

达观数据:计算广告系统算法与架构综述
source link: https://zhuanlan.zhihu.com/p/60544294
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


前言
我们当今身处一个被广告包围的时代,无论是走在马路上、收看电视剧、或者是玩手机游戏,都能看见形形色色的广告。随着时代和技术的发展,广告的形式呈现出多样化、立体化的趋势,从最早的纸媒广告发展到如今的网页的展示、搜索广告,广告的定位也从原先的“广而告之”发展成大数据时代的“精准营销”,相应地,人们对广告的态度也在悄然变化。这一切都得益于互联网技术的快速发展以及用户数据的爆炸式增长。作为IT从业者,自然想对广告产业背后的产品、技术一探究竟,正如刘鹏博士在其《计算广告》一书中所说的“不论你在做一款用户产品还是商业产品,不深入了解在线 广告,就不太可能全面地了解互联网业务”,因此本文也希望能带领读者从产品、技术以及整个生态的角度深入浅出的了解计算广告。
核心术语
首先,在深入了解计算广告之前, 有必要先对一些核心术语做简单的介绍。
- 广告主:有广告需求的客户公司,也称为需求方
- 媒体:可以是网站或者app,即有多余的广告位可以出售,也称为供给方
- RTB(Real Time Bidding,实时竞价):综合利用算法、大数据技术在网站或移动应用上对在线的流量实时评估价值,然后出价的竞价技术
- DSP(需求方平台):为各广告主或者代理商提供实时竞价投放平台,可以在该平台上管理广告活动及其投放策略,并且通过技术和算法优化投放效果,从中获得收益
- SSP(供应方平台):为各媒体提供一致、集成的广告位库存管理环境
- DMP(数据管理平台):整合各方数据并提供数据分析,数据管理、数据调用等,用来指导广告主进行广告优化和投放决策
- Ad Exchange,简称Adx(广告交易平台):同时接入了大量的DSP和SSP,给双方提供一个“交易场所”,将SSP方的广告展示需求以拍卖的方式卖给DSP方。可以类比于股票交易中的证券大厅角色
- CTR(点击率):广告点击与广告展现的比例,这是广告主、各大DSP厂商都非常重视的一个数字,从技术角度看,这一数字可以影响到广告的排序、出价等环节,从业务来看,这是运营人员的考核指标之一
- CVR(转化率):转化(主要由广告主定义,可以是一次下单或是一次下载app等)次数与到达次数的比例
- eCPM(千次展示期望收入):点击率 * 点击价值,这个数字在计算广告中是核心指标,涉及到对召回广告的排序策略,以及最终出价策略
- CPM(Cost per mille):每千次展现收费,最常见的广告模式,即不考虑点击次数、转化次数,只要广告在网站上被展现给一千个人看到就收费,是大型网站变现的最有效的方式。对广告主来说,适合于注重推广品牌的广告,力求最快最广的触及大众
- CPC(Cost per click):每次点击收费,无论广告被展现了多少次,只要没有产生点击就不收费。对于广告主来说选择 CPC 模式可以有助于提升点击量、发现潜在用户,进而可以真正做到精准营销;对于广大DSP厂商来说,这种收费模式也是获取利润的最有效来源之一
- CPA(Cost per action):每次动作收费,此处的动作一般定义为转化,可以是注册、咨询、交易、下载、留言等等,按照转化的数量来收费。对于广告主来说,这是性价比较高的一种收费方式,但是对于DPS和媒体方来说,想要把这种收费做好,却是有相当的难度。因此,目前也只有大厂或者技术实力深厚的DSP厂商才有能力接这种单子
- 其他的还有CPT(按展现时间收费)、CPL(按潜在线索收费)、CPS(按成功销售收费)等模式,由于应用没有那么广泛,在此不一一介绍了
竞价流程
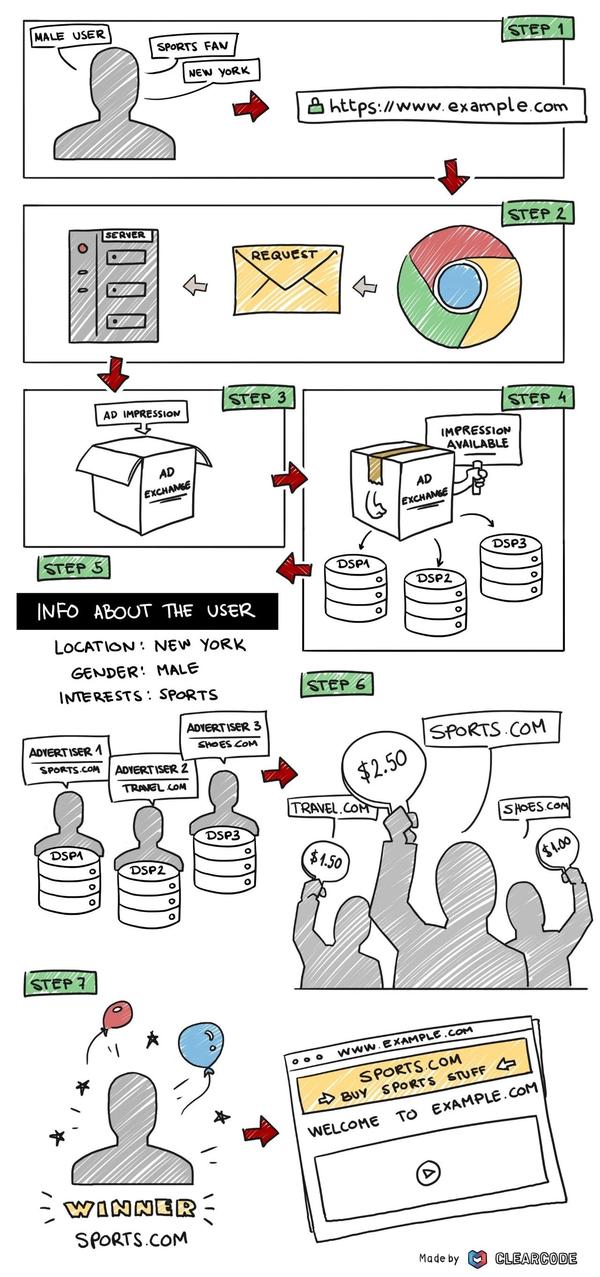
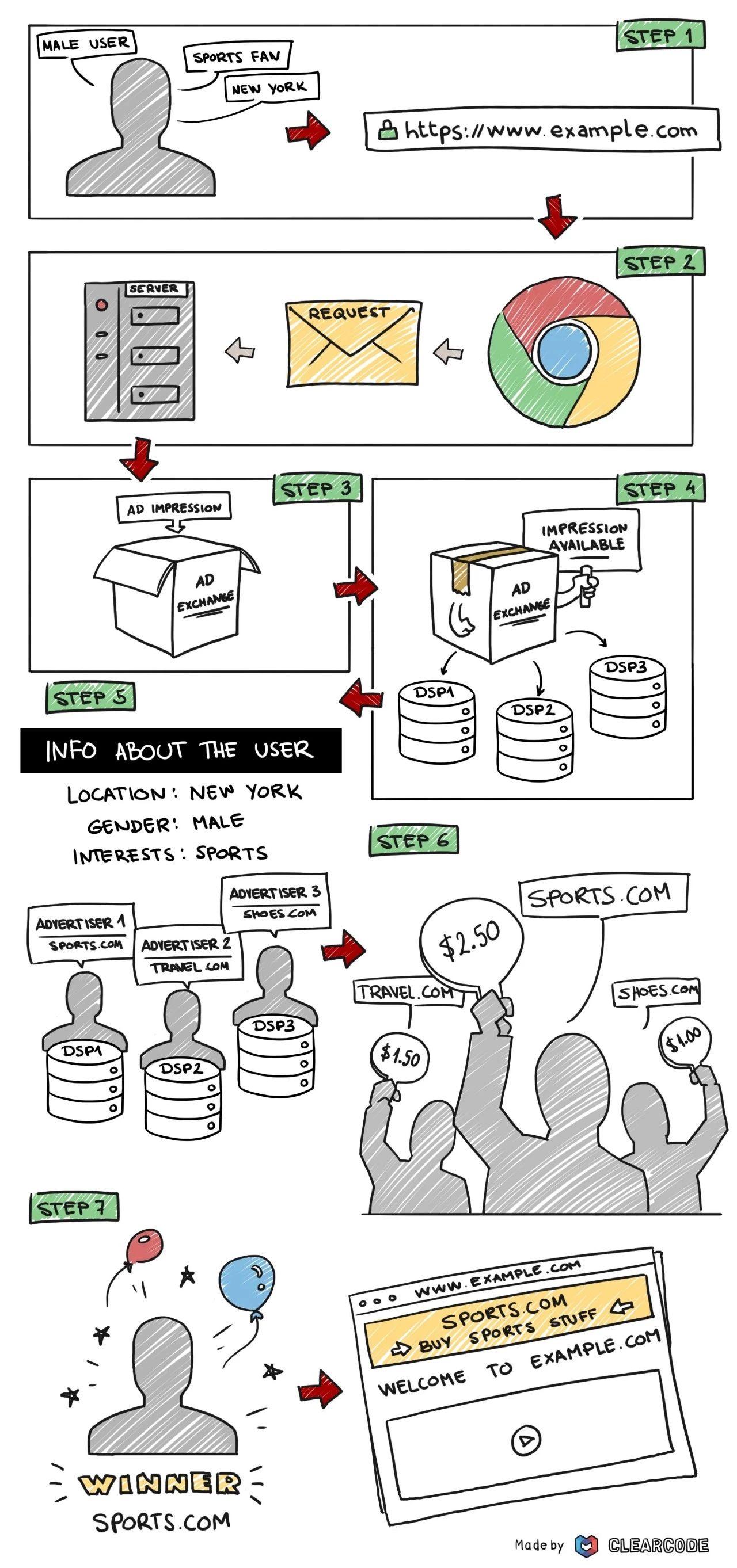
在RTB模式出现之后,我们发现展现的广告越来越精准了,好像网站知道用户是谁、用户在做什么、用户对什么感兴趣,因此,在了解了上述这些核心术语之后,接下来就以网站用户角度,从流程上解析RTB是如何做到精准展示广告的。
- 用户通过浏览器访问网站
- 浏览器发送广告请求给网站服务器,即SSP方
- SSP将广告展示需求发送给Adx
- Adx组织一次竞价,将本次的竞价请求通知给所有DSP方,并传输用户ID、用户IP以及广告位信息等等
- 各家DSP监听服务收到Adx发来的竞价请求后,根据发送来的当前用户的信息、上下文信息、代理的广告主信息对照投放需求,评估该请求
- 各家DSP将根据评估结果决定是否参与出价,若参与,则将出价结果通知Adx
- Adx收到所有出价响应后根据出价排序,通知出价最高的DSP胜出,同时将胜者的竞价信息告知SSP
- 胜者DSP会收到Adx发送的竞价消息(WinNotice),表示该次展现已经竞价成功。DSP此时将广告物料传送至浏览器展示。至此,一次完整的竞价流程就完成了
有两点需要说明:
- 以上流程需在100毫秒之内完成,也就是一眨眼的功夫都不到,这样才能让访问网站的用户马上看到广告。
- 虽然竞价最后的胜者是出价最高的DSP,但其实际支付的价格是出价第二高的报价再加上一个最小值,这就是著名的广义二阶拍卖(GSP)。这种定价模式的好处主要是为了避免各家DSP在多次竞价中,下一次的出价只需比上一次的胜出价格高一点点即可,从而导致出价越来越低。在GSP模式下,每个胜者只需要支付次高出价的金额,这样各家DSP也就没有动力相互压价。GSP是一种稳定的竞价方式,可操作性很强,现阶段几乎所有的互联网广告平台都使用这一种竞价方式。
技术细节
纵观计算广告的发展会发现,整个市场本质上是计算驱动的,而计算背后最大的推动力正是互联网以及大数据,而大数据的发展动力又来自于硬件和软件。因此接下来,就来剖析下技术细节。
1.架构
一个典型的广告系统架构如下图:
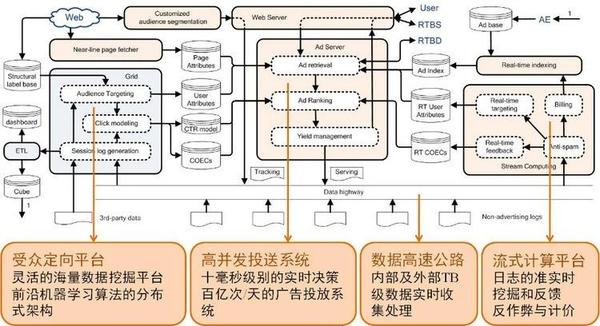
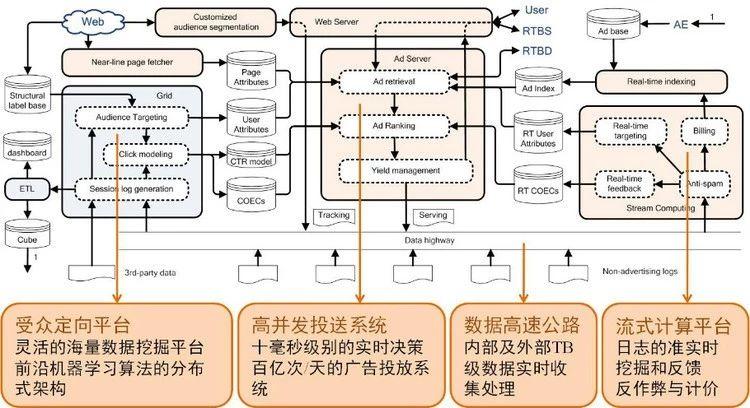
结合上图,广告系统有以下几个重要组成部分:
(1)受众定向平台:这部分一般为离线挖掘,是系统中最具算法挑战的部分,利用数据挖掘、机器学习等技术进行受众定向,点击率预估等工作。具体还可以细分为以下几个模块:
- 会话日志生成(Session loggeneration):从各个数据平台收集日志,并最终根据用户ID为主键汇集成一份统一存储格式的日志,从而为后续的数据分析、算法研发提供数据来源。
- 行为定向(Audience targeting):从会话日志中根据用户的行为,利用数据挖掘、机器学习等算法建模,从而可以刻画出用户的行为模式、兴趣点等,最终为用户打上结构化标签,以供广告定向投放使用。该模块在整个系统具有非常关键的作用。
- 点击率建模(Click modeling):利用大数据工具以及算法,从会话日志中提取预定义的特征,训练一个点击率模型,加载到缓存中以供线上投放系统决策时使用。
- 商业智能模块(BusinessIntelligence):包括ETL(Extract-Transform-Load)过程、Dashboard、cube。BI系统可以为决策者提供直观且即时的数据分析,而算法对决策者来说相当于黑盒,因此,设计一个良好的BI系统可以为决策提供有力的帮助。另外,在广告投放中,除了技术之外,运营是非常重要的角色。所以,这一模块也影响到了广告运营的策略运行以及调整。
(2)高并发的投送系统:也就是在线的广告投放机(Ad server),主要任务是与各模块交互,将它们串联起来完成在线广告的投放决策。特点是高并发,要做到10ms级别的实时决策,百亿次/天的广告投放系统。具体可细分为以下几个模块:
- 广告检索(Ad retrieval):也称为广告召回,即根据用户属性以及页面上下文属性从广告索引(Ad index)中查找符合条件的广告候选。
- 广告排序(Ad ranking):主要功能是对广告检索模块送来的广告候选集计算eCPM,并按照值的大小倒排。eCPM的计算依赖于受众定向平台离线计算好的点击率。由于最终投放出的广告都是来自于排序的结果,因此这一模块也是至关重要,成为各种算法模型和策略大展身手的地方。
- 收益管理(Yield management):将局部广告排序的结果进一步优化,以做到全局最优收益。
(3)数据高速公路:联系在线与离线的部分,可以用开源工具实现。作用是准实时地将日志推送到其它平台上,目的一是快速地反馈到线上系统中,二是给BI人员快速看结果。它还可能收集其它平台的日志,比如搜索广告会收集搜索日志。
(4)流式计算平台:主要功能是对在线数据的处理,做到准实时的挖掘和反馈,解决那些离线计算平台无法快速响应的计算问题。具体又可分为:
- 实时受众定向(Real-timetargeting)和实时点击反馈(Real-time click feedback):对用户的实时行为进行计算,如实时更新点击率模型、动态调整用户标签,进而更好的适应线上环境。实践表明,实时系统的作用对于最终效果提升明显大于离线系统,举个简单例子,当实时点击反馈模块发现当前用户的行为与其历史点击行为有较大差异时,可以反馈给其他模块并通知进行及时的更新,从而可以更好的满足用户变化的需求,最终提升效果。
- 计费(Billing):该模块掌管着广告系统的“钱袋子”,运行的准确性和稳定性直接影响了系统的收益。在广告投放过程中,经常会遇到投放预算用完的情况,这时计费模块必须及时反应,采取例如通知索引系统暂时将广告下线的办法,避免带来损失。
- 反作弊(Anti-spam):利用算法和人工规则等实时判断流量来源中是否有作弊流量,并将这部分流量从后续的计价和统计中去掉,是广告业务非常重要的部分。
2. 硬件
在以上介绍的架构图中,都离不开大数据工具的作用,其中大多来自开源社区,正所谓,工欲善其事,必先利其器。可以说,正是由于这些成熟的开源工具有力的保障了数据通信、数据传输、负载分配等底层架构的健康运行,才使得上层的广告算法和策略能快速发展。
(1)Hadoop:一个由Apache基金会所开发的分布式系统基础架构,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序,主要优点有:高可靠性、高扩展性、高容错、低成本。Hadoop框架最核心的设计就是:HDFS和MapReduce。
- HDFS是一种易于横向扩展的分布式文件系统,是分布式计算中数据存储管理的基础,适合应用于流数据模式访问和处理超大文件的需求,不适合于要求低时间延迟数据访问的应用、存储大量的小文件、多用户写入。广告系统中用户生成的海量日志就是存在HDFS上,为各种离线计算提供服务。
- MapReduce 是用于并行处理大数据集的软件框架。MapReduce的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。在Spark出现之前,MapReduce是在大规模数据上计算点击率预估、挖掘用户行为、生成用户画像等的首选计算框架。
(2)Spark:一个用来实现快速而通用的集群计算的平台,扩展了广泛使用的MapReduce计算模型,Spark的一个重要特点就是能够在内存中计算,因而更快,即使在磁盘上进行的复杂计算,Spark依然比MapReduce更加高效。举例来说,机器学习中很多算法都要迭代训练多次才能达到收敛,例如聚类算法K-Means,每次迭代需要将K个中心点的位置保存下来,以进行下次的更新,传统的MapReduce计算框架在Map阶段和Reduce阶段用硬盘进行数据交换,这就使得整个训练过程效率很低,而Spark的做法则是将数据加载到内存中,直接在内存中更新K个中心点的位置,大大加快了训练过程。Spark支持各种机器学习算法为代表的迭代型计算、流式实时计算、社交网络中常用的图计算、交互式即席查询等。
(3)Lucene:用于全文检索和搜索的开源程式库,提供了一个简单却强大的应用程式接口,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构。目前大多数的计算广告采用的是检索加排序模式,为了加快检索的时间,可以对所有广告的关键字建立倒排索引(主键为关键字,值为文档ID),这样在广告召回时,便能快速地从规模巨大的广告库中返回结果。
(4)Storm:广告系统中除了需要离线挖掘数据,同样还需要在线、准实时的处理数据,例如反作弊处理、实时点击反馈、实时查看某地区当前的广告投放情况等,业界常用的工具是Storm。利用Storm可以很容易做到可靠地处理无限的数据流,像Hadoop批量处理大数据一样,主要的特点有:
- 高性能:应用于需要对广告主的操作进行实时响应的场景.
- 可扩展: 随着业务发展,数据量和计算量越来越大,系统可水平扩展.
- 消息不丢失:能够保证每个消息都能得到处理.
- 编程容易:任务逻辑与MapReduce类似,熟悉MapReduce框架的开发人员可以快速上手
(5)ZooKeeper:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件,为分布式应用提供一致性服务。分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、配置维护等功能。简单来说ZooKeeper=文件系统+监听通知机制。在广告系统中,大量的广告投放机就是通过ZooKeeper进行管理,可以把所有机器的配置全部放到ZooKeeper上的某个目录节点中,所有相关应用程序对这个目录节点进行监听。当需要增加一台新的投放机时,配置信息发生了变化,应用程序就会收到 ZooKeeper 的通知,然后从 ZooKeeper 获取新的配置信息应用到系统中。
3.核心算法
介绍完了上述的硬件架构之后,接下来就要了解一下计算广告背后的核心算法和技术。
CTR(点击率)预估是所有广告系统、推荐系统中非常重要的一个指标,可以反映出一个系统是否做的精准,是各个广告系统的“必争之地“。点击率预估的目的是为了广告排序,排序的依据是eCPM,即点击率*点击单价,然后再根据其他策略进行后续处理。
目前业界的点击率预估方法,是利用系统中已有的大量用户行为日志、根据规则抽取特征、离线训练机器学习模型、将模型上线后对每一个请求计算其点击广告的概率值,值的范围为 。这里既然用到了模型,就不得不提其背后的两个细节。
(1)特征
在实际的广告系统中,其实有非常多的因素会决定广告的点击率,这些因素在模型中即称为特征,主要分为三大类:
- 广告主侧(Advertiser):比如广告创意、广告的表现形式、广告主行业等。
- 用户侧(User):如人群属性、年龄、性别、地域、手机型号、WiFi环境、兴趣等等。
- 上下文侧(Context):比如不同的广告位、投放时间、流量分配机制、频次控制策略等。
在有了用户日志后,就需要根据上述三类特征进行特征工程。特征工程对于机器学习来说非常重要,可以使特征更好地在算法上发挥作用,一般包括特征选择、特征提取、特征构造。
1.1 特征选择:在实际拿到的数据中一般都有非常多的特征,但并非每一个都能拿来训练模型,可能有些特征有用,而另外一些特征就毫无作用,即冗余特征,特征选择的作用就是从已有的特征全集中选择出一部分的特征子集。
进行特征选择有两个重要的原因:
一、维数灾难。若对所有特征不加筛选而一股脑全扔进模型,比如,用户ID和设备ID交叉之后,特征的维度就会非常高,而其实这样的组合特征完全可以只用一个特征来代替,进行特征选择就会大大减少冗余特征,缓解维数灾难问题。
二、去除冗余特征可以减轻模型的学习难度,直观感受就是减少模型的训练时间。常见的特征选择方法主要有三种:过滤式、包裹式、嵌入式。
- 过滤式:使用一些评价指标单独地计算出单个特征跟类别变量之间的关系。如Pearson相关系数,Gini-index(基尼指数),IG(信息增益)等。以Pearson系数为例,计算公式:
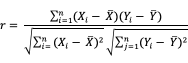
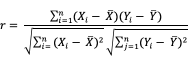
描述的是两个变量间线性相关强弱的程度,绝对值越大表明相关性越强。
的取值在-1与+1之间,若
,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若
,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。
- 包裹式:直接将模型要使用的性能(如AUC)作为特征子集的评价标准,只选择模型性能表现最佳的特征,相对于过滤式来说,包裹式考虑了特征与特征之间的关联性,最终的模型表现也更好。常用的有逐步回归(Stepwise regression)、向前选择(Forward selection)和向后选择(Backward selection)。
- 嵌入式:将特征选择过程与模型训练过程融为一体,即在训练过程中自动地进行了特征选择。例如,针对训练样本数量较少,而特征数量又比较多时,可以使用L1正则化,即在损失函数基础上直接加上权重参数的绝对值:
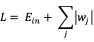
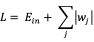
在上式求解过程中,最初的特征全集中只有对应于非零权重的特征才会出现在最终模型中。这样,L1正则化就起到了特征筛选的作用,其特征选择过程与模型训练过程融为一体,同时完成。
1.2 特征提取:将原始特征转换为一组具有明显物理意义(Gabor、几何特征角点、不变量、纹理LBP HOG)或者统计意义或核的特征,比如通过变换特征取值来减少原始数据中某个特征的取值个数等。常用的方法有:
- PCA: PCA的主要思想是将维特征映射到维上,这维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的维特征。其中,第一个新维度选择原始数据中方差最大的方向,第二个新维度选取与第一维正交的平面中方差最大的,第三个新维度是与第1、2维正交的平面中方差最大的,依次类推,可以得到n个这样的维度,最终,大部分方差都包含在前面k个维度中,而后面的维度所含的方差几乎为。
- ICA:PCA是将原始数据降维,并提取不相关的部分;而ICA是将原始数据降维并提取出相互独立的属性;寻找一个线性变换,使得线性变换的各个分量间的独立性最大。ICA相比于PCA更能刻画变量的随机统计特性。
- LDA:也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,基本思想是将高维的模式样本投影到最佳判别空间,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
1.3特征构建:在经过了特征选择之后,确定了需要放入模型的特征后,接下来就要对特征进行处理,对特征进行转换、加工、处理成模型能够识别的格式。根据不同的数据类型,需要采取不同的处理方式:
- 连续型:例如用户年龄、反馈点击率等。由于连续型数值的分布非常广,各特征的取值范围差别很大,如用户的反馈点击率一般为0到1之间,而用户的年龄取值则远远大于1,所以,需要对连续特征进行特别处理,使特征值在同样的量纲范围内:
- Z-score标准化:
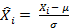
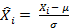
即求出样本特征 的均值
和标准差
,然后用来代替原特征。这样新的特征值就变成了均值为0,方差为1。
- 最大-最小标准化:
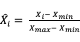
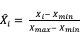
求出样本特征的最大值
和最小值
,然后


用来代替原特征值。不过,这种方法有个问题,若预测集里的特征有小于,或者大于
的数据,会导致
和
发生变化,需要重新计算。所以一般实际应用中,最大-最小标准化不如Z-score标准化鲁棒。
- 离散化:对于连续型特征,除了上述两种标准化方法之外,还有一种常用的处理方式:离散化。和标准化不同的是,离散化可以加入人工经验,也可以是和业务紧密相关的规则,因此这种方法更容易被人类理解。
一般采用分桶或者分段的方式,即事先指定每个桶的取值范围,然后将特征值划分到桶中,最后用桶的编号作为新的特征值。对于桶的划分又可以分为等频(各个桶中的数量大致相同)、等宽(各个桶的上下界的差值相同)、人工指定。一般来说,等频离散不会像等宽离散出现某些桶中数量极多或者极少。但是等频离散为了保证每个区间的数据一致,很有可能将原本是相同的两个数值却被分进了不同的区间,会对最终模型效果产生一定影响。人工指定则需要根据过去的经验来进行划分,例如对于反馈点击率,发现过去的点击率集中在1%和2%之间,因此,可以这样划分(python代码):


- 离散特征:例如广告尺寸、广告样式、投放城市等等。对于离散特征一般采用One-hot(独热编码)方式,即将所有样本的离散特征放在一起,称为特征空间,每个特征就转换为一个特征空间大小的向量,其中该特征值对应下标的值为1,其余的都为0,从数学角度可以理解为将离散特征的取值扩展到了欧式空间,因为常用的距离或相似度的计算都是在欧式空间中进行,因此,One-hot对于离散特征来说是最合理的选择。
- 文本特征:例如广告的标题、描述信息等等。对于文本型特征,可以用如下处理方法:
- tf-idf:基于统计词的出现频次的方法,用以评估一个词的重要程度,具体计算公式:


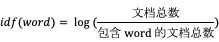
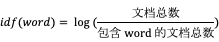
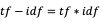
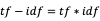
其中, 反映的是该词在当前文档中的热门程度,但是对于那些几乎每篇文章都会出现的助词来说,如“的”、“了”、“这”等等,就需要给它们降权,从
的计算公式可以看出,包含该词的文档数约多,倒数就越小,从而就可以起到降权的作用。因此最终的乘积就可以认为是该词在整篇文章的重要性。
- Word2vec:在深度学习大热之后,出现了Word2vec模型,可以将词向量化,即转化为低维度的连续值、稠密向量,从而使得意思相近的词在向量空间中也处于相同的位置。Word2vec实际上是一个具有隐含层的神经网络,输入是One-hot编码的词汇向量表,隐含层没有激活函数,也就是线性单元,输出层使用Softmax回归,但其实我们不关心输出层的结果,只需要拿到隐藏层的输出单元即是所需的向量。
Word2Vec其实训练了一个语言模型,即通过前n 个字预测下一个字的概率,是一个多分类器,输入一个one hot,然后连接一个全连接层、再连接若干个层,最后接一个Softmax分类器,就可以得到语言模型了,然后将大批量文本输入训练就行了,最后得到第一个全连接层的参数,就是字、词向量表。
Word2vec主要有两个模型:
CBOW:主要用来从原始语句推测目标词汇。CBOW用周围词预测中心词,从而利用中心词的预测结果情况。当训练完成之后,每个词都会作为中心词。把周围词的词向量进行了调整,这样也就获得了整个文本里面所有词的词向量。
Skip-gram:从目标词汇推测原始语境。与CBOW相反的是,Skip-gram使用中心词预测周围词,Skip-gram会利用周围的词的预测结果情况,不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。对比而言,Skip-gram进行预测的次数多于CBOW的:因每个词作为中心词时,皆需使用周围词进行预测一回,训练时间相对更长。
- 动态特征:在计算广告模型的特征中,除了有用户年龄、地理位置、广告尺寸等相对不变的静态特征,还可以加入其他特征:如相同广告尺寸的历史点击率、历史到达率等,这类特征我们称之为动态特征,因为这些特征的值随着时间窗口的取值不同而不同。使用动态特征主要有两个好处:1. 可以大大减少模型参数数目 2. 模型不必快速更新。
- CoEC(Clickon Expected Click)特征:由于广告在实际展示时,最终效果经常会受到广告位置的影响,例如一个展示在首页顶端位置的广告往往比另一个在内容页下端展示的广告效果好的多,这其实是由于位置带来的偏差,导致在位置上占据优势的广告点击率被严重高估。其他的影响因素还包括广告位尺寸、广告位类型、创意类型等,以上这些特征都称为偏差因素。因此为了去除这些偏差等因素的影响,工业界的做法是:
- 首先,训练一个偏差模型,只用那些偏差因素训练一个点击率模型,称为偏差模型。
- 利用偏差模型,计算下式:
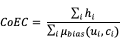
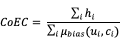
其中, 表示是否点击(0或1),
为用户端特征,
为上下文特征。这一式子其实是点击与期望点击的比值,因此称为CoEc特征,该特征可以更准确的表征某部分流量上广告投放的实际点击率水平,比较适用于点击反馈的动态特征。
(2)模型
经过了上述特征工程处理之后,就需要将特征放入到具体的模型中。针对ctr预估问题,工业界也产生了很多的模型,由最初的逻辑回归模型到目前非常热门的深度学习模型,效果也随之提升了很多。下面就来具体看下ctr预估模型的一路发展。
2.1LR(逻辑回归)
LR是ctr预估模型的最基本的模型,也是工业界最喜爱使用的方案。LR 是广义线性模型,与传统线性模型相比,LR 使用了 Logit 变换将函数值映射到 0~1 区间,映射后的函数值就是 CTR 的预估值。
LR 利用了 Logistic 函数,函数形式为:
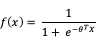
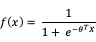
优点:由于LR 模型简单,训练时便于并行化,在预测时只需要对特征进行线性加权,所以性能比较好,往往适合处理海量 id 类特征,模型的结果直观易解释。
缺点:LR 的缺点也很明显,首先对连续特征的处理需要先进行离散化,如上文所说,对连续特征的分桶方式有很多种,各种方式都有差异。另外 LR 需要进行人工特征组合,这就需要开发者有非常丰富的领域经验,才能不走弯路。这样的模型迁移起来比较困难,换一个领域又需要重新进行大量的特征工程。
2.2 FM(Factorization Machine)、FFM(Field-aware factorization machine)
在一般的线性模型中,各个特征独立考虑的,没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的。
一般的线性模型为:为了表述特征间的相关性,可以采用多项式模型。在多项式模型中,特征 与
的组合用
表示。二阶多项式模型如下:
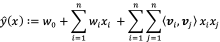
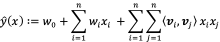
其中 表示样本的特征数量,这里的特征是离散化后的特征。与线性模型相比,FM的模型多了后面的特征组合的部分。
FM主要有如下特点:
1.可以在非常稀疏的数据中进行合理的参数估计
2.FM模型的时间复杂度是线性的
3.FM是一个通用模型,它可以用于任何特征为实值的情况
而FFM则是在FM的基础上,考虑了特征交叉的field的特点,但是也导致它没有办法实现线性的时间复杂度,模型训练要比FM慢一个量级,但是效果会比FM来得更好。在业界,目前已经有公司线上利用FM去预测ctr。
2.3 LR + GBDT
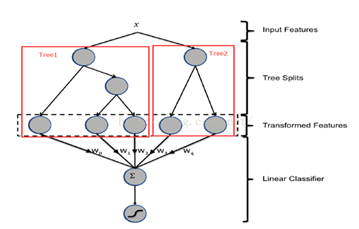
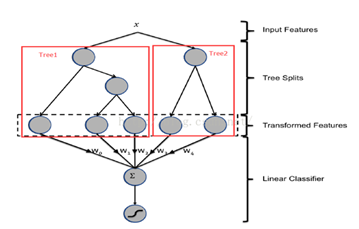
在Facebook2014年的一篇论文中,提及到GBDT+LR的解决方案。即先使用GBDT对一些稠密的特征进行特征选择,得到的叶子节点,再拼接离散化特征放进去LR进行训练。在方案可以看成,利用GBDT替代人工实现连续值特征的离散化,而且同时在一定程度组合了特征,减少了人工的工作量。
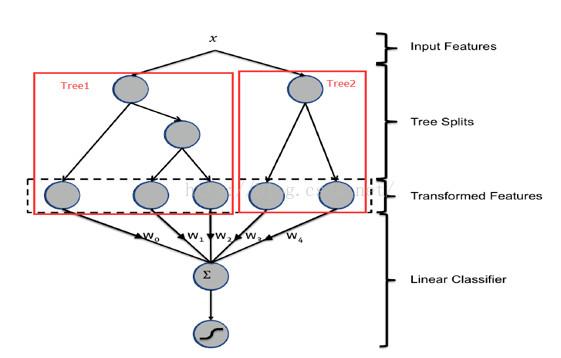
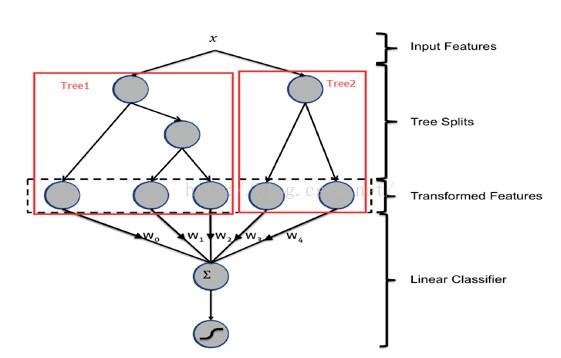
从上图可以看到,输入x分别落到2颗树的叶子节点上,每个叶子节点对应的编号就作为新的特征送入LR中,其中新的特征维度与树的数目相同,在实际应用中,需要进行调参的有每棵树的深度、树的总数等。
另外,对于广告来说,ID类特征在CTR预估中是非常重要的特征,直接将AD ID作为feature进行建树不可行,可以考虑为每个AD ID建GBDT树。具体做法,使用GBDT建两类树,非ID建一类树,ID建一类树。
1)非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以得到有区分性的特征、特征组合。
2)ID类树:以细粒度的ID建一类树,用于发现那些曝光充分的ID有区分性的特征、特征组合。在实际应用中,效果略有提升,但是需要综合考虑GBDT的性能问题。
2.4 Wide & Deep
Wide & Deep 模型是 Google在2016年发表的文章中提出的,并应用到了 Google Play 的应用推荐中。Wide & Deep模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
Wide & Deep模型中使用的特征包括两大类: 一类是连续型特征,主要用于deep模型的训练,包括连续值型的特征以及embedding类型的特征等;一类是离散型特征,主要用于Wide模型的训练,包括稀疏类型的特征以及组合型的特征等。
模型结构:
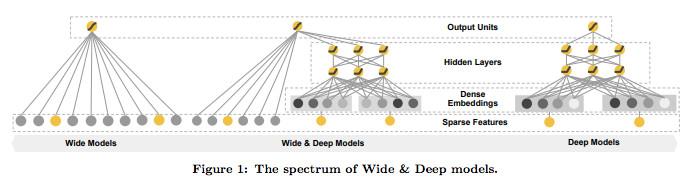
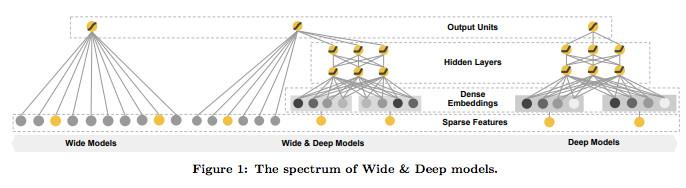
模型特点:
记忆(memorization)通过特征叉乘对原始特征做非线性变换,输入为高维度的稀疏向量。通过大量的特征叉乘产生特征相互作用的“记忆(Memorization)”,高效且可解释。
泛化(generalization)只需要少量的特征工程,深度神经网络通过embedding的方法,使用低维稠密特征输入,可以更好地泛化训练样本中未出现过的特征组合。
Memorization趋向于更加保守,推荐用户之前有过行为的items。相比之下,generalization更加趋向于提高推荐系统的多样性(diversity)。
2.5 DeepFM
DeepFM是由哈工大与华为诺亚方舟实验室共同发表的论文中提出的,模型有效的结合了神经网络与因子分解机在特征学习中的优点。DeepFM可以同时提取到低阶组合特征与高阶组合特征,并除了得到原始特征之外无需其他特征工程。
模型结构:
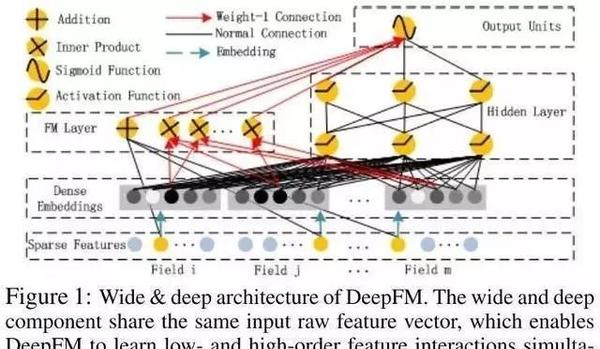
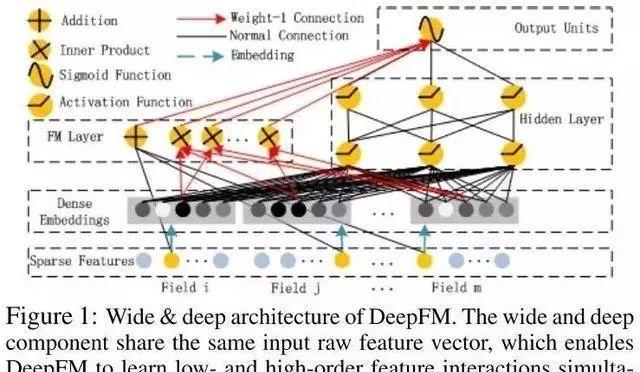
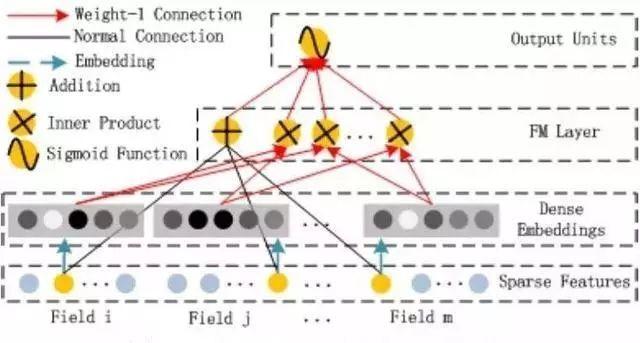
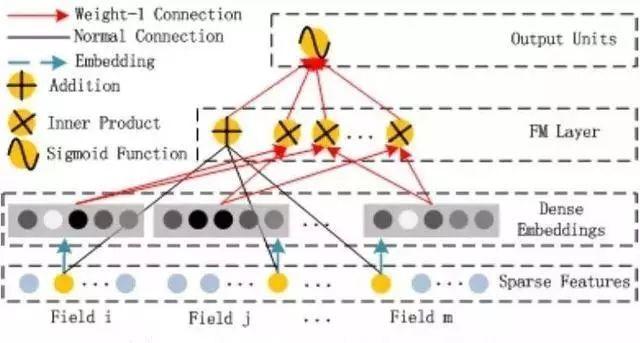
比起Wide& Deep的LR部分,DeeFM采用FM作为Wide部分的输出,FM部分如下图:
Deep component 如下图:
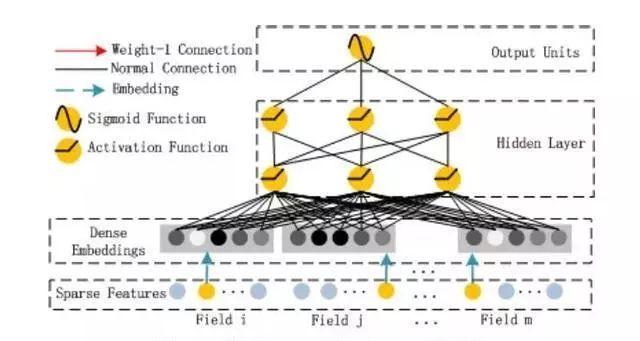
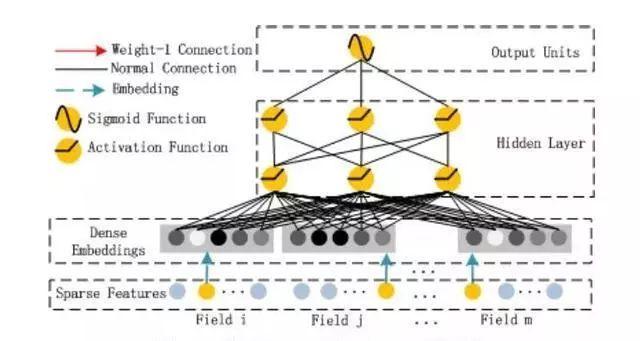
Deep Component是用来学习高阶组合特征的。网络里面黑色的线是全连接层,参数需要神经网络去学习。
由于ctr或推荐系统的数据One-hot之后特别稀疏,如果直接放入到DNN中,参数非常多,我们没有这么多的数据去训练这样一个网络。所以增加了一个Embedding层,用于降低纬度。
优点:首先,FM提取低阶组合特征,Deep提取高阶组合特征。但是和Wide & Deep不同的是,DeepFM是端到端的训练,不需要人工特征工程.
其次,共享feature embedding。FM和Deep共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。
相比之下,Wide & Deep的输入vector非常大,里面包含了大量的人工设计的pairwise组合特征,因此增加了计算复杂度。
生态
说到整个程序化交易广告的生态圈,除了以上介绍的SSP、DSP、Adx等,还有其他大大小小的角色在其中发挥着作用。在此,列举几个如下:
- 广告代理商:指由一些创作人员和经营管理人员所组成的,能够为广告客户制定广告计划、商业宣传、制作广告和提供其它促销工具的一个独立性机构,收入来源为服务费和合作的各大广告平台的返点。但最近几年,随着代理商之间的竞争激烈,加之返点模式也越来越被诟病,也导致了许多的代理商或转型或退出这个行业。
- 广告网络:在PC端介于想出售广告资源的Web网站与想在PC端发布广告的广告主之间的平台。拥有大量的媒体资源,一方面帮助媒体将广告位资源整合打包出售,另一方面帮助广告主定向目标人群。广告主按照千次展示数或按点击付费。
- 数据交换平台:是实现用户标签数据交换的平台,服务项目包括为客户提供统一CookieMapping技术解决方案,以及用户标签数据的私有交换,帮助企业客户提高数据管理能力。
- 第三方监测公司:由于程序化广告的交易模式是由多方参与其中,因此,为了保证数据的准确性、避免各方在结算时的数据差异,同时为广告主有效评估在线广告的接触效果(包括接触人数、频次和目标受众特征等)以及互联网广告的投入产出(ROI),需要引入第三方监测公司。这些公司往往具有完整且成熟的产品或者解决方案,因此目前这些服务都是收费的。
目前国内完整的生态圈如下图:


关于趋势,最近有国外的广告科技前沿作者预测,媒体方削减推送给广告交易平台的流量并自主搭建与DSP的直接对接或许会成为趋势,并预测,未来主流大型媒体通过程序化方式售卖的形态很可能是仅和二、三家广告交易平台对接,同时直接和十多家DSP对接,以获得更好的利润和控制权。此趋势如发生,将进一步削弱开放式广告交易平台的作用并进一步减少优质库存通过广告交易平台交易的机会。
对于独立的移动广告技术公司而言,出海的发展机会似乎大于固守本土的机会,2018年广告技术公司上市的情况即是佐证。OTT和OOH以及音频媒体库存正在处于酝酿进入程序化模式的前夜,这或许是未来几年的持续增长点。
参考文献
- 《计算广告》 刘鹏 / 王超
- 《机器学习》 周志华
- https://clearcode.cc/blog/how-the-real-time-bidding-rtb-ad-exchange-works-infographic/
- http://hadoop.apache.org/
- http://spark.apache.org/
- http://lucene.apache.org/
- http://zookeeper.apache.org/
- Practical Lessonsfrom Predicting Clicks on Ads at Facebook, 2014
- DistributedRepresentations of Sentences and Documents, 2014
- Word2vec Parameter LearningExplained, 2016
- Wide & Deep Learningfor Recommender Systems, 2016
- DeepFM: AFactorization-Machine based Neural Network for CTR Prediction, 2017
- http://www.rtbchina.com/china-programmatic-ad-tech-landscape-2018-vq4.html
ABOUT
关于作者
吴威骏:达观推荐算法工程师,负责推荐算法的研究、应用。先后在SAP、力美、百度等公司从事数据挖掘和广告系统的算法开发,对机器学习算法、广告系统有深入研究。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK