

DPDK加速技术深度剖析(一)—— 综述篇
source link: https://www.sdnlab.com/22406.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者简介:王成飞,M.S-Group组织主要成员,前锐捷网络系统架构师,锐捷路由器REF(锐捷快速转发平台)的主设计师,多年数通行业实战经验,资深数通领域专家。
索引导读:
- X86平台报文处理加速技术分类总揽
- 各技术维度及采用的实现技巧产生效果是多维、非线性、相互影响的
- “消除IO延迟阻塞CPU”技术实现技巧浅谈
- DPDK作为数据转发平台框架是优秀的,但是作为数通产品基础平台,需持续优化
随着云计算的兴起,SDN/NFV等网络技术快速发展,越来越多的SDN/NFV开源项目选用DPDK作为基础的报文处理加速平台。本系列文章将深入分析DPDK和硬件体系架构相关的加速技术,着重分析DPDK基于X86/IA-64CPU架构的硬件体系的加速, 纯软件算法相关的加速技术暂不在本文讨论范围。

传统的看法,网络设备以IO密集型为主,X86/IA-64架构CPU更适合计算密集型的任务。DPDK为IA架构正名,做IO密集型的工作已经被证实有出色的表现。如果以CPU为核心来划分,提高报文处理的吞吐率,DPDK加速技术在顶层设计上大致涉及以下四个方面的内容:
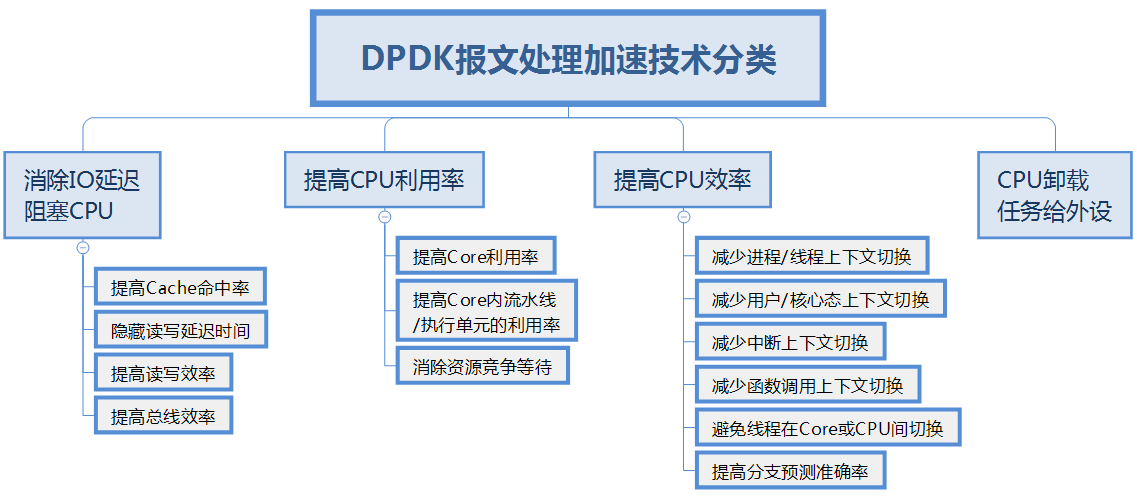
1)消除IO延迟阻塞CPU:
IO问题(包括隐式的自动取指和显示的内存读写指令)是拖垮CPU处理报文吞吐率的第一杀手。以Linux的IP栈为例,对报文的处理过程中,远超过90%以上CPU时钟周期是消耗在内存读写时的Cache行填充等待上,结果导致CPU核内的执行单元在绝大多数时间实际处于空闲等待状态。
2)提高CPU利用率:
CPU利用率的问题就是如何减少CPU核的空闲等待时间,包括CPU核等待、以及核/超线程内部的执行单元的闲置等待两个方面。
3)提高CPU效率:
CPU效率和利用率不是一回事,效率问题要解决的是减少无用功,例如减少上下文切换的开销。
4)CPU卸载任务给外设:
CPU卸载就是把CPU核要干的部分活,分派给外设或其他单元去干,DPDK常见的是卸载给网卡去干。这样可以减轻CPU的负荷来提高CPU处理报文的吞吐率。
上述加速技术的分类,不是具体的实现技巧,而是解决问题的方向和要点。实际的具体加速实现技巧,是立体多维的,可能一个技巧的应用,对解决某一个或几个问题方向有利,却对另外某个方向有害。且硬件的具体架构、报文处理的调度框架模型、用户配置的业务功能集、实时的业务流等众多实时动态因素,会改变这些技巧的效力及效力因素的权重。
具体技巧和前面的分类技术方向之间的关系如下图所示:
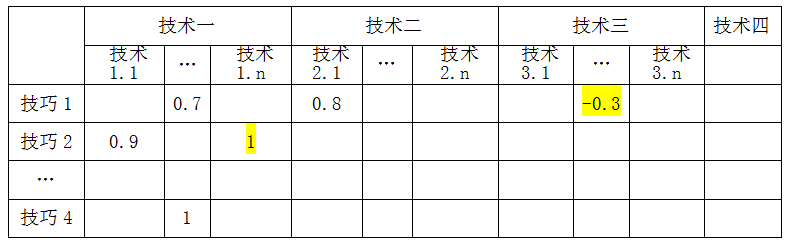
上表中的生效系数展示了单个技巧和技术分类间的关系。技巧的应用可能会引入新问题,产生负向效果,如上表所示的技巧1在技术三(解决CPU利用率)维度产生负向效果。
消除IO延迟阻塞CPU,是重要的基础技术,下面简单解释几个这类技术在DPDK中的具体使用技巧:
数据结构局部性:在设计数据结构时,预判分析在某个时段(如某个函数或依次调用的函数集)内,需要密集访问的数据域,集中在尽可能小的内存空间内,并且尽可能在一个Cache行内。例如:mbuf的控制结构,绝大多数报文在数据平面要使用的字段,集中在mbuf控制结构的第一个Cache内,第二个Cache行内的字段,在数据平面一般情况下都不会使用。报文buffer数据结构的精心设计,是提高报文处理性能的核心要害点,相对而言,Linux的报文buffer数据结构sk-buffer的设计非常糟糕,成为报文处理吞吐率的重要杀手。凭经验值估计,如果DPDK的报文buffer换成sk-buffer,吞吐率会降数倍。
多报文批处理:从收发包,到对报文处理各种业务功能处理的函数,多数函数一次调用处理一批报文。而不是象Linux的IP栈一样单报文跑全程。根据“时间/空间局部性原理”可得知,多报文批处理可以显著提高Cache特别是L1-Cache的命中率(I-Cache和D-Cache命中率都会提高),分摊函数调用时堆栈/寄存器组上下文切换的开销(根据测试数据,函数调用上下文切换的开销均值达到20%左右)。同时,批处理模式还是其他报文处理加速技术的基础,例如:只有在批处理模式下,“读写延迟隐藏”相关技术的实现才有可能。
Cache行预取:对于IA架构来说,L1-Cache访问时延为4个时钟周期,L2为12个,L3需要26-31个时钟周期。如果三级Cache全部脱靶,一次内存访问需要100多个(约140个左右)的时钟周期,耗费的CPU核的时间是几百甚至上千条指令的损失!如新的haswell架构的IA-64核,每核每时钟周期是8 issue(发射),即每周期最多可以发射8条指令和retirement(引退)8条指令。为了隐藏内存访问无法容忍的延迟,避免因等待内存访问完成让核内的执行单元处于空闲等待的状态,提前将需要访问的内存内容预取到Cache中。
交织:IA-64的haswell以后的架构,每周期8发射,其中4条RW和4条非RW如算术/逻辑/分支等类型指令;老的x86架构是4发射,类似是2条RW+2条非RW。因此,要让核内的流水线满负荷运行,RW指令和非RW指令交替编排,并且邻近指令间没有数据相关性,是让流水线满负荷且不断流的唯一模式。这是RW指令和非RW指令间的交织。另一个很重要的交织模式是:Cache行数据预取和数据处理的交织,例如,在多报文批处理中,预取下一个报文或者下一个小批次指文组的处理过程中要使用的数据结构、报文内容等,然后再处理当前报文或者当前小批次报文组。报文相关数据的Cache行预取和报文处理错位交替推进,是交织处理的典型模式,可以高效地隐藏Cache行填充的延迟。
自动预取:CPU核内有自动预取单元,硬件系统会自动预取数据到Cache行。因此就像航海的人需要了解海洋洋流一样,软件工程师也需要彻透了解硬件自动预取逻辑和算法,顺着洋流而不是逆流而行。
在DPDK中还使用了其他很多的报文处理加速的实现技巧,例如:DDIO、减少MMIO、提高PCIE传输效率、避免Cache行部分写、分支预测、大页内存、展开循环、展开函数、线程私有结构、核/CPU私有结构、无锁设计、无锁队列环ring、原子操作、RCU机制、读写锁、自旋锁、信息版本序号(分布式时戳)、用户态收发及UIO、报文零COPY、PMD收包、CPU亲和性、SIMD、调度模型:RTC及pipeline模式等等。在这里不再详述。在后续的分项专题中,每个技巧将会讲清楚:背景基础理论、运用要点、实例及分析。
总的说来,DPDK是一个优秀的通信设备数据平面开发平台,提供数据平面开发工具集,为IA(Intel architecture)架构提供高效的用户态数据报文处理的库函数和驱动框架的支持。不同于Linux系统以通用性为设计目标,而是专注于数通设备或网络应用中数据包的高性能处理;DPDK数据平面工作在用户态,对需要转发的业务报文,旁路掉Linux中对数据报文进行处理的核心态IP栈。
DPDK的顶层设计对硬件体系架构特性的利用很充分,也较为成功,但具体到二级模块级设计、详细设计后不尽完美,再到实现中的代码级,欠优化的地方更多。DPDK调度模型RTC和pipeline也较为粗犷,实际使用中需要精细调优。
DPDK仅提供的是高性能处理报文的框架平台和库函数,而不是对报文的具体业务处理。对通信设备的项目工程实现来说,性能调优是一件具体而艰巨的任务,数据平面随便一行代码的处理失当,就可能会引起性能狂降,因此,应用好DPDK并不是一件轻松的事,深入理解DPDK加速技术的精髓是前提条件。
后续的系列文章将向您详尽展示DPDK加速技术的技术细节,敬请期待!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK