to add the new syntax to the application, before doing the database upgrade, decoupling the two upgrades.
Colin Watson even provided an implementation of this proposal.
The solution is rejected by upstream
Unfortunately upstream did not accept this idea. You can read the whole thread yourself if you like. But in summary, the objections were (italic indicates literal quotes):
- New features don't gain a backpatch. This is a project policy. Of course this is not a new feature, and if it is an exception should be made. This was explained clearly in the thread.
- I'm not sure the "we don't want to upgrade application code at the same time as the database" is really tenable. This is quite an astonishing statement, particularly given the multiple users who said they wanted to do precisely that.
- I think we could find cases where we caused worse breaks between major versions. Paraphrasing: "We've done worse things in the past so we should do this bad thing too". WTF?
- One disadvantage is that this will increase confusion for users, who'll get used to the behavior on 12, and then they'll get confused on older releases. This seems highly contrived. Surely the number of people who are likely to suffer this confusion is tiny. Providing the new syntax in old versions (including of course the appropriate changes to the docs everywhere) might well make such confusion less rather than more likely.
- [Poster is concerned about] 11.6 and up allowing a syntax that 11.0-11.5 don't. People are likely to write code relying on this and then be surprised when it doesn't work on a slightly older server. And, similarly: we'll then have a lot more behavior differences between minor releases. Again this seems a contrived and unconvincing objection. As that first poster even notes: Still, is that so much different from cases where we fix a bug that prevented some statement from working? No, it isn't.
- if we started looking we'd find many changes every year that we could justify partially or completely back-porting on similar grounds ... we'll certainly screw it up sometimes. This is a slippery slope argument. But there is no slippery slope: in particular, the proposed change does not change any of the substantive database logic, and the upstream developers will hardly have any difficulty rejecting future more risky backport proposals.
- if you insist on using the same code with pre-12 and post-12 releases, this should be achievable (at least in most cases) by using the "offset 0" trick. What? First I had heard of it but this in fact turns out to be true! Read more about this, below...
I find these extremely unconvincing, even taken together. Many of them are very unattractive things to hear one's upstream saying.
At best they are knee-jerk and inflexible application of very general principles. The authors of these objections seem to have lost sight of the fact that these principles have a purpose. When these kind of software principles work against their purposes, they should be revised, or exceptions made.
At worst, it looks like a collective effort to find reasons - any reasons, no matter how bad - not to make this change.
The OFFSET 0 trick
One of the responses in the thread mentions OFFSET 0.
As part of writing the queries in the Xen Project CI system, and
preparing for our system upgrade, I had carefully read the relevant
pgsql documentation. This OFFSET 0 trick was new to me.
But, now that I know the answer, it is easy to provide the right
search terms and find, for example, this
answer on stackmumble.
Apparently adding a no-op OFFSET 0 to the subquery
defeats the pgsql 12 query planner's ability to see into the subquery.
I think
OFFSET 0is the better approach since it's more obviously a hack showing that something weird is going on, and it's unlikely we'll ever change the optimiser behaviour aroundOFFSET 0... wheras hopefully CTEs will become inlineable at some point CTEs became inlineable by default in PostgreSQL 12.
So in fact there is a syntax for an optimisation fence that is accepted by both earlier and later PostgreSQL versions. It's even recommended by pgsql devs. It's just not documented, and is described by pgsql developers as a "hack". Astonishingly, the fact that it is a "hack" is given as a reason to use it!
Well, I have therefore deployed this "hack". No doubt it will stay
in our codebase indefinitely.
Please don't be like that!
I could come up with a lot more examples of other projects that have exhibited similar arrogance. It is becoming a plague!
But every example is contentious, and I don't really feel I need to annoy a dozen separate Free Software communities. So I won't make a laundry list of obstructiveness.
If you are an upstream software developer, or a distributor of software to users (eg, a distro maintainer), you have a lot of practical power. In theory it is Free Software so your users could just change it themselves. But for a user or downstream, carrying a patch is often an unsustainable amount of work and risk. Most of us have patches we would love to be running, but which we haven't even written because simply running a nonstandard build is too difficult, no matter how technically excellent our delta.
As an upstream, it is very easy to get into a mindset of defending your code's existing behaviour, and to turn your project's guidelines into inflexible rules. Constant exposure to users who make silly mistakes, and rudely ask for absurd changes, can lead to core project members feeling embattled.
But there is no need for an upstream to feel embattled! You have the vast majority of the power over the software, and over your project communication fora. Use that power consciously, for good.
I can't say that arrogance will hurt you in the short term. Users of software with obstructive upstreams do not have many good immediate options. But we do have longer-term choices: we can choose which software to use, and we can choose whether to try to help improve the software we use.
After reading Colin's experience, I am less likely to try to help improve the experience of other PostgreSQL users by contributing upstream. It doesn't seem like there would be any point. Indeed, instead of helping the PostgreSQL community I am now using them as an example of bad practice. I'm only half sorry about that.
tl;dr: Use MessagePack, rather than CBOR.
Introduction
I recently wanted to choose a binary encoding. This was for a project using Rust serde, so I looked at the list of formats there. I ended up reading about CBOR and MessagePack.
Both of these are binary formats for a JSON-like data model. Both of them are "schemaless", meaning you can decode them without knowing the structure. (This also provides some forwards compatibility.) They are, in fact, quite similar (although they are totally incompatible). This is no accident: CBOR is, effectively, a fork of MessagePack.
Both formats continue to exist and both are being used in new programs. I needed to make a choice but lacked enough information. I thought I would try to examine the reasons and nature of the split, and to make some kind of judgement about the situation. So I did a lot of reading [11]. Here are my conclusions.
History and politics
Between about 2010 and 2013 there was only MessagePack. Unfortunately, MessagePack had some problems. The biggest of these was that it lacked a separate string type. Strings were to be encoded simply as byte blocks. This caused serious problems for many MessagePack library implementors: for example, when decoding a MessagePack file the Python library wouldn't know whether to produce a Python bytes object, or a string. Straightforward data structures wouldn't round trip through MessagePack. [1] [2]
It seems that in late 2012 this came to the attention to someone with an IETF background. According to them, after unsatisfactory conversations with MessagePack upstream, they decided they would have to fork. They submitted an Internet Draft for a partially-incompatible protocol [3] [4]. Little seemed to happen in the IETF until soon before the Orlando in-person IETF meeting in February 2013.[5]
These conversations sparked some discussion in the MessagePack issue tracker. There were long threads including about process [1,2,4 ibid]. But there was also a useful technical discussion, about proposed backward compatible improves to the MessagePack spec.[5] The prominent IETF contributor provided some helpful input in these discussions in the MessagePack community - but also pushed quite hard for a "tagging" system, which suggestion was not accepted (see my technical analysis, below).
An improved MessagePack spec resulted, with string support, developed largely by the MessagePack community. It seems to have been available in useable form since mid-2013 and was officially published as canonical in August 2013.
Meanwhile a parallel process was pursued in the IETF, based on the IETF contributor's fork, with 11 Internet-Drafts from February[7] to September[8]. This seems to have continued even though the original technical reason for the fork - lack of string vs binary distinction - no longer applied. The IETF proponent expressed unhappiness about MessagePack's stewardship and process as much as they did about the technical details [4, ibid]. The IETF process culminated in the CBOR RFC[9].
The discussion on process questions between the IETF proponent and MessagePack upstream, in the MessagePack issue tracker [4, ibid] should make uncomfortable reading for IETF members. The IETF acceptance of CBOR despite clear and fundamental objections from MessagePack upstream[13] and indeed other respected IETF members[14], does not reflect well on the IETF. The much vaunted openness of the IETF process seems to have been rather one-sided. The IETF proponent here was an IETF Chair. Certainly the CBOR author was very well-spoken and constantly talks about politeness and cooperation and process; but what they actually did was very hostile. They accused the MessagePack community of an "us and them" attitude while simultaneously pursuing a forked specification!
The CBOR RFC does mention MessagePack in Appendix E.2. But not to acknowledge that CBOR was inspired by MessagePack. Rather, it does so to make a set of tendentious criticisms of MessagePack. Perhaps these criticisms were true when they were first written in an I-D but they were certainly false by the time the RFC was actually published, which occurred after the MessagePack improvement process was completely concluded, with a formal spec issued.
Since then both formats have existed in parallel. Occasionally people discuss which one is better, and sometimes it is alleged that "yes CBOR is the successor to MessagePack", which is not really fair.[9][10]
Technical differences
The two formats have a similar arrangement: initial byte which can encode small integers, or type and length, or type and specify a longer length encoding. But there are important differences. Overall, MessagePack is very significantly simpler.
Floating point
CBOR supports five floating point formats! Not only three sizes of IEEE754, but also decimal floating point, and bigfloats. This seems astonishing for a supposedly-simple format. (Some of these are supported via the semi-optional tag mechanism - see below.)
Indefinite strings and arrays
Like MessagePack, CBOR mostly precedes items with their length. But CBOR also supports "indefinite" strings, arrays, and so on, where the length is not specified at the beginning. The object (array, string, whatever) is terminated by a special "break" item. This seems to me to be a mistake. If you wanted the kind of application where MessagePack or CBOR would be useful, streaming sub-objects of unknown length is not that important. This possibility considerably complicates decoders.
CBOR tagging system
CBOR has a second layer of sort-of-type which can be attached to each data item. The set of possible tags is open-ended and extensible, but the CBOR spec itself gives tag values for: two kinds of date format; positive and negative bignums; decimal floats (see above); binary but expected to be encoded if converted to JSON (in base64url, base64, or base16); nestedly encoded CBOR; URIs; base64 data (two formats); regexps; MIME messages; and a special tag to make file(1) work.
In practice it is not clear how many of these are used, but a decoder must be prepared to at least discard them. The amount of additional spec complexity here is quite astonishing. IMO binary formats like this will (just like JSON) be used by a next layer which always has an idea of what the data means, including (where the data is a binary blob) what encoding it is in etc. So these tags are not useful.
These tags might look like a middle way between (i) extending the binary protocol with a whole new type such as an extension type (incompatible with old readers) and encoding your new kind data in a existing type (leaving all readers who don't know the schema to print it as just integers or bytes or string). But I think they are more trouble than they are worth.
The tags are uncomfortably similar to the ASN.1 tag system, which is widely regarded as one of ASN.1's unfortunate complexities.
MessagePack extension mechanism
MessagePack explicitly reserves some encoding space for users and for future extensions: there is an "extension type". The payload is an extension type byte plus some more data bytes; the data bytes are in a format to be defined by the extension type byte. Half of the possible extension byte values are reserved for future specification, and half are designated for application use. This is pleasingly straightforward.
(There is also one unused primary initial byte value, but that would be rejected by existing decoders and doesn't seem like a likely direction for future expansion.)
Minor other differences in integer encoding
The encodings of integers differ.
In MessagePack, signed and unsigned integers have different typecodes. In CBOR, signed and unsigned positive integers have the same typecodes; negative integers have a different set of typecodes. This means that a CBOR reader which knows it is expecting a signed value will have to do a top-bit-set check on the actual data value! And a CBOR writer must check the value to choose a typecode.
MessagePack reserves fewer shortcodes for small negative integers, than for small positive integers.
Conclusions and lessons
MessagePack seems to have been prompted into fixing the missing string type problem, but only by the threat of a fork. However, this fork went ahead even after MessagePack clearly accepted the need for a string type. MessagePack had a fixed protocol spec before the IETF did.
The continued pursuit of the IETF fork was ostensibly been motivated by a disapproval of the development process and in particular a sense that the IETF process was superior. However, it seems to me that the IETF process was abused by CBOR's proponent, who just wanted things their own way. I have seen claims by IETF proponents that the open decisionmaking system inherently produces superior results. However, in this case the IETF process produced a bad specification. To the extent that other IETF contributors had influence over the ultimate CBOR RFC, I don't think they significantly improved it. CBOR has been described as MessagePack bikeshedded by the IETF. That would have been bad enough, but I think it's worse than that. To a large extent CBOR is one person's NIH-induced bad design rubber stamped by the IETF. CBOR's problems are not simply matters of taste: it's significantly overcomplicated.
One lesson for the rest of us is that although being the upstream and nominally in charge of a project seems to give us a lot of power, it's wise to listen carefully to one's users and downstreams. Once people are annoyed enough to fork, the fork will have a life of its own.
Another lesson is that many of us should be much warier of the supposed moral authority of the IETF. Many IETF standards are awful (Oauth 2 [12]; IKE; DNSSEC; the list goes on). Sometimes (especially when network adoption effects are weak, as with MessagePack vs CBOR) better results can be obtained from a smaller group, or even an individual, who simply need the thing for their own uses.
Finally, governance systems of public institutions like the IETF need to be robust in defending the interests of outsiders (and hence of society at large) against eloquent insiders who know how to work the process machinery. Any institution which nominally serves the public good faces a constant risk of devolving into self-servingness. This risk gets worse the more powerful and respected the institution becomes.
References
- #13: First-class string type in serialization specification (MessagePack issue tracker, June 2010 - August 2013)
- #121: Msgpack can't differentiate between raw binary data and text strings (MessagePack issue tracker, November 2012 - February 2013)
- draft-bormann-apparea-bpack-00: The binarypack JSON-like representation format (IETF Internet-Draft, October 2012)
- #129: MessagePack should be developed in an open process (MessagePack issue tracker, February 2013 - March 2013)
- Re: JSON mailing list and BoF (IETF apps-discuss mailing list message from Carsten Bormann, 18 February 2013)
- #128: Discussions on the upcoming MessagePack spec that adds the string type to the protocol (MessagePack issue tracker, February 2013 - August 2013)
- draft-bormann-apparea-bpack-01: The binarypack JSON-like representation format (IETF Internet-Draft, February 2013)
- draft-bormann-cbor: Concise Binary Object Representation (CBOR) (IETF Internet-Drafts, May 2013 - September 2013)
- RFC 7049: Concise Binary Object Representation (CBOR) (October 2013)
- "MessagePack should be replaced with [CBOR] everywhere ..." (floatboth on Hacker News, 8th April 2017)
- Discussion with very useful set of history links (camgunz on Hacker News, 9th April 2017)
- OAuth 2.0 and the Road to Hell (Eran Hammer, blog posting from 2012, via Wayback Machine)
- Re: [apps-discuss] [Json] msgpack/binarypack (Re: JSON mailing list and BoF) (IETF list message from Sadyuki Furuhashi, 4th March 2013)
"no apologies for complaining about this farce" (IETF list message from Phillip Hallam-Baker, 15th August 2013)
Edited 2020-07-14 18:55 to fix a minor formatting issue, and 2020-07-14 22:54 to fix two typos
master for the default git branch. Regardless of the etymology (which is unclear), some people say they have negative associations for this word, Changing this upstream in git is complicated on a technical level and, sadly, contested.
But git is flexible enough that I can make this change in my own repositories. Doing so is not even so difficult.
Announcement
I intend to rename master to trunk in all repositories owned by my personal hat. To avoid making things very complicated for myself I will just delete refs/heads/master when I make this change. So there may be a little disruption to downstreams.
I intend make this change everywhere eventually. But rather than front-loading the effort, I'm going to do this to repositories as I come across them anyway. That will allow me to update all the docs references, any automation, etc., at a point when I have those things in mind anyway. Also, doing it this way will allow me to focus my effort on the most active projects, and avoids me committing to a sudden large pile of fiddly clerical work. But: if you have an interest in any repository in particular that you want updated, please let me know so I can prioritise it.
Bikeshed
Why "trunk"? "Main" has been suggested elswewhere, and it is often a good replacement for "master" (for example, we can talk very sensibly about a disk's Main Boot Record, MBR). But "main" isn't quite right for the VCS case; for example a "main" branch ought to have better quality than is typical for the primary development branch.
Conversely, there is much precedent for "trunk". "Trunk" was used to refer to this concept by at least SVN, CVS, RCS and CSSC (and therefore probably SCCS) - at least in the documentation, although in some of these cases the command line API didn't have a name for it.
So "trunk" it is.
Aside: two other words - passlist, blocklist
People are (finally!) starting to replace "blacklist" and "whitelist". Seriously, why has it taken everyone this long?
I have been using "blocklist" and "passlist" for these concepts for some time. They are drop-in replacements. I have also heard "allowlist" and "denylist" suggested, but they are cumbersome and cacophonous.
Also "allow" and "deny" seem to more strongly imply an access control function than merely "pass" and "block", and the usefulness of passlists and blocklists extends well beyond access control: protocol compatibility and ABI filtering are a couple of other use cases.
I need an alternative to BountySource, who have done an evil thing. Please post recommendations in the comments.
From: Ian Jackson <*****> To: [email protected] Subject: Re: Update to our Terms of Service Date: Wed, 17 Jun 2020 16:26:46 +0100 Bountysource writes ("Update to our Terms of Service"): > You are receiving this email because we are updating the Bountysource Terms of > Service, effective 1st July 2020. > > What's changing? > We have added a Time-Out clause to the Bounties section of the agreement: > > 2.13 Bounty Time-Out. > If no Solution is accepted within two years after a Bounty is posted, then the > Bounty will be withdrawn and the amount posted for the Bounty will be retained > by Bountysource. For Bounties posted before June 30, 2018, the Backer may > redeploy their Bounty to a new Issue by contacting [email protected] > before July 1, 2020. If the Backer does not redeploy their Bounty by the > deadline, the Bounty will be withdrawn and the amount posted for the Bounty > will be retained by Bountysource. > > You can read the full Terms of Service here > > What do I need to do? > If you agree to the new terms, you don't have to do anything. > > If you have a bounty posted prior to June 30, 2018 that is not currently being > solved, email us at [email protected] to redeploy your bounty. Or, if > you do not agree with the new terms, please discontinue using Bountysource. I do not agree to this change to the Terms and Conditions. Accordingly, I will not post any more bounties on BountySource. I currently have one outstanding bounty of $200 on https://www.bountysource.com/issues/86138921-rfe-add-a-frontend-for-the-rust-programming-language That was posted in December 2019. It is not clear now whether that bounty will be claimed within your 2-year timeout period. Since I have not accepted the T&C change, please can you confirm that (i) My bounty will not be retained by BountySource even if no solution is accepted by December 2021. (ii) As a backer, you will permit me to vote on acceptance of that bounty should a solution be proposed before then. I suspect that you intend to rely on the term in the previous T&C giving you unlimited ability to modify the terms and conditions. Of course such a term is an unfair contract term, because if it were effective it would give you the power to do whatever you like. So it is not binding on me. I look forward to hearing from you by the 8th of July. If I do not hear from you I will take the matter up with my credit card company. Thank you for your attention. Ian.
They will try to say "oh it's all governed by US law" but of course section 75 of the Consumer Credit Act makes the card company jointly liable for Bountysource's breach of contract and a UK court will apply UK consumer protection law even to a contract which says it is to be governed by US law - because you can't contract out of consumer protection. So the card company are on the hook and I can use them as a lever.
Update - BountySource have changed their mind
From: Bountysource <[email protected]> To: ***** Subject: Re: Update to our Terms of Service Date: Wed, 17 Jun 2020 18:51:11 -0700 Hi Ian The new terms of service has with withdrawn.
This is not the end of the matter, I'm sure. They will want to get long-unclaimed bounties off their books (and having the cash sat forever at BountySource is not ideal for backers either). Hopefully they can engage in a dialogue and find a way that is fair, and that doesn't incentivise BountySource to sabotage bounty claims(!) I think that means that whatever it is, BountySource mustn't keep the money. There are established ways of dealing with similar problems (eg ancient charitable trusts; unclaimed bank accounts).
I remain wary. That BountySource is now owned by cryptocurrency company is not encouraging. That they would even try what they just did is a really bad sign.
Edited 2020-06-17 16:28 for a typo in Bountysource's email address
Update added 2020-06-18 11:40 for BountySource's change of mind.
I have made the 1.0 release of subdirmk.
subdirmk is a tool to help with writing build systems in make, without use of recursive make.
Peter Miller's 1997 essay Recursive Make Considered Harmful persuasively argues that it is better to arrange to have a single make invocation with the project's complete dependency tree, rather than the conventional $(MAKE) -C subdirectory approach.
This has become much more relevant with modern projects which tend to be large and have deep directory trees. Invoking make separately for each of these subdirectories can be very slow. Nowadays everyone needs to run a parallel build, but with the recursive make approach great discipline is needed to avoid introducing races which cause the build to sometimes fail.
There are various new systems which aim to replace make. My general impression of these is that they mostly threw away the good parts of make (often, they discard the flexibility, and the use of the shell command as the basic unit of execution, making them hard to extend), or make other unfortunate assumptions. And there are a lot of programming-language-specific systems - a very unsatisfactory development. Having said all that, I admit I haven't properly evaluated every make competitor. Other reasons for staying with make including that it is widely available, relatively widely understood, and has a model relatively free of high-level abstract concepts. (I like my languages with high-level concepts, but not my build systems.)
But, with make, I found that actually writing a project's build system in non-recursive make was not very ergonomic. So with some help and prompting from Mark Wooding, I have made a tool to help.
subdirmk is a makefile preprocessor and aggregator, typically run from autoconf. subdirmk provides convenience syntaxes for references to per-directory variables and pathnames. It also helps by providing a little syntactic sugar for GNU make's macro facilities, which are awkward to use in raw make.
subdirmk's features are triggered by the sigil &. The syntax is carefully designed to avoid getting in the way of makefile programming (and programming of shell commands in make rules).
subdirmk is fully documented in the README. There is a demo in the example directory (which also serves as part of the test suite).
What's new
The version number.
I have not felt the need to make any changes since releasing 0.4 in mid-February. The last non-docs change was a (backwards-compatible) extension, in late January, to pass through unaltered GNU make's new grouped multiple targets syntax.
Advantages and disadvantages of subdirmk
Compared to recursive make, subdirmk is easier and simpler, although you do have to decorate a lot of your variables and filenames with & to indicate that they are directory-local. It is much easier to avoid writing parallel make bugs. You naturally get properly working per-subdirectory targets. subdirmk-based nonrecursive make is much, much faster than recursive make.
Compared to many other recent build system tools, subdirmk retains all the flexibility and extensibility of make, and operates at a fairly low level of abstraction. subdirmk-based makefiles can easily invoke other build systems. make knows it's not the only thing in the universe. You can adopt subdirmk incrementally or partially, gradually bringing your recursive submakefiles into the unified build. The build system code in subdirmk's Dir.sd.mk files will be readily navigable by most readers; much will be familiar.
Because subdirmk is a small collection of (fairly simple) scripting and makefile code, there is no need to build it; you can simply ship it with your project using git-subtree. For an autoconf-based project, there need be no change to how your users and downstreams invoke your build.
On the other hand the price you (continue to) pay is make's punctation soup, which subdirmk adds a new sigil to. subdirmk-based makefiles are terse and help you use make's facilities to abstract away repetition, but that can make them dense. The new & sigil will faze some readers.
Currently, the provided mechanism for incorporating subdirmk into your project assumes you are using autoconf but not automake. It would be possible to use subdirmk with autoconf-less projects, or with automake-based ones, but I haven't done the glue work to make that easy.
subdirmk does require GNU make and it assumes you have perl installed. But GNU make is very portable, and perl is very widely available. (The perl used is very conservative.) The make competitors are, themselves, even less standard build tools. I don't think a build-dependency on GNU make, or perl, is a significant barrier nowadays, for most projects.
Note about comment moderation
I have deliberately been vague about other build systems and avoided specific criticisms or references. I don't want the comments to become a build system advocacy debate. Comments may be screened and moderated accordingly. Pointers to other obscure build system tools are very welcome. If you want to write a survey of build tools, or a critique of subdirmk, please do so on your own blog; I would be happy to consider linking to it.
People complained that my laptop sound was buzzy, so I bought a proper microphone (thanks to mdw for advice, and loan of some kit). Proper microphones come with a holder that accepts a screw from your microphone stand. In my case, 3/8" "BSW" - similar to 3/8" US standard "coarse" (or if you unscrew a supplied insert, a special 27tpi 5/8" UNS).
I don't have a microphone stand and I didn't want to buy one. I have two camera tripods - a small one and a big one. My camera tripods have 1/4" coarse (20tpi) UNC screws.
Also, we have a 3D printer at home. And nowadays you can download a configurable screw thread from the internet. So I made myself an adapter. After a few iterations I have a pretty good object which can be used to fit my new microphone to either camera tripod. (I found that a UNC thread was close enough to fit the microphone's BSW.)
Of coure, this is Open Hardware and the (short) source code is available. (To build it you'll want to git clone to get the included files.)
Pictures below the cut. The flange at the bottom is because tripods usually have a soft top which is supposed to stop scratching the camera; a narrow hexagonal base would make gouges, hence the wide base. ( Read more... )
These revocations will start "no earlier than" 00:00 UTC tonight (24:00 on the 3rd of March), a little over 9h from now. Affected websites etc. may stop working.
I discovered this at about lunchtime UK time today; two of my certs were affected. xenproject.org and linuxfoundation.org are listed as affected and I am trying to get in touch with the hosting provider to get it fixed. One of the domains we in the Xen Project run ourselves, with the help of the contractors who do much of our sysadmin, is affected - and those contractors (who are very competent) didn't know until I told them.
tl;dr: If you are responsible for any Let's Encrypt certificates, check it right away and maybe panic now!
edited 2020-03-03 15:35 to fix arithmetic error
We recently upgraded our home internet (AAISP) to FTTC which meant getting a new router (one of the Zyxel boxes which A&A supply), and the new router could do IPv6. Now the firewall has a public v6 interface and the guest wifi has v6 support. Both my laptop and my phone seem happy with the setup.
The appropriate trivial update to my vpn config means now secnet works to my house on v6 only, so I will be able to use the proper v6-only FOSDEM network :-). Hooray!
Thanks to my friends on irc for various helpful tips etc.
Things I discovered that were not obvious to me
I knew that to do IPv6 routing for the guest wifi, it's necessary to send out RAs. I didn't know that this is done by a daemon, radvd, which you have to install. You have to hand-write a radvd config file. You have to manually write an rdnss entry so that wifi guests using v6 have nameservers. What a palaver. At least the example config is OK. See the README.Debian.
bind9 silently ignores v6 addresses in "listen-on" stanzas (!) You have to use "listen-on-v6". IPv6 entries in "allow-recursion" do work.
Do not try to turn on ipv6 forwarding for only certain interfaces by echoing 1 into /proc/sys/net/ipv6/conf/$IFACE/forwarding (eg in /etc/network/interfaces). This doesn't work. Linux's v6 stuff is broken in this area: the ipv6 interface-specific forwarding config entries are decoys. You must echo 1 into /proc/sys/net/ipv6/conf/all/forwarding, or it won't work. The docs say if you're concerned about forwarding on other interfaces, you must use firewalling tools, so I think the per-interface entries are simply ignored?
On my system I want to honour my DSL router's RA's on my public interface. This is done with "accept_ra 2" in /etc/network/interfaces. Thanks to a helpful blog post for tipping me off about this.
It is OK to have wifi with v6 and slaac and rdnss, but no dhcpv6. That's nice and means I don't have to run a dhcpv6 server. The only operating systems which don't work with v6 this way are AIX, AS/400, and most versions of Windows (including Windows phones). Well, they can use v4.
Maybe it's obvious, but to configure the external v6 interface, adding an "iface ethx inet6 static" stanza to /e/n/i is correct. Setting "dad-attempts 0" will make it come up even if the firewall host wins the startup race with the router when booting from cold.
If your laptop is using network-manager, you can test all this by turning off v4 in the network entry for your home wifi.
I have released subdirmk 0.3.
Recap
Peter Miller's 1997 essay Recursive Make Considered Harmful persuasively argues that it is better to arrange to have a single make invocation with the project's complete dependency tree, rather than the currently conventional $(MAKE) -C subdirectory approach.
However, I have found that actually writing a project's build system in a non-recursive style is not very ergonomic. So with some help and prompting from Mark Wooding, I have made a tool to help.
What's new
I have overhauled and regularised some of the substitution syntaxes. The filenames have changed. And there is a new $-doubling macro help facility.
Status
It's still 0.x. I'm still open to comments about details of syntax and naming. Please make them here on this blog, or by posting to sgo-software-discuss.
But it's looking quite good I think and I intend to call it 1.0 RSN.
Further reading
edited 2019-12-30 16:39 Z to fix some formatting issues with Dreamwidth's HTML "sanitiser"
I was shown a link to a twitter post in which a DD
encourages using a curl pastebin | mutt
rune to vote. The rune looked like it had been debugged,
so the poster put at least a little work into developing it.
I think this is rather poor. I think you should make up your own mind. That is why I have written three blog posts to encourage you to help with drafting alternatives during the discussion started by the DPL, understand the options on the ballot, and most conveniently deal with devotee's ballot format.
But of course maybe providing such a pre-cooked rune will enable people to vote who are otherwise too busy. It's certainly important that we get good turnout. If you are too busy, and you trust my judgement, then you could run:
mutt -H <(curl https://people.debian.org/~iwj/thoughtless-vote.txt )
or
curl https://people.debian.org/~iwj/thoughtless-ballot.txt | gpg --clearsign | mail [email protected]
Since you can change your vote up to the deadline of 23:59:59 UTC on Friday 2019-12-27, you could run a rune like that now and then change your vote later if you get time to think about it properly.
Obviously it would be best for you to read something like my voting guide and make up your own mind. But maybe it would be better to run my rune than not vote at all? Up to you I guess.
This can get a bit confusing. The ballot options have letters (eg, "E"). They also have numbers, which show up on the vote page as "Choice 6" or whatever. Separately, there are the ranks you have to assign when voting, where 1 is your first preference, etc.
On the ballot paper, the choices are numbered from 1 to 8. The letters appear too along with the Secretary's summaries. Your preferences also have to be numbered. It is important not to get confused.
Reorder the ballot paper!
You are allowed to reorder the choices on your ballot paper, and this is effective.
That is, you can take the ballot paper in the CFV and edit the lines in it into your preferred order with cut and paste. You can look at the letters, or the Secretary's summary lines, when you do that.
It's important to use a proper text editor and not linewrap things while you do this.
After, that you can simply write numbers 1 to 8 into the boxes down the left hand side.
Rank all the options. That way when you get your vote ack back, any parse failure will show up as a blank space in the ack.
Worked example
If after reading my voting guide you answer "maintainers MUST support non-systemd" to Q1, and "Accepting contributions is more important" to Q2, and "I like the vision" to Q3, you fall into the top left corner of my voting table. Then you would vote like this:
> - - -=-=-=-=-=- Don't Delete Anything Between These Lines =-=-=-=-=-=-=-=- > 7b77e0f2-4ff9-4adb-85e4-af249191f27a > [ 1 ] Choice 6: E: Support for multiple init systems is Required > [ 2 ] Choice 5: H: Support portability, without blocking progress > [ 3 ] Choice 4: D: Support non-systemd systems, without blocking progress > [ 4 ] Choice 7: G: Support portability and multiple implementations > [ 5 ] Choice 3: A: Support for multiple init systems is Important > [ 6 ] Choice 8: Further Discussion > [ 7 ] Choice 2: B: Systemd but we support exploring alternatives > [ 8 ] Choice 1: F: Focus on systemd > - - -=-=-=-=-=- Don't Delete Anything Between These Lines =-=-=-=-=-=-=-=-
When you get your ack back from the vote system, it lists, from left to right, the preferences numbers for each vote.
In the case above, that's
Your vote has been recorded as follows -=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-= V: 87532146 -=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
Understanding the devotee ack
The V: list in the ack is listed in the order of the "Choice" numbers on the ballot, not in your preference order:
Your vote has been recorded as follows
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
V: 87532146
[ 6 ] ||||||| `-- Choice 8: Further Discussion
[ 4 ] |||||| `--- Choice 7: G: Support portability
[ 1 ] ||||| `---- Choice 6: E: Support for multipl
[ 2 ] |||| `----- Choice 5: H: Support portability
[ 3 ] ||| `------ Choice 4: D: Support non-systemd
[ 5 ] || `------- Choice 3: A: Support for multipl
[ 7 ] | `-------- Choice 2: B: Systemd but we supp
[ 8 ] `--------- Choice 1: F: Focus on systemd’
Edited 2019-12-11 15:35 to add the "Understanding the devotee ack" section. Thanks to my correspondent for the confusion-report and review.
Introduction
If you don't know what's going on, you may wish to read my summary and briefing blog post from a few weeks ago. There are 7 options on the ballot, plus Further Discussion (FD). With this posting I'm trying to help voting Debian Members (Debian Developers) cast their votes.
I am going to be neutral about the technical merits of systemd. My advice does not depend on your opinion about that.
So my advice here is addressed to people who like systemd and want to keep running it, and developing with it, as well as, of course, people who prefer not to use systemd. I'm even addressing readers who think systemd has useful features which they would like Debian packages to be able to use.
However, I am going to be opinionated about one key question: My baseline is that Debian must welcome code contributions to support running without systemd, just as it welcomes code contributions for other non-default setups. If you agree with that principle, then this posting is for you. Unfortunately this principle is controversial. Several of the options on the current GR mean rejecting contributions of non-systemd support. So in that sense I am not neutral.
tl;dr
(Using # to indicate the "Choice" numbers on the ballot.)
Rank H (#5), D (#4) and E (#6) ahead of all other options unless you can't accept the "portability" principles in H (#5), or can't accept the MUST in E (#6). For more on D vs E vs H, see below.
Do not be fooled by A (#3) which sounds like it actually answers the question, with a compromise. But making these bugs "important" does not have any practical effect. It just sets us up for more arguments. A also enables continuation of blocking behaviours by maintainers who want to support only systemd - probably more than G (#7) does. Both A and G are poor in their practical effect, but I would rank G ahead of A, unless you really disagree with the Principles in G.
Summary of the options
Ordered from strongest support for contributors of non-systemd support, and users who don't want to use systemd, to weakest. H (#5) is the Principles part of G (#7) pasted onto the front of the specific decisions in D (#4) - the similar-looking texts are identical.
#6 E Dmitry Packages MUST work on non-systemd systems
#5 H Ian Portability and multiple implementations, "without blocking progress"
#4 D Ian Compromise, "Support non-systemd systems, without blocking progress"
#7 G Guillem Portability and multiple implementations, avoids giving any guidance on specifics.
Options below here will mean that systemd becomes effectively mandatory for most users and developers
#3 A Sam Vaguely positive words, but maintainers can (and some will) block non-systemd support. Fudge, not compromise. Sets us up for more arguments. #2 B Sam Encourages adoption of systemd features
#1 F Michael Support only systemd, encourages tighter systemd integration
Voting flowchart
You should probably vote H (#5), D (#4) and E (#6) ahead of all the other options, in some order or other For more details, and the exceptions, read on.
Q1 - Non-systemd support mandatory ?
Do you think support for non-systemd systems should be mandatory - ie that maintainers of leaf packages should be required to write init scripts, etc ?
Yes,
maintainers should do the work to support non-systemd
init systems.
Rank: E > H+D. (# 6 > 5+4.
)
No,
the non-systemd commmunity should do this work.
Rank: H+D > E. (# 5+4 > 6.
)
How far down you put E depends how strongly
you feel about this. I have assumed in the rest
of this posting that you think the principle
that the non-systemd community should be allowed
to do this work is more important than the principle
that other people shouldn't be required
to do it. If you don't agree, you should rank
E (#6) lower than the suggestions I make in the rest of this post.
Q2 - Discussion closure
How much do you care that we settle this matter once and for all? (compared to valuing accepting contributions, and thereby enabling variety in software, flexibility, portability, Debian's centrality, and so on)
Accepting contributions is more important. I expect the non-systemd community to keep using, supporting (and working on) non-systemd regardless, even if Debian makes it difficult, and in a downstream if necessary. Rank: H+D+E > G > A > FD > B > F. (# 5+4+6 > 7 > 3 > 8 > 2 > 1. )
I want closure somewhat. If we have support in principle, I am prepared to have to revisit some of the details in another GR and/or escalate individual bugs to the Technical Committee (TC). Otherwise we should just make systemd mandatory and be done with it. Rank: H+D+E > G > A > F > B > FD. (# 5+4+6 > 7 > 3 > 1 > 2 > 8. )
I want closure very much. I want this settled once and for all. (But I would rather have one more GR than a bunch of TC fights over individual bugs.) Rank: H+D+E > F > FD > B > G > A. (# 5+4+6 > 1 > 8 > 2 > 7 > 3. )
NB the Rank listings here here are subject to Q3, regarding G (#7), and Q1, regarding E (#6).
You may be surprised that I suggest ranking G (#7) ahead of A (#3) even if you very much want closure, despite G's lack of any detailed guidance. This is because I think both A and G would lead to many arguments about details, but G provides clearer principles for resolving those arguments - so there would be fewer of them and they will be less bad. A also leaves much more open the possibility of a renewed attempt to desupport non-systemd systems via another GR. You may very well disagree with me on this, in which case you will want to rank A ahead of G; however I would still advise against ranking A highly.
Q3 - "Glue", portability and multiple implementations
Do you agree with the Principles at the top of proposals G (#7) and H (#5) ? Do you see the init systems debate as part of a pattern and think this is something the project needs to make a more general statement about ?
I like this vision for Debian as the
universal operating system.
Rank: H > D. (# 5 > 4.
)
I have concerns about making such
a strong general statement, or
this is a distraction
which unnecessarily broadens the debate;
but I can live with it if the practical results are right
for init systems.
Rank: D > H. (# 4 > 5.
)
Probably keep G (#7) ahead of A (#3).
If you want the arguments to be over, both are poor.
I disagree with this vision
and do not want it as part of the winning option.
Rank: D > H. (# 4 > 5.
)
You may wish to demote H (#5) and G (#7)
below other options, perhaps even below FD or A (#3).
I would caution against demoting H (#5),
too far, because several of those other
options answer the specific init systems question badly or
not at all. Consider whether you can live with
this rather woolly vision text if it means the
init systems arguments are
ended satisfactorily.
Voting table
Q1: Maintainers must support non-systemd Q1: Non-systemd community should do the work "portability" vision I like it I have concerns I like it I have concerns
Q2: Must accept contribs
E H D G A FD B F
Choice 6 5 4 7 3 8 2 1
Ballot 8 7 5 3 2 1 4 6
E D H* G* A FD B F
Choice 6 4 5* 7* 3 8 2 1
Ballot 8 7 5 2 3 1 4 6
H D E G A FD B F
Choice 5 4 6 7 3 8 2 1
Ballot 8 7 5 2 1 3 4 6
D H* E G* A FD B F
Choice 4 5* 6 7* 3 8 2 1
Ballot 8 7 5 1 2 3 4 6
Q2: Want closure somewhat
E H D G A F B FD
Choice 6 5 4 7 3 1 2 8
Ballot 6 7 5 3 2 1 4 8
E D H* G* A F B FD
Choice 6 4 5* 7* 3 1 2 8
Ballot 6 7 5 2 3 1 4 8
H D E G A F B FD
Choice 5 4 6 7 3 1 2 8
Ballot 6 7 5 2 1 3 4 8
D H* E G* A F B FD
Choice 4 5* 6 7* 3 1 2 8
Ballot 6 7 5 1 2 3 4 8
Q2: Want closure very much
E H D F FD B G A
Choice 6 5 4 1 8 2 7 3
Ballot 4 6 8 3 2 1 7 5
E D H* F FD B G A
Choice 6 4 5* 1 8 2 7 3
Ballot 4 6 8 2 3 1 7 5
H D E F FD B G A
Choice 5 4 6 1 8 2 7 3
Ballot 4 6 8 2 1 3 7 5
D H* E F FD B G A
Choice 4 5* 6 1 8 2 7 3
Ballot 4 6 8 1 2 3 7 5
* If you really dislike the Principles in G (#7), you may wish to rank it, and maybe H (#5), lower. See also my comments in Q1 about the MUST in E (#6).
In the table Choice is the Choice numbers from the vote page in the same order as the letters, ie in descending order of preference. Ballot is the preference numbers to fill in on the ballot, in the order on the ballot paper. This is confusing because of the ballot paper's reuse of numbers to mean both choices and preferences. I suggest instead that you reorder the ballot paper, as I suggest in my other blog post about ballot paper format.
Edited 2019-12-09 17:38 UTC to add Ballot number listings, discussion of ballot ordering, and link to followup post. And again at 17:40 to fix the link.
Detailed analysis of the options
I have dealt with this by theme, rather than going through the options one by one.
Overall framing and vision
E (#6) Supporting non-systemd init systems is simply and clearly required. No wider philosophical points.
H (#5) Strong general principles about Debian's central "glue" role, combined with detailed rules of engagement for stopping dysfunctional blocking behaviours. (Operative text is from D; principles are from G.)
D (#4) Contributions of work, both to support non-systemd systems, and systemd, should be welcomed, but init system communites must do their own work. Detailed rules of engagement for stopping dysfunctional blocking behaviours.
G (#7) Strong general principles about Debian's central "glue" role, support for portability, and so on. Deliberately avoids giving specific guidance; instead has some extremely vague words about being respectful.
A,B (#3,2) Hard to discern a clear vision.
F (#1) Claims that systemd is for "cross-distro collaboration". What this means is mainly collaboration on desktop operating systems with RPM-based distros, notably Red Hat. But it will actually hinder or prevent collaboration with (for example) GNU Guix, embedded operating systems, non-Linux operating systems such as FreeBSD, and even other distros like Gentoo or our own downstreams like Devuan. So the sense of "cross-distro collaboration" meant here is much narrower than it seems.
Clarity, vision and consequences
E (#6) Admirably clear and straightforward. Non-systemd systems will be properly supported; some strong systemd supporters may go to work elsewhere. No wider implications.
H (#5) Addresses specific situations relating to init systems in detail. If it is followed, the atmosphere should improve. Additionally, I find the clarity of vision attractive. Adopting it may preempt or help settle other disputes.
D (#4) Addresses specific situations in detail (and thus rather long). If it is followed, the atmosphere should improve and we can get on with programming.
G (#7) Clear statement of principles, undermined by an explicit refusal to give specific guidance; instead there is some extremely vague text about being respectful and compromising. In practice if this wins we are likely to continue to have a lot of individual fights over details. Despite the strong words in favour of portability etc., some maintainers are still likely to engage in blocking behaviours which will have to be referred to the TC.
Another GR is a possibility. At least, G winning now would make it look unlikely that that 2nd GR would completely de-support non-systemd, so that 2nd GR will hopefully be on a narrower question and less fraught: it will have to give the answers to details that G lacks.
A (#3) Looks like it supports working with different init systems. It also looks like it gives specific answers. It declares that systemd-only is an "important" bug, and discusses NMUs. But NMUs are only permitted "according to the NMU guidelines" - which means that maintainers can block them simply by saying they don't like the patch. The only escalation route for an "important" bug where the maintainer does not want to take the patch is the TC. TC disputes are generally very unpleasant, especially if (as in this case) the decision involves a conflict between the interests of different communities, and the underlying principles are in dispute.
Unlike G (#7), there is no statement of broader principles that would discourage a maintainer from blocking in this way (and would narrow a TC debate by de-legitimising the kinds of very weak arguments often presented to justify these blocking behaviours). The result will be a continuation of the existing situation where some maintainers are deleting init scripts and/or rejecting patches to support non-systemd. So there will be further fights over details, probably more even than with G (#7).
I would expect another GR at some point; that 2nd GR would probably involve a renewed attempt to de-support non-systemd systems. So I think this provides even less of a clear decision than G.
B,F (#2,1) In the short term, Debian contributors and users who don't like systemd may switch to Devuan instead (or simply shrug their shoulders and reduce their engagement). In the medium to longer term, Debian's narrowing of focus will make it less attractive for its current variety of interesting use cases. Debian's unwillingness to let people within Debian forge their own path will make it less fun.
Are init scripts required and who must write them?
Actually, init scripts are really just an example. All of the proposals treat other kinds of leaf package support for non-systemd init systems in a roughly similar way.
E (#6) init scripts are mandatory. Maintainers must write them.
H,D (#5,4) Maintainers do not have to write them, but they must accept them if they are provided (and they must not simply delete them from existing packages, as some have been doing). Ie, the non-systemd community must write them if it wants them where they are currently missing.
G (#7) No guidance. We might hope that the strong words on portabilility and multiple implementations will cause constructive behaviours by the various contributors, but in practice escalation of some kind, or a further GR, will be needed.
A,B,F (#3,2,1) Maintainers do not have to write them and do not need to accept them.
What about systemd sysusers.d, timer units, etc.
Consider for example, sysusers.d: this is a facility for creating needed system users - an alternative to our current approach of debhelper script fragments containing adduser calls. Or consider timer units, which overlap with cron. These do not necessarily imply actually running systemd; other implementations would be possible. Some people think some of these facilities are better and are unhappy that progress in Debian (particularly in Policy) has been blocked in this area.
Note that although this has been regarded by some people as being blocked by systemd sceptics, in fact it's mostly that the proponents of these facilities have not wanted to write a 2nd implementation for non-systemd systems.
E (#6) Such facilities may only be used if there is an implementation for non-systemd systems. Effectively, this means proponents of such a facility must do the reimplementation work. But if they do, adoption of these facilities is unblocked.
H,D (#5,4) There is a list of criteria for whether such a facility may be adopted, including feasibility of implementation for non-systemd (and non-Linux) systems, and whether the facility is any good. If a facility is approved then the non-systemd community get time (probably in practice 6 months) to reimplement the facility for their init system(s). In case of dispute the TC is to adjudicate the listed criteria.
G (#7) No specific guidance. Formal adoption of these facilities in Policy is likely to remain blocked but uncontrolled adoption in individual packages is a real possibility.
A,B,F (#3,2,1) Package maintainers are free to adopt these facilities in an uncoordinated way, making their packages work only with systemd. Presumably systemd Depends or Recommends would follow.
Dependencies which force (or switch) the init system
Some packages which would work fine without systemd cannot be installed, because the dependencies are overly strict. (This because of difficulties expressing the true situation in our dependency system, and what I see as largely theoretical concerns that systemd systems might come to miss parts of the systemd infrastructure.)
E,H,D (#6,5,4) Dependencies on systemd are forbidden (E) or dependencies are not allowed to try to switch the init system (H,D). Effectively, this means that this situation is forbidden.
G (#7) No specific guidance. This will lead to further arguments, unfortunately, since this situation is contrary to the Principles in the resolution but not clearly discussed.
A,B,F (#3,2,1) These dependencies are to be tolerated. Core package maintainers can maintain strict dependencies even if they make running without systemd difficult or impossible.
Acknowledgements
Thanks to everyone who helped review this posting. Thanks also to the Debian Members who proposed and seconded of the options on the ballot. Everyone who helped draft, or seconded, any one of these options has helped make sure that we have a good slate of choices.
I would like particularly to thank: Russ Allbery for his review comments on my option D which substantially improved it, and his encouragement (all remaining deficiencies are of course mine); Sean Whitton and Matthew Vernon whose support and friendship have been invaluable; Guillem Jover for having an excellent vision and then being very constructive and tolerant about the way I appropriated his language; Dmitry Bogatov for providing a very clear and simple proposal and engaging with the process well; and I even want to thank Michael Biebl for drafting an option which (although I strongly disagree with it, and with its framing) clearly represents the views of the pro-systemd-integration community. And I would like to thank my friends and partners for their support, without which I could not have coped.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK