

Python爬取笔趣阁小说,有趣又实用
source link: https://blog.csdn.net/zhiguigu/article/details/115915722
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序。好吧,其实就是找个目的学习python,分享一下。
1. 首先导入相关的模块
import os
import requests
from bs4 import BeautifulSoup
2. 向网站发送请求并获取网站数据
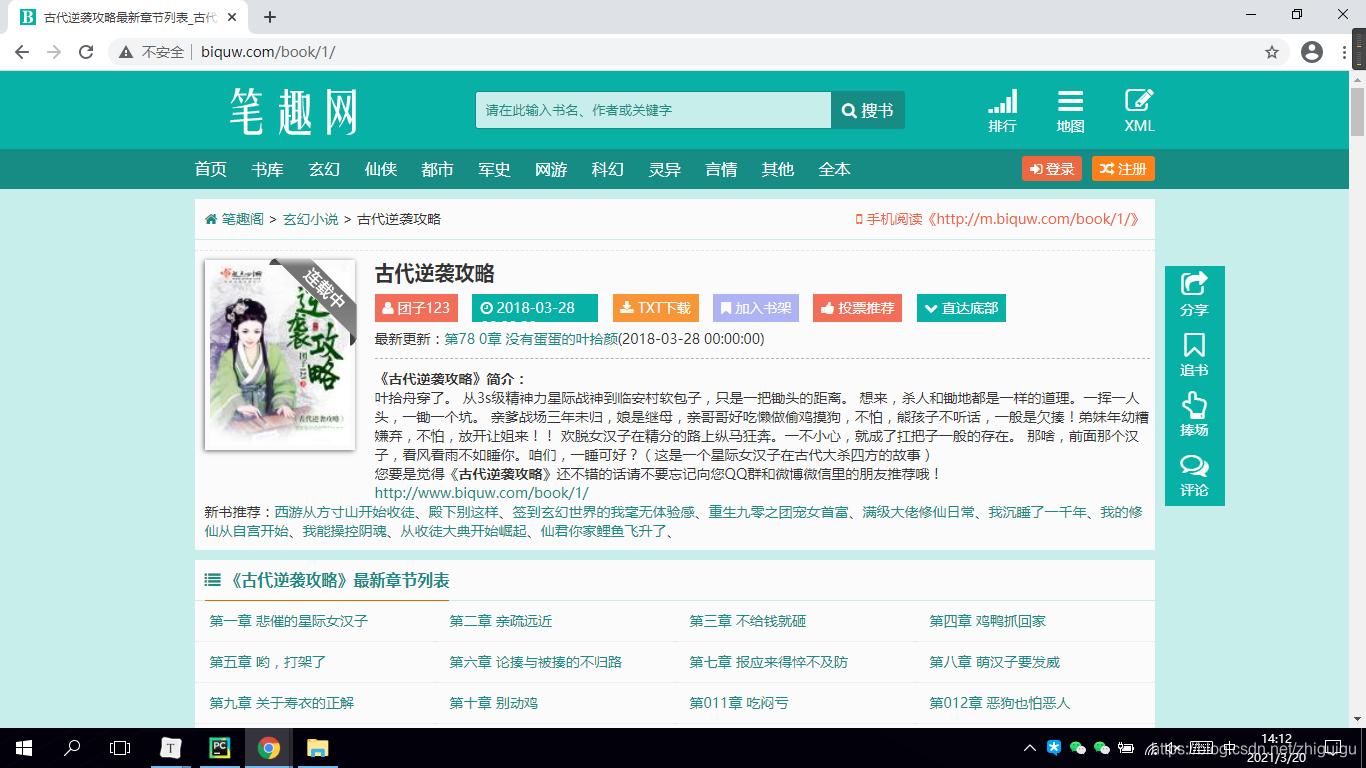
网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例。
进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取
# 声明请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
# 创建保存小说文本的文件夹
if not os.path.exists('./小说'):
os.mkdir('./小说/')
# 访问网站并获取页面数据
response = requests.get('http://www.biquw.com/book/1/').text
print(response)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uu2ddyQB-1618914957232)(.\素材图片\中文显示乱码.png)]
写到这个地方同学们可能会发现了一个问题,当我去正常访问网站的时候为什么返回回来的数据是乱码呢?
这是因为页面html的编码格式与我们python访问并拿到数据的解码格式不一致导致的,python默认的解码方式为utf-8,但是页面编码可能是GBK或者是GB2312等,所以我们需要让python代码很具页面的解码方式自动变化
#### 重新编写访问代码
```python
response = requests.get('http://www.biquw.com/book/1/')
response.encoding = response.apparent_encoding
print(response.text)
'''
这种方式返回的中文数据才是正确的
'''
3. 拿到页面数据之后对数据进行提取
当大家通过正确的解码方式拿到页面数据之后,接下来需要完成静态页面分析了。我们需要从整个网页数据中拿到我们想要的数据(章节列表数据)
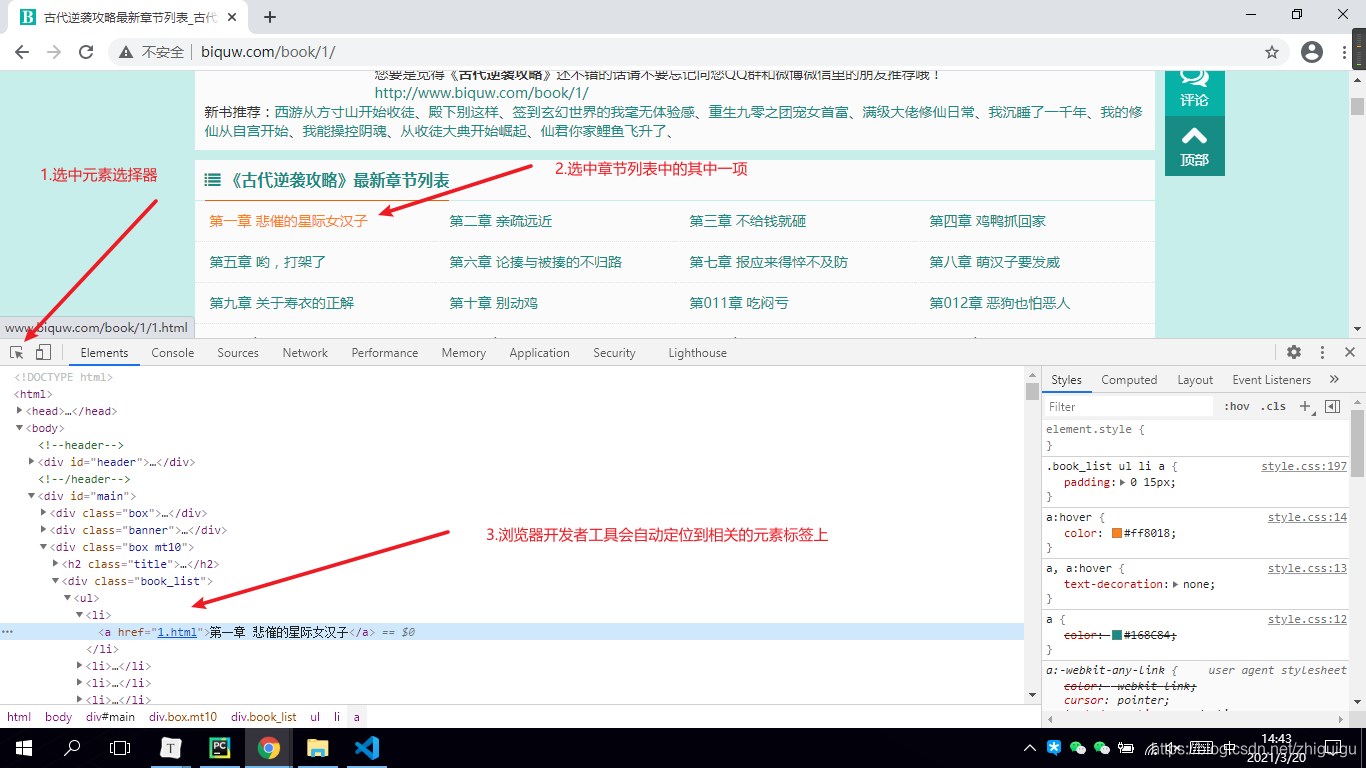
- 首先打开浏览器
- 按F12调出开发者工具
- 选中元素选择器
- 在页面中选中我们想要的数据并定位元素
- 观察数据所存在的元素标签
'''
根据上图所示,数据是保存在a标签当中的。a的父标签为li,li的父标签为ul标签,ul标签之上为div标签。所以如果想要获取整个页面的小说章节数据,那么需要先获取div标签。并且div标签中包含了class属性,我们可以通过class属性获取指定的div标签,详情看代码~
'''
# lxml: html解析库 将html代码转成python对象,python可以对html代码进行控制
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup对象获取批量数据后返回的是一个列表,我们可以对列表进行迭代提取
for book in book_list:
book_name = book.text
# 获取到列表数据之后,需要获取文章详情页的链接,链接在a标签的href属性中
book_url = book['href']
4. 获取到小说详情页链接之后进行详情页二次访问并获取文章数据
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
5. 对小说详情页进行静态页面分析
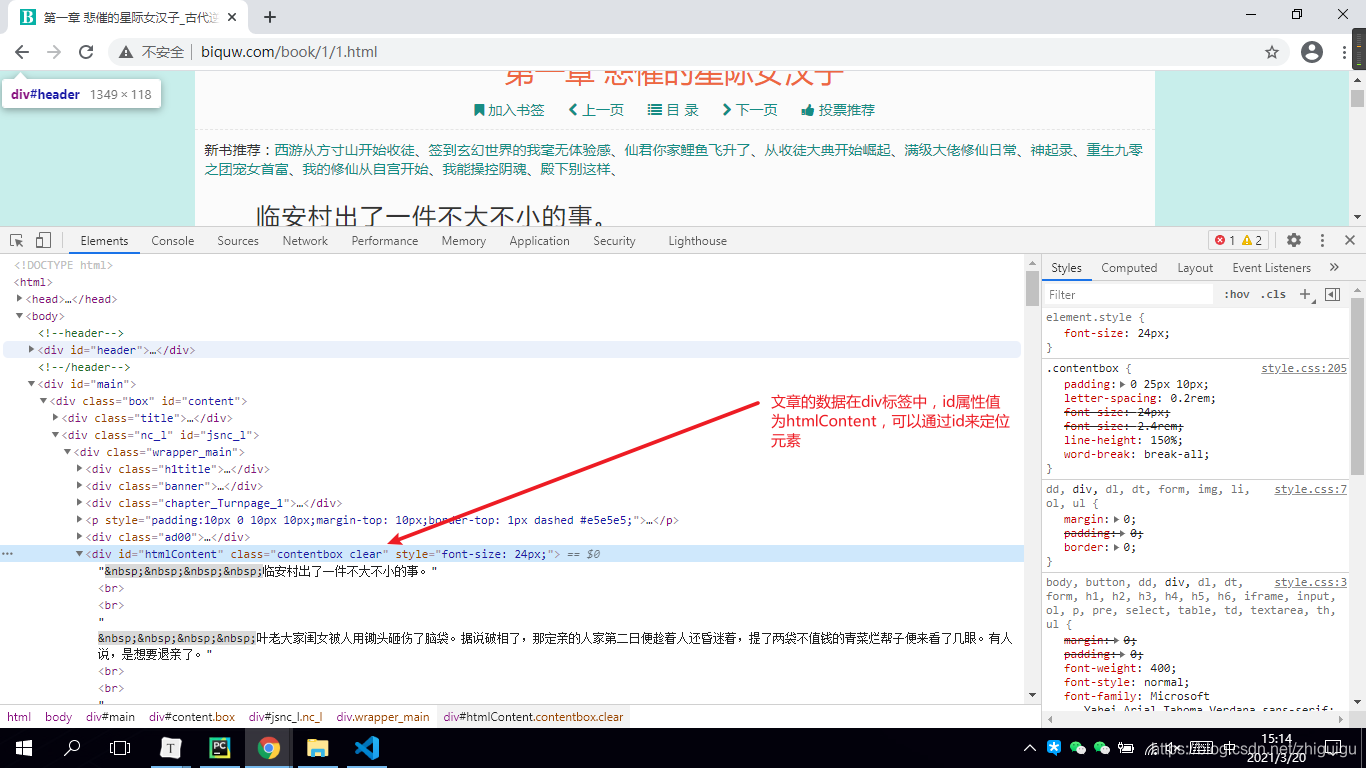
info = soup.find('div', id='htmlContent')
print(info.text)
6. 数据下载
with open('./小说/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
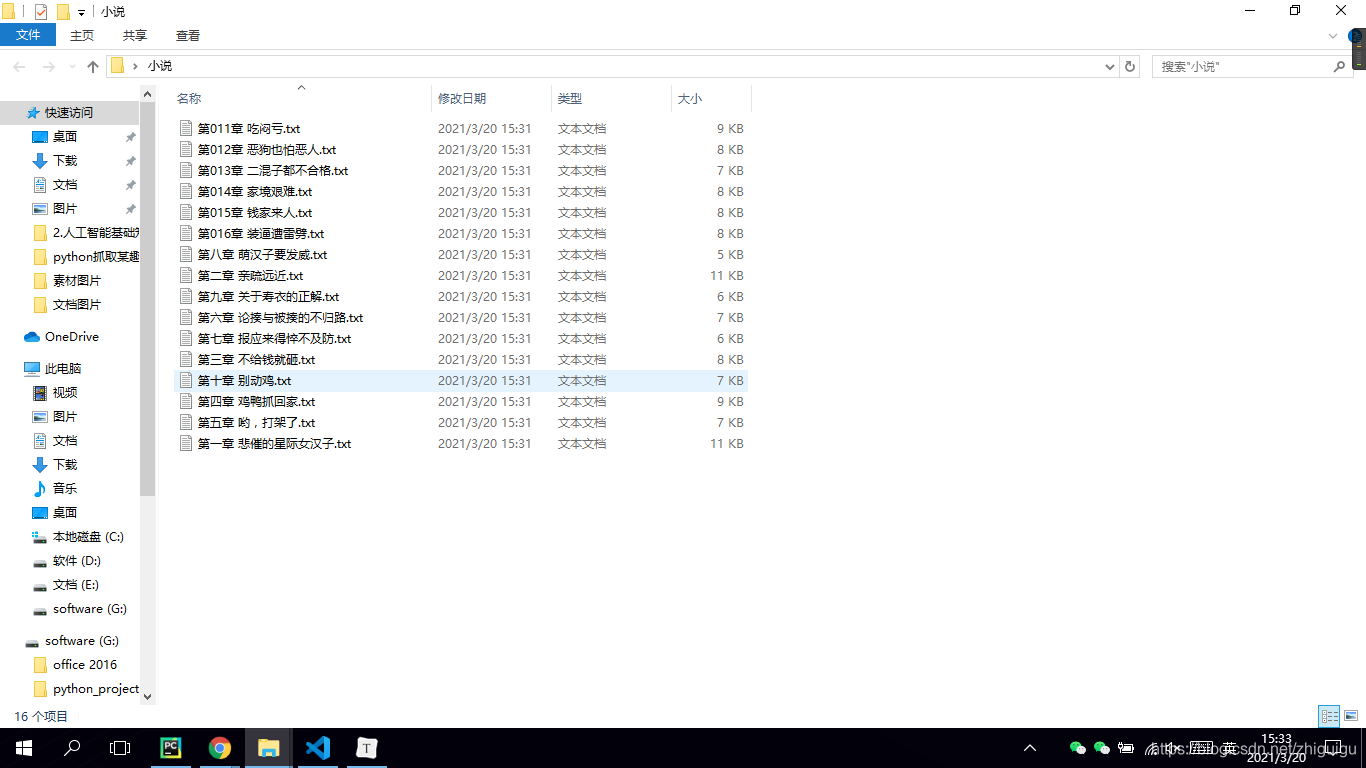
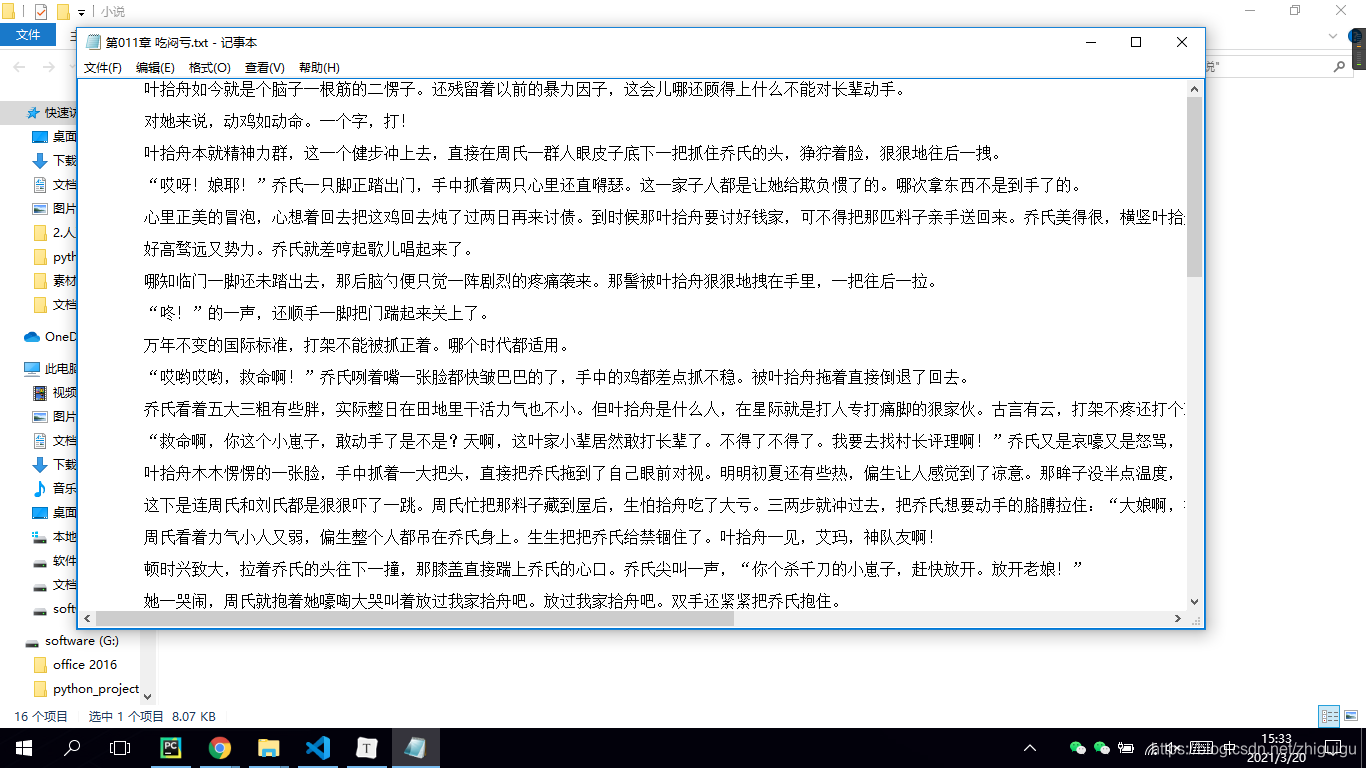
最后让我们看一下代码效果吧~
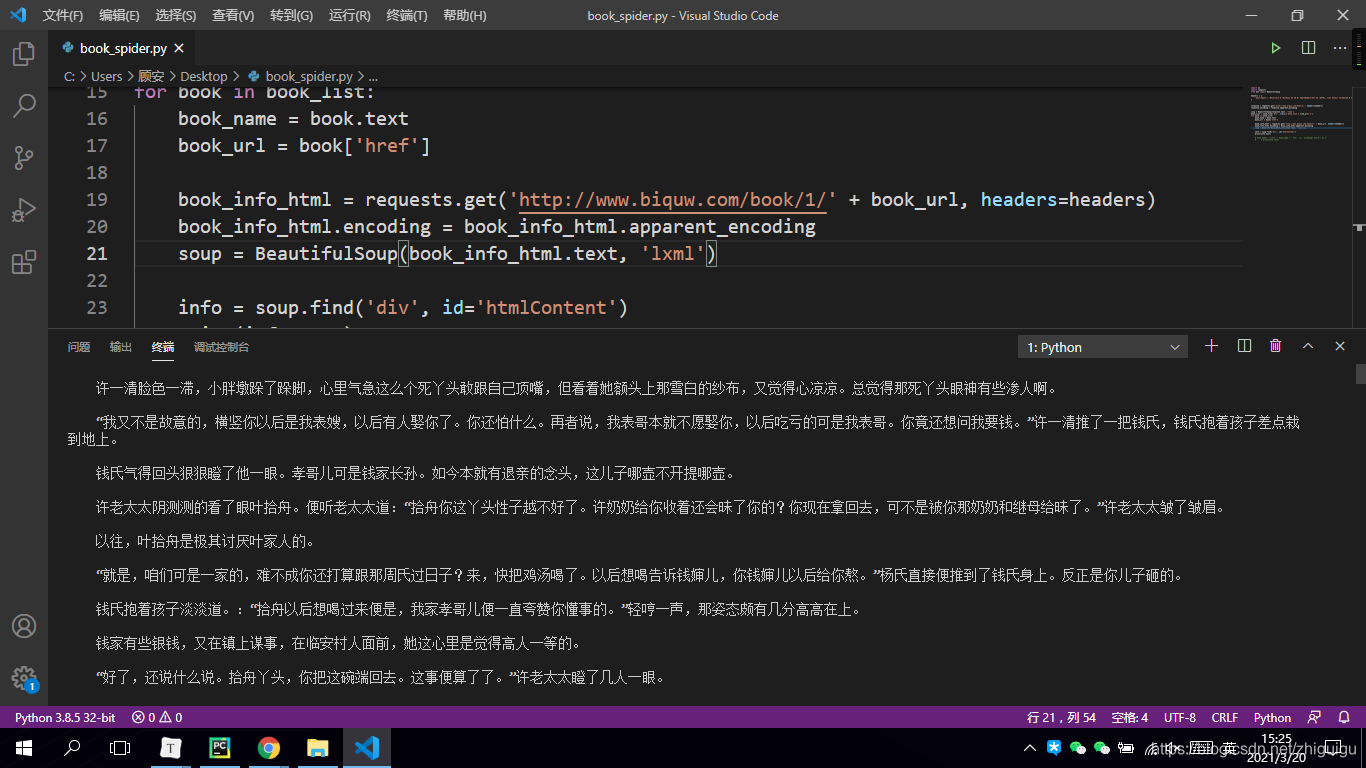
抓取的数据

文章正文到这里已经结束了,只是想感谢一些阅读我文章的人。
我退休后一直在学习如何写文章,说实在的,每次我在后台看到一些读者的回应就会觉得很欣慰,于是我想把我收藏的一些编程干货贡献给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门视频等等(适合小白学习)
*如果你用得到的话可以直接拿走,在我的QQ技术交流群里(广告勿入)可以自助拿走,群号是980758007。*

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK