

Thinking AI? Think Data First
source link: https://blog.knoldus.com/thinking-ai-think-data-first/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Thinking AI? Think Data First
Reading Time: 4 minutes
There is a lot of interest in Machine Learning and AI. Ofcourse, a lot of it is still the level 1 of AI . This is when we are thinking about machines acting like humans. Everyone wants to jump on the bandwagon of AI. It is an amazing field and man organizations do not want to be left behind. That said, something which is ignored most of the time is the fuel, the data!
Teaching the machines required showing them a lot of “training data”. This could be in the form of videos, images, text, structured, unstructured, inhouse, locked in private spaces, public spaces, etc etc. Machines need to learn with a lot of data. They also need to learn with the Right Data.
In theory, the world is awash with data, the lifeblood of modern AI. A market-research firm, reckons the world generated 33 zettabytes of data in 2018, enough to fill seven trillion dvds.
Data issues are one of the most common sticking-points in any AI project.
Considerations of working with Data
Data-wrangling of various sorts takes up about 80% of the time consumed in a typical AI project. Machines, in order to perform accurately need a lot of training.
According to the economist, 80% of the time is spent in getting the right data. This is where most organizations falter. They spend too much time working on the model training and algorithms without realizing the data ownership and cleansing mechanisms.
These result in data anemic models where either the data is incorrect or inadequate . The results from these systems are usually questionable.
Two course data scientists (Engineers who take a couple of courses on data science) and proclaim mastery in the field, are almost always a victim to the pattern of ignoring the importance of data. The attention on detail for cleansing, labeling and combining of data cannot be ignored. Without that you are hunting for your car keys under the lamp post. Not because you lost them here but because there is more light here.
All said and done, internally, getting access to the right data is a huge challenge for many organizations. The data science and machine learning departments would quickly like to start building models with subset of data. Procurement and cleanliness of data come as an afterthought and that is where most ML/AI failures would happen.
Inadequate attention on building the pipelines. Once the data ownership and the cleansing etc are identified, the job is not complete. Many organizations would fail in building the pipelines to get the data from the source to the sink. Many AI/ML models would work on a streamflow of data. Consider adjusting the medicine dispensed to a patient in the hospital which depends on his vital statistics or detecting fraud in real time. These systems need robust data pipelines which can be high-availability and scale well.
Modern data pipelines include acquisition of data from various systems and combining that data to together to run analytics. A possible architecture would be the following
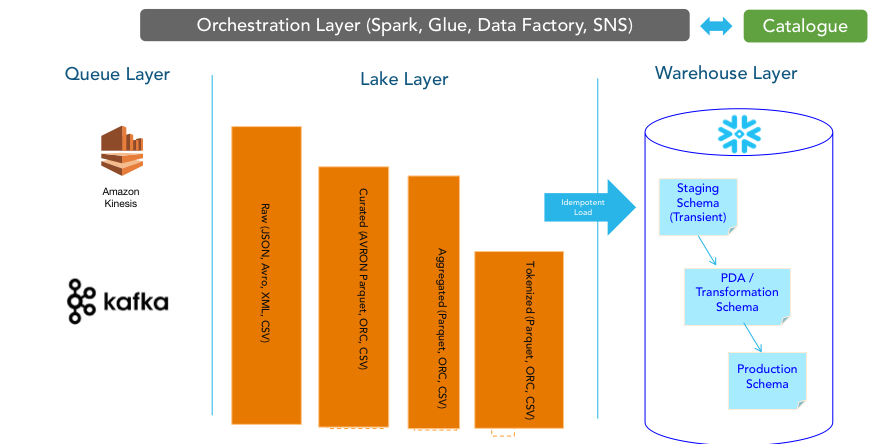

Data needs a lot of handholding. The training labels usually have to be applied by humans. Big tech firms often do the work internally. Companies that lack the required resources or expertise can take advantage of a growing outsourcing industry to do it for them. Mechanical turk from Amazon brings data labelling to a huge population of data entry operators who can label a lot of data like x-rays, image etc.
Further, the data itself contains traps. Machine-learning systems correlate inputs with outputs, but they do it blindly, with no understanding of broader context. That has led to a lot of bias being built into machines. A recent case which exploded in the media was the face recognition used in US. This was more often than not biased to skin tones other than white for identifying suspects. This is completely dependent on the kind of data being fed into the training set. It seemed that most of the colored data set fed in was for suspects which resulted in the algorithm behaving in unprecedented ways.
In 2017 Amazon abandoned a recruitment project designed to hunt through cvs to identify suitable candidates when the system was found to be favouring male applicants. The post mortem revealed a circular, self-reinforcing problem. The system had been trained on the cvs of previous successful applicants to the firm. But since the tech workforce is already mostly male, a system trained on historical data will latch onto maleness as a strong predictor of suitability.
Other Considerations
Privacy of data is another issue where a lot of legal and medical data is not readily available. This results in a lot of organizations generate synthetic data which can be close, in best case. In most cases it ends up being disjoint from the real data.
Another interesting one is drift in the data. Sometimes this drift is gradual. As in the case of shopping preferences for a region in the country where the population is aging and does not have too many kids. Other drift scenarios could be overnight. For example, booking a one way ticket on a credit card would trigger alerts but this was a norm in COVID situation. Similarly any prediction models which were based on forecasting the need for toilet paper or home gym equipment were thrown off with the surge in demand during the pandemic.
The world’s changeability means more training, which means providing the machines with yet more data, in a never-ending cycle of re-training.
AI is definitely not an install-and-forget system
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK