

HashMap 源码学习
source link: https://suiyia.github.io/2019/10/15/HashMap-%E6%BA%90%E7%A0%81%E5%AD%A6%E4%B9%A0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
HashMap 源码学习
本文 java version “1.8.0_221”
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 初始默认容量大小,如果指定容量,容量必须是 2 的倍数
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大的容量大小 1*2^30=1073741824 ,如果指定容量,容量必须是 2 的倍数
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子
static final int TREEIFY_THRESHOLD = 8; // 超过 8 就变为 红黑树
static final int UNTREEIFY_THRESHOLD = 6; // 小于 6 变为链表
transient Node<K,V>[] table; // 存放元素的哈希桶数组
transient int size; // 当前 Map 中 键值对数量
final float loadFactor; // 负载因子
int threshold; // 当前 Map 能容纳的最大键值对数量,threshold = length * Load factor
transient int modCount; // 结构性修改的次数,用于 fail-fast 机制
key 对应到哈希桶的过程
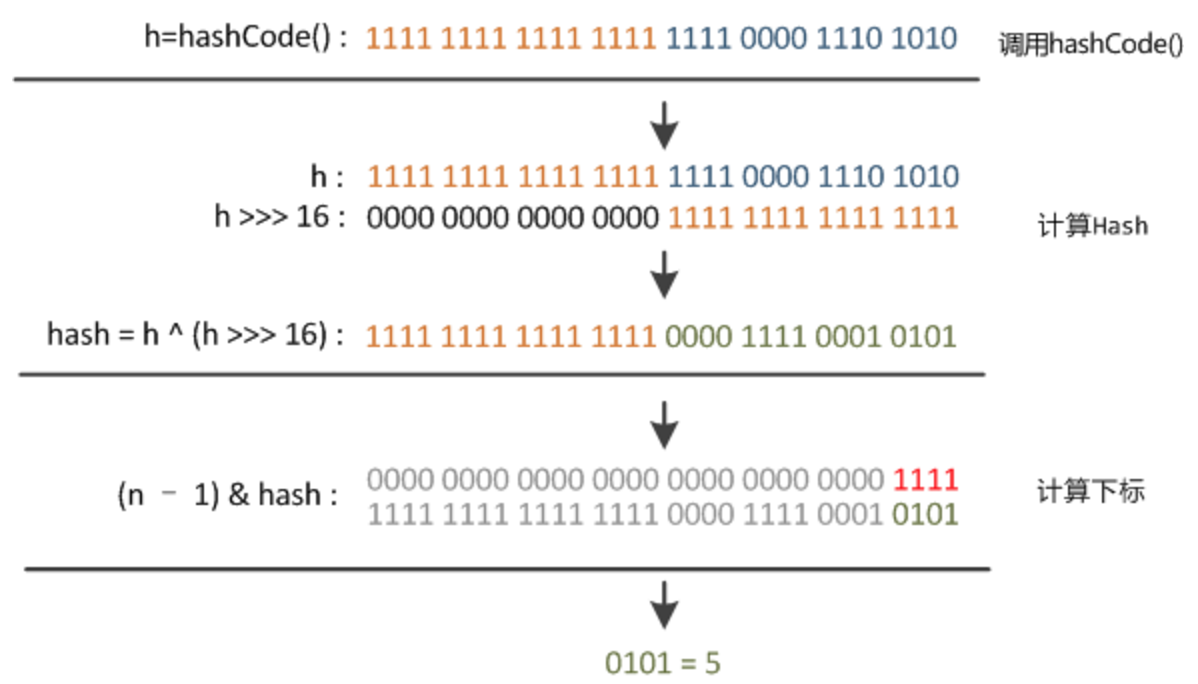
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
index = hash(key) & (length - 1)
若 key == null,放到数组第一位
key != null,调用 Object.hashCode() 方法将 key 进行 hash 得到 h
将 h 与 h 右移 16 位后的数值进行异或得到一个 hash 值
将第 3 步得到 hash 值与数组长度减一进行与运算,得到 key 在哈希桶的索引位置。
第 4 步非常巧妙,它通过 h&(table.length -1)来得到该对象的保存位,而 HashMap 底层数组的长度总是2的n次方,这是 HashMap 在速度上的优化。当 length 总是 2 的 n 次方时,h& (length-1)运算等价于对 length 取模,也就是h%length,但是 & 比 % 具有更高的效率。
get 方法
put 方法支持,key、value 都为 null,并且是 尾插法
get 方法返回 null,有两种情况:一是不包含这个键值对,二是该键值对的键 key 对应的 value 就是 null,可以通过 containsKey 方法判断 Map 是否包含该 key
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 找到 hash 值一样的桶
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k)))) // 如果第一个元素 key 相同,返回这个 Node
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key); // 如果是树节点,那么去树里面找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 在链表中找
return e;
} while ((e = e.next) != null);
}
}
return null;
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
put 方法
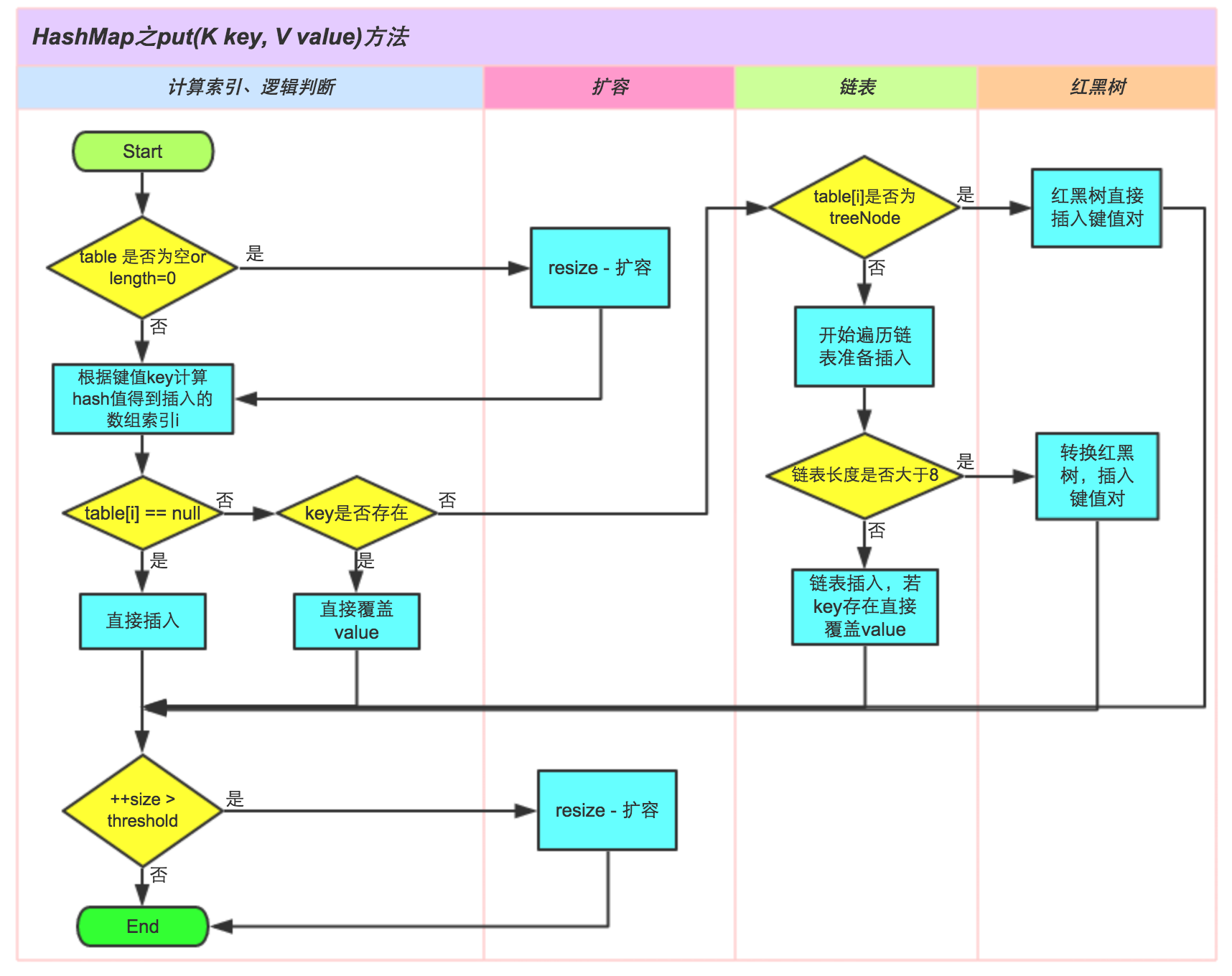
table 为 null 或者 tab.size = 0,进行 resize。
key 进行 hash 之后取模得到的索引位置,若在桶的位置元素为 null,那么直接插入元素。
桶位置元素不为 null,那么进行比较
判断 key 是否相同:
- 如果 key 相同,e 保存该节点
- 如果 key 不同,如果该是红黑树节点,那么执行红黑树的 put 方法;如果是链表节点,执行链表遍历操作,找到对应的节点并用 e 保存,如果链表长度大于 >=7,就将链表转为红黑树
Node e 保存找到的节点,如果没有找到返回 null
如果 size 超过阈值,进行扩容
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果 table 的在(n-1)&hash 的值是 null,就新建一个节点插入在该位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 表示该索引位置有值
else {
Node<K,V> e; K k;
// 如果 key 相等,那么 Node e 保存原来的值用于替换
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))){
e = p;
// 如果 key 最终不等,而且是树节点,执行红黑树的 put 方法
} else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 如果 key 最终不等,而且是链表节点,执行链表的 put 方法
else {
for (int binCount = 0; ; ++binCount) {
// 如果指针为空就挂在后面
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 链表数量 >= 7 就转为红黑树
treeifyBin(tab, hash);
break;
}
// 链表上面有相同的 key 的元素,那么 e 保存原来的值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 最终 Map 中有该元素,那么进行 value 替换
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 结构修改次数加 1
++modCount;
// 如果新增一个元素后容量大于阈值,进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
resize 方法
- 扩容是 2 倍的倍数进行扩容
- 扩容后,换一个更大的数组重新映射,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 如果原来的桶长度已经超过最大阈值,那么数组扩大到 2^31 -1
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
// 如果原来桶长度扩大 2 倍后还是小于最大阈值,那么新阈值为原来阈值的 2 倍
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY){
newThr = oldThr << 1; // double threshold
}
} else if (oldThr > 0){ // initial capacity was placed in threshold
newCap = oldThr;//
} else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK