

Building a Road Sign Classifier in Keras
source link: https://towardsdatascience.com/building-a-road-sign-classifier-in-keras-764df99fdd6a?gi=f6bed8c77f68
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Building a Road Sign Classifier in Keras
Writing a CNN that classifies over 43 types of road signs in the Keras framework
Jan 24 ·10min read

{kind=link}
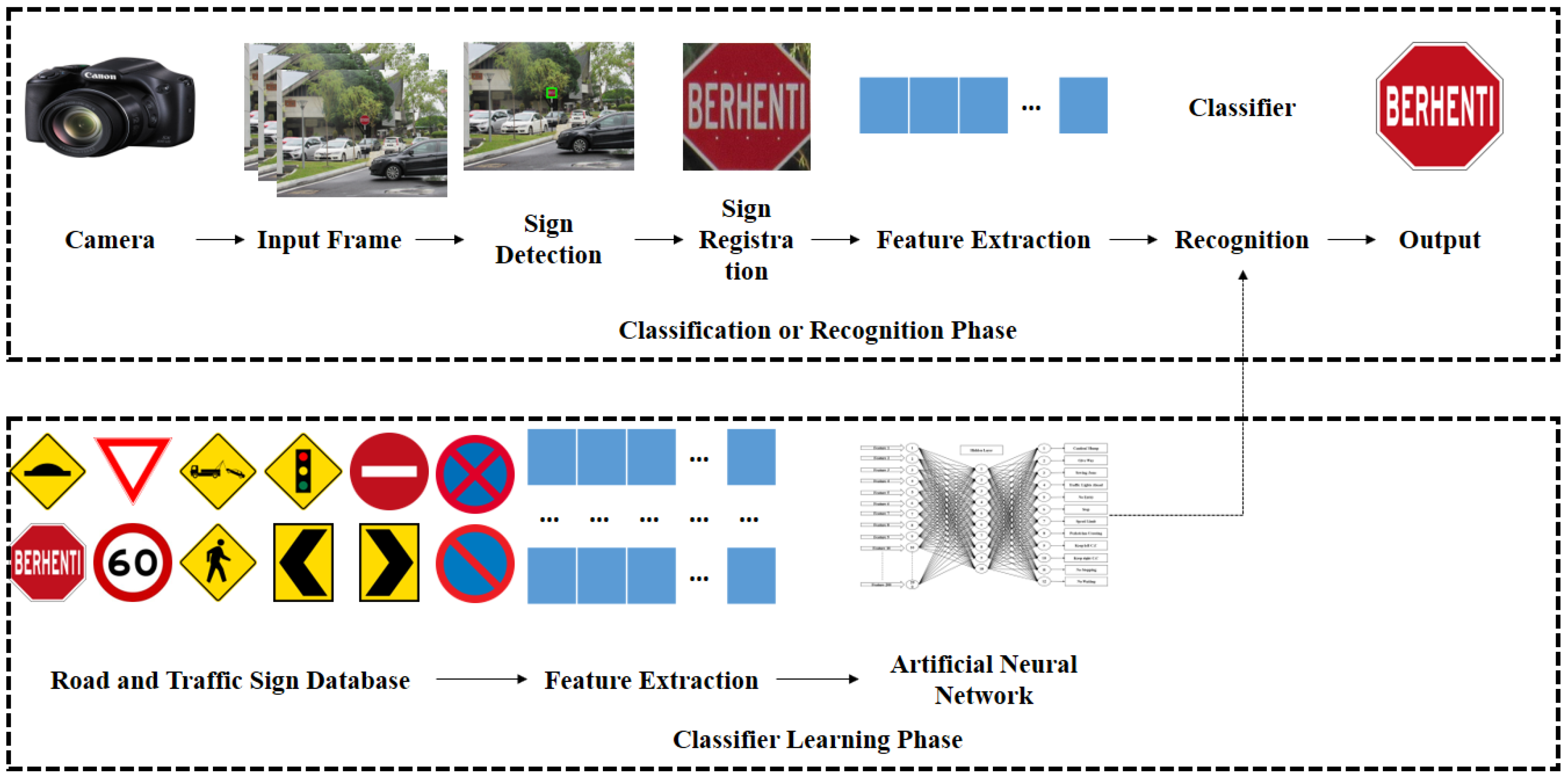
There are so many different types of traffic signs out there, each with different colours, shapes and sizes. Sometimes, there are two signs may have a similar colour, shape and size, but have 2 totally different meanings. How on earth would we ever be able to program a computer to correctly classify a traffic sign on the road? We can do this by creating our very own CNN to classify each different road sign for us.
Downloading the Data
In this tutorial, we’ll use the GTSRB dataset, a dataset with over 50,000 images of German Traffic Signs. There are 43 classes (43 different types of signs that we’re going to have to classify). Click the link below to download the dataset.
When you open the dataset in your computer, there should be 6 paths inside your dataset (3 folders and 3 spreadsheets), like below.

The meta should have folder should have 43 different images (ranging from 0–42). The test folder is just a bunch of test images. The train folder should have 43 folders (again, ranging from 0–42), each containing images from its respective class.
Now that you have the dataset, and that the dataset contains all the required data, let's begin coding!
This tutorial will be divided into 3 parts: loading the data , building the model and training the model .
Just before starting though, make sure you have Jupiter notebooks installed on your computer because this tutorial is done on Jupiter notebooks (this can be done by installing Anaconda. Click the link below to install Anaconda.)
Loading the Data
Okay, so now that we’ve installed Jupyter Notebooks and we have the dataset installed, we’re ready to begin coding (Yesss)!
First things first, let’s import the necessary libraries and modules that are required for us to load the data.
import pandas as pd import numpy as np import os import cv2 import matplotlib.pyplot as plt import randomimport tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Activation from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Dense from tensorflow.keras.utils import to_categorical from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.optimizers import Adam
The first bunch is libraries needed to create the load_data function. The second bunch is the stuff that we need to build our model. You can import each bunch in different kernels if you like, but it really doesn’t matter.
Creating the L oad_Data Function
To begin loading the data, let's create a variable that will represent where our dataset is stored. Make sure you put the letter r in front of your path string so that your computer knows that it’s supposed to read the string.
Note:My path will be different to yours. To get the path to your dataset, you should go to the folder where your dataset is located, click once on your dataset (don’t open it, just make that you clicked on it), then click the button copy path which is on the top left of your screen

Then paste the path into your jupyter notebook (like I did below). Make sure that you put an r in front of your string so that the pc knows that it's supposed to read the file.
data_path = r"D:\users\new owner\Desktop\Christmas Break\gtsrb-german-traffic-sign"
Next, let’s define the function that will load our data into the notebook from the computer.
def load_data(dataset):
images = []
classes = [] rows = pd.read_csv(dataset)
rows = rows.sample(frac=1).reset_index(drop=True)
Our load_data function takes 1 parameter, which is the path to our dataset. After that, we define two lists, images and classes . The images list will store the image arrays and the class list will store the class number for each image.
In the next line, we’re going to open the CSV file.
And the final line randomizes our data which will prevent the model from overfitting to specific classes.
for i, row in rows.iterrows():
img_class = row["ClassId"]
img_path = row["Path"] image = os.path.join(data, img_path)
The for loop cycles through all the rows. The .iterrows() function returns an index for each row (The first row is 0, then 1, 2, 3, …. until the final row).
We take the image’s class from the ClassId column and the image data from the Path column.
Finally, we take the image’s path we got from the spreadsheet and we join it with the path to our dataset to get the full path to the image
image = cv2.imread(image)
image_rs = cv2.resize(image, (img_size, img_size), 3) R, G, B = cv2.split(image_rs) img_r = cv2.equalizeHist(R)
img_g = cv2.equalizeHist(G)
img_b = cv2.equalizeHist(B) new_image = cv2.merge((img_r, img_g, img_b))
First, we read the image array (convert it from an array of numbers into an actual picture, so that we can resize it). Then we resize the image dimensions into 32 X 32 X 3, (it makes training the model lot faster if all the images are the same dimensions).
The next 5 lines are performing histogram equalization, which is an equalization technique which improves the contrast in images. If you’re interested in learning more about histogram equalization, click here
Note: This code is still in the for loop from the previous code block
if i % 500 == 0:
print(f"loaded: {i}") images.append(new_image)
classes.append(img_class) X = np.array(images)
y = np.array(images)
return (X, y)
Still in the for loop, we’re going to write an if statement that prints how many images we have loaded in. This statement will print every 500 images, just so that we know that our function is actually working.
Next, we’ll add the image that we just extracted from the dataset into the lists that we defined before.
Now outside of the for loop, we’re going to redefine the images and classes lists as Numpy arrays. This is so that we can perform operations on the arrays later on.
Finally, when we have finished extracting all the images from the dataset, we will return both the images and classes list in a tuple.
Defining Hyperparameters
Hyperparameters are parameters that a neural network cannot learn. They must be explicitly defined by the programmer before training
epochs = 20 learning_rate = 0.001 batch_size = 64
Our first hyperparameter (I’ll use the abbreviation HYP), epochs , tells the neural network how many times it should complete a full training process. In this case, the neural network will train itself 20 times (go over all 50,000 images and validate itself with 12,000 test images 20 times)!
The learning rate tells us how much the weights will be updated each time. The learning rate is often between 0 and 1.
The batch size tells us how much images the neural network will cycle through at once. It would be impossible for the computer to cycle through all 50,000 images at one go, it would crash. That’s why we have the batch size.
Loading in the Data
train_data = r"D:\users\new owner\Desktop\TKS\Christmas Break\gtsrb-german-traffic-sign\Train.csv" test_data = r"D:\users\new owner\Desktop\TKS\Christmas Break\gtsrb-german-traffic-sign\Test.csv"(trainX, trainY) = load_data(train_data) (testX, testY) = load_data(test_data)
First, we’ll define the paths to our test and train datasets, using the same method that we used to define the path to the dataset before
Now, we’re going to load both the training and test data in using our load_data function.
We’re going to store the images list in the variable trainX, and store the classes list in the trainY variable, and do the same for testX, and testY.
Note: This step may take a while, depending on the specs of your computer. Mine took 10–15 mins.
Preparing the Data for Training
print("UPDATE: Normalizing data")
trainX = train_X.astype("float32") / 255.0
testX = test_X.astype("float32") / 255.0print("UPDATE: One-Hot Encoding data")
num_labels = len(np.unique(train_y))
trainY = to_categorical(trainY, num_labels)
testY = to_categorical(testY, num_labels)class_totals = trainY.sum(axis=0)
class_weight = class_totals.max() / class_totals
Now we’re going to normalize the data. This allows us to scale down the values in the data to be between 0 and 1, from before which was between 0 and 255.
Next, we’re going to one-hot encode the test and train labels. In essence, one-hot encoding is a way of representing each class with a binary value (1s and 0s) instead of a categorical value (“red” or “blue”). It does this by creating a diagonal matrix where the principal diagonal is ones, and the rest of the values are 0. The matrix has dimensions equal to the number of classes there are (if there are 20 classes, the matrix is a 20X20 matrix). In the matrix, each row represents a different class, so each class has its unique code. If you want to learn more about one-hot encoding, here's a great resource
And finally, we’re going to account for inequalities in the classes by assigning a weight to each class.
Building the Model
Now it’s time to build the actual CNN architecture. First, let's import the necessary libraries and modules:
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Activation from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Dense
Here, we import Tensorflow, which is a framework in Python that allows us to build our ML models, and from Tensorflow we import Keras, which simplifies our models even more! After that, we’re importing a bunch of different layers that we need to build the model. If you want to learn more about exactly what each of these layers does, skim through my article on CNN’s.
Before we jump into building the model, I want to point out that there is no “proper” way to build the model. There is no fixed amount of layers, dimensions or types of layers that your CNN has to have. You should play around with it to see which one gives you the best accuracy. I’ll give you the one that gave me the best accuracy.
class RoadSignClassifier:
def createCNN(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
This time, we’re going to create a class, called RoadSignClassifier (any name should do). Within the class, there is one function, createCNN, which takes 4 parameters. We’ll be using the Sequential API, which allows us to create the model layer-by-layer.
model.add(Conv2D(8, (5, 5), input_shape=inputShape, activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
This is our first convolutional layer. We define the dimension of our output (8 X 8 X 3), and we use the activation function “relu”. We continue with this Conv2D — MaxPooling2D sequence for 2 more times.
model.add(Conv2D(16, (3, 3), activation="relu"))
model.add(BatchNormalization())
model.add(Conv2D(16, (3, 3), activation="relu"))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(BatchNormalization())
The same thing as last time, except this time we include batch normalization. It just speeds up training.
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(512, activation="relu")) model.add(Dense(classes, activation="softmax"))
return model
Now we flatten the output from the final convolutional layer, perform a dropout and enter into our final dense layer. The output in the final dense layer is equal to the number of classes that we have.
That’s basically it for building the model. Time to move on ahead!
Training the Model
Now its time for the fun part (actually this is the part where we have to wait 30 mins for the model to train lol). Its time to train our model to recognize road signs!
data_aug = ImageDataGenerator( rotation_range=10, zoom_range=0.15, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.15, horizontal_flip=False, vertical_flip=False)
Here we’re performing data augmentation . Data augmentation creates modified versions of the images in our dataset. It allows us to add images to our dataset without us having to collect new ones. In Keras, we use the ImageDataGenerator module to perform data augmentation.
model = RoadSignClassifier.createCNN(width=32, height=32, depth=3, classes=43) optimizer = Adam(lr=learning_rate, decay=learning_rate / (epochs))
The first line defines our model. We use the class RoadSignClassifier, and define the width, height, depth and the number of classes.
In the second line, we create our optimizer, which in this case is the Adam optimizer. We’ll initialize the learning rate as what we had set it to be previously (0.001), we’ll also set the learning rate to decrease every epoch (that’s the decay parameter, it reduces overfitting).
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])fit = model.fit_generator(
data_aug.flow(train_X, trainY, batch_size=batch_size),
epochs=epochs,
validation_data=(test_X, testY),
class_weight=class_weight,
verbose=1)
The first line compiles the model. We create the model and define the optimizer, the loss, and the number of epochs.
In the second line, we fit out model (this is where the training takes place). Our data_aug.flow method applies the augmentations to our images that we defined before. The number of epochs is set to 20. For the validation data , we use our test data. The verbose is set to 1, which just means that Keras will show the progress of the model being trained as you go along.
Now, you’ve finished writing the code for your model. Its time to run it. Once you’ve run it for a bit, you should get an output like this:
First three epochs (your accuracy should be 70–80% at the third epoch)Then after you’ve finished all you’re epochs, you should get an output similar to this:
Final three epochs (your accuracy should be over 90%)Your accuracy should be at least 90%. If not, go an play around with the model architecture. Eventually, your model will return an accuracy of around 90% or more.
Cool!
Now you finished your classifier! It feels good, right! Well, that’s it for today. Hopefully, you learned something in this article! If you’re stuck on something, you can e-mail me at [email protected], and I’ll do my best to help you. Good luck on your ML journey.
Other Great Options
If this tutorial didn’t appeal to you, or you’re just looking for another tutorial, here is another great tutorial that I find really informative!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK