

Data Science for Sales with Python
source link: https://towardsdatascience.com/data-science-for-sales-with-python-95b1bc8e4246
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Data Science for Sales with Python

Every data scientist, even a beginner one, knows that Python is the most popular language currently, she also knows what neural networks and support vector machines are. But what are the most popular tasks that really bring value for companies on a daily basis? What business-related skills should a successful data scientist have?
Well, the first and most important thing for a business is to sell something. Sure logistics, process-optimization, HR, and other departments are important and have metrics of their own, but if there are no sales there is no business. That’s why there are many more metrics and data associated with customers and sales than there are in any other department and that’s why the data scientists can have a major impact on analyzing sources of revenue.
In this article, I am going to go through some of the most common business problems that data science can solve, and I will do it in Python. To follow the examples you can find a mall-dataset, a movie-dataset, and a whiskey-dataset here.
- Profiling: also known as behavior-description, profiling attempts to characterize the typical behavior of an individual, group, or population. An example profiling question would be: “What is the typical cell phone usage of this customer segment?”. The most common procedure here is to use Matplotlib to explore the shape of the distributions of variables and draw conclusions about them. Let’s see an example with the mall customers dataset:

We can see there is a categorical variable “Gender” that can translate to a dummy variable just using one-hot encoding like this:
As we can see in the histogram there are more female shoppers than males:
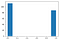
Now let’s see the age pyramid:

Finally, let’s plot a histogram of the income and spending scores:
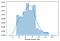
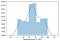
Basing on these conclusions, we could go on and group our customers using clustering in our preferred form (by low, average, or high income/spending, gender, age, etc). That’s what we’ll do in the following examples.
- Association Discovery and Link Prediction: also known as frequent itemset mining, and market-basket analysis, these techniques attempt to find associations between customers based on transactions involving them. The most common application of this technique is used in cross-sales: “people who bought item X also bought item Y”
Let’s see an example with the movies dataset, first we load the “u.data” and the “movies” file and merge them in a single Pandas DataFrame, then we drop the timestamp column that is useless.

We have joined user ratings and movie titles in a single DataFrame. Now we can explore the average rating and number of ratings for each movie like this:

We can pivot our DataFrame and obtain a matrix with movie titles in the columns and users in the rows, doing this:

Finally, we can calculate correlations for the ratings of a movie and use them to recommend similar ones, let’s do it with Starwars for example:

Clustering and Similarity Matching: These techniques deal with grouping individuals in a population together by their similarity. They are used most commonly in customer segmentation and recommendation systems, to answer questions like do our customers form groups? What products should we offer or develop? How should our customer care teams (or sales teams) be structured?
In the example of the Whisky dataset we can see that there are 5 types of whisky:

And paying attention to the distribution of scores I see most of them are concentrated around the mean (score= 87) so I could classify whisky types in three categories: low quality(scores below 85), average quality(scores 85–90), and premium quality (scores greater than 90).
Here is my method to re-score them:
Finally, it’s time to do the clustering: I will use the elbow method to determine the right number of clusters and then implement a K-Means algorithm:
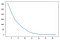
Looking at the elbow-graph we can see the error flattens when we use 15 groups which match exactly our expectations: 5 types x 3 categories of rating.
We can group Whisky types just like this:
Perfect, we have grouped our unsupervised Whisky data with 15 labels, now we can use this new dataset for supervised learning tasks, but that will be in my following article.
Happy coding!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK