

Literate Programming: A Radical Approach to Writing Code with Documentation
source link: https://blog.bitsrc.io/literate-programming-a-radical-approach-to-writing-code-with-documentation-ebb5dc892cd7
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Literate Programming: A Radical Approach to Writing Code with Documentation
Get the best of both worlds with this very old programming paradigm

Ever heard the phrase: self-documenting code doesn’t exist? Well, hold my beer, because I’m about to show you the opposite — kind of.
Originally introduced by Donald Knuth around 1984, Literate programming is considered a programming paradigm that allows you to weave the documentation of your code, written in natural language, with snippets and original portions of your source code. It works in a way that as an output of compilation, you can either run the code, or generate an interactive version of the documentation (i.e an HTML version).
While huge codebases would be very uncomfortable to write like this, there is an argument to be made about smaller components, such as libraries, or components. For instance, if you’re a web dev creating a React component you can take advantage of literate programming. You can structure both, the documentation and the actual source code in a way that anyone trying to understand how to use it can organically learn by reading the generated documentation.
I know, right now, I’m making it sound like a glorified version of Javadocs, but give me a chance, there is more to it than meets the eye.
Why is it better than documentation generation tools?
Javadocs allows you to generate documentation from well-constructed comments. You have a format to follow, and if you do it right, the final result can be something very indeed.
However, the resulting documentation with tools like that has a major flaw: it feels like you’re browsing through a mirror version of your source code. You get all the details, but you have to know where to look to get them.
It’s not organic, it’s not intuitive, it’s very mechanical and machine-like.
However, that is where Literate Programming comes into play: instead of putting the explanation inside the code, you put the code inside the explanation. This very basic difference makes it so that when you browse the final result, you get to read a story that shows you how things work.
It’s like reading an article or a book about your library, instead of going through its internal logic hoping you didn’t miss a connection.
A quick example
For a quick practical example of how literate programming works, the only thing you need to know right now is that:
- There are plenty of CLI tools available for most programming languages, allowing you to create the documentation using your favorite markup language and then translating it correctly.
- Inside the markup documentation, you’ll use special tags that will identify the code blocks. These code blocks will be the ones extracted during a process called Tangling.
The following file contains my written code and documentation, all in one.
Although a very basic example, notice how I was able to split what would normally be a single file, into three different pieces, by using these special tags (i.e the sum and subtract functions should be both on the same file called mylib.js and the last code snippet is actually part of the subtract function).
This way I’m able to focus however I want on the explanation, without letting the code structure affect my storytelling.
With that file, and using the pyWeb utility (a literate tool written in Python), I’m able to run the following lines to parse and extract what I need:
$ python3 -m pyweb my-lib.w
$ rst2html5.py my-lib.rst my-lib.html
The first line translates my .w file into 2 other files: mylib.js (because that’s how I named it inside the documentation) through the process known as tangling, and mylib.rst which can already be seen as the final documentation (through the process known as weaving), but using rst2html which you can download from here, I turned that into HTML.
The outputs are my JavaScript file:

And the documentation itself:

A quick intro to tags and macros
The gist of the .w file other than the documentation itself, are the macros (essentially everything that starts with a @).
Here are the basic ones you need to understand the code:
@omeans “output”. In other words, where you are meant to export the following block of code. If you repeat the filename on different instances, that code will be appended (which is what happens in the above example).@{and@}open and close code blocks. Essentially, anything inside them is code. That also applies to white space, which helps with indentation, especially if you’re writing Python code.@<and@>open and close inline inclusion. These are snippets you can extract and expand somewhere else. Notice I added one of those inside thesubtractfunction.@ddefines an inline definition. This one is used to define the code block to be included using the previous elements.
Of course, the specs are filled with more macros, but you can now go back to the main example and check it out again, it’ll make a lot more sense.
When would you use Literate Programming?
Look, I’m not advocating that you start a full-blown platform from scratch using Literate Programming, that wouldn’t make sense. But then again, maybe your platform doesn’t really need that level of deep documentation, since it’s not meant to be consumed by others.
However, if you’re building code that will be used by 3rd parties, or in other words, if you’re building libraries (think pip modules, NPM packages, React components, and any other type of modularized code) then well-written documentation is paramount to achieve user adoption.
The thing is, just like with TDD, making the switch to do anything other than coding as your first step towards creating these libraries is hard. But if like with TDD, you make the effort, and in this case, create the documentation while you’re writing your code, it can even help your mental modeling process.
It’s not the same to think for 10 minutes and then move on to testing your hypothesis than spending 20 minutes “externalizing” those ideas into actual words, and seeing how coherent they end-up being.
Using Literate Programming for our React Components
Just to give you a more practical example, here I’m going to re-write this component I shared on Bit.dev:
Essentially it is a button you can add to your app and set it a default look and behavior based on its relevance. You can see the full source code here, and as you can appreciate, it’s not a complicated component. However, it’s not documented, in fact, it’s not even commented.
So, if I were to follow a Literate approach, I could write something like this:
If you can mentally parse that, you’ll notice a few things:
- It’s mixing examples and showing you bits of code and CSS styles while speaking of particular sections of the component (in the example I only added an explanation for the “important” button, but you can do the same for the others).
- It’s not repeating the code, I’m writing code in one place, and then I’m referencing the same snippet in another place. So there is no code duplication, what you write is what you get.
- You can even write sample code that will not be “exported”. That is code only meant for the documentation itself, but that code can also pull sections of your main source code.
- I’m not only generating TSX code, but I’m also writing CSS here.
And with these 2 commands, I get both, my HTML documentation and my source code ready to be exported back to Bit:
$ python3 -m pyweb extended-buttons.w
$ rst2html5.py extended-buttons.rst extended-buttons.html
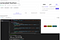
For the sake of simplicity, here are 2 screenshots of the source code and the doc generated:


Completely functional on one side, and completely readable and understandable on the other, and they both came from the same place.
Literate Programming is definitely not the answer to all your documentation problems, and if your codebase is big enough, you’ll have to deal with multiple .w files and import them just like you would with code.
But for a certain group of developers, who are constantly modularizing and sharing their code, this approach can be a great time saver.
Granted, if you need to go back and update your code or fix a bug, having your function split into 3 parts can be an actual problem. So it might also be an interesting option to look at once your code is stable enough and all you need is to write proper documentation.
What do you think? Will you give Literate Programming a chance?
Learn More
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK