

Unicode: On Building The One Character Set To Rule Them All
source link: https://hackaday.com/2021/03/17/unicode-on-building-the-one-character-set-to-rule-them-all/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Unicode: On Building The One Character Set To Rule Them All
Most readers will have at least some passing familiarity with the terms ‘Unicode’ and ‘UTF-8’, but what is really behind them? At their core they refer to character encoding schemes, also known as character sets. This is a concept which dates back to far beyond the era of electronic computers, to the dawn of the optical telegraph and its predecessors. As far back as the 18th century there was a need to transmit information rapidly across large distances, which was accomplished using so-called telegraph codes. These encoded information using optical, electrical and other means.
During the hundreds of years since the invention of the first telegraph code, there was no real effort to establish international standardization of such encoding schemes, with even the first decades of the era of teleprinters and home computers bringing little change there. Even as EBCDIC (IBM’s 8-bit character encoding demonstrated in the punch card above) and finally ASCII made some headway, the need to encode a growing collection of different characters without having to spend ridiculous amounts of storage on this was held back by elegant solutions.
Development of Unicode began during the late 1980s, when the increasing exchange of digital information across the world made the need for a singular encoding system more urgent than before. These days Unicode allows us to not only use a single encoding scheme for everything from basic English text to Traditional Chinese, Vietnamese, and even Mayan, but also small pictographs called ‘emoji‘, from Japanese ‘e’ (絵) and ‘moji’ (文字), literally ‘picture word’.
From Code Books to Graphemes
As far back as the era of the Roman Empire, it was well-known that getting information quickly across a nation was essential. For the longest time, this meant having messengers on horseback or its equivalent, who would carry a message across large distances. Although improvements to this system were imagined as far back as the 4th century BC in the form of the hydraulic telegraph by the ancient Greek, as well as use of signal fires, it wasn’t until the 18th century that rapid transmission of information over large distances became commonplace.
The French Chappe optical telegraph code from around 1809The optical telegraph (also called the ‘semaphore’) was discussed in depth in our recent article on the history of optical communications. It consisted of a line of relay stations, each of which was equipped with an elevated system of pivoting indicator arms (or its equivalent) used to display the telegraph code character encoding. The French Chappe system, which saw French military use between 1795 and the 1850s, was based around a wooden crossbar with two movable ends (arms), each of which could be moved into one of seven positions. Along with four positions for the crossbar, this made for a theoretical 196 symbols (4x7x7). In practice this was whittled down to 92 or 94 positions.
These code points were used not only for direct encoding of characters, but mostly to indicate specific lines in a code book. The latter method meant that a couple of transferred code points might entail the entire message, which sped up transmission and made intercepting the code points useless without the code book.
Improving the Throughput
As the optical telegraph was phased out in favor of the electrical telegraph, this meant that suddenly one wasn’t limited to encodings which could be perceived by someone staring through a telescope at a nearby relay tower in acceptable weather. With two telegraph devices connected by a metal wire, suddenly the communication medium was that of voltages and currents. This change led to a flurry of new electrical telegraph codes, with International Morse Code ultimately becoming the international standard (except for the US, which kept using American Morse Code outside of radiotelegraphy) since its invention in Germany in 1848.
International Morse Code has the benefit over its US counterpart in that it uses more dashes than dots, which slowed down transmission speeds, but also improved the reception of the message on the other end of the line. This was essential when long messages were transmitted across many kilometers of unshielded wire, by operators of varying skills levels.
The ITA 2 standard, with the two characters per code point. A shift character would indicate which of the two would be used for the following characters.As technology progressed, the manual telegraph was replaced in the West by automatic telegraphs, which used the 5-bit Baudot code, as well as its derived Murray code, the latter based around the use of paper tape in which holes got punched. Murray’s system allowed for the message tape to be prepared in advance and then fed into a tape reader for automatic transmission. The Baudot code formed the basis of the International Telegram Alphabet version 1 (ITA 1), with a modified Baudot-Murray code forming the basis of ITA 2, which saw use well into the 1960s.
By the 1960s, the limit of 5-bits per character was no longer needed or desirable, which led to the development of 7-bit ASCII in the US and standards like JIS X 0201 (for Japanese katakana characters) in Asia. Combined with the teleprinters which were in common use at the time, this allowed for fairly complicated text messages, including upper- and lower-case characters, as well as a range of symbols to be transmitted.
The full character set of 7-bit ASCII.During the 1970s and early 1980s the limits of 7- and 8-bit encodings like extended ASCII (e.g. ISO 8859-1 or Latin 1) were sufficient for basic home computing and office needs. Even so, the need for improvement was clear, as common tasks like exchanging digital documents and text within e.g. Europe would often lead to chaos due to its multitude of ISO 8859 encodings. The first step to fixing this came in 1991, in the form of the 16-bit Unicode 1.0.
Outgrowing 16-Bits
The amazing thing is that in only 16-bits, Unicode managed to not only cover all of the Western writing systems, but also many Chinese characters and a variety of specialized symbols, such as those used in mathematics. With 16-bits allowing for 216 = 65,536 code points, the 7,129 characters of Unicode 1.0 fit easily, but by the time Unicode 3.1 rolled around in 2001, Unicode contained no less than 94,140 characters across 41 scripts.
Currently, in version 13, Unicode contains a grand total of 143,859 characters, which does not include control characters. While originally Unicode was envisioned to only encode writing systems which were in current use, by the time Unicode 2.0 was released in 1996, it was realized that this goal would have to be changed, to allow even rare and historic characters to be encoded. In order to accomplish this without necessarily requiring every character to be encoded in 32-bits, Unicode changed to not only encode characters directly, but also using their components, or graphemes.
The concept is somewhat similar to vector drawings, where one doesn’t specify every single pixel, but describes instead the elements which make up the drawing. As a result, the Unicode Transformation Format 8 (UTF-8) encoding supports 231 code points, with most characters in the current Unicode character set requiring generally one or two bytes each.
Many Flavors of Unicode
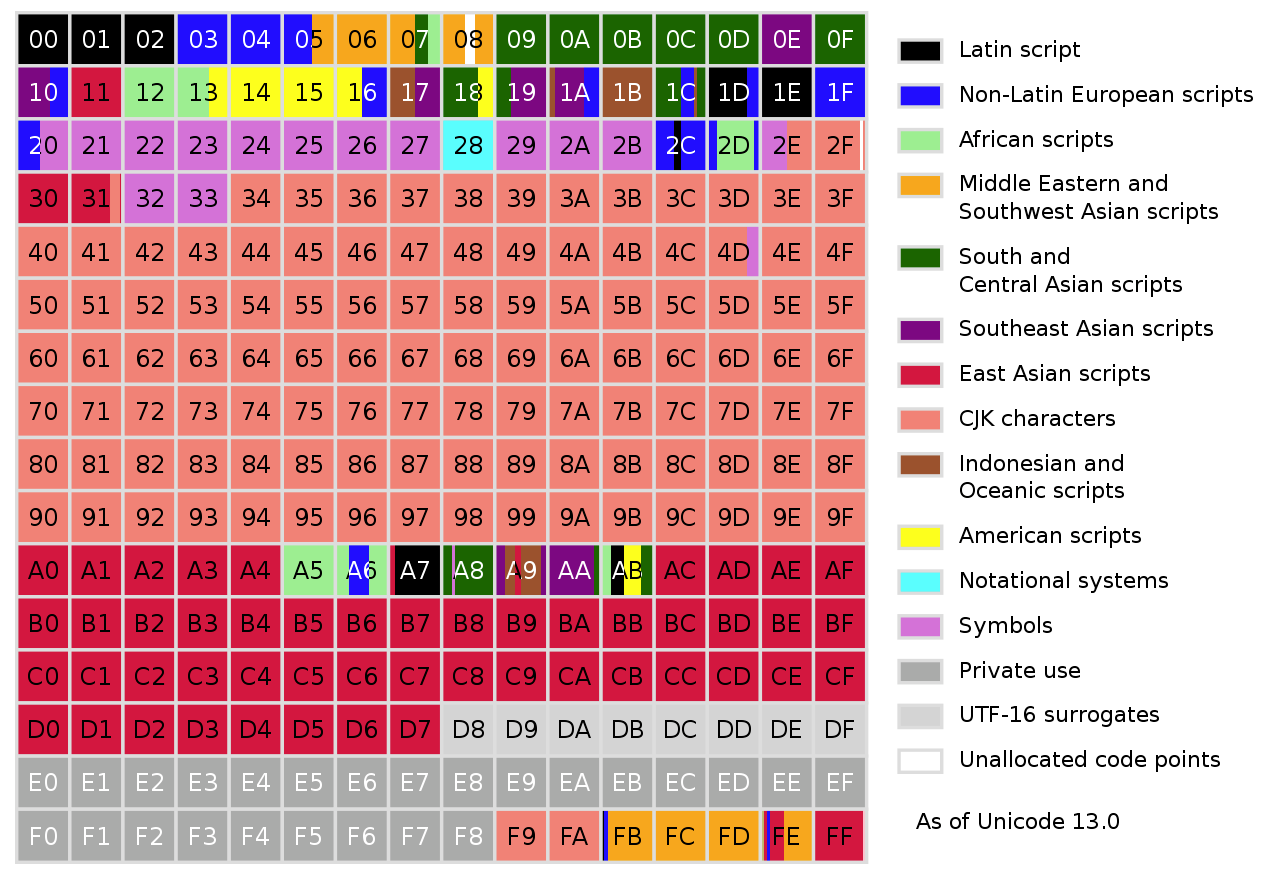
At this point in time, quite a few people are probably at least somewhat confused by the different terms being thrown around when it comes to Unicode. It’s therefore essential to note here that Unicode refers to the standard, with the different Unicode Transformation Formats (UTF) being the implementations. UCS-2 and USC-4 are older 2- and 4-byte Unicode implementations respectively, with UCS-4 being identical to UTF-32, and UCS-2 having been superseded by UTF-16.
UCS-2, as the earliest form of Unicode, made its way into many operating systems of the 90s, which made a move to UTF-16 the least disruptive option. This is why Windows, as well as MacOS, window managers like KDE and the Java and .NET runtime environments use a UTF-16 internal representation.
UTF-32, as the name suggests, encodes every single character in four bytes. While somewhat wasteful, it is also straight-forward and predictable. Whereas in UTF-8 a character can be one to four bytes, in UTF-32 determining the number of characters in a string is as simple as counting the number of bytes and dividing by four. This has led to compilers and some languages like Python (optionally) allowing for the use of UTF-32 to represent Unicode strings.
Of all the Unicode formats, UTF-8 is however the most popular by far. This has been driven largely by the Internet’s World Wide Web, with most websites serving their HTML documents in UTF-8 encoding. Due to the layout of the different code point planes in UTF-8, Western and many other common writing systems fit within two bytes. Compared to the old ISO 8859 and (8 to 16-bit) Shift JIS encodings, this means that effectively the same text in UTF-8 does not take up any more space than before.
From Relay Towers to the Internet
Since those early years in humanity’s past, communication technology has come a long way. Gone are the messengers, the relay towers and small telegraph offices. Even the days when teleprinters were a common sight in offices around the world are now a fading memory. During each step, however, the need to encode, store and transmit information has been a central theme that has relentlessly driven us to the point where we can now instantly transmit a message around the world, in a character encoding that can be decoded and understood no matter where one lives.
For those of us who enjoyed switching between ISO 8859 encodings in our email clients and web browsers in order to get something approaching the original text representation, consistent Unicode support came as a blessing. I can imagine a similar feeling among those who remember when 7-bit ASCII (or EBCDIC) was all one got, or enjoyed receiving digital documents from a European or US office, only to suffer through character set confusion.
Even if Unicode isn’t without its issues, it’s hard not to look back and feel that at the very least it’s a decent improvement on what came before. Here’s to another thirty years of Unicode.
(header image: Punch card with the western alphabet encoded in EBCDIC)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK