

SOA: traffic routing and control
source link: https://bytes.grubhub.com/soa-traffic-routing-and-control-667463b70506
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
SOA: traffic routing and control
In this article we’ll distill the traffic control capabilities that should be considered status quo for a mature service platform into seven scenarios that enable service teams to safely evolve the services they run on it.


Whether your service-oriented platform is comprised of five or five hundred services, how they communicate with each other and other systems/third parties is a key concern. This article focuses more on the basics of traffic routing and what control is required to provide a safe platform for service teams to build on, as such it does not cover load balancing, back pressure, affinity, circuit breakers, and other fundamental networking components. Further to that, we’ll stay technology agnostic, so it doesn’t matter if your services are written in Java/Go/C++/Ruby or whether you share base frameworks, have a service mesh, cluster manager, run on a cloud, self host and so on.
Safely… what’s that mean?
For platforms such as the one Grubhub operates, we see some traffic 24x7. There are certainly times of the day and days of the week that are slower than others, which are the safer times to make production changes, but there’s never zero traffic or a “good” opportunity to take downtime. We aim for 100% availability, so safety in this context speaks to the methods and controls the SOA platform provides service teams so that they can meet the availability goal and use their error budgets for more interesting experimentation and functionality (as opposed to basic backward compatibility, for example).
The ability to control the traffic at all levels is an important tool in your safety toolkit.
SOA basics review
To properly describe the traffic control capabilities, let’s first quickly review some basics so what follows is nice and clear.
While some features may be served by a call to a single service, in our experience, it’s common for that service in turn to call one or more other services which may do the same and so on. Then there’s background work, which is often done via messaging. Services also talk to persistent storage, caches, and external dependencies. The result is a graph of calls.
Here are some illustrations to help:
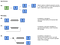
The above can, of course, be combined ad infinitum.
We can also simplify the messaging example. Looking at how messaging systems actually work, you could replace the queues for services in (B), (C) & (D). The key difference is that the client only waits for an ack/response from the intermediary service, not the ultimate receiver(s) of the message.
Seven scenarios
Expanding on that and incorporating messaging, we end up with these seven scenarios from each service’s perspective:
- I want to talk to service A.
- I want to publish a message of type X.
- I’m service A, version V, instance I. Please send me W weight of traffic.
- I’m interested in consuming W weight of messages of type X.
- I want to talk to service A version V, ignore traffic weights.
- I want to publish a message to any instance of the same service and version as me, ignore traffic weights.
- I want to talk to a specific instance, ignore traffic weights.
Scenarios 1–4 are standard default production behavior for real traffic. For example, when an external client (web/native mobile/3rd party) calls an endpoint, they’re invoking #1. There can be an intermediary, such as an API gateway or edge router between, so they’re not explicitly calling for “service A,” but that is the effect.
Scenario 3 is quite commonly implemented but scenario 4 less so. Messaging is equally as important as standard synchronous traffic (e.g. RPC, HTTP).
Scenarios 5 and 6 are where you really get to take control of your traffic and provide safety throughout testing and release. These scenarios should only be available to authorized clients (e.g. testers).
Scenario 7 is for operational tasks that apply to each instance individually (e.g. give me your latest metrics).
Only scenarios 1 and 5 apply to external/third-party systems. In this case, scenario 5 usually takes the form of talking to a sandbox or dev environment as opposed to production.
This doesn’t quite cover everything a service will need to do in order to be a good, safe citizen on such a platform. Here are some additional behaviors for services to implement:
- If my traffic weight is zero, I should not publish messages per scenario 2. The options are to either not publish in the case of an event type message or to invoke scenario 6 in the case of a “do work” type of message intended to distribute work across the cluster.
- Flow overrides. For scenarios 5–7 to work at all levels in the call graph, services must have a contract for how targeting requirements are specified, and this context should be flowed with all outgoing requests except those to third parties. The contract should be protocol specific (e.g. http headers). Messaging systems also generally support some form of metadata/attributes/headers.
Multiple versions
One of the key reasons to build a service oriented platform is that the lifecycle of services should be independent. In the case of a good design, this allows you to get more done with more engineers (rather than less) because there are more opportunities for them to work concurrently.
The result of all this is that over time services change, are added to, and removed from the platform. The dependency graph changes constantly, and you will end up running at least two versions of a service concurrently throughout the upgrade process, which, in many cases, can be lengthy.
With just a few concurrent versions, a new service, and a dependency on it, you end up with something like this:

A calls B, but which version of B should it talk to? The same goes for B calling D. There’s also a new service E which D v2 depends on.
A platform that supports these scenarios can run multiple versions of services concurrently and determine which instances receive what traffic. These versions can (and should) include simulated versions which aid in testing. Given this, you must be able to run at least four concurrent versions to do an upgrade so consider supporting N versions (within reason of course, it’s unlikely that anyone will ever want to run tens of concurrent versions, but there’s no need for a rigid a/b, red/green, alpha/beta/gamma structure).
More on safety
Businesses want engineering to move fast and be agile, which means lots of releases. So let’s talk about how they work on a platform that supports the scenarios above.
Releasing new versions of existing services
- Deploy updates to persistent storage data schema. (optional)
- Start instances of the new version with a traffic weight of 0 so they’re not seeing any “real” traffic. Scenario 1 is not going to hit these new instances and scenario 4 results in 0 messages being consumed.
- Test! Testers have the authority to invoke scenarios 5–7, which ignore traffic weights and instead adhere to what the tester requests, giving it the power to exercise standard integration testing as well as forward and backward compatibility, which is done by mixing targeted versions of both the service under test and its dependencies. Testers may also directly publish targeted messages.
- Increase traffic weight, monitor, continue to increase or decrease in the event of issues.
- Tear down old version(s) (optional)
Releasing entirely new services is very similar with only two relatively minor variations. First, step 4 above must be handled by clients of the service in question after it has been released. This represents new functionality and a new dependency for them, so they must deploy a new version of themselves which gives them an opportunity to run the above flow. The other variation is that step 2 is not applicable for installed clients (e.g. native mobile).
The time spent in step 4 is dictated by one’s need for speed to market and appetite for risk. Given the additional capabilities to test, particularly backward and forward compatibility, there’s no longer a rush due to lack of testing (perhaps due to it being overly costly) based on concerns of that nature. Consider this simple example:
- Build shopping cart
- Checkout
How would you test whether carts created by v2 can be checked out by v1 or even read successfully from storage without the ability to mix targeted versions? What was very painful and may have led teams to rush through an upgrade cycle to reduce the number of shopping carts in this limbo state is now relatively easy and therefore no longer a reason to rush. This highlights an important point: the lifetime of data schema exceeds that of service versions. You can migrate rows/entries but in order to do that on a running system you still have to support backward and forward compatibility which therefore needs to be tested.
Simulators
Simulators are simply another version of a service that generally responds with a “canned” response and can be leveraged to introduce failure scenarios.
They fill gaps in seemingly opposite ends of the testing spectrum by #1, providing a way to create failures and #2, making tests easier to construct, faster to execute, and more reliable due to their “canned” responses. Compare this to the behavior of sandbox environments often provided by vendors: “If the credit card number ends in a 0, it’ll succeed, anything else results in a failure from the following list. 1 = insufficient funds, 2 = ..”. This covers #2 and a subset of #1. The missing aspect of #1 is to provide some randomness in failures, latency, timeouts, etc..
Timeouts are a common source of problems — more specifically, lack of timeouts or having them set too loosely. Either can result in a range of symptoms including: blocked threads, unnecessary work, thundering herds, OOM. What this comes down to is a need for superior testing of our networking code and business logic, especially under load. Having the ability to introduce simulators into the system and target them with testing traffic comes into its own because there’s no need for any change in the service under test. It makes real calls across the network to the simulator, so the only difference is how the simulator responds — or not, or maybe it just takes a while. There are a number of options for degrading networking performance in a more generalized manner, including dropping packets, connections and delaying responses. With the ability to introduce latency and timeouts, the simulator approach gives testers more granular control over specific endpoints/routes/methods, which aligns with how they think about test plans and is also less disruptive in a shared environment.
Conclusion
Much of the above facilitates different methods of testing services so service teams can balance the cost / benefit ratio of their testing efforts while ensuring good coverage. Without granular traffic control throughout the call graph, testing is either all or nothing, which can lead to it being skipped due to cost. We need to take a lead from other engineering disciplines, which, in some cases, go to great lengths to design for testability. Having a service platform that supports the scenarios above helps greatly in reducing overall cost. At Grubhub, we have done this, and it’s paid us back many times over.
Availability and speed to market with new features is key, but one without the other is a recipe for disaster. Stay safe out there. Test it like someone else wrote it!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK