

人脸识别系统设计实践:代码生成训练PNET的图片数据
source link: https://blog.csdn.net/tyler_download/article/details/111175749
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
人脸识别系统设计实践:代码生成训练PNET的图片数据
上一节我们了解了PNET的基本原理,本节看看如何生成PNET需要的训练数据。总体而言我们需要产生两部分数据,一部分图片里面包含人脸,另一部分不包含人脸。这里的“包含”或“不包含”并不是指图片中完全没有人脸,而是图片中人脸占据的比率超过一定的阈值时就可以认为给定图片包含人脸。
算法会设定三个阈值,当人脸在图片区域占据比率不超过30%,那么认为图片不包含人脸。如果超过30%但是不到45%,那么图片属于“中性”,当人脸占据区域超过65%则断定图片内含有人脸。训练使用的数据集为WIDERFace,该数据集不但包含了大量含有人脸的图片,而且还通过文本文件详细描述了每张图片中人脸所在的坐标位置。
下载给定数据集后解压,可以看到路径下有多个文件夹和一个文本文件,文件夹中包含不同类型的人脸图片,文本文件描述了每张图片中人脸的坐标位置,例如打开文本可以看到如下一行信息:
0_Parade_marchingband_1_205 59.60 56.00 78.29 74.94 39.41 1.66 56.60 22.60 90.26 18.61 106.71 41.04 144.10 15.87 161.05 37.30 117.68 30.32 132.38 47.02 201.93 16.36 221.37 36.06 162.79 53.26 176.50 72.45 97.98 53.26 113.19 79.43 9.34 85.48 22.43 106.57 59.35 116.15 76.15 139.59 45.29 161.07 59.74 182.17 18.25 247.82 48.34 278.95 114.79 237.10 139.12 265.09 210.80 239.19 231.73 266.66 308.43 259.50 332.99 285.24 402.90 205.89 433.36 242.02 260.95 141.52 280.40 164.15 283.12 151.71 301.22 170.71 353.49 159.85 370.91 183.38 238.07 37.05 250.12 56.08 251.39 28.39 271.26 47.62 266.40 56.71 280.56 75.95 357.28 80.38 371.45 101.73 489.01 112.72 508.57 135.54 545.43 122.50 561.98 148.07 511.58 73.61 529.88 94.92 543.67 75.11 560.97 100.18 544.68 49.29 561.22 67.59 562.48 67.09 583.04 96.17 464.94 68.59 482.75 94.92 502.80 37.00 520.86 56.81 595.57 53.05 612.62 70.85 574.01 138.29 588.80 159.86 554.71 164.62 567.99 185.18 497.47 256.35 526.72 284.60 580.56 239.07 607.82 267.32 706.86 166.62 747.08 209.82 654.28 140.01 672.72 164.13 533.31 3.35 549.04 20.67 596.23 20.99 613.08 39.74 684.31 47.47 699.18 67.20 665.16 40.90 678.88 58.91 659.73 6.03 673.73 27.46 747.49 10.31 765.78 32.90 795.22 17.75 809.80 37.76 813.52 16.03 830.67 41.19 850.39 39.76 870.40 62.63 806.94 59.48 823.81 84.06 739.20 54.34 756.92 78.35 831.81 117.80 852.40 140.38 866.69 108.36 882.70 132.09 798.11 221.94 830.85 260.00 870.04 236.21 898.59 267.28 911.23 223.52 927.69 245.54 991.32 142.56 1011.70 164.67 940.88 88.66 958.15 109.39 917.04 24.75 939.50 53.08 1000.30 25.44 1017.23 45.83 932.24 58.95 949.51 83.14 759.27 34.53 774.08 57.43 758.94 127.71 775.70 152.78 346.72 22.38 363.76 40.91 25.75 42.00 40.87 63.96 47.01 23.81 62.83 45.78 328.05 219.76 350.44 243.90 "
数据以空格将不同信息分离,第一个空格前面的字符串对应图片的名称,上面数据就表明有一张名为0_Parade_marchingband_1_205.jpg的图片,后面的数字以每四个为一组分别对应一张人脸在图片中的坐标,因此我们可以通过这些数据将图片中的人脸“框”出来:
txt_line = "0_Parade_marchingband_1_205 59.60 56.00 78.29 74.94 39.41 1.66 56.60 22.60 90.26 18.61 106.71 41.04 144.10 15.87 161.05 37.30 117.68 30.32 132.38 47.02 201.93 16.36 221.37 36.06 162.79 53.26 176.50 72.45 97.98 53.26 113.19 79.43 9.34 85.48 22.43 106.57 59.35 116.15 76.15 139.59 45.29 161.07 59.74 182.17 18.25 247.82 48.34 278.95 114.79 237.10 139.12 265.09 210.80 239.19 231.73 266.66 308.43 259.50 332.99 285.24 402.90 205.89 433.36 242.02 260.95 141.52 280.40 164.15 283.12 151.71 301.22 170.71 353.49 159.85 370.91 183.38 238.07 37.05 250.12 56.08 251.39 28.39 271.26 47.62 266.40 56.71 280.56 75.95 357.28 80.38 371.45 101.73 489.01 112.72 508.57 135.54 545.43 122.50 561.98 148.07 511.58 73.61 529.88 94.92 543.67 75.11 560.97 100.18 544.68 49.29 561.22 67.59 562.48 67.09 583.04 96.17 464.94 68.59 482.75 94.92 502.80 37.00 520.86 56.81 595.57 53.05 612.62 70.85 574.01 138.29 588.80 159.86 554.71 164.62 567.99 185.18 497.47 256.35 526.72 284.60 580.56 239.07 607.82 267.32 706.86 166.62 747.08 209.82 654.28 140.01 672.72 164.13 533.31 3.35 549.04 20.67 596.23 20.99 613.08 39.74 684.31 47.47 699.18 67.20 665.16 40.90 678.88 58.91 659.73 6.03 673.73 27.46 747.49 10.31 765.78 32.90 795.22 17.75 809.80 37.76 813.52 16.03 830.67 41.19 850.39 39.76 870.40 62.63 806.94 59.48 823.81 84.06 739.20 54.34 756.92 78.35 831.81 117.80 852.40 140.38 866.69 108.36 882.70 132.09 798.11 221.94 830.85 260.00 870.04 236.21 898.59 267.28 911.23 223.52 927.69 245.54 991.32 142.56 1011.70 164.67 940.88 88.66 958.15 109.39 917.04 24.75 939.50 53.08 1000.30 25.44 1017.23 45.83 932.24 58.95 949.51 83.14 759.27 34.53 774.08 57.43 758.94 127.71 775.70 152.78 346.72 22.38 363.76 40.91 25.75 42.00 40.87 63.96 47.01 23.81 62.83 45.78 328.05 219.76 350.44 243.90 "
annotation = txt_line.strip().split(' ')
img_path = annotation[0]
box = list(map(float, annotation[1:]))
boxes = np.array(box, dtype=np.float32).reshape(-1, 4)
print("image contains {} faces".format(len(boxes)))
img = cv2.imread(img_path + ".jpg")
for box in boxes:
top_left = (box[0], box[1])
bottom_right = (box[2], box[3])
img = cv2.rectangle(img, top_left, bottom_right, (255,0,0), 1)
cv2_imshow(img)
上面代码运行后结果如下:
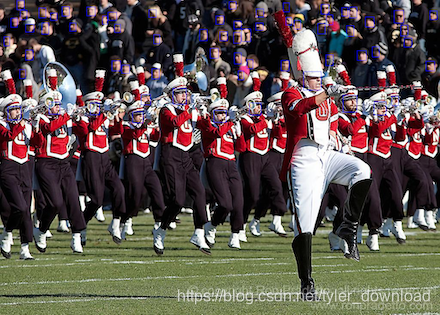
def get_img_boxes(txt_line):
cur_path = os.getcwd()
annotation = txt_line.strip().split(' ')
img_path = os.path.join(cur_path, annotation[0] + ".jpg")
box = list(map(float, annotation[1:]))
boxes = np.array(box, dtype=np.float32).reshape(-1, 4)
return img_path, boxes
txt_line = "0_Parade_marchingband_1_849 448.51 329.63 570.09 478.23 "
img_path, boxes = get_img_boxes(txt_line)
print("image contains {} faces".format(len(boxes)))
face_img = cv2.imread(img_path)
for box in boxes:
top_left = (box[0], box[1])
bottom_right = (box[2], box[3])
face_img = cv2.rectangle(face_img, top_left, bottom_right, (255,0,0), 1)
cv2_imshow(face_img)
上面代码运行后结果如下:

def IOU(box, boxes):
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
boxes_area = (boxes[:,2] - boxes[:,0] + 1) * (boxes[:,3] - boxes[:,1] + 1)
#计算矩形重叠部分面积
xx1 = np.maximum(box[0], boxes[: ,0])
yy1 = np.maximum(box[1], boxes[:,1])
xx2 = np.minimum(box[2], boxes[:,2])
yy2 = np.minimum(box[3], boxes[:,3])
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
over_lap = w * h
area_combine = (box_area + boxes_area - over_lap + 1e-10) #1e-10避免数值为0
overlap_percentage = over_lap / area_combine
return overlap_percentage
代码将两个区域的面积加总然后减去两个区域的重叠部分由此得到两个区域的“并后我们随机在图片上扣出一系列区域,然后选择那些与人脸区域交集所占比率小于0.3的区域作为训练数据:
npr=np.random
def create_neg_parts(img, face_boxes):
neg_num = 0
height, width, channel = img.shape
neg_boxes = []
while neg_num < 50:
#随机截取一个区域,不小于12*12,因为pnet要训练得识别12*12的图片内部是否有人脸
size = npr.randint(12, min(width, height) / 2)
#选取左上角坐标
nx = npr.randint(0, width - size)
ny = npr.randint(0, height - size)
crop_box = np.array([nx, ny, nx+size, ny + size])
iou = IOU(crop_box, face_boxes)
if np.max(iou) < 0.3: #如果截取的面积与所有人脸面积重叠部分小于两者合并面积的0.3表明截取面积中不含有人脸
neg_boxes.append(crop_box)
neg_num += 1
return neg_boxes
def draw_boxes(img, boxes, color):
for box in boxes:
top_left = (box[0], box[1])
bottom_right = (box[2], box[3])
img = cv2.rectangle(img, top_left, bottom_right, color, 1)
cv2_imshow(img)
接着我们调用上面代码并将所选择的区域绘制出来,这样读者就能对算法和代码有更感性的理解:
print(len(boxes))
color = (0, 255, 0)
neg_boxes = create_neg_parts(face_img, boxes)
draw_boxes(face_img.copy(), neg_boxes, color)
代码运行后所得结果如下:

def create_neg_overlapped_parts(img, face_boxes): #产生只含有部分脸部的区域
height, width, channel = img.shape
neg_overlapped_boxes = []
for box in face_boxes:
left, top, right, bottom = box
w = right - left
h = bottom - top
if max(w, h) < 20 or left < 0 or top < 0: #忽略掉小于20像素的人脸区域
continue
for i in range(5): #每个人脸区域最多生成5个重叠不超过0.3的区域
size = npr.randint(12, min(width, height))
delta_x = npr.randint(max(-size, -left), w)
delta_y = npr.randint(max(-size, -top), h) #沿着左上角随机上下和左右偏移形成重叠区域的左上角
nx1 = int(max(0, left + delta_x))
ny1 = int(max(0, top + delta_y))
if nx1 + size > width or ny1 + size > height: #确保创建的区域不超过整个图片范围
continue
crop_box = np.array([nx1, ny1, nx1+size, ny1+size])
iou = IOU(crop_box, face_boxes)
if np.max(iou) < 0.3:
neg_overlapped_boxes.append(crop_box)
return neg_overlapped_boxes
neg_overlapped_boxes = create_neg_overlapped_parts(face_img, boxes)
print(len(neg_overlapped_boxes))
color = (0, 0, 255)
draw_boxes(face_img.copy(), neg_overlapped_boxes, color)
上面代码运行后结果如下:

def create_pos_part_box(img, boxes): #产生与脸部重叠部分超过0.65和0.45的交集区域
height, width, channel = img.shape
pos_boxes = []
pos_offset = []
part_boxes = []
part_offset = []
for box in boxes:
left, top, right, bottom = box
w = right - left
h = bottom - top
if max(w, h) < 20 or left < 0 or top < 0:
continue
for i in range(20): #每个人脸生成20个与人脸部分重叠超过0.65或0.4的区域
size = npr.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
if w < 5:
continue
delta_x = npr.randint(-w * 0.2, w * 0.2)
delta_y = npr.randint(-h * 0.2, h * 0.2)
nx1 = int(max(left + w /2 + delta_x - size / 2, 0))
ny1 = int(max(top + h / 2 + delta_y - size / 2, 0))
nx2 = nx1 + size
ny2 = ny1 + size
if nx2 > width or ny2 > height: # 生成区域不能超出图片大小
continue
crop_box = np.array([nx1, ny1, nx2, ny2])
#计算生成区域左上角和右下角相对于人脸框的偏移比率后期计算需要
offset_x1 = (left - nx1)/float(size)
offset_y1 = (top - ny1) / float(size)
offset_x2 = (right - nx2) / float(size)
offset_y2 = (bottom - ny2) / float(size)
box_ = box.reshape(1, -1)
iou = IOU(crop_box, box_)
if np.max(iou) >= 0.65:
pos_boxes.append(crop_box)
pos_offset.append((offset_x1, offset_y1, offset_x2, offset_y2))
elif np.max(iou) >= 0.4:
part_boxes.append(crop_box)
part_offset.append((offset_x1, offset_y1, offset_x2, offset_y2))
return pos_boxes, pos_offset, part_boxes, part_offset
pos_boxes, pos_offset, part_boxes, part_offset = create_pos_part_box(face_img, boxes)
print("pos boxes len: ", len(pos_boxes))
print("part boxes len: ", len(part_boxes))
color = (125, 125, 0)
draw_boxes(face_img.copy(), pos_boxes, color) #显示与脸部重叠面积超过0.65的区域
上面代码运行后结果如下:

color = (0, 125, 125)
draw_boxes(face_img.copy(), part_boxes, color) #显示与脸部重叠面积超过0.4的区域
代码运行后所得结果如下:

我们将三部分数据分别存储在不同文件夹下,第一种存在"neg"文件夹,第二种存在"part"文件夹,第三种存在"pos"文件夹,然后就可以把他们当做训练数据输入网络。这些实践对理论的理解至关重要,如若不然你看论文描述的算法就会落入到云里雾里,这也是我认为很多知乎上的文章是装逼假把式的主要原因。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK