

Go 调度模型 | wudaijun's blog
source link: http://wudaijun.com/2018/01/go-scheduler/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
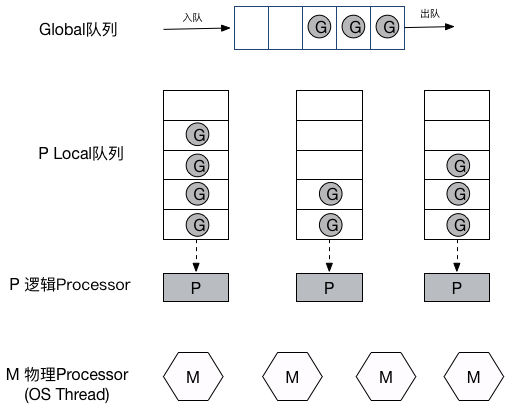
G P M 模型
定义于src/runtime/runtime2.go:
- G: Gourtines, 每个Goroutine对应一个G结构体,G保存Goroutine的运行堆栈,即并发任务状态。G并非执行体,每个G需要绑定到P才能被调度执行。
- P: Processors, 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等
- M: Machine, OS线程抽象,负责调度任务,和某个P绑定,从P的runq中不断取出G,切换堆栈并执行,M本身不具备执行状态,在需要任务切换时,M将堆栈状态写回G,任何其它M都能据此恢复执行。
Go1.1之前只有G-M模型,没有P,Dmitry Vyukov在Scalable Go Scheduler Design Doc提出该模型在并发伸缩性方面的问题,并通过加入P(Processors)来改进该问题。
G-P-M模型示意图:
补充说明:
- P的个数由GOMAXPROCS指定,是固定的,因此限制最大并发数
- M的个数是不定的,由Go Runtime调整,默认最大限制为10000个
在M与P绑定后,M会不断从P的Local队列(runq)中取出G(无锁操作),切换到G的堆栈并执行,当P的Local队列中没有G时,再从Global队列中返回一个G(有锁操作,因此实际还会从Global队列批量转移一批G到P Local队列),当Global队列中也没有待运行的G时,则尝试从其它的P窃取(steal)部分G来执行,源代码如下:
// go1.9.1 src/runtime/proc.go
// 省略了GC检查等其它细节,只保留了主要流程
// g: G结构体定义
// sched: Global队列
// 获取一个待执行的G
func findrunnable() (gp *g, inheritTime bool) {
// 获取当前的G对象
_g_ := getg()
top:
// 获取当前P对象
_p_ := _g_.m.p.ptr()
// 1. 尝试从P的Local队列中取得G 优先_p_.runnext 然后再从Local队列中取
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 2. 尝试从Global队列中取得G
if sched.runqsize != 0 {
lock(&sched.lock)
// globrunqget从Global队列中获取G 并转移一批G到_p_的Local队列
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// 3. 检查netpoll任务
if netpollinited() && sched.lastpoll != 0 {
if gp := netpoll(false); gp != nil { // non-blocking
// netpoll返回的是G链表,将其它G放回Global队列
injectglist(gp.schedlink.ptr())
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// 4. 尝试从其它P窃取任务
procs := uint32(gomaxprocs)
if atomic.Load(&sched.npidle) == procs-1 {
goto stop
}
if !_g_.m.spinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
for i := 0; i < 4; i++ {
// 随机P的遍历顺序
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
goto top
}
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
// runqsteal执行实际的steal工作,从目标P的Local队列转移一般的G过来
// stealRunNextG指是否steal目标P的p.runnext G
if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil {
return gp, false
}
}
}
...
}
当没有G可被执行时,M会与P解绑,然后进入休眠(idle)状态。
用户态阻塞/唤醒
当Goroutine因为Channel操作而阻塞(通过gopark)时,对应的G会被放置到某个wait队列(如channel的waitq),该G的状态由_Gruning变为_Gwaitting,而M会跳过该G尝试获取并执行下一个G。
当阻塞的G被G2唤醒(通过goready)时(比如channel可读/写),G会尝试加入G2所在P的runnext,然后再是P Local队列和Global队列。
syscall
当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于block on syscall状态,此时仍然可被抢占调度: 执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但队列中仍然有G需要执行,则创建一个新的M。
当系统调用完成后,G会重新尝试获取一个idle的P,并恢复执行,如果没有idle的P,G将加入到Global队列。
系统调用能被调度的关键有两点:
runtime/syscall包中,将系统调用分为SysCall和RawSysCall,前者和后者的区别是前者会在系统调用前后分别调用entersyscall和exitsyscall(位于src/runtime/proc.go),做一些现场保存和恢复操作,这样才能使P安全地与M解绑,并在其它M上继续执行其它G。某些系统调用本身可以确定会长时间阻塞(比如锁),会调用entersyscallblock在发起系统调用前直接让P和M解绑(handoffp)。
另一个关键点是sysmon,它负责检查所有系统调用的执行时间,判断是否需要handoffp。
sysmon
sysmon是一个由runtime启动的M,也叫监控线程,它无需P也可以运行,它每20us~10ms唤醒一次,主要执行:
- 释放闲置超过5分钟的span物理内存;
- 如果超过2分钟没有垃圾回收,强制执行;
- 将长时间未处理的netpoll结果添加到任务队列;
- 向长时间运行的G任务发出抢占调度;
- 收回因syscall长时间阻塞的P;
入口在src/runtime/proc.go:sysmon函数,它通过retake实现对syscall和长时间运行的G进行调度:
func retake(now int64) uint32 {
n := 0
for i := int32(0); i < gomaxprocs; i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// 如果当前P Local队列没有其它G,当前有其它P处于Idle状态,并且syscall执行事件不超过10ms,则不用解绑当前P(handoffp)
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// handoffp
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
handoffp(_p_)
}
incidlelocked(1)
} else if s == _Prunning {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
// 如果当前G执行时间超过10ms,则抢占(preemptone)
if pd.schedwhen+forcePreemptNS > now {
continue
}
// 执行抢占
preemptone(_p_)
}
}
return uint32(n)
}
抢占式调度
当某个goroutine执行超过10ms,sysmon会向其发起抢占调度请求,由于Go调度不像OS调度那样有时间片的概念,因此实际抢占机制要弱很多: Go中的抢占实际上是为G设置抢占标记(g.stackguard0),当G调用某函数时(更确切说,在通过newstack分配函数栈时),被编译器安插的指令会检查这个标记,并且将当前G以runtime.Goched的方式暂停,并加入到全局队列。源代码如下:
// src/runtime/stack.go
// Called from runtime·morestack when more stack is needed.
// Allocate larger stack and relocate to new stack.
// Stack growth is multiplicative, for constant amortized cost.
func newstack(ctxt unsafe.Pointer) {
...
// gp为当前G
preempt := atomic.Loaduintptr(&gp.stackguard0) == stackPreempt
if preempt {
...
// Act like goroutine called runtime.Gosched.
// G状态由_Gwaiting变为 _Grunning 这是为了能以Gosched的方式暂停Go
casgstatus(gp, _Gwaiting, _Grunning)
gopreempt_m(gp) // never return
}
}
// 以goched的方式将G重新放入
func goschedImpl(gp *g) {
status := readgstatus(gp)
// 由Running变为Runnable
casgstatus(gp, _Grunning, _Grunnable)
// 与M解除绑定
dropg()
lock(&sched.lock)
// 将G放入Global队列
globrunqput(gp)
unlock(&sched.lock)
// 重新调度
schedule()
}
func gopreempt_m(gp *g) {
if trace.enabled {
traceGoPreempt()
}
goschedImpl(gp)
}
netpoll
前面的findrunnable,G的获取除了p.runnext,p.runq和sched.runq外,还有一中G从netpoll中获取,netpoll是Go针对网络IO的一种优化,本质上为了避免网络IO陷入系统调用之中,这样使得即便G发起网络I/O操作也不会导致M被阻塞(仅阻塞G),从而不会导致大量M被创建出来。
G创建流程
G结构体会复用,对可复用的G管理类似于待运行的G管理,也有Local队列(p.gfree)和Global队列(sched.gfree)之分,获取算法差不多,优先从p.gfree中获取(无锁操作),否则从sched.gfree中获取并批量转移一部分(有锁操作),源代码参考src/runtime/proc.go:gfget函数。
从Goroutine的角度来看,通过go func()创建时,会从当前闲置的G队列取得可复用的G,如果没有则通过malg新建一个G,然后:
- 尝试将G添加到当前P的runnext中,作为下一个执行的G
- 否则放到Local队列runq中(无锁)
- 如果以上操作都失败,则添加到Global队列sched.runq中(有锁操作,因此也会顺便将当P.runq中一半的G转移到sched.runq)
G的几种暂停方式:
- gosched: 将当前的G暂停,保存堆栈状态,以
_GRunnable状态放入Global队列中,让当前M继续执行其它任务。无需对G进行唤醒操作,因为总会有M从Global队列取得并执行该G。抢占调度即使用该方式。 - gopark: 与goched的最大区别在于gopark没有将G放回执行队列,而是位于某个等待队列中(如channel的waitq,此时G状态为
_Gwaitting),因此G必须被手动唤醒(通过goready),否则会丢失任务。应用层阻塞通常使用这种方式。 - notesleep: 既不让出M,也不让G和P重新调度,直接让线程休眠直到被唤醒(notewakeup),该方式更快,通常用于gcMark,stopm这类自旋场景
- notesleepg: 阻塞G和M,放飞P,P可以和其它M绑定继续执行,比如可能阻塞的系统调用会主动调用entersyscallblock,则会触发 notesleepg
- goexit: 立即终止G任务,不管其处于调用堆栈的哪个层次,在终止前,确保所有defer正确执行。
Go调度器的查看方法
示例程序,对比cgo sleep和time.sleep系统调用情况:
// #include <unistd.h>
import "C"
func main() {
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func() {
C.sleep(1) // 测试1
// time.Sleep(time.Second) // 测试2
wg.Done()
}()
}
wg.Wait()
println("done!")
time.Sleep(time.Second * 3)
}
通过GODEBUG运行时环境变量的schedtrace=1000参数,可以每隔1000ms查看一次调度器状态:
$ GODEBUG=schedtrace=1000 ./test
// 测试1输出结果
SCHED 0ms: gomaxprocs=4 idleprocs=2 threads=1003 spinningthreads=2 idlethreads=32 runqueue=0 [0 0 0 0]
done!
SCHED 1001ms: gomaxprocs=4 idleprocs=4 threads=1003 spinningthreads=0 idlethreads=1000 runqueue=0 [0 0 0 0]
SCHED 2001ms: gomaxprocs=4 idleprocs=4 threads=1003 spinningthreads=0 idlethreads=1000 runqueue=0 [0 0 0 0]
SCHED 3010ms: gomaxprocs=4 idleprocs=4 threads=1003 spinningthreads=0 idlethreads=1000 runqueue=0 [0 0 0 0]
// 测试2输出结果
SCHED 0ms: gomaxprocs=4 idleprocs=2 threads=6 spinningthreads=1 idlethreads=2 runqueue=129 [0 128 0 0]
done!
SCHED 1009ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 2010ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
SCHED 3019ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
其中schedtrace日志每一行的字段意义:
SCHED:调试信息输出标志字符串,代表本行是goroutine scheduler的输出;
1001ms:即从程序启动到输出这行日志的时间;
gomaxprocs: P的数量;
idleprocs: 处于idle状态的P的数量;通过gomaxprocs和idleprocs的差值,我们就可知道执行go代码的P的数量;
threads: os threads的数量,包含scheduler使用的m数量,加上runtime自用的类似sysmon这样的thread的数量;
spinningthreads: 处于自旋状态的os thread数量;
idlethread: 处于idle状态的os thread的数量;
runqueue: go scheduler全局队列中G的数量;
[0 0 0 0]: 分别为4个P的local queue中的G的数量。
可以看出,time.Sleep并没有使用系统调用,而是进行了类似netpoll类似的优化,使得仅仅是G阻塞,M不会阻塞,而在使用cgo sleep的情况下,可以看到大量的闲置M。
通过运行时环境变量GODEBUG的schedtrace参数可定时查看调度器状态:
// 每1000ms打印一次
$GODEBUG=schedtrace=1000 godoc -http=:6060
SCHED 0ms: gomaxprocs=4 idleprocs=3 threads=3 spinningthreads=0 idlethreads=0 runqueue=0 [0 0 0 0]
SCHED 1001ms: gomaxprocs=4 idleprocs=0 threads=9 spinningthreads=0 idlethreads=3 runqueue=2 [8 14 5 2]
SCHED 2006ms: gomaxprocs=4 idleprocs=0 threads=25 spinningthreads=0 idlethreads=19 runqueue=12 [0 0 4 0]
SCHED 3006ms: gomaxprocs=4 idleprocs=0 threads=26 spinningthreads=0 idlethreads=8 runqueue=2 [0 1 1 0]
...
GODEBUG还可使用GODEBUG="schedtrace=1000,scheddetail=1"选项来查看每个G,P,M的调度状态,打出的信息非常详尽复杂,平时应该是用不到。关于Go调试可参考Dmitry Vyukov大牛的Debugging performance issues in Go programs。
再回头来看,Go 为什么要使用GPM?而不是像大多数调度器一样只有两层关系GM,直接用M(OS线程)的数量来限制并发能力。我粗浅的理解是为了更好地处理syscall,当某个M陷入系统调用时,P则”抛妻弃子”,与M解绑,让阻塞的M和G等待被OS唤醒,而P则带着local queue剩下的G去找一个(或新建一个)idle的M,当阻塞的M被唤醒时,它会尝试给G找一个新的归宿(idle的P,或扔到global queue,等待被领养)。多么忧桑的故事。
相关资料:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK