

Shopify 如何在 Kubernetes 中实现自定义的自动扩展
source link: https://www.infoq.cn/article/CIcJm7q2wAtUOES1ccfM
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
来自 Shopify 的 Andy Kwiatkowski 在柏林举行的 Velocity 会议上 讨论了他们为何要在 Kubernetes 中创建自定义的自动扩展器 。 现有的自动扩展方案 无法满足 Shopify 的需求。这主要是因为它们会接收到大量突如其来的流量请求。同时,他们还需要在收缩或配置复杂的扩展条件时,能够有一个经济有效的解决方案。
Kwiatkowski 说到,Shopify 的 Web 站点在促销或“限时抢购”的时候会突然接收到大量的请求。限时抢购通常只会维持很短的时间,比如十五或二十分钟。所以,它们需要快速扩展,但是反应式扩展并不适合这些情况,这主要是因为扩展过程有很多的活动,比如生成新节点、下载 Docker 镜像以及启动守护程序集之类的应用。因此,平均来看,扩展可能会需要两分钟到二十分钟。当自动扩展和添加处理能力就绪的时候,限时抢购可能已经结束了。
Shopify 使用 Go 语言创建了一个 自定义的自动扩展器 以满足其突然暴增的流量的需求,目前它还没有开源。同时,他们还需要更好的控制功能,以实现安全的部署或配置更为复杂的扩展条件(比如使用过去的数据)。自动扩展器每 30 秒运行一次,为即将到来的限时抢购添加所需的副本。
扩展或伸缩还会影响每月的云账单。因此,自动扩展器需要基于丰富的信息作出决策。为了定义集群需要多少副本,Shopify 使用了 Kubernetes 中来自 HPA 的风险与成分分析公式 。Shopify 定义了他们希望的服务器繁忙程度。然后,基于服务器的繁忙程度和目前存在的副本数量,该公式能够给出集群应该具有的副本数量。其目的是始终保持集群的目标使用率。
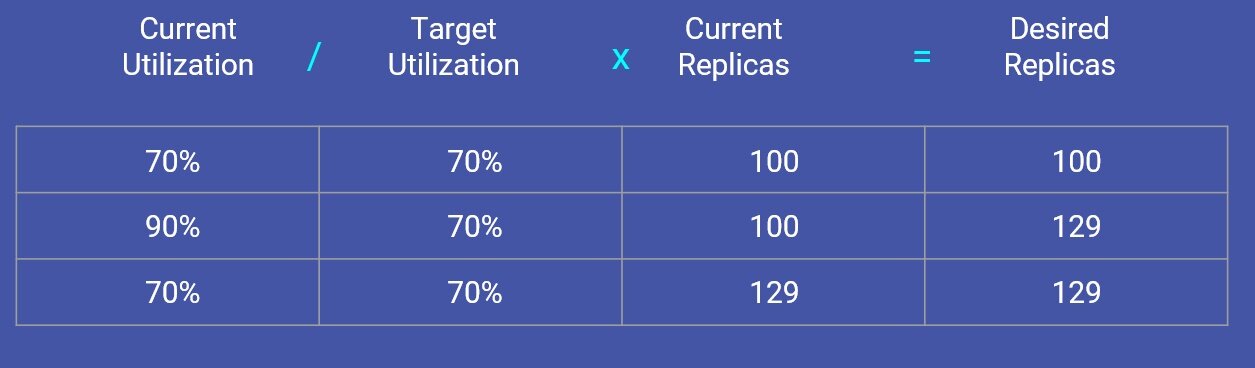
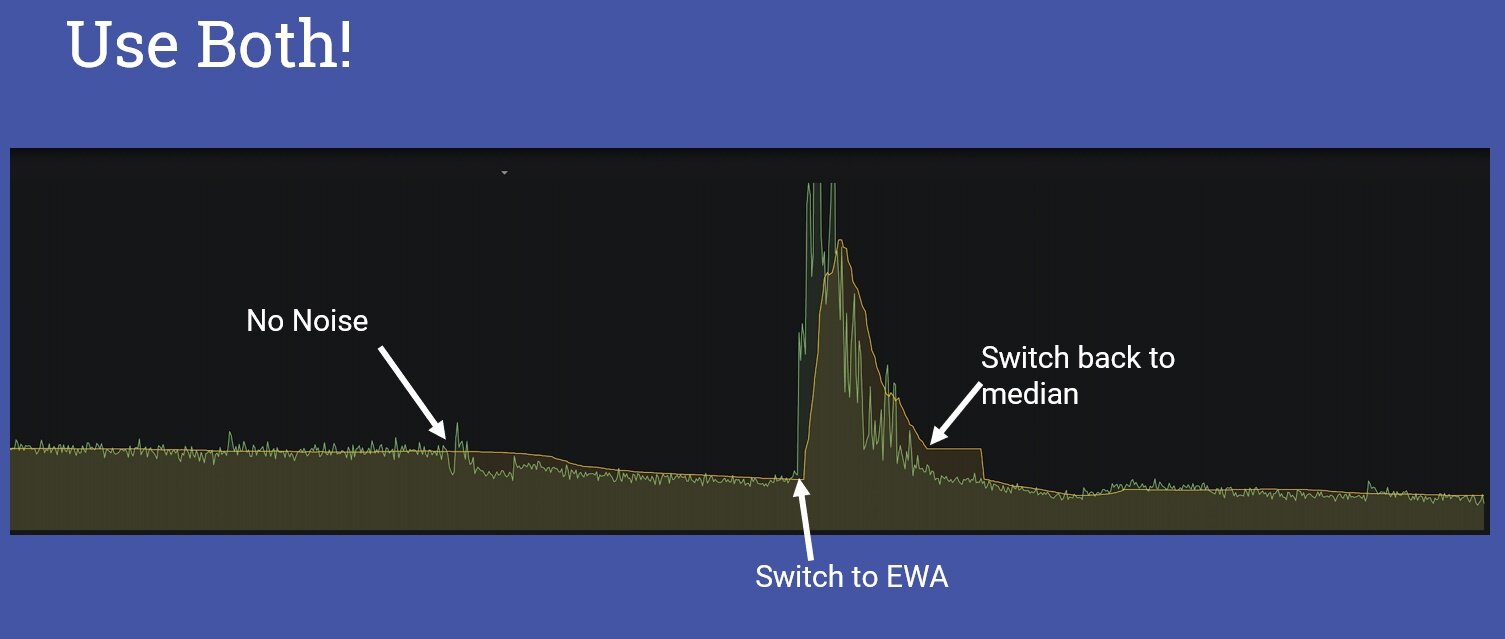
收缩集群会消耗时间,因此会增加成本。所以,为了有一个高效的成本扩展方案,Shopify 必须通过分析过去的流量数据来提升其自动扩展器。在运行一些实验之后,Shopify 注意到在使用平均 CPU 利用率来设置扩展规则时(当然其他解决方案都是这样做的),他们无法准确地预测峰值。如果使用 CPU 使用率中位数的话,会有更好的结果,只不过会有暂时的额外容量。但是,当有更长(30 分钟)的峰值时,自动扩展器不会增加更多的副本。为了解决该问题,他们使用 CPU 利用率的指数加权平均值(exponentially weighted average,EWA),在这种方式下,新的值会比旧的值更重要。因此,自动扩展器可以快速添加更多副本。
Shopify 的自动扩展器会同时计算中位数和 EWA 的 CPU 利用率。如果没有明显差异的话,自动扩展器会使用中位数 CPU 利用率。否则的话,它会使用 EWA 的 CPU 利用率。通过这种方式,Shopify 能够在真正需要的时候才添加副本。
最后,Kwiatkowski 说,有时他们收集的数据会有错误,如空值、零值、陈旧的数据或稀疏的数据。因此,为了避免在扩展或伸缩时出现问题,如果有任何数据错误,它们总是按最大容量伸缩以确保安全。此外,它们配置了一个最小的副本值,以防止在收缩时出现问题。
原文链接:
How Shopify Implements Custom Autoscaling Rules in Kubernetes
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK