

巧用localCheckpoint加速Spark上的迭代计算(break lineage)
source link: https://blog.csdn.net/yanxiangtianji/article/details/108975613
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Spark和迭代计算
Spark是一个基于lineage的计算框架。
它通过lineage记录了数据从加载以来的所有操作,这样一方面让spark可以轻松地实现lazy execution,另一方面当发生问题的时候,可以准确地进行数据恢复。
我们可以这样理解:Spark把一个数据X抽象为一个RDD。在这个RDD里面Spark不仅记录了X的值X.data,还通过一个DAG记录了它是怎么计算得来的X.lineage。
这种设计非常适合对于普通的数据处理任务,但是对于数据需要不断循环优化的分析任务(特别是迭代优化类的算法),它就会产生严重的性能问题。
这里我说的迭代计算是指这样的计算模型:
X=f(X,D)
我们不断地使用同一个方法f,去优化数据X的值。这里的D是指可能用到的其他数据。
超长lineage问题
在Spark中,当我们进行迭代计算的时候,默认情况下,这些修改操作本身也会被不断记录起来。累计到若干轮之后,lineage会变很别长,特别是当操作函数f比较复杂的时候。
根据实际经验,随着计算的进行,这个问题会逐步地劣化每一轮的性能,大约10轮就能有明显的体现。
这里我举一个我用Python写的PageRank的例子(damp=0.8):
from operator import add
import time
def compute(link, rank):
n = len(link)
for d in link:
yield (d, rank/n)
graph=...
# graph=sc.parallelize([(0,[1,2]),(1,[0,2,3]),(2,[1,2]),(3,[2,0])])
# initialize ranks of all nodes to 1.0
r = graph.map(lambda v:(v[0], 1.0))
po = r.count() * 1.0
# compute
for i in range(100):
t = time.time()
# compute the contribution of each edge
c = graph.join(r).flatMap(lambda klr:compute(klr[1][0], klr[1][1]))
# compute the new rank
r = c.reduceByKey(add).mapValues(lambda v: v*0.8+0.2)
# current progress
p = r.map(lambda v:v[1]**2).sum()
t = time.time() - t
print('iteration: %d, time: %f, progress: %p' % (i, t, p))
我用6个worker跑一个10M个节点,平均度数为4.33的Power-Law图(alpha=2.3)。
前10轮,平均每轮100秒左右。从低20轮开始,每轮大约120秒。30轮时增加到150秒。50轮时增加到250秒左右。到100轮时已经增加到530秒了。
下图这个图是第三轮时计算流程所对应的lineage图。
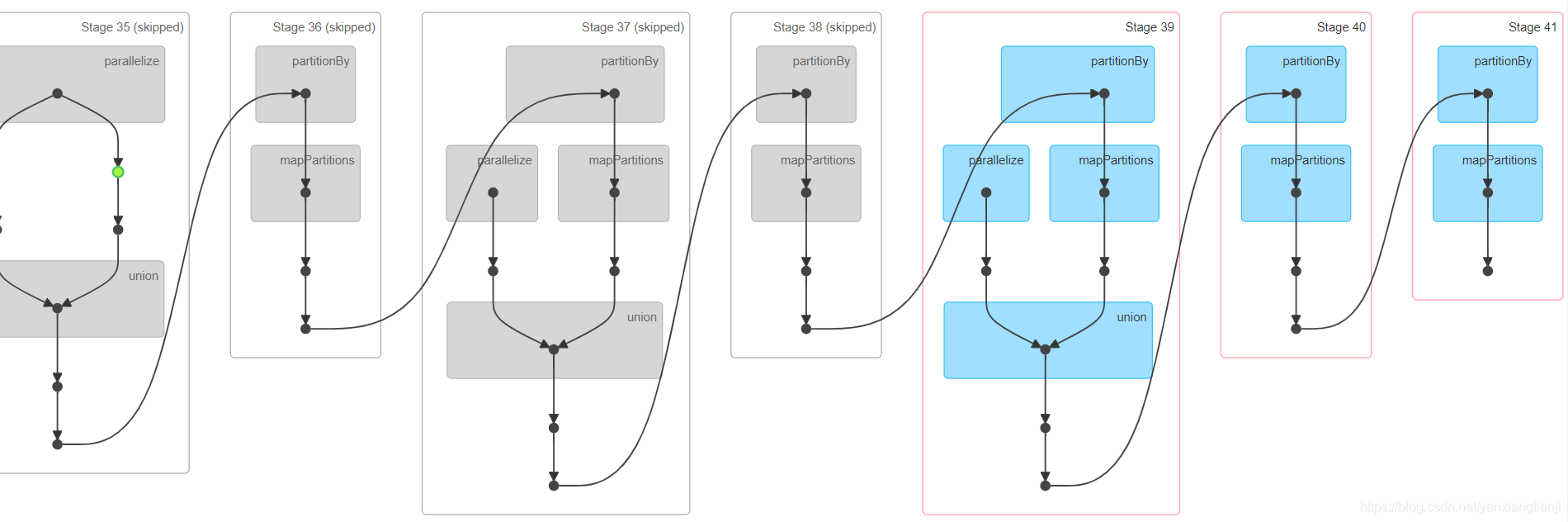
通过这个图,可以明显看出,这个linage图越来越长。即使spark会自动跳过一些stage,比如上图中的灰色部分。但Spark并不保证一定这么做。这意味着计算后期Spark很可能会重做很多前面的stage。而且我们的实验也验证了这一点。
最简单的办法是重新生成迭代数据的RDD,把之前的lineage砍掉。比如下面这样:
r = sc.parallelize(r.collect())
但是这样做也会导致性能问题,甚至有时候根本无法执行。
关键问题在于r.collect()操作需要把所有数据都汇集到driver(执行这行代码的worker)上。一方面这会引入一个网络数据传输操作,通常这都是很耗时的;另一方面数据可能很大以致于worker的内存并不足以容纳它,这时collect()就会抛出异常。
一个更好的办法是使用cache()和localCheckpoint()函数,来强制跳过之前的lineage。这也是GraphX所采用的方法。
cache函数
RDD的cache()函数强制系统在内存中为这个RDD创建一个副本,这样后后续用到它的操作就可以直接使用这个cache下来的结果了。比如:
r.cache()
注意:现在版本的Spark里面cache()和以前的执行逻辑不通。现在调用cache()时是对数据做一个需要cache的标记,而不再立即求出它的值。只有等到这个RDD数据真正被计算之后,Spark才把它的结果cache起来。可以通过r.is_cached来查看数据r是否完成了cache。
localCheckpoint函数
RDD的localCheckpoint()函数和checkpoint()使用目的函数完全不同。localCheckpoint是设计出来斩断lineage的,而checkpoint是用来提供容错的。
调用r.localCheckpoint()时,除了进行checkpoint操作,r之前的lineage会被斩断,仿佛它是新load出来的数据一样。
注意:与cache()一样,在目前版本的Spark中localCheckpoint()也是只做标记而不立即执行。当数据被真正算出来之后它才会执行。
我们可以修改上面的例子为:
for i in range(100):
t = time.time()
# compute the contribution of each edge
c = graph.join(r).flatMap(lambda klr:compute(klr[1][0], klr[1][1]))
# compute the new rank
r = c.reduceByKey(add).mapValues(lambda v: v*0.8+0.2)
# break the lineage every 5 iterations
if i % 5 == 1:
r.cache()
r.localCheckpoint()
# current progress
p = r.map(lambda v:v[1]**2).sum()
t = time.time() - t
print('iteration: %d, time: %f, progress: %p' % (i, t, p))
由于cache和localCheckpoint本身也是有开销的,特别是localCheckpoint,所以并不建议每一轮都这么做一次。最好是根据实际计算的复杂度,设置一个周期。
但是需要注意,在有些情况下,cache+localCheckpoint并不必collect+parallelize更快。因为写checkpoint所涉及的硬盘读写消耗有可能反而超过了网络传输消耗的时间。
参考资料:
- https://zhuanlan.zhihu.com/p/87983748
- https://livebook.manning.com/book/spark-in-action-second-edition/16-cache-and-checkpoint-enhancing-spark-s-performances/v-14/
- https://medium.com/swlh/scaling-iterative-algorithms-in-spark-3b2127de32c6
- http://spark.apache.org/docs/latest/api/python/pyspark.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK